
论文链接:https://arxiv.53yu.com/pdf/2104.12753.pdf?ref=https://githubhelp.com
代码链接:https://github.com/ChengyueGongR/PatchVisionTransformer
1. 动机
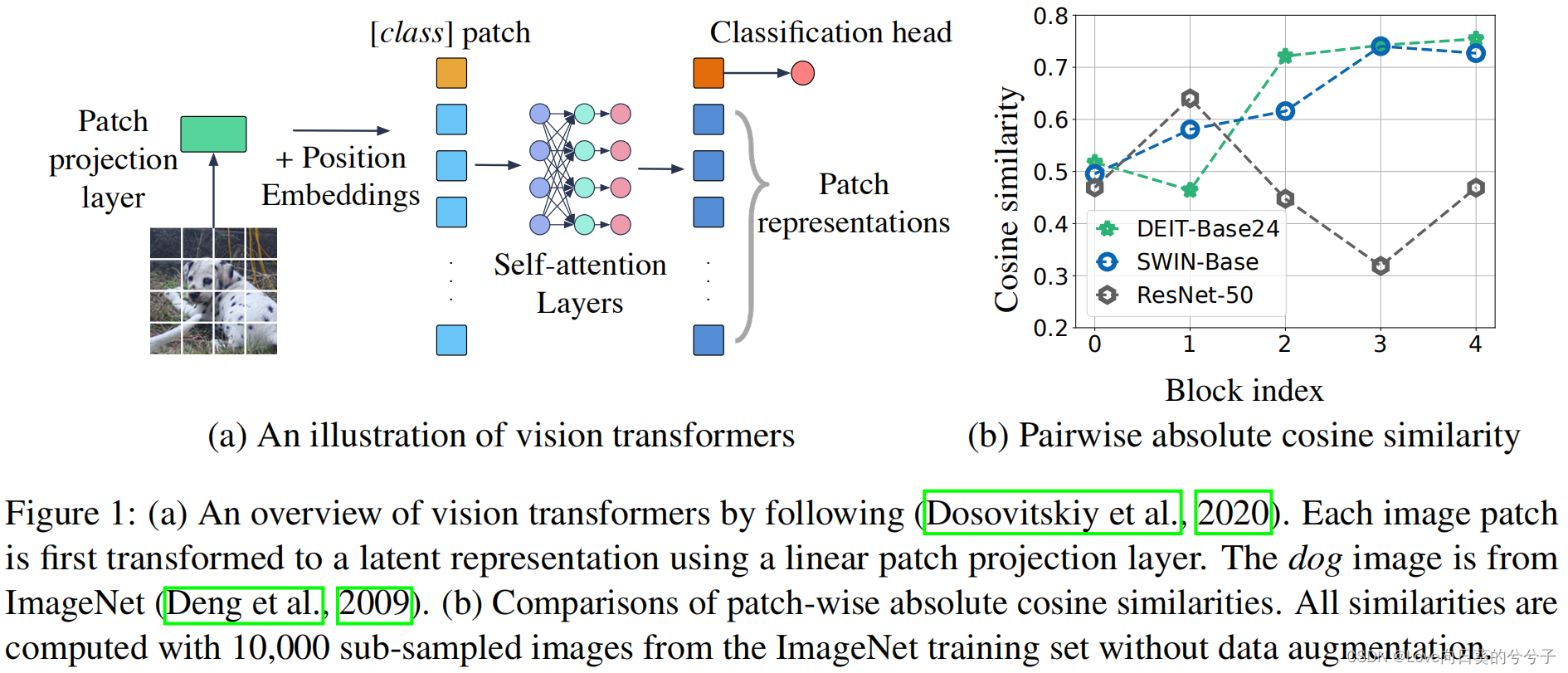
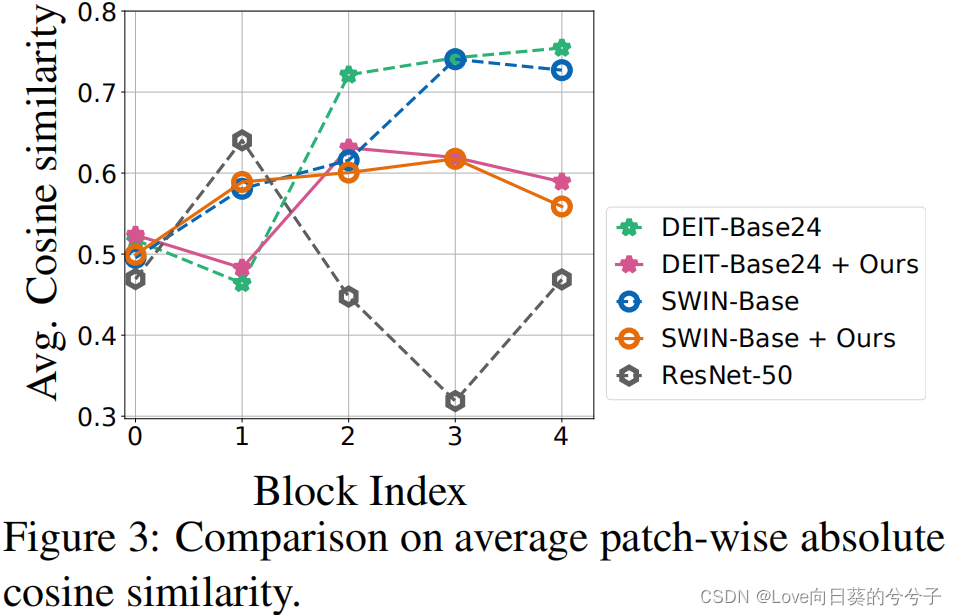
视觉Transformer已在具有挑战性的计算机视觉任务中显示出良好的性能。然而,人们发现视觉Transformer的训练不是特别稳定,尤其当模型变得更宽和更深时。为了研究训练不稳定性的原因,作者在两种流行的视觉Transformer变体(DeiT, Swin-Transformer)上提取每个self-attention层的patch表示,并计算patch表示之间的平均绝对余弦相似性。发现在这两种模型种,patch表示之间相似性显著增加,如上图1(b)所示。这种行为降低了patch表示的整体表达能力,降低了强大的视觉transformer的学习能力。更具体地说,对于深度视觉Transformer来说,self-attention模块倾向于将不同的patch映射成相似的潜在表示,从而导致信息丢失和性能下降。(与论文《REVISITING OVER-SMOOTHING IN BERT FROM THE PERSPECTIVE OF GRAPH》待解决问题很相似,只是解决问题的方式不同)
注意:如果输入patch表征序列为 h = [ h c l a s s , h 1 , ⋯ , h n ] h=[h_{class}, h_1, \cdots, h_n] h=[hclass,h1,⋯,hn],则绝对余弦相似性计算公式如下(这里忽略了class patch),
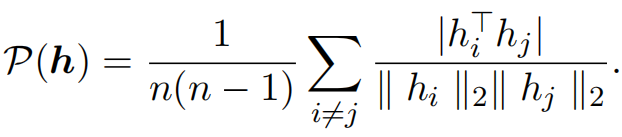
2. 方法
为了缓解上述问题,本文在视觉Transformer训练中没有对任何模型框架的进行修改,只引入了新的损失函数,以显式地鼓励不同的patch表示形式,从而更有区别地提取特征。具体地,本文提出三种不同损失,即
1)Patch-wise cosine loss:通过惩罚patch-wise余弦相似性来直接提高不同patch表示之间的多样性
2)Patch-wise contrastive loss:一种基于patch的对比损失,以鼓励第一层和后续层之间学习到的相对应patch之间的表示相似,不对应的patch之间的表示不同。(这是因为作者观察发现第一个self-attention层的输入patch表示只依赖于输入像素,因此往往更加多样化)
3)Patch-wise mixing loss:一种patch-wise混合损失,与cutmix相似。混合来自两张不同图像的输入patch,并使用从每张图像中学习到的patch表示来预测其相应的类标签。在该损失的情况下,迫使self-attention层只关注与自己类别最相关的patch,从而学习到更多有区别的特征。
-
Patch-wise cosine loss
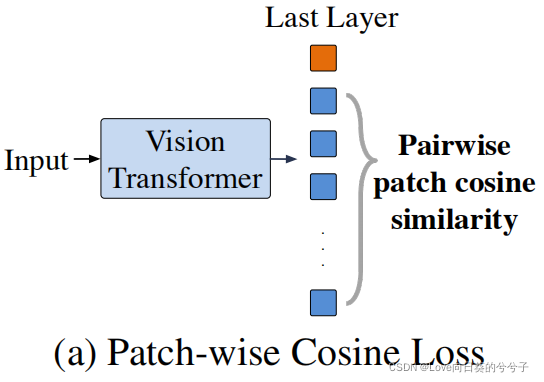
作为一个直接的解决方案,提出直接最小化不同patch表示之间的余弦相似度绝对值,如上图(a)。给定输入 x x x的最后一层patch表示 h [ L ] h^{[L]} h[L],向训练目标添加一个patch-wise余弦损失:
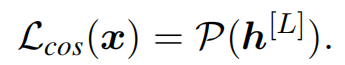
这种正则化损失显式地最小化了不同patch之间的成对余弦相似度,可以看作是最小化$$h的最大特征值的上界,从而改善了表征的表达性。 -
Patch-wise contrastive loss
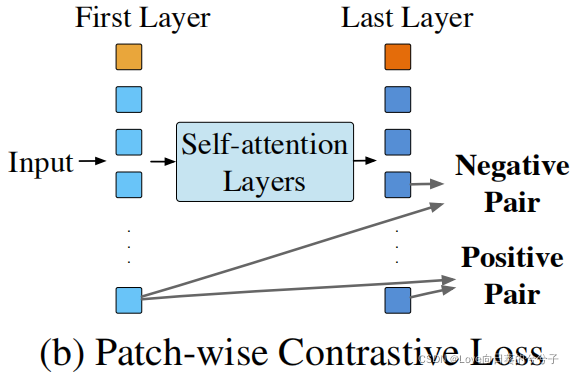
早期层学习到的表示比在更深层学习到的表示更加多样化。因此,提出了一种对比损失,使用早期层的表示,并正则化更深层的patch,以减少patch表征的相似性。具体地,给定输入图像 x x x, h [ 1 ] = { h i [ 1 ] } i h^{[1]}=\{ h^{[1]}_i \}_i h[1]={ hi[1]}i和 h [ L ] = { h i [ L ] } i h^{[L]}=\{ h^{[L]}_i \}_i h[L]={ hi[L]}i分别表示第一层和最后一层的patch,我们约束每个 h i [ L ] h^{[L]}_i hi[L]和 h i [ 1 ] h^{[1]}_i hi[1]相似,和其他任何patch h j ≠ i [ 1 ] h^{[1]}_{j \neq i} hj=i[1],即
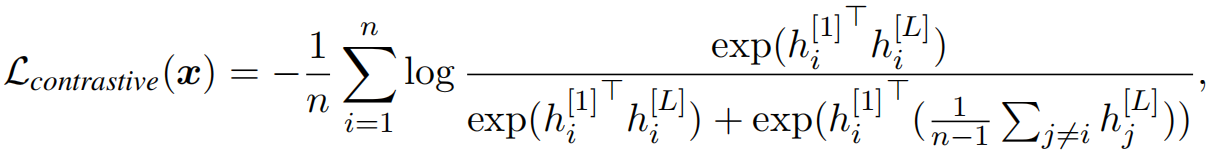
实验中,停止了h^{[1]}$的梯度。 -
Patch-wise mixing loss
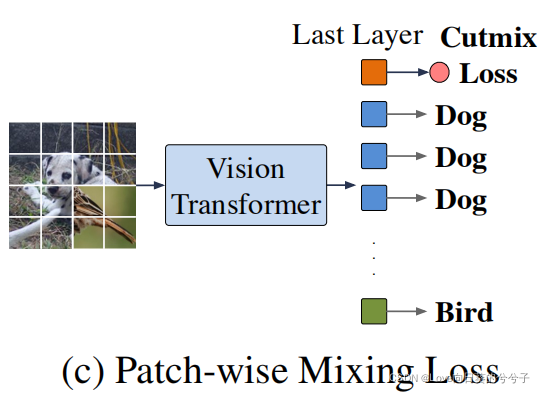
建议训练每个patch来预测类别标签,而不是仅仅使用类patch进行最终预测。这可以与Cutmix的数据增强相结合,为视觉Transformer提供额外的训练信号。如图 ©所示,将来自两张不同图像的输入patch混合,并在每个输出patch表示上附加一个共享的线性分类头进行分类。混合损失迫使每个patch只关注来自相同输入图像的patch子集,忽略不相关的patch。因此,它有效地阻止了不同patch之间的简单平均,以产生更有信息和有用的patch表示。该patch的混合损失可表示为
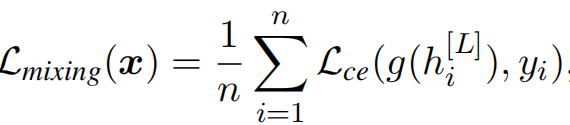
这里 h i [ L ] h^{[L]}_i hi[L]表示最后一层的patch表示,g为附加的线性分类头, y i y_i yi表示patch-wise类标签, L c e \mathcal{L}_{ce} Lce表示交叉熵损失。
最后,通过简单地联合最小化 α 1 L c o s + α 2 L c o n t r a s t + α 3 L m i x i n g \alpha_1 \mathcal{L}_{cos} + \alpha_2 \mathcal{L}_{contrast} + \alpha_3 \mathcal{L}_{mixing} α1Lcos+α2Lcontrast+α3Lmixing的加权组合来改进视觉Transformer的训练。不需要任何网络修改,同时也不局限于任何特定的架构。在实验中,本文简单地设置α1 = α2 = α3 = 1,没有任何特定的超参数调整。
3. 部分实验结果
- 图像分类结果
1) ImageNet库
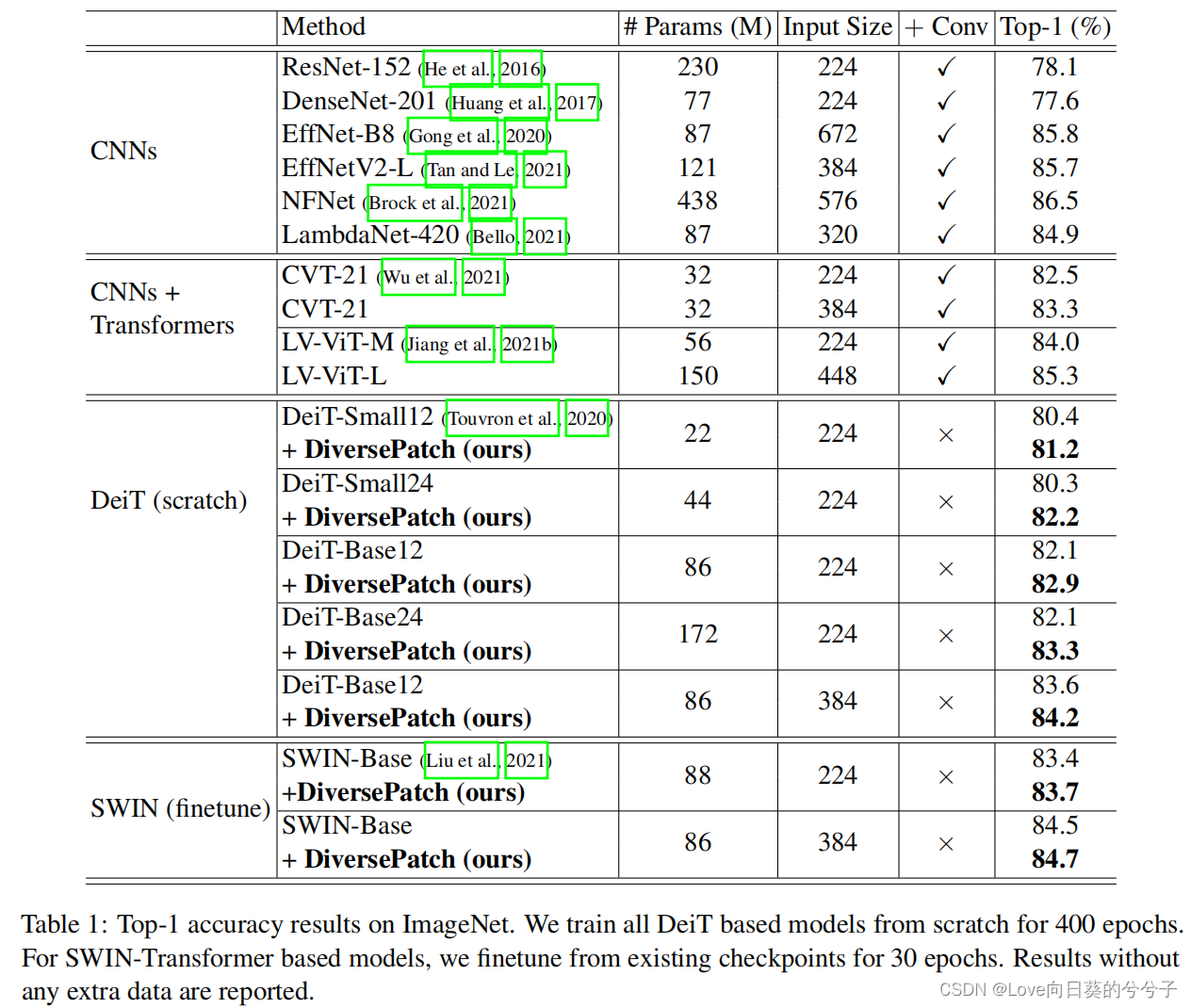
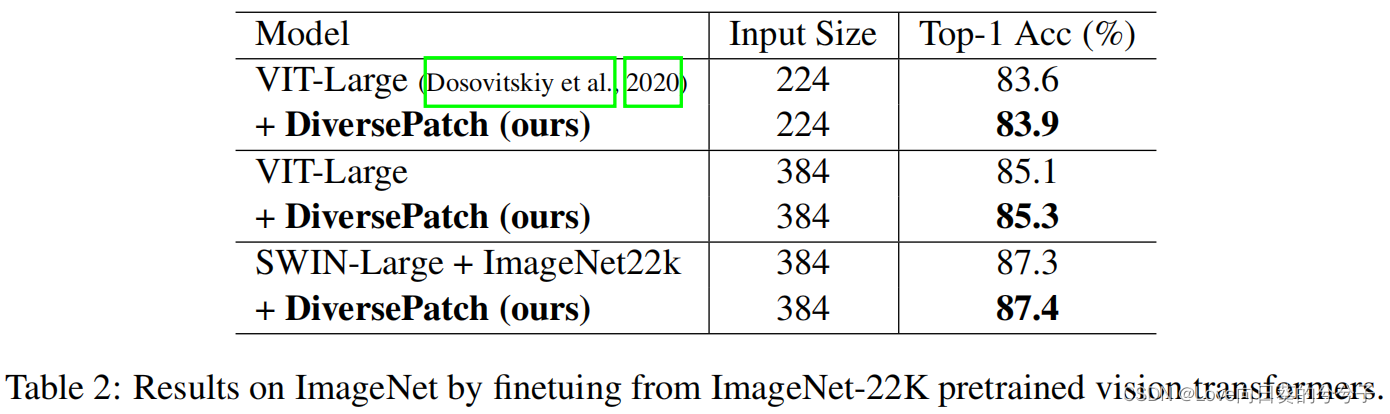
2)ImageNet-22K库
- 语义分割的迁移学习结果
1)ADE20K库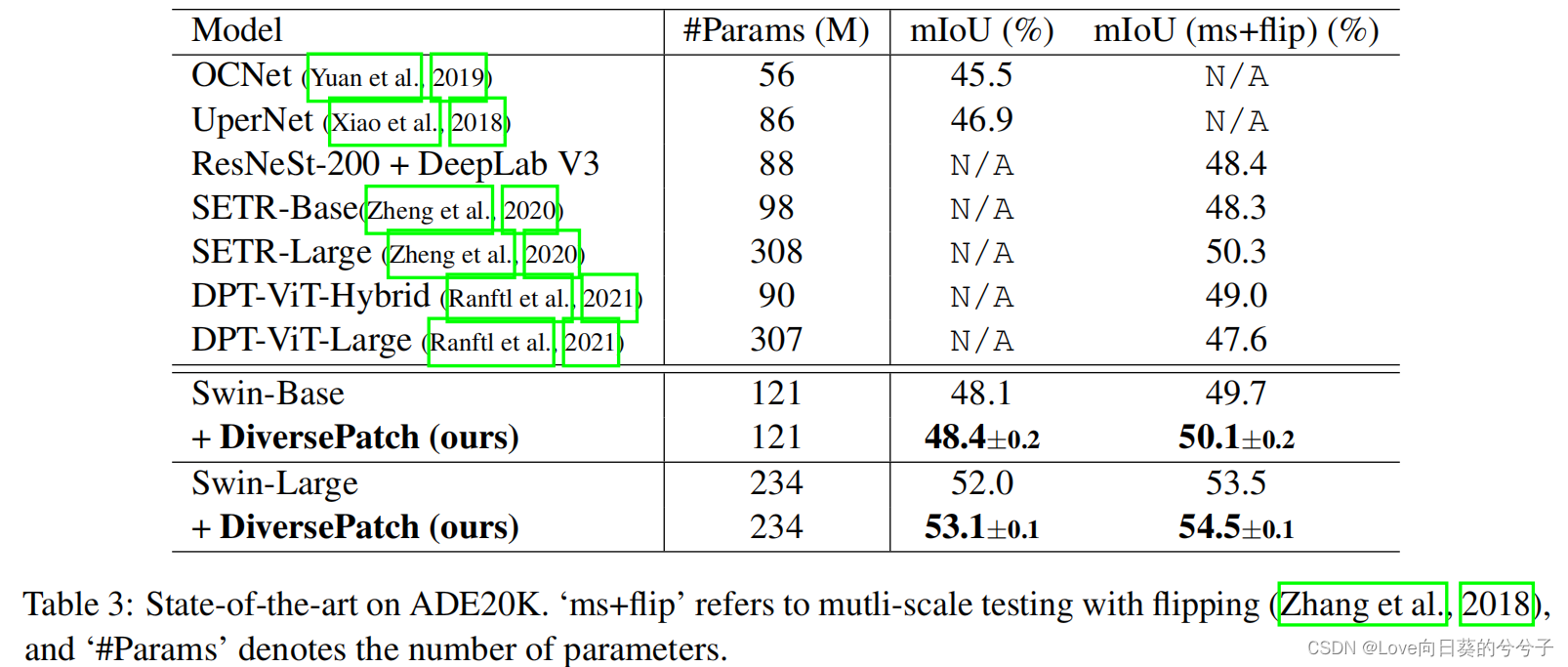
2) Cityscapes库
- 平均patch绝对余弦相似度对比(ImageNet库)
- 消融实验
1)正规化策略的有效性
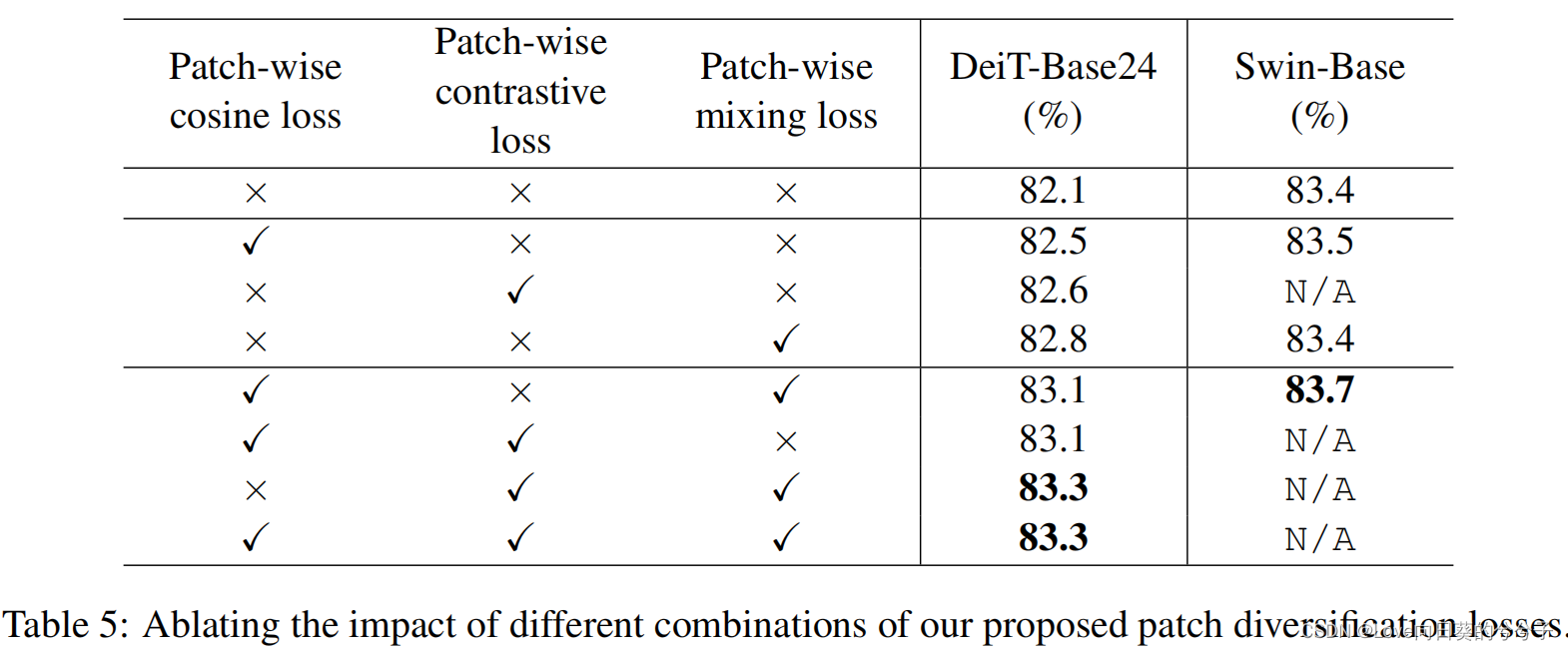
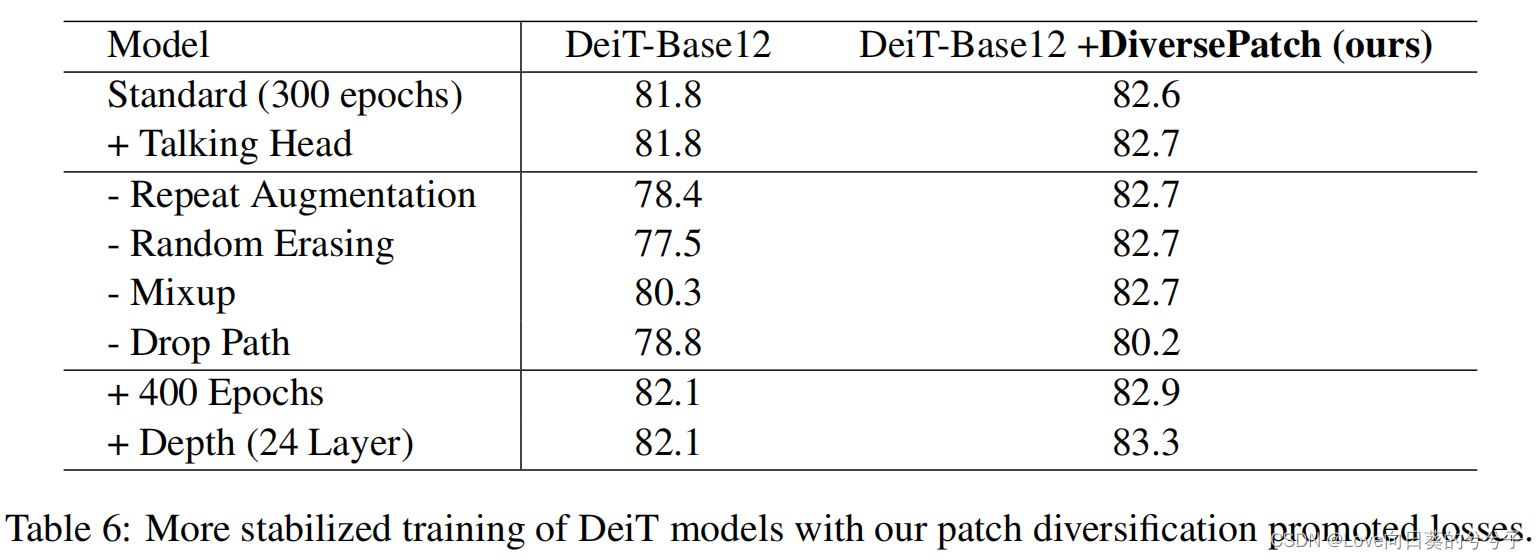
2)训练的稳定性
4. 结论
1)本文核心就是要在训练图像Transformer时促进patch的多样性,从而提升模型的学习能力。这一目的主要是通过提出三个损失来达到。
2)论文经验表明,在不改变Transformer模型结构的情况下,通过使patch表示多样化,能够训练更大、更深入的模型,并在图像分类任务中获得更好的性能。
3)论文只在监督任务进行实验