一、朴素贝叶斯算法
1、什么是朴素贝叶斯分类方法
之前用KNN算法,分类完直接有个结果,但是朴素贝叶斯分完之后会出现一些概率值,比如:
这六个类别,它都有一定的可能性
再比如,对文章进行分类: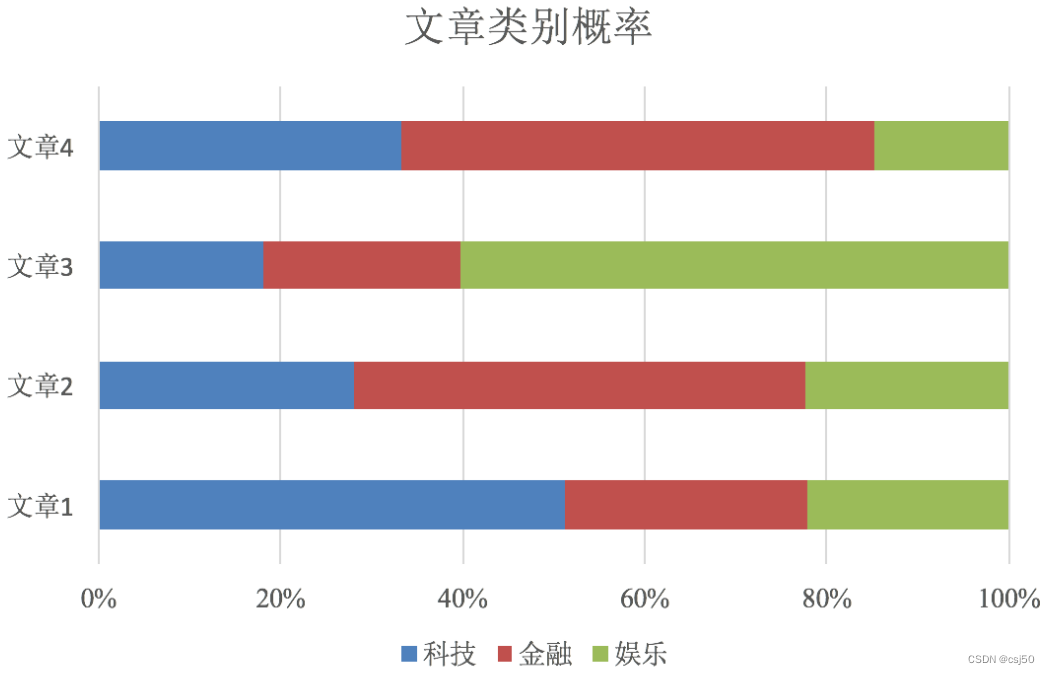
分类为三个类别,对每个样本用朴素贝叶斯分类之后,会得到这样的结果,会取概率比较大的作为最终的结果
二、概率基础
1、概率(probability)定义
概率定义为一件事情发生的可能性
比如:扔出一个硬币,结果头朝上概率是多少
2、取值范围
P(X):取值在[0, 1]
如果取值为0,是不可能事件。如果取值为1,是必然事件
3、女神是否喜欢计算案例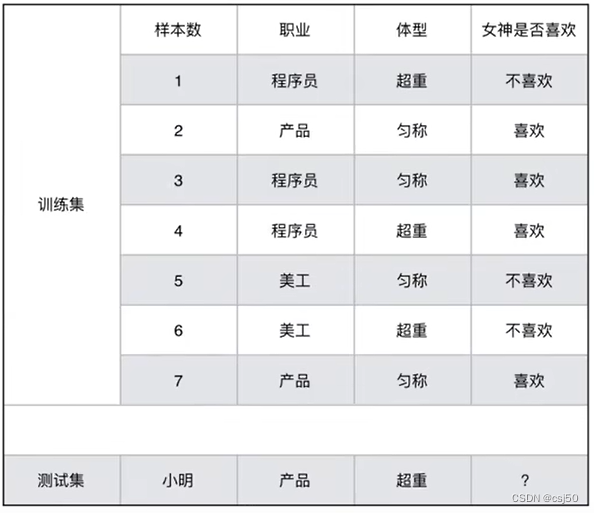
已知小明是产品经理,体重超重,是否会被女神喜欢?
特征有两个,职业和体型。目标值就是是否会被女神喜欢,是个二分类问题
4、问题
(1)女神喜欢的概率?
样本有7个,女神喜欢有4个
p(喜欢) = 4/7
(2)职业是程序员并且体型匀称的概率?
P(程序员, 匀称) = 1/7
--联合概率
(3)在女神喜欢的条件下,职业是程序员的概率?
P(程序员 | 喜欢) = 2/4
--条件概率
(4)在女神喜欢的条件下,职业是程序员,体重是超重的概率?
P(程序员, 超重 | 喜欢) = 1/4
--既符合条件概率,也符合联合概率
三、联合概率、条件概率与相互独立
1、联合概率:包含多个条件,且所有条件同时成立的概率
记作:P(A,B)
特性:P(A,B) = P(A)P(B)
例如:P(程序员, 匀称),P(程序员, 超重|喜欢)
2、条件概率:就是事件A在另外一个事件B已经发生条件下的发生概率
记作:P(A|B)
特性:P(A1,A2|B) = P(A1|B)P(A2|B)
例如:P(程序员|喜欢),P(程序员, 超重|喜欢)
3、相互独立:如果P(A,B) = P(A)P(B),则称事件A与事件B相互独立
例子:
在女神是否喜欢数据当中,程序员和匀称是否相互独立?
P(程序员, 匀称) = 1/7
P(程序员) = 3/7
P(匀称) = 4/7
所以程序员和匀称不是相互独立的
4、已知小明是产品经理,体重超重,是否会被女神喜欢?
目标是求:P(喜欢|产品, 超重) = ?
这时候就要用到贝叶斯公式
四、贝叶斯公式
1、公式
注:W为特征值,C为类别
2、解决小明的问题
分子:P(产品, 超重|喜欢) * P(喜欢)
分母:P(产品, 超重)
什么是朴素:加上了假设,特征与特征之间是相互独立的
P(产品, 超重) = P(产品) * P(超重)
上式中,P(产品, 超重|喜欢)和P(产品, 超重)的结果均为0,导致无法计算结果。这是因为我们的样本量太少了,不具有代表性,本来现实生活中,肯定是存在职业是产品经理并且体重超重的人的,P(产品, 超重)不可能为0;而且事件“职业是产品经理”和事件“体重超重”通常被认为是相互独立的事件
而朴素贝叶斯可以帮助我们解决这个问题
朴素贝叶斯,简单理解,就是假定了特征与特征之间相互独立的贝叶斯公式
也就是说,朴素贝叶斯,之所以朴素,就在于假定了特征与特征相互独立
所以,思考题如果按照朴素贝叶斯的思路来解决,就可以是:
P(产品, 超重) = P(产品) * P(超重) = 2/7 * 3/7 = 6/49
P(产品, 超重|喜欢) = P(产品|喜欢) * P(超重|喜欢) = 1/2 * 1/4 = 1/8
P(喜欢) = 4/7
分子 / 分母 = (1/8) * (4/7) / (6/49) = 196/336 = 7/12
五、朴素贝叶斯算法小结
1、KNN算法可以用一句话根据我的邻居,来判断我的类别
2、朴素贝叶斯算法 = 朴素 + 贝叶斯公式
六、应用场景
1、朴素贝叶斯特点就是假设特征与特征之间是相互独立的,经常用在文本分类、文本情感分析中
2、因为要把文章转换为能够被机器学习可以处理的数据,是以单词作为特征
3、一般把词作为特征,有一个假设,词与词之间是相互独立的
七、对文本分类的案例
1、案例
2、公式

3、计算结果
(1)P(C|Chinese, Chinese, Chinese, Tokyo, Japan)
当文章中有这5个词的时候,文章属于China类的概率是多少
分子:P(Chinese, Chinese, Chinese, Tokyo, Japan|C) * P(C)
分母:P(Chinese, Chinese, Chinese, Tokyo, Japan)
实际只要求分子就可以了,分母一样
P(C) = 3/4
P(Chinese|C)^3 * P(Tokyo|C) * P(Japan|C)
P(Chinese|C) = 5/8
P(Tokyo|C) = 0/8 (出现0,原因样本量太少,需要引入拉普拉斯平滑系数)
运用拉普拉斯平滑系数后:
P(Chinese|C) = (5+1) / (8+1*6) = 6/14 = 3/7
P(Tokyo|C) = (0+1) / (8+1*6) = 1/14
P(Japan|C) = (0+1) / (8+1*6) = 1/14
(3/7)^3 * 1/14 * 1/14 = 27/343 * 1/14 * 1/14 = 27/67228 = 0.0004016183732968406
(2)P(非C|Chinese, Chinese, Chinese, Tokyo, Japan)
文章不属于China类的概率大小
分子:P(Chinese, Chinese, Chinese, Tokyo, Japan|非C) * P(非C)
分母:P(Chinese, Chinese, Chinese, Tokyo, Japan)
实际只要求分子就可以了,分母一样
P(非C) = 1/4
P(Chinese|非C)^3 * P(Tokyo|非C) * P(Japan|非C)
运用拉普拉斯平滑系数后:
P(Chinese|非C) = (1+1) / (3+1*6) = 2/9
P(Tokyo|非C) = (1+1) / (3+1*6) = 2/9
P(Japan|非C) = (1+1) / (3+1*6) = 2/9
(2/9)^3 * 2/9 * 2/9 = 32/59049 = 0.0005419228098697692
(3)综合来看,非C的概率大于C的概率,所以测试集不属于China类别
八、拉普拉斯平滑系数
1、目的
防止计算出的分类概率为0
2、公式
九、API
1、sklearn.naive_bayes.MultinomialNB(alpha = 1.0)
朴素贝叶斯分类
alpha:拉普拉斯平滑系数
十、案例:20类新闻分类
1、数据
2、步骤分析
(1)获取数据
(2)划分数据集
(3)特征工程
文本特征抽取
(4)朴素贝叶斯预估器流程
(5)模型评估
3、代码
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import GridSearchCV
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
def KNN_iris():
"""
用KNN算法对鸢尾花进行分类
"""
# 1、获取数据
iris = load_iris()
print("iris.data:\n", iris.data)
print("iris.target:\n", iris.target)
# 2、划分数据集
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=6)
# 3、特征工程:标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
# 用训练集的平均值和标准差对测试集的数据来标准化
# 这里测试集和训练集要有一样的平均值和标准差,而fit的工作就是计算平均值和标准差,所以train的那一步用fit计算过了,到了test这就不需要再算一遍自己的了,直接用train的就可以
x_test = transfer.transform(x_test)
# 4、KNN算法预估器
estimator = KNeighborsClassifier(n_neighbors=3)
estimator.fit(x_train, y_train)
# 5、模型评估
# 方法1:直接比对真实值和预测值
y_predict = estimator.predict(x_test)
print("y_predict:\n", y_predict)
print("直接比对真实值和预测值:\n", y_test == y_predict)
# 方法2:计算准确率
score = estimator.score(x_test, y_test)
print("准确率为:\n", score)
return None
def KNN_iris_gscv():
"""
用KNN算法对鸢尾花进行分类,添加网格搜索和交叉验证
"""
# 1、获取数据
iris = load_iris()
print("iris.data:\n", iris.data)
print("iris.target:\n", iris.target)
# 2、划分数据集
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=6)
# 3、特征工程:标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
# 用训练集的平均值和标准差对测试集的数据来标准化
# 这里测试集和训练集要有一样的平均值和标准差,而fit的工作就是计算平均值和标准差,所以train的那一步用fit计算过了,到了test这就不需要再算一遍自己的了,直接用train的就可以
x_test = transfer.transform(x_test)
# 4、KNN算法预估器
estimator = KNeighborsClassifier()
# 加入网格搜索和交叉验证
# 参数准备
param_dict = {"n_neighbors": [1, 3, 5, 7, 9, 11]}
estimator = GridSearchCV(estimator, param_grid=param_dict, cv=10)
estimator.fit(x_train, y_train)
# 5、模型评估
# 方法1:直接比对真实值和预测值
y_predict = estimator.predict(x_test)
print("y_predict:\n", y_predict)
print("直接比对真实值和预测值:\n", y_test == y_predict)
# 方法2:计算准确率
score = estimator.score(x_test, y_test)
print("准确率为:\n", score)
#最佳参数:best_params_
print("最佳参数:\n", estimator.best_params_)
#最佳结果:best_score_
print("最佳结果:\n", estimator.best_score_)
#最佳估计器:best_estimator_
print("最佳估计器:\n", estimator.best_estimator_)
#交叉验证结果:cv_results_
print("交叉验证结果:\n", estimator.cv_results_)
return None
def nb_news():
"""
用朴素贝叶斯算法对新闻进行分类
"""
# 1、获取数据
news = fetch_20newsgroups(subset="all")
# 2、划分数据集
x_train, x_test, y_train, y_test = train_test_split(news.data, news.target)
# 3、特征工程:文本特征抽取-tfidf
transfer = TfidfVectorizer()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4、朴素贝叶斯算法预估器流程
estimator = MultinomialNB()
estimator.fit(x_train, y_train)
# 5、模型评估
# 方法1:直接比对真实值和预测值
y_predict = estimator.predict(x_test)
print("y_predict:\n", y_predict)
print("直接比对真实值和预测值:\n", y_test == y_predict)
# 方法2:计算准确率
score = estimator.score(x_test, y_test)
print("准确率为:\n", score)
return None
if __name__ == "__main__":
# 代码1:用KNN算法对鸢尾花进行分类
#KNN_iris()
# 代码2:用KNN算法对鸢尾花进行分类,添加网格搜索和交叉验证
#KNN_iris_gscv()
# 代码3:用朴素贝叶斯算法对新闻进行分类
nb_news()4、运行结果
y_predict:
[11 17 15 ... 9 2 4]
直接比对真实值和预测值:
[ True True True ... True True True]
准确率为:
0.8497453310696095十一、朴素贝叶斯算法小结
1、优点
朴素贝叶斯模型发源于古典数学理论,有稳定的分类效率
对缺失数据不太敏感,算法也比较简单,常用于文本分类
分类准确度高,速度快
2、缺点
由于使用了样本属性独立性的假设,所以如果特征属性有关联时其效果不好