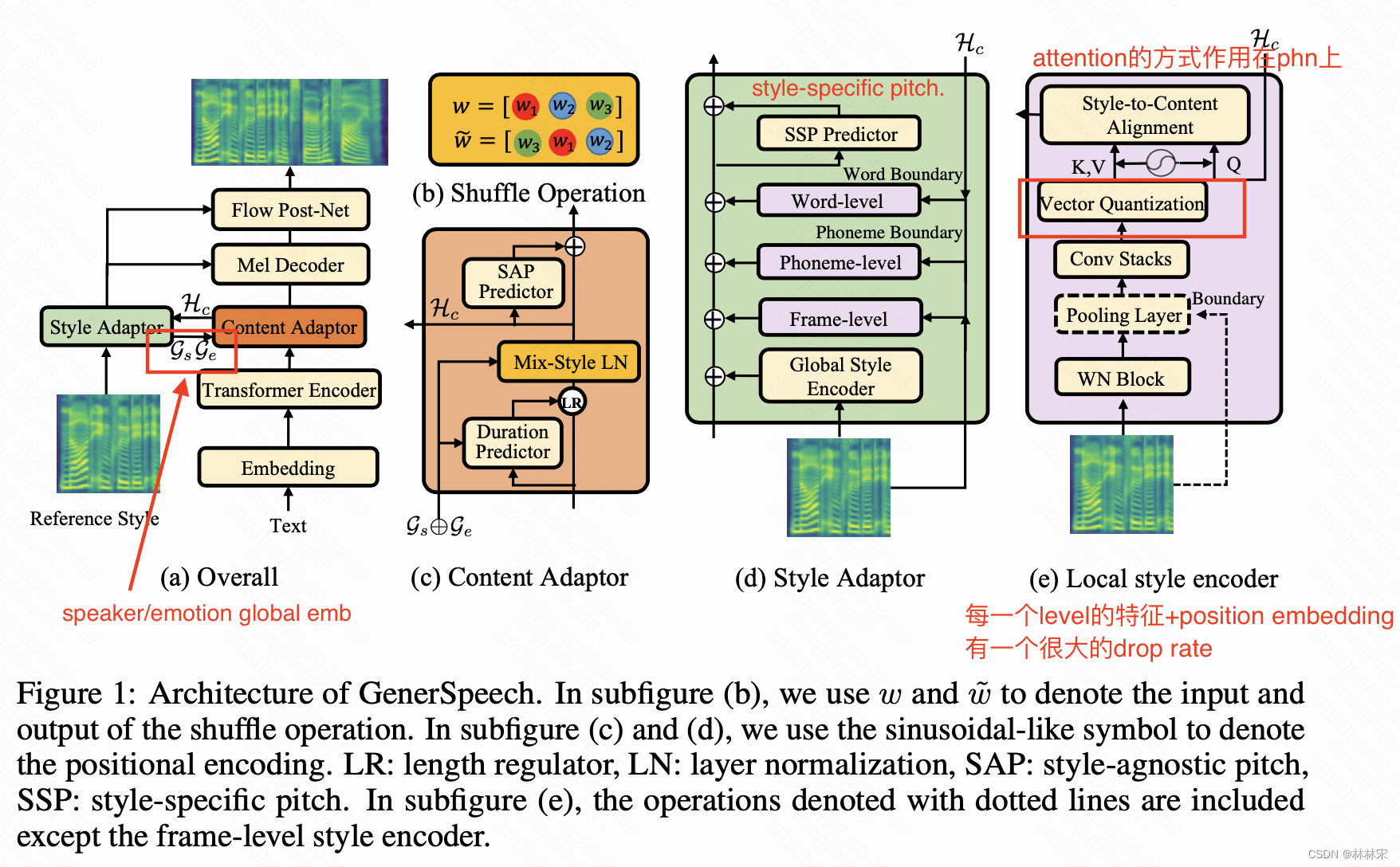
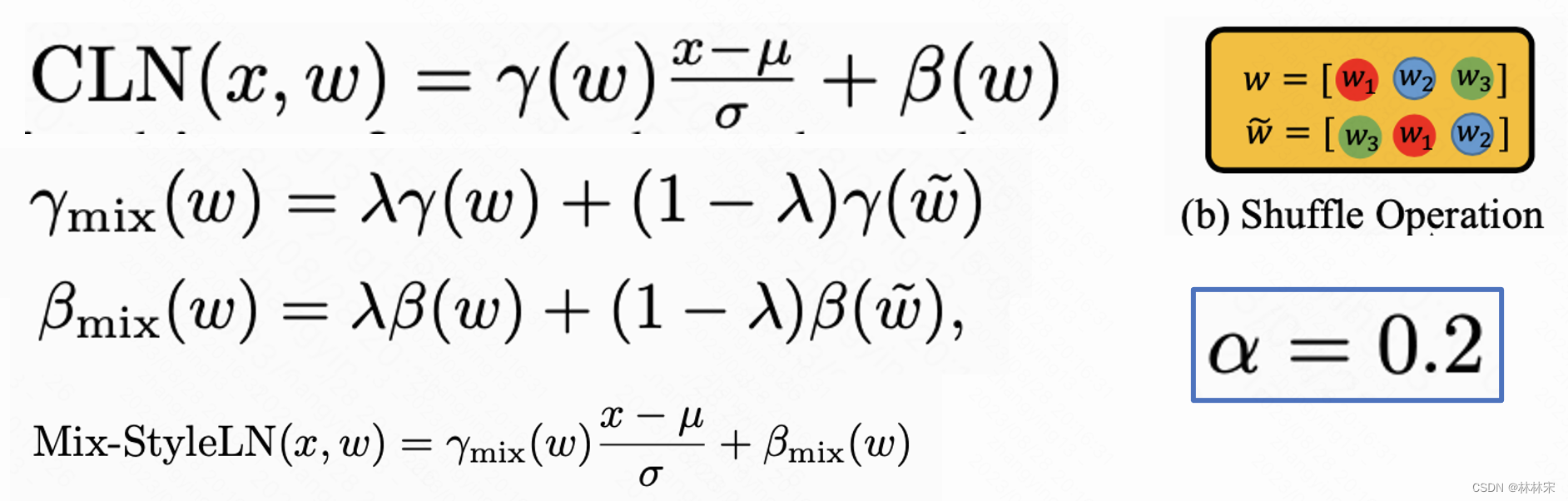两个改进:(1)multi-level style adaptor :包括global style以及 local style (utterance, phoneme, and word-level) ;(2) content adaptor with Mix-Style Layer Normalization:用以消除输入文本特征中的风格信息,改善模型泛化能力;
背景
Meta-StyleSpeech,SC-GlowTTS,Styler: Style factor modeling with rapidity and robustness via speech decomposition for expressive and controllable neural text to speech.
OOD的风格迁移,尤其是zero-shot的,都有先验的假设新的目标风格对于base model是可迁移的,但实际上,新的目标风格可能不同于base model中任意一种数据分布,这就要求:the model can be invariant to domain shift given unseen data. 从图像上借鉴一些方法。
GenerSpeech
问题定义:transfer of out-of-domain custom voice.
分析:想要做风格迁移,首先要划分好哪些是风格先管的特征,哪些是风格无关的特征
style-agnostic (linguistic content)
style-specific (e.g., speaker identity, emotion, and prosody)