特别小的目标检测识别
目标检测现在越来越流行,而且自从使用深度学习方法以来,人们越来越感兴趣。
目标检测现在越来越流行,而且自从使用深度学习方法以来,人们越来越感兴趣。如今,根据无人机和飞行器的广泛使用情况,使用航拍照片的应用程序非常畅销。由于物体的尺寸小得多,与使用边缘设备相关的计算能力限制,以及由于电源有限的能耗,以及与实时应用相关的效率和推理时间,这种方法比普通的目标检测任务更困难。
无人驾驶车辆系统协会国际学生无人机系统竞赛(AUVSISUAS)计算机视觉任务,除了物体(标签)检测之外,还要求对检测到的标签进行视觉分析,以提取标签颜色、字母数字符号和符号的颜色等特征。
有研究者证明,新提出的方法基于以下方法:YOLO算法,k-均值聚类,基于CNN的字母数字符号分类,取得了令人满意的结果。
现在的任务是开发一个针对从无人机上拍摄的航拍照片的标签检测系统,该系统允许将标签定位与GPS联系起来,并获得目标类型、方向和颜色、字母数字符号及其颜色。
新提出的方法使用YOLO算法模型来检测对象,k-均值聚类从背景分组,SqueezeNet对字母数字符号进行分类。AUVSI SUAS检测任务没有官方数据集,因此生成了数据生成器。它旨在以自然背景的形式准备数据。不同的草的阴影,沙子,混凝土,在随机的位置添加了不同的标签。Generator使用10个模板数字和12种颜色。 上图是检测的案例。例如左边的目标只有14个像素大小。
上图是检测的案例。例如左边的目标只有14个像素大小。
新框架方法
Object Detection
航拍照片的关键是物体大小,由于飞行高度,通常要小得多。在这种方法中,使用了轻量级版本的YOLOv4的YOLOv4-tiny-3l,可以检测特别小的物体。这个解决方案让研究者在功能较弱的设备(如Nvidia Jetson)上以高FPS率进行推理。
Detection metrics with tag size attention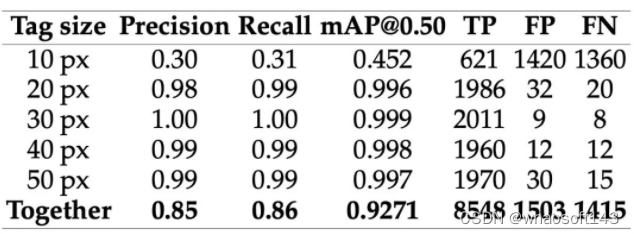
Tag Segmentation
分割任务依赖于使用具有两个聚类中心的k-Means算法的集群检测目标ROI。这种方法允许从背景中分割标记。聚类的结果是两个集群中心的标签和背景形式的(R、G、B)颜色。为了对这个值进行分类,使用欧几里得范式来计算最近的模板颜色。标签颜色被指定为检查ROI图像边框。标签分割和颜色分类的结果如下图所示。 whaosoft aiot http://143ai.com  Alphanumeric Sign Classification
Alphanumeric Sign Classification
第三个任务需要将字母数字标记分类为36个标签(26个符号和10个数字)。为此,使用了EMNIST数据集,它用大写字母扩展了标准MNIST。
Results of methods used for alphanumeric sign classification
它包含了533,993次训练和89,264张测试图像。研究表明,轻量级的CNN-SqueezeNet比SiameseNet with Triplet Loss方法更精确、更快(如上表),这还需要一个分类算法,如KNN。
实验
AUVSI SUAS Competition扩展了普通的检测任务,以创建更复杂的流程。因此,这些结果需要被编码在一个JSON文件中,如下所示。
{”type ”: ”standard ” ,”latitude”: 52.402477,”longitude ”: 16.953619 ,”orientation”: ”n”,”shape”: ”cross”,”background color ”: ”brown” ,”alphanumeric”: ”V”,”alphanumeric color ”: ”yellow”}
上表1包含了10px-50px尺寸图的检测任务的结果。上表2包括已测试的分类方法的精度评分。通过遥测技术从无人机GPS传感器接收经纬度数据。此外,几何方程、校准后的技术信息和距离传感器的测量可以指定更精确的定位值。