朴素贝叶斯分类器,听起来挺玄乎的名字,但是学过概率的同学们就知道,其本质就是条件概率的扩展。而且其实原理还是挺简单的。
一、原理详解
贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类。而朴素朴素贝叶斯分类是贝叶斯分类中最简单,也是常见的一种分类方法。
说白了,贝叶斯就是比较两个类别之间的所属概率,谁的概率的大,自然就归为哪一类。
很多书上此刻就会写上很多的概率公式,我们不急。用一个例子,完全理解朴素贝叶斯,而且还完成一个监督学习分类模型的任务。
任务:根据一组数据,判断一个学生考试挂不挂科。(简单的分类任务,两类,是否挂科是标签目标)
那么咱们就来看看这样的一组数据到底有哪些特征组成。
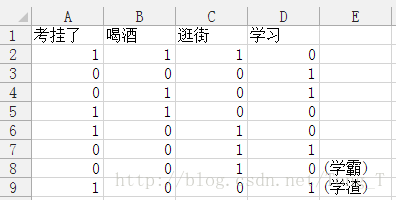
在样本中,考试挂科与考前去喝酒、考前去逛街、考前学习三个特征变量相关。
我们用1表示特征的肯定性,而0代表特征的否定性。
现在可以给一个具体的测试数据来判断预测他到底会不会挂科。
数据是: 没喝酒(0),没逛街(0),学习了(1)。
START !
先简单做下小变化:
A = 挂科
B = 喝酒
C = 逛街
D = 学习
来计算一下基本的单一概率:

基本上我们每个人都会计算这样的概率。再来看看条件概率:

看着这三个概率,明显感觉有多元因素影响我们判断,概率不再是单一的感觉,而是由很多部分相互管理的概率。
这样就可以提出贝叶斯公式了:

两个条件概率公式,一整合就是贝叶斯公式,看来这个贝叶斯还真会偷懒。玩笑!,那具体有什么应用呢,能拿它干什么呢?那当然就是用它来对我们的样本求概率,然后分类呀。
进入分类阶段了,但我们需要对数据做点变换,增加特征变量名字:
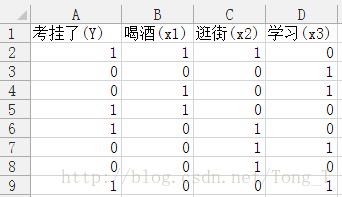

这里面提到了马尔科夫假设,其实马尔科夫这人对统计学的贡献还真不小,哪都有他。
具体的理论,我找个时间,自己专研一下,在写出来分享。
这里就可以理解为: 一个过程,下一状态只与当前状态有关,与之前状态无关,所以约等于各个条件概率相乘。
所以基本上又是四张图理解一种算法。
其中大家还要注意:朴素贝叶斯算法是假设各个特征之间相互独立,那么这个等式就成立了!朴素因此而来。
在机器学习中,我们都假设各个特征相互独立,在数学上,如果不相互独立,贝叶斯公式就是错误的。
理论还有什么不懂,http://blog.csdn.net/amds123/article/details/70173402这篇文章也许能帮到你。
二、原生代码实现
数据集选取iris数据集,来源与sklearn库中:
from sklearn import datasets
import numpy as np
class NaiveBayesClassifier(object):
def __init__(self):
self.data = []
self.label = []
self.p_label = {}
self.p_num = {}
def load_dataset(self):
iris = datasets.load_iris()
self.data = iris.data
self.label = iris.target
label_set = set(iris.target)
label_list = [i for i in label_set]
label_num = len(label_list)
for i in range(label_num):
self.p_label.setdefault(label_list[i])
self.p_label[label_list[i]] = np.sum(self.label == label_list[i]) / float(len(self.label))
def seperate_by_class(self):
seperated = {}
for i in range(len(self.data)):
vector = self.data[i]
if self.label[i] not in seperated:
seperated[self.label[i]] = []
seperated[self.label[i]].append(vector)
return seperated
# 通过numpy array二维数组来获取每一维每种数的概率
def get_prob_by_array(self, data):
prob = {}
for i in range(len(data[0])):
if i not in prob:
prob[i] = {}
data_set_list = list(set(data[:, i]))
for j in data_set_list:
if j not in prob[i]:
prob[i][j] = 0
prob[i][j] = np.sum(data[:, i] == j) / float(len(data[:, i]))
prob[0] = [1 / float(len(data[:, 0]))] # 防止feature不存在的情况
return prob
def fit(self):
seperated = self.seperate_by_class()
t_p_num = {} # 存储每个类别下每个特征每种情况出现的概率
for label, data in seperated.items():
if label not in t_p_num:
t_p_num[label] = {}
t_p_num[label] = self.get_prob_by_array(np.array(data))
self.p_num = t_p_num
def predict(self, data):
p_test = np.ones(3)
for i in self.p_label:
for j in self.p_num[i]:
if data[j] not in self.p_num[i][j]:
p_test[i] *= self.p_num[i][0][0]
else:
p_test[i] *= self.p_num[i][j][data[j]]
p_max = np.max(p_test)
ind = np.where(p_test == p_max)
return ind[0][0]
if __name__ == '__main__':
NB = NaiveBayesClassifier()
NB.load_dataset()
NB.fit()
pred = []
right = 0
for d in NB.data:
pred.append(NB.predict(d))
for i in range(len(NB.label)):
if pred[i] == NB.label[i]:
right += 1
print('prediction: ' + str(pred[i]) + ' ==> actual: ' + str(NB.label[i]) + ' ' + str(pred[i] == NB.label[i]))
print(str(right / float(len(NB.label)) * 100) + '%')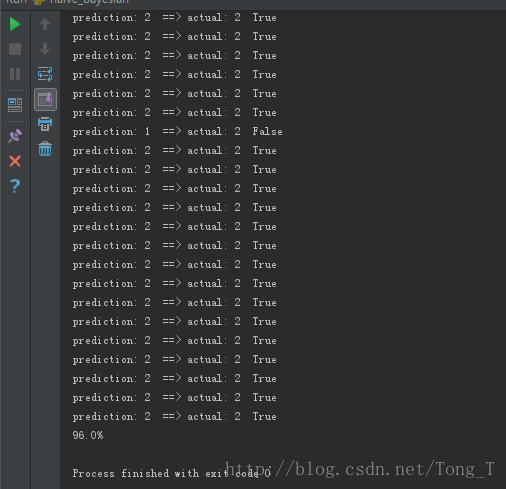
150例识别率达到96%。
三、scikit-learn库代码实现
from sklearn import datasets
from sklearn.naive_bayes import GaussianNB
iris = datasets.load_iris()
gnb = GaussianNB()
gnb.fit(iris.data, iris.target)
prediction = gnb.predict(iris.data)
print("贴错标签的点总共 %d 点数量 : %d" % (
iris.data.shape[0], (iris.target != prediction).sum()))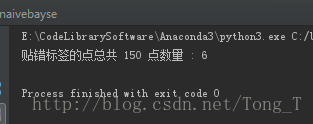
说实话sklearn这个库封装得真是好,更别说什么Tensorflow,keras,caffe这类的框架(用这些框架做贝叶斯感觉有点大材小用了),原谅有时候我甚至都怀疑我做这些学习有什么意义,现成的工具简单到似乎原理已经不那么重要了。哎,继续下一篇SVM吧。这是在神经网络没火之前分类效果最好的算法了。