论文地址 :https://www.aclweb.org/anthology/P19-1482/
作者 :Chen Wu, Xuancheng Ren, Fuli Luo, Xu Sun
机构 : 清华、北大
研究的问题:
关注的是文本的风格迁移问题。目前主流的方法还是用类似于翻译中的端到端方法,但端到端系统本身存在一些问题,比如不具有可解释性、在风格和内容之间寻找一个平衡比较困难。本文提出的是基于强化学习的一种基于序列操作的方法,包括两个部分,一个是提出操作位置的高级agent,一个是根据高级agent提出的去修改句子的低级agent。
文本风格迁移主要关注流利性、风格极性、内容保存。对于流利性,使用语言模式的奖励函数;对于风格极性,引入分类置信度奖励和辅助的分类任务;对于内容保存,采用重建的方法。
重建的方法来自于CycleGAN,考虑到文本的离散型,这里用对于序列的操作来模拟。
研究方法:
选项框架:
本文的整体方法是基于HRL(Hierarchical Reinforced Learning)中的选项框架(options framework)的。首先介绍一下选项框架,一个选择框架由两个层次组成:
底层是一个次级政策(进行环境观察、输出动作、一直持续到终止)
高层是选项之上的政策(进行环境观察、产出次级政策、一直持续到终止)
对于上层所做的一个option,包括两个部分,一个是行动策略,一个是终止函数。当终止函数返回0的时候,下一步还会由当前的这个option来控制;当终止函数返回1的时候 ,该option的任务就暂时完成了,控制权就交回给上层策略。
高级agent:指针
高层agent的目标是提出操作的位置,这里通过指针网络来实现。相关定义如下:
Option:给定一个句子x={x_1,…,x_t},选择空间就是O={1,…,t}。如果句子长度变化了,t的范围也随之变化。
State:通过Bi-LSTM编码器得到的句子表示。
Policy:一个softmax的过程,如下所示。
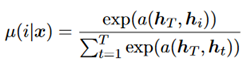
低级agent:操作
操作是预先定义的,包括以下7种。

Action:给定一个句子和一个操作位置,低级agent从表中选择一种操作,如果需要词的话,生成一个词。
State:同样是通过Bi-LSTM得到的句子编码。
终止条件:在原始的选项框架中,终止条件是学习得到的,不过这里终止条件是固定的,目的是让训练更稳定。
操作选择策略:在训练阶段,选择一种统一的操作,比如全是替换。同样是为了让训练更稳定,在inference阶段的策略在下面介绍。
词生成策略:由下面的公式生成词。

这里的h也就是state。
训练方法:
首先是训练方法的图示。
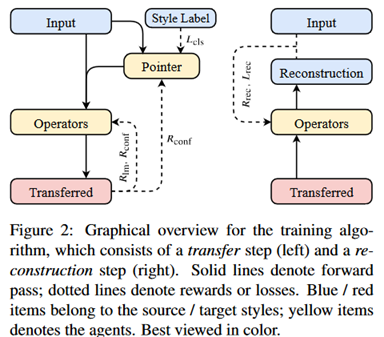
如前述提到,训练目标主要是为了模拟流利性、风格极性、内容保留这三个方面,下面分别介绍。
流利性:使用语言模型奖励。如下所示。
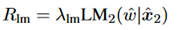
本文是通过对前向和后向的LSTM求平均值来计算概率的。
风格极性:
分类置信度:采用分类置信度函数,如下所示:

同时设置了一个辅助任务,在HRL中高级agent往往面临梯度方差大的问题,为了稳定训练,这里设置了一个辅助的任务,也就是将高级agent扩展为一个基于attention的分类器,如下所示。
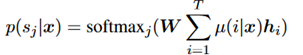
内容保留:
重构损失:
考虑一个操作M,在第i个位置上操作,根据定义的操作可以找出可能的操作M‘,以及可能的位置i‘,具体规律如下表所示。

之后使用(M‘,i‘)来定义重构损失如下:
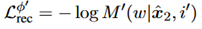
重构奖励:给出定义如下,
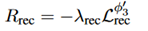
它的目的主要是鼓励1对1的映射,也就是防止把很多词都映射到good,bad这类词上。
训练过程:
在高级的agent中,只使用引入的分类任务的奖励,而不使用语言模型的奖励。作者解释是语言模型的奖励更加局部,会很大地增加奖励的方差。
在低级的agent中,使用所有的外部奖励和内部奖励。也就是前述的三个部分的奖励函数。
Inference阶段:
覆盖选项:在inference中会面临,前一步操作影响后一步的操作的问题,这里作者通过mask选项(这里的选项也就是位置)的方法来实现,具体是在文本中出现插入、删除、跳过操作时使用。
终止条件:如果操作局被确定为目标类型,就终止。但这样高度风格化的部分可能会导致过早终止。所以作者这里对操作局中的词进行mask。
Operator的选择策略:枚举所有的操作符,通过语言模型来打分,选择分数最高的。
实验部分:
数据集有两个,分别是Yelp和Amazon数据集
评价指标有三种,一个是样本分类器(使用TextCNN)实现,BLEU、还有人类打分
实验结果如下:

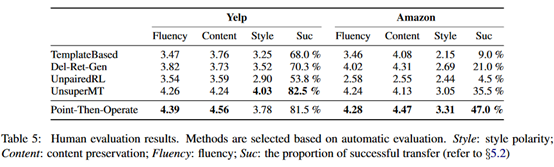
可以看到在BLEU上提升比较明显,但在分类准确率上并不太高。
评价:
文本领域的风格迁移当前还达不到使用的程度,一部分原因也在于数据的匮乏,端到端的训练需要大量的对齐文本,想达到翻译那样的效果还差很多。如果类比人类去做这个任务的思路,先理解文本,再改写句子,对于目前的技术来说还不能实现。
从实验结果来看,本文的实验结果并不是很好。在分类准确率上不如之前的一些系统,虽然在BLEU上有个比较明显的提升。但这里有个问题在于,在这个任务上以往的工作大多更看重风格迁移是否成功,也就是分类准确率,BLEU并不是一个很重要的指标。虽然在人类评估上它们的模型结果更好,但人类评估的主观性比较大。
对于风格迁移,当前主流的方法还是RL+deep learning。本文是基于HRL中的选项框架设计的,然后针对训练过程中遇到的一些问题提出了一些改进措施,理论上的创新较少。