点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
转载自:CSIG文档图像分析与识别专委会

本文简要介绍被IJCAI 2023录用的论文《Towards Robust Scene Text Image Super-resolution via Explicit Location Enhancement》。本文注意到场景文本图像中的背景区域对下游文本识别任务的用处并不大,同时复杂背景的存在也会干扰超分辨率模型的重建结果。基于这一观察,本文提出对文本图像中的字符位置进行显式建模从而在超分辨率重建过程中给予字符区域更多关注。实验表明,使用本文提出的显式位置建模方案可以进一步提升超分辨率模型在下游识别任务中的精度,同时对复杂样例表现出很强的鲁棒性。
一、研究背景
场景文本识别是一项重要的计算机视觉任务,在自动驾驶、证件识别等领域具有广泛的应用。尽管取得了令人印象深刻的进展,但目前的场景文本识别方法仍然难以处理低分辨率图像。因此,为场景文本图像定制超分辨率网络已成为一个热门的研究课题。
为此,近年来许多场景文本图像超分辨率方法被提出并取得了可喜的成果。例如,Chen等人[1]提出了位置感知损失函数来考虑字符的空间分布。通过应用字符概率分布,TPGSR[2]证明了在STISR任务中使用语言知识作为指导的重要性。为了处理空间不规则文本,Ma等人[3]提出了TATT模型。此外,C3-STISR[4]则通过使用三个视角的线索来进一步提升模型的性能。
尽管已有的方法做了很多努力,但是目前的方法大多在模型设计上对字符区域和背景同等对待,而忽略了复杂背景的不利影响。从直观上看,非字符背景对于下游识别任务来说通常是缺乏信息的,因此不需要重建背景的纹理细节。此外,复杂的背景会给重建过程带来干扰。一方面,背景可能被错误地当作字符,从而产生错误的重建(见图1 (a))。另一方面,背景可能会影响模型对字符的准确定位,从而导致重建效果较差(见图1 (b))。因此,现有方法在面临背景复杂时往往存在性能下降的问题,从而限制了实际应用。

图1 复杂背景给场景文本图像超分带来挑战。(a)“SUPER”中的“R”可能被错误地重建为“B”或“S”。(b)复杂的背景会导致字符定位不准确致使重建效果不佳。
二、方法简述
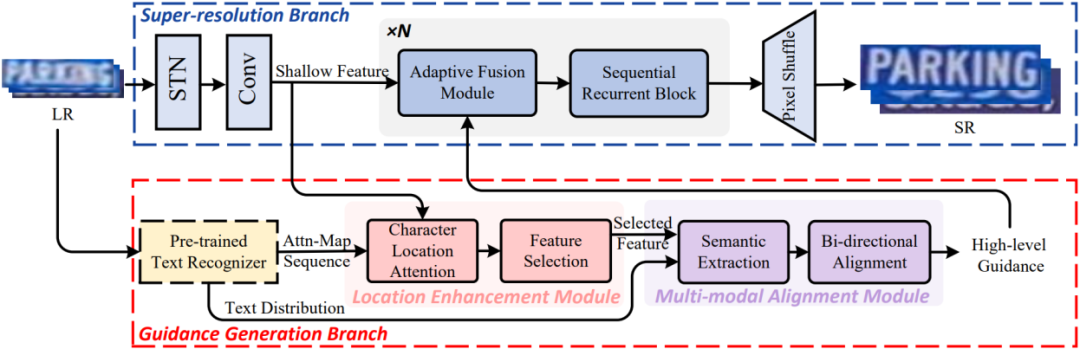 图2 详细框图
图2 详细框图
如图2所示,模型由超分辨率重建分支和先验生成分支组成。其中超分辨率重建分支负责高清文本图像的重建,先验生成分支包含位置增强模块和多模态对齐模块通过挖掘字符位置特征和语义特征来为超分辨率主干提供先验指导。
位置增强模块将文本识别器生成的注意图序列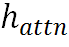 进行字符位置增强。设L为字符序列的长度,
进行字符位置增强。设L为字符序列的长度,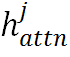 表示第j个字符对应的注意力图。这里选择有意义的注意力图来产生
表示第j个字符对应的注意力图。这里选择有意义的注意力图来产生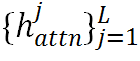 ,然后将它们沿通道维度进行拼接并使用Max算子将通道维数降至1,将该过程结果记为
,然后将它们沿通道维度进行拼接并使用Max算子将通道维数降至1,将该过程结果记为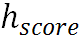 :
:
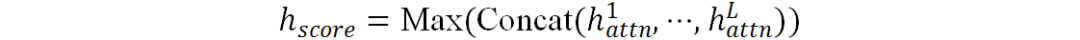
之后使用C个卷积核提取不同的特征模式并在最后使用Softmax函数进行归一化,得到最终结果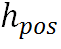 :
:
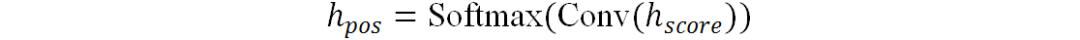
使用经过实例归一化后的图像特征与相乘得到位置增强特征:
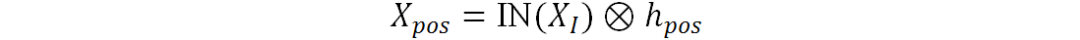
其中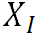 为原始图像特征,
为原始图像特征,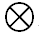 表示Hadamard乘积,IN为实例归一化。
表示Hadamard乘积,IN为实例归一化。
由于 包含像素级字符置信分数,选择其前K个大元素来获得前景坐标集合:
包含像素级字符置信分数,选择其前K个大元素来获得前景坐标集合:
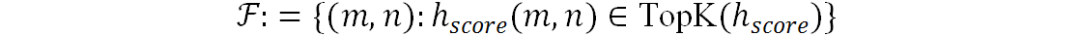
然而直接使用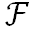 来索引图像特征会丢失不在
来索引图像特征会丢失不在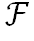 中的邻域像素特征从而使模型容易受到注意力漂移的影响。为了充分考虑邻域信息,这里使用邻域特征加权来表征邻域信息:
中的邻域像素特征从而使模型容易受到注意力漂移的影响。为了充分考虑邻域信息,这里使用邻域特征加权来表征邻域信息:
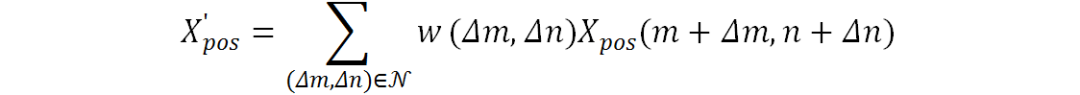
其中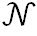 表示八邻域像素集合,
表示八邻域像素集合,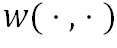 表示邻域每个位置对应权值。
表示邻域每个位置对应权值。
多模态对齐模块首先通过投影算子和自注意力块对文本分布进行语义信息提取来产生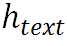 。为了使视觉模态与语言模态更容易对齐,本项目提出一种双向对齐策略来促进跨模态对齐。该策略主要包含两个层级的渐进对齐。首先,图像到文本的对齐使用
。为了使视觉模态与语言模态更容易对齐,本项目提出一种双向对齐策略来促进跨模态对齐。该策略主要包含两个层级的渐进对齐。首先,图像到文本的对齐使用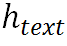 作为注意力机制中的Query,使用图像特征同时作为Key和Value,这一设计可以让每个字符找到它对应的图像区域:
作为注意力机制中的Query,使用图像特征同时作为Key和Value,这一设计可以让每个字符找到它对应的图像区域:
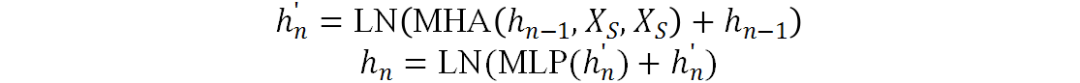
当n=1时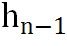 表示
表示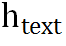 ,其他情况下则表示上一个块的输出。
,其他情况下则表示上一个块的输出。
第二级文本到图像的对齐使用图像特征作为Query,第一级对齐结果作为Key,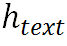 作为Value。使得图像模态中的每个元素都可以找到应该关注的文本特征。
作为Value。使得图像模态中的每个元素都可以找到应该关注的文本特征。
最后通过自适应融合模块来将不同程度的先验指导引入到不同超分辨率模块中。具体来说,给定图像特征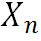 ,它可以是浅层特征或者上一个超分块的输出,以及先验生成分支产生的指导,自适应融合模块首先沿通道维度将
,它可以是浅层特征或者上一个超分块的输出,以及先验生成分支产生的指导,自适应融合模块首先沿通道维度将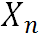 和指导拼接起来。之后是三个并行的1×1卷积来将
和指导拼接起来。之后是三个并行的1×1卷积来将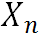 投影到三个不同的特征空间中,并将它们分别表示为
投影到三个不同的特征空间中,并将它们分别表示为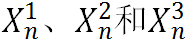 。然后在特征图
。然后在特征图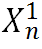 上执行通道注意力机制,并将得到的注意力分数与
上执行通道注意力机制,并将得到的注意力分数与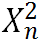 相乘以生成经过通道注意力后的特征,这些特征将被用来和
相乘以生成经过通道注意力后的特征,这些特征将被用来和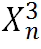 相加以获得最终融合结果:
相加以获得最终融合结果:
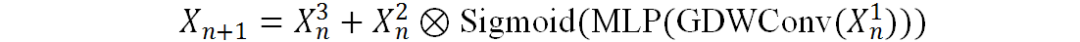
其中GDWConv 表示全局深度可分离卷积。
通过设计带有文本字符位置先验增强的文本超分模型,将文本特定的细粒度先验加入到超分辨率主干中,实现了在模型推断过程中有区别地对待字符区域和非字符背景,从而提高了模型在复杂背景下超分辨率重建的性能。
三、实验结果
表1展示了本文提出的方法与其他方法在下游文本识别任务上的定量对比,可以看到,由于本文对字符区域给予更多关注因此生成的高分辨率图像可以更容易地被下游识别器识别。
表1 在下游识别任务上的定量对比
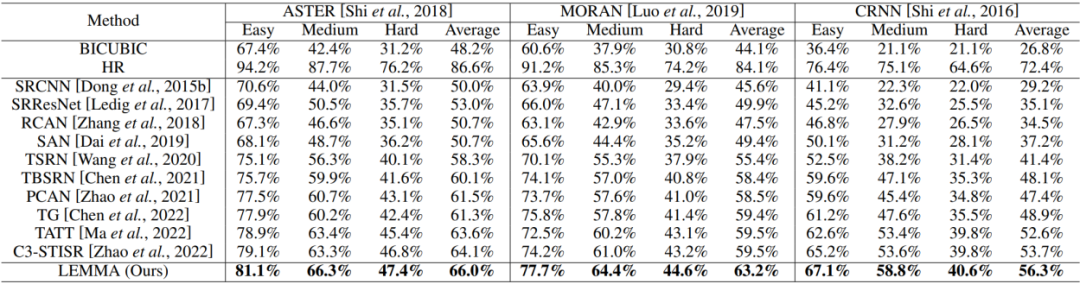
图3也给出了定性的对比实验结果。
表3定性对比结果

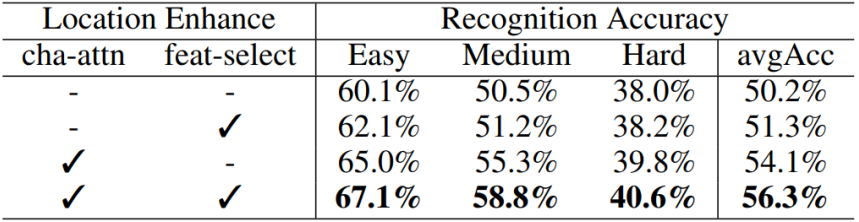
随后是关于本文提出模块的消融实验。首先是验证显式位置增强即所提出的位置增强模块的有效性。可以看到,使用字符位置注意力以及特征选择技术对背景特征进行丢弃之后,不仅没有导致性能下降,反而由于减轻了背景干扰而提升了性能。
表2 位置增强模块的有效性
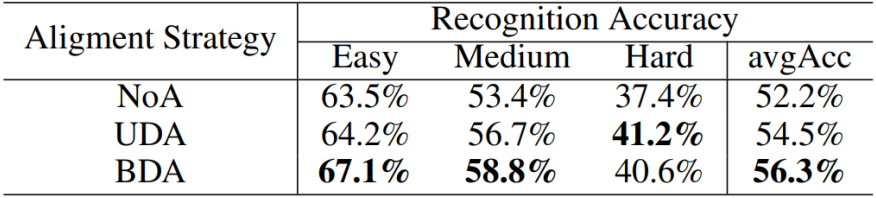
之后是对所提出的多模块双向对齐模块的有效性的验证。实验结果表面双向的特征对齐比未对齐和单向对齐的效果都要更好。
表2多模态对齐模块的有效性
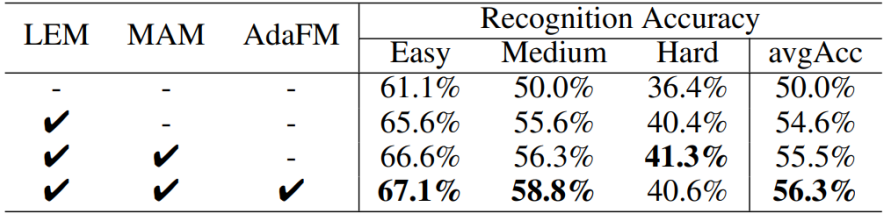
同时,作者也给出了所提出的三个模块之间的消融实验,如表3所示。
表3不同模块组合的有效性
最后作者给出了在面对不同字符长度的场景文本图像时不同模型的下游识别任务精度对比结果,如图4所示。由于采用了显式的位置增强策略,在面临较长字符文本时模型可以加强字符区域特征,从而减轻与长字符文本相关的长程遗忘问题。
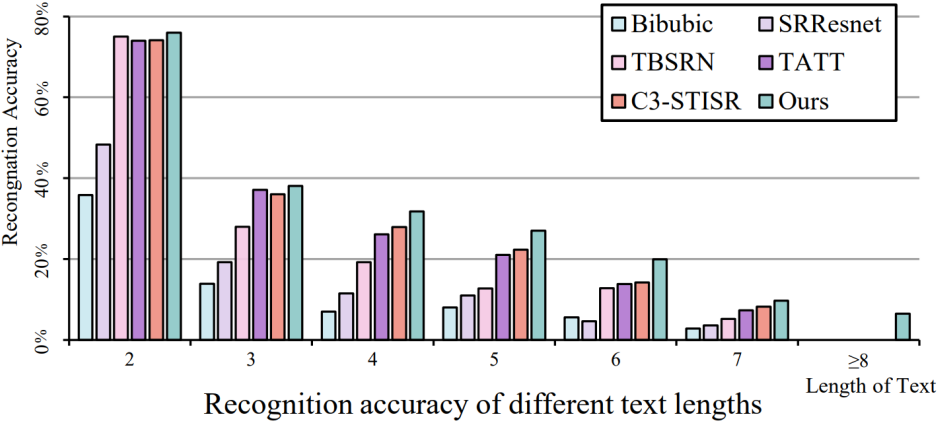
图4 在不同字符长度图像下的对比
四、总结
本文提出了位置增强多模态网络LEMMA以应对现有的STISR方法所面临的挑战。该方法通过显式的位置增强来更多地关注字符区域。位置增强模块使用字符位置注意和特征选择技术从所有像素中提取字符区域特征。多模态对齐模块采用双向渐进策略来促进跨模态对齐。自适应融合模块则自适应地将生成的高级指导整合到不同的重建块中。通过在TextZoom数据集和其他四个具有挑战性的场景文本识别基准数据集上的表现,证明了本文方法可以进一步提高下游文本识别任务的正确率,为鲁棒的场景文本图像超分辨率技术的发展迈出了重要一步。
五、相关资源
论文下载地址:
https://arxiv.org/pdf/2307.09749.pdf
代码地址:
https://github.com/csguoh/LEMMA
参考文献
[1] Jingye Chen, Haiyang Yu, Jianqi Ma, Bin Li, and Xiangyang Xue. Text gestalt: Stroke-aware scene text image super-resolution. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 36, pages 285–293, 2022.
[2] G Ma J, Guo S, Zhang L. Text prior guided scene text image super-resolution. IEEE Transactions on Image Processing, 32: 1341-1353, 2023.
[3] Jianqi Ma, Zhetong Liang, and Lei Zhang. A text attention network for spatial deformation robust scene text image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5911–5920, 2022.
[4] Minyi Zhao, Miao Wang, Fan Bai, Bingjia Li, Jie Wang, and Shuigeng Zhou. C3-stisr: Scene text image super-resolution with triple clues. international joint conference on artificial intelligence, 2022.
原文作者:Hang Guo, Tao Dai, Guanghao Meng, and Shu-Tao Xia
撰稿:郭 航 编排:高 学
审校:连宙辉 发布:金连文
ICCV / CVPR 2023论文和代码下载
后台回复:CVPR2023,即可下载CVPR 2023论文和代码开源的论文合集
后台回复:ICCV2023,即可下载ICCV 2023论文和代码开源的论文合集OCR和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer333,即可添加CVer小助手微信,便可申请加入CVer-OCR或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF等。
一定要备注:研究方向+地点+学校/公司+昵称(如OCR或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer333,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉,已汇集数千人!
▲扫码进星球
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看