目录
前言
本文内容通过分析航空公司数据用户数据,得到航空公司用户年龄年龄段分布情况
先对航空公司用户年龄进行数据预处理,后面再通过pyecharts实现航空公司用户年龄段分布玫瑰图。
一、Pyecharts
1.概括
Echarts 是一个由百度开源的数据可视化,凭借着良好的交互性,精巧的图表设计,得到了众多开发者的认可。而 Python 是一门富有表达力的语言,很适合用于数据处理。当数据分析遇上数据可视化时,pyecharts 诞生了。
2.特性
- 简洁的 API 设计,使用如丝滑般流畅,支持链式调用
- 囊括了 30+ 种常见图表,应有尽有
- 支持主流 Notebook 环境,Jupyter Notebook 和 JupyterLab
- 可轻松集成至 Flask,Django 等主流 Web 框架
- 高度灵活的配置项,可轻松搭配出精美的图表
- 详细的文档和示例,帮助开发者更快的上手项目
- 多达 400+ 地图文件以及原生的百度地图,为地理数据可视化提供强有力的支持
3.安装
windows中搜索anaconda prompt打开,运行下述代码:
pip install pyecharts
或使用清华镜像下载(建议使用这个):
pip install pyecharts -i https://pypi.tuna.tsinghua.edu.cn/simple
4.官方网站
文档
包含pyecharts中各个功能和图形的介绍和代码参数解析。
https://pyecharts.org/#/zh-cn/intro
社区
包含各种图形demo的项目案例代码和演示。
https://gallery.pyecharts.org/#/README
二、导入相关的库
-
第一行代码
from pyecharts import options as opts是将pyecharts库中的options模块导入,并取一个别名为opts,options模块包含了各种绘图时的配置项,例如设置x轴标签字体大小、是否开启平滑曲线等等。 -
第二行代码
from pyecharts.charts import Pie是将pyecharts库中的Pie模块导入,Pie模块提供了绘制饼状图的功能。 -
第三行代码
from pyecharts.faker import Faker是将pyecharts库中的faker模块导入,faker模块用于生成虚假的数据,这个模块可以在数据不够的时候提供一些测试数据。 -
第四行代码
import pandas as pd是导入pandas库,并取一个别名为pd。pandas库是用于数据分析的重要库,它提供了各种数据处理和操作的工具,比如DataFrame等。这里可能是为了读取数据文件或者进行数据清洗和处理等需要使用到pandas库的操作。
from pyecharts import options as opts
from pyecharts.charts import Pie
from pyecharts.faker import Faker
import pandas as pd三、数据预处理
1.读取数据
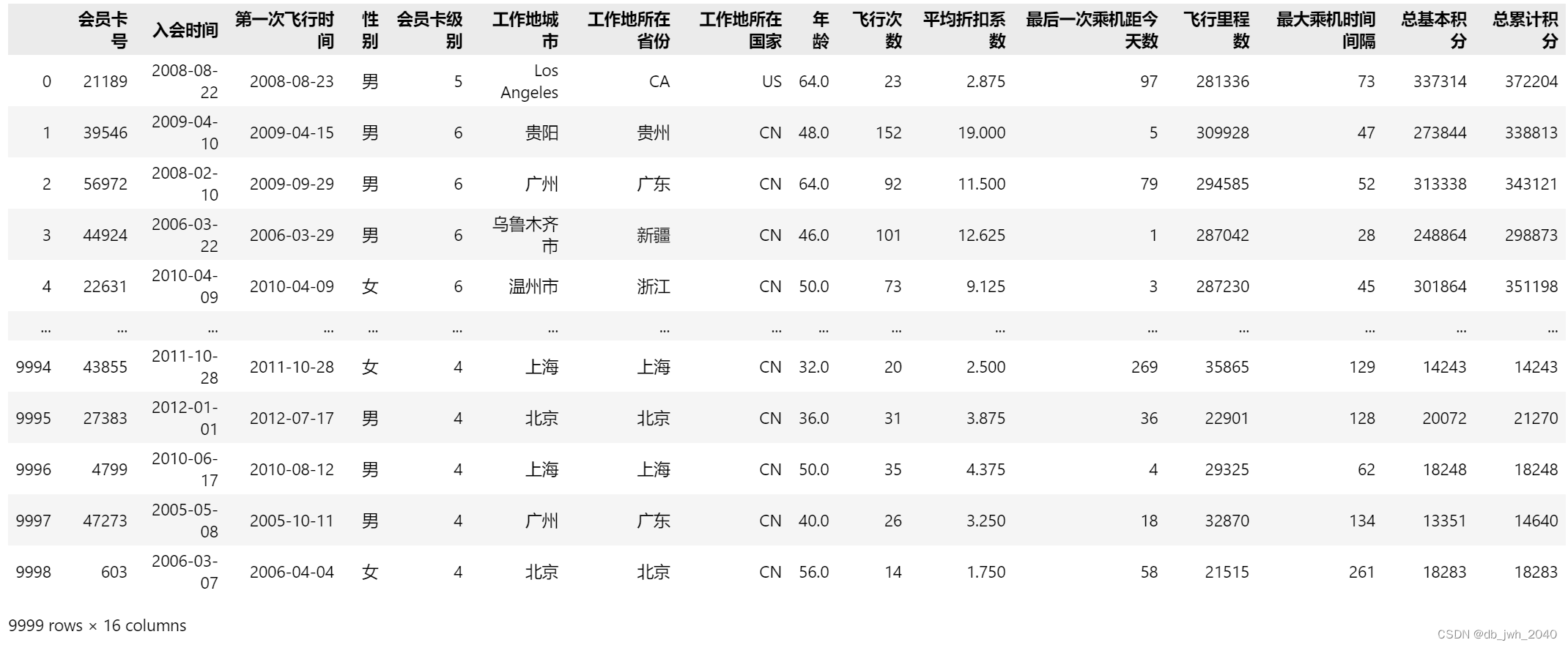
这段代码会读取名为 “航空公司数据.xlsx” 的 Excel 文件,并将数据存储到名为 data 的 pandas DataFrame 对象中。这个DataFrame对象可以像Excel表格一样查看和处理数据。如果你在打印 data 对象时在代码的最后加了 print,那么它将输出这个DataFrame对象的所有内容。如果没有加print,则Jupyter Notebook会默认显示DataFrame对象的前五行数据,后续行省略。可以通过 data.head(n) 来查看前 n 行的数据,或者使用 data.tail(n) 来查看后 n 行的数据。
data = pd.read_excel(r'航空公司数据.xlsx')
data运行结果:
2.构造年龄段序列
方法1:序列的加工 Series.agg(加工函数)
这段代码定义了一个叫做 age_range 的函数,它的作用是根据传入的一个年龄参数,返回这个年龄所属的年龄段。
接下来的一行代码 data['年龄段'] = data['年龄'].agg(age_range) 表示将DataFrame中的’年龄’这一列传入函数 age_range 中,并将返回值存储在一个新的列’年龄段’中。
最后的 data 表示输出经过处理后的原始数据 data,新增了一列’年龄段’用于表明每个人属于哪个年龄段。
def age_range(age):
if age<20:
return '少年'
elif age<40:
return '青年'
elif age<60:
return '中年'
else:
return '老年'
data['年龄段'] = data['年龄'].agg(age_range)
data方法2:通过pd.cut()函数实现分箱
这段代码使用 pandas 库的 cut() 函数将’年龄’一列按照预设的分组分为4组,分组规则是按照0-20、20-40、40-60、60-100进行分组,每个组对应的标签为少年、青年、中年、老年。具体而言,该函数会将一个 Series 或者数组按照指定的区间分组,并为每个区间指定对应的标签或者类别。
其中,bins参数是分组区间列表,labels参数是每个区间对应的标签,data['年龄'] 是指对’年龄’这一列进行分组操作。最后将结果赋值给新的列’年龄段’,即 data['年龄段'],表示每个人属于哪个年龄段。
data['年龄段'] = pd.cut(data['年龄'],bins=[0,20,40,60,100],labels=['少年','青年','中年','老年'])
data 运行结果: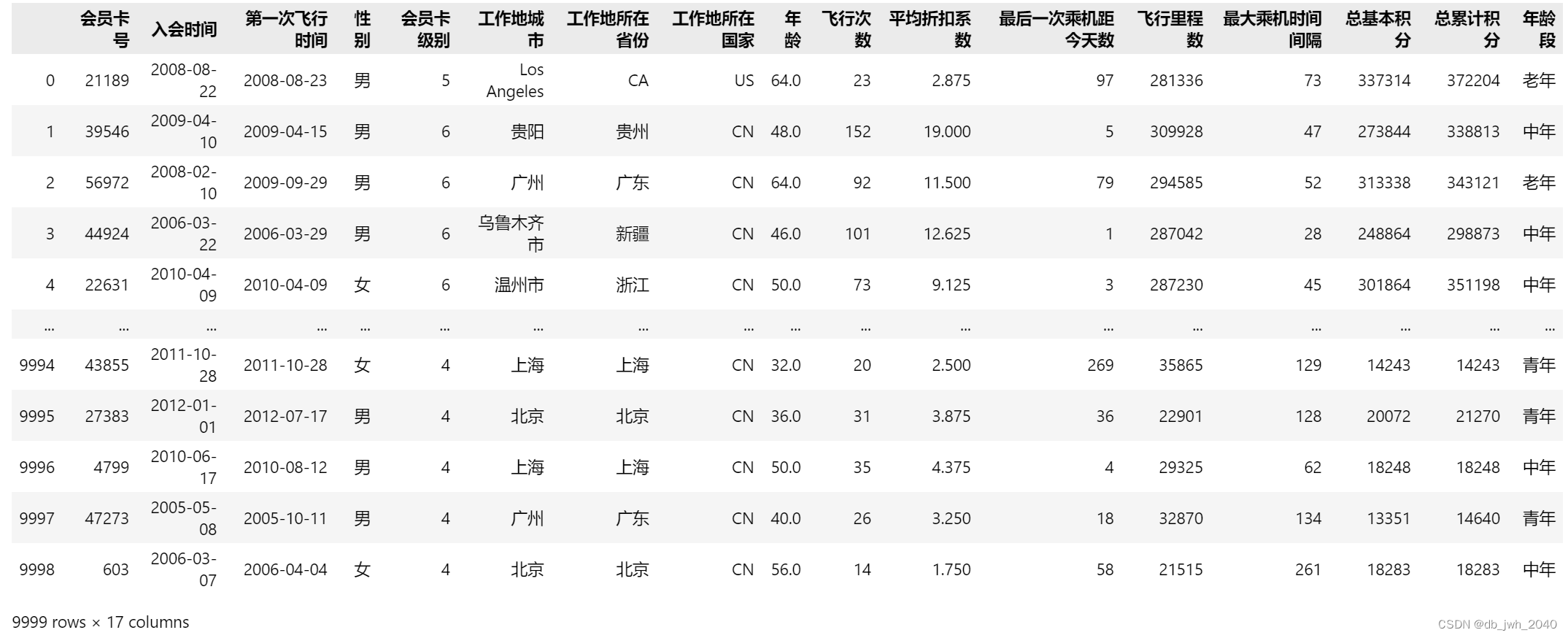
3.统计各年龄段人数
这段代码使用 pandas 库的 groupby() 方法对 ‘年龄段’ 这一列进行分组,然后分别统计了各个年龄段的数量。by='年龄段' 表示按照’年龄段’这一列进行分组,并返回各个分组中’年龄’这一列的计数。
后续的 ['年龄'].count() 表示对分组后的’年龄’这一列进行计数操作,统计每个年龄段中’年龄’这一列的数值个数。最后将结果存储在 result 变量中,并输出结果。
result = data.groupby(by='年龄段')['年龄'].count()
result运行结果:

4.数据类型改造
这段代码创建了一个名为 list 的列表,通过遍历 result 对象,将每个年龄段对应的计数值转化成列表中的元素。具体而言,代码中的列表推导式 [x,int(y)] for x,y in zip(result.index, result.values)] 遍历了 result 对象的索引和值,将它们对应的年龄段和计数值打包成一个二元组,其中 x 表示年龄段,y表示计数值。
在将二元组打包成列表时,通过 int() 将计数值的类型转化为整数类型,避免后续处理时出现错误。最终,该列表中的每个元素都是一个列表,其中第一个元素是年龄段,第二个元素是该年龄段计数值。
list = [[x,int(y)] for x,y in zip(result.index, result.values)]
list 运行结果: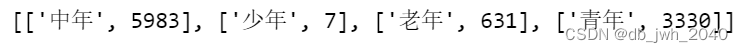
四、画图
玫瑰图
在饼图的基础上,每一块饼的半径表示该区域的数据大小。
玫瑰图代码
这段代码使用 pyecharts 库绘制了一个玫瑰图,数据源是前面处理后的年龄段及其对应的计数值列表 list。
首先,在 Pie() 方法中使用 InitOpts() 设置绘图区域的宽度和高度。然后,使用 add() 方法添加一个系列 ‘年龄段’,并指定 data_pair 参数为前面输出的 list 列表。radius 参数指定了玫瑰图的内径和外径,这里设置为 “20%” 到 “40%”,即中心的百分之二十到四十的位置之间,表示绘制的是一个空心环状玫瑰图。
接着,使用 LabelOpts() 方法为标签设置格式,包括重命名数据名称为 “年龄段”,同时设置标签内容格式为 “{a}:{b}\n个数:{c}\n占比:{d}%”,表示在标签上输出年龄段及其对应的数值和占比。
最后,使用 set_colors() 方法设置玫瑰图的配色方案,使用 set_global_opts() 方法为图表设置全局参数,包括设置主标题 title、图例样式 legend_opts、图示位置,然后调用 render_notebook() 方法将图表渲染出来并在 Jupyter Notebook 中显示。
c = (
Pie(init_opts=opts.InitOpts(width="600px", height="400px")) # 设置背景的大小
.add(
series_name = "年龄段", # 必须项
data_pair = list,
radius=["20%", "40%"], # 设置环的大小
# center=["20%", "50%"], # 设置饼图的位置
rosetype="radius", # 设置玫瑰图类型
label_opts=opts.LabelOpts(formatter="{a}:{b}\n个数:{c}\n占比:{d}%"), # 设置标签内容格式
)
.set_colors(["blue", "green", "yellow", "red"]) # 颜色设置
.set_global_opts(title_opts=opts.TitleOpts(title="Pie-玫瑰图示例"),
legend_opts=opts.LegendOpts(pos_top="10%", pos_left="25%"), # 设置图示的位置
)
)
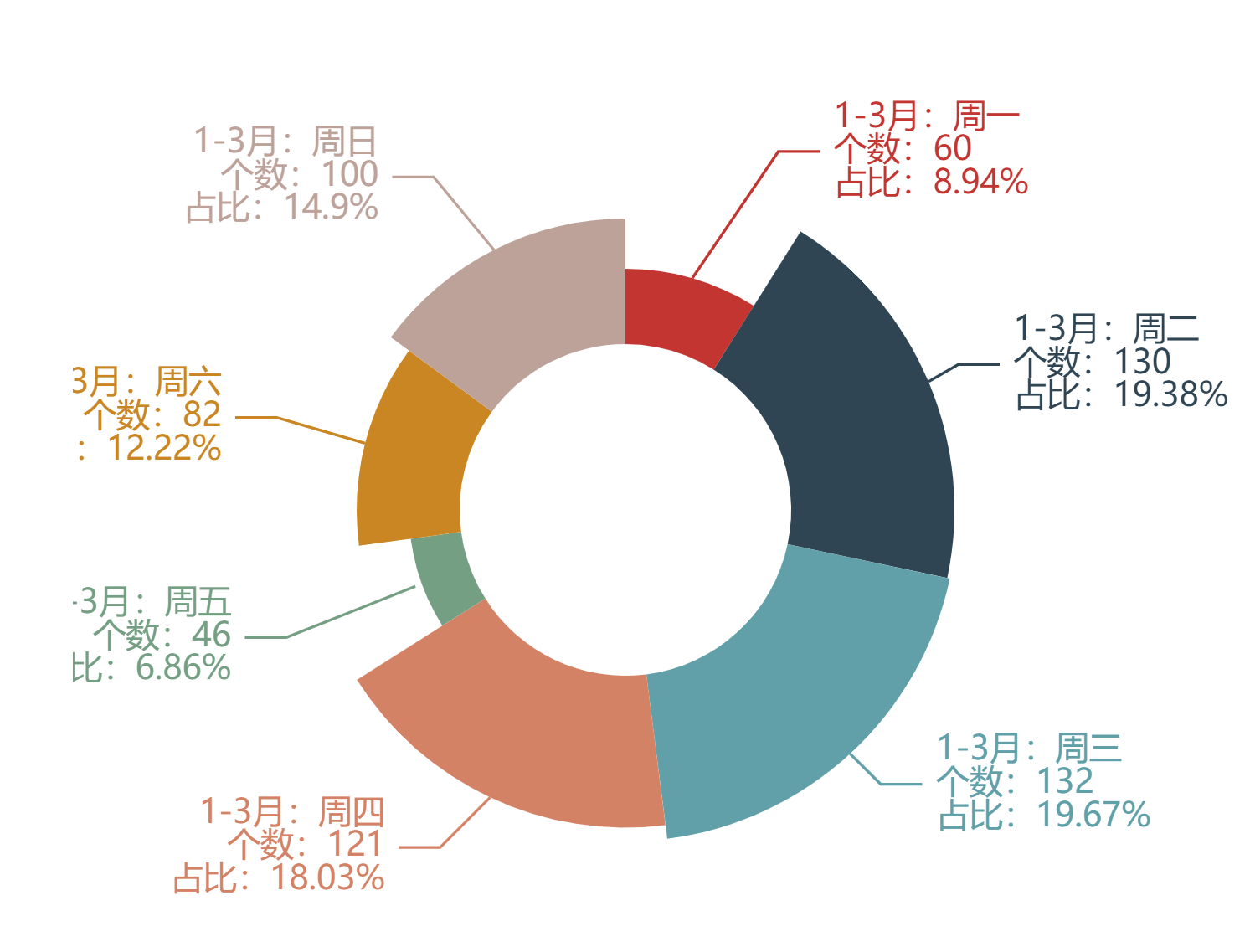
c.render_notebook()运行结果:
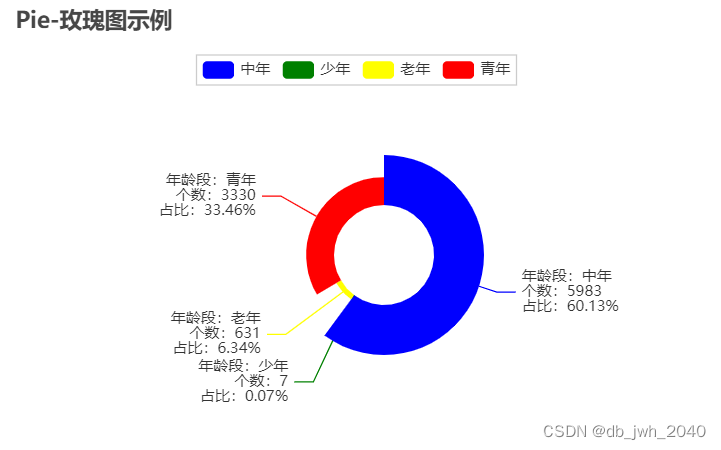
通过画出的玫瑰图看到,中年人数量最多占了航空公司用户数量的百分之六十,而且少年数量最少才占了航空公司用户数量不到百分之一。
五、完整代码
# 导入必要的库
from pyecharts import options as opts
from pyecharts.charts import Pie
from pyecharts.faker import Faker
import pandas as pd
# 读取文件数据
data = pd.read_excel(r'航空公司数据.xlsx')
# 构造年龄段序列
# 方法1:序列的加工 Series.agg(加工函数)
# def age_range(age):
# if age<20:
# return '少年'
# elif age<40:
# return '青年'
# elif age<60:
# return '中年'
# else:
# return '老年'
# data['年龄段'] = data['年龄'].agg(age_range)
# 方法2:通过pd.cut()函数实现分箱
data['年龄段'] = pd.cut(data['年龄'],bins=[0,20,40,60,100],labels=['少年','青年','中年','老年'])
# 统计各年龄段人数
result = data.groupby(by='年龄段')['年龄'].count()
# 数据类型改造
list = [[x,int(y)] for x,y in zip(result.index, result.values)]
# 画图
c = (
Pie(init_opts=opts.InitOpts(width="600px", height="400px")) # 设置背景的大小
.add(
series_name = "年龄段", # 必须项
data_pair = list,
radius=["20%", "40%"], # 设置环的大小
# center=["20%", "50%"], # 设置饼图的位置
rosetype="radius", # 设置玫瑰图类型
label_opts=opts.LabelOpts(formatter="{a}:{b}\n个数:{c}\n占比:{d}%"), # 设置标签内容格式
)
.set_colors(["blue", "green", "yellow", "red"]) # 颜色设置
.set_global_opts(title_opts=opts.TitleOpts(title="Pie-玫瑰图示例"),
legend_opts=opts.LegendOpts(pos_top="10%", pos_left="25%"), # 设置图示的位置
)
)
c.render_notebook()总结
以上就是今天要讲的内容,本文仅仅简单介绍了用Pyecharts实现航空公司用户年龄段分布玫瑰图的实现方法,而Pyecharts提供了大量有的图表还有高度灵活的配置项,可轻松搭配出精美的图表。