摘要
本文简要介绍IJCAI2022论文“SVTR: Scene Text Recognition with a Single Visual Model”的主要工作。主流的场景文字识别算法通常包含两个模块,即用以提取特征的视觉模块(如CNN,MHSA),以及用于输出文本的序列模块(如RNN,Attention)。本文提出了一个只由视觉模块构成的模型SVTR,在中英文场景文字识别上都取得了较好效果,并且推理速度较快。代码已开源,链接见文末。
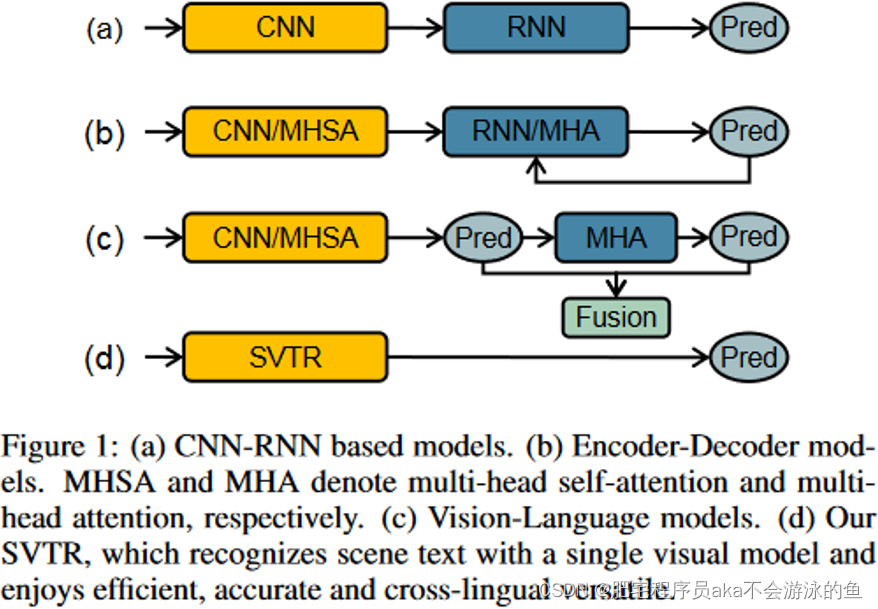
研究背景
场景文字识别可以看作是一个从图像映射到序列的任务。大多数的识别算法通常由两个模块构成,即用于特征提取的视觉模块以及用于文本输出的序列模块。比如早期基于CNN-RNN的CRNN[1],和现在一些基于注意力机制,进行自回归式解码的算法。但是这样的双阶段算法的推理速度往往较慢,难以满足工业应用的需求。因此本文从推理速度和模型性能的双重角度出发,提出了只由Transformer构成的纯视觉模块网络SVTR,在NVIDIA 1080Ti GPU上达到了 4.5 ms的推理速度,并且参数量仅有6.03M。
网络概述
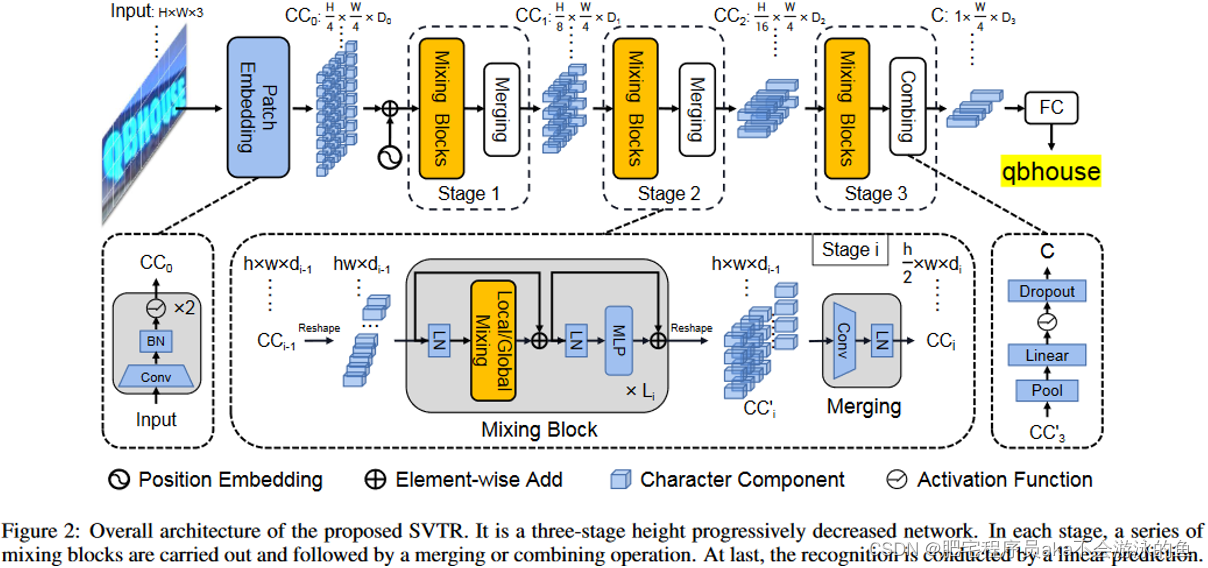
图2是这篇文章提出的SVTR的整体结构,采用类似于SwinTransformer[2]的视觉模型和一个全连接层以及CTC解码器进行文本序列预测。
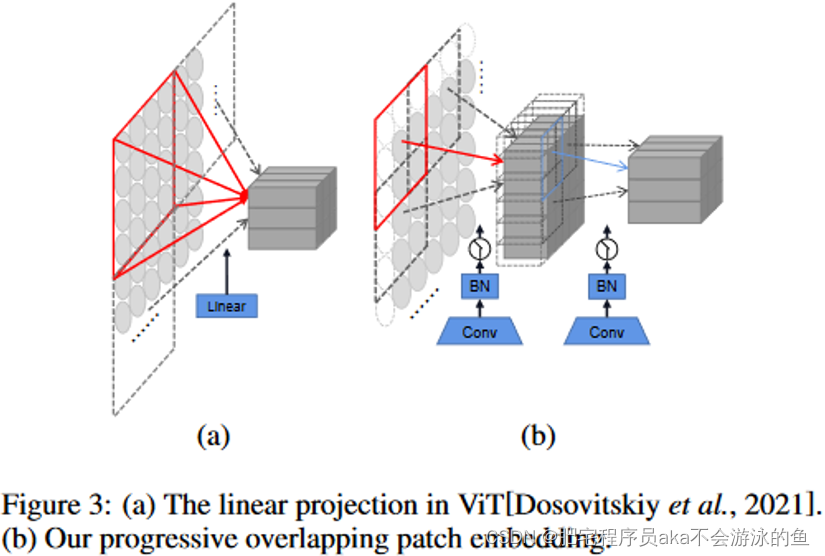
首先和ViT[3]类似,将输入尺寸为H * W * 3图片图像按照Patch进行划分, 得到图片 H 4 × W 4 × D 0 \frac{H}{4} \times \frac{W}{4} \times D_{0} 4H×4W×D0 Embeddings。本文采用的Patch Embedding操作和ViT中的有些许差异,其由两层步距为2,卷积核大小为卷积层3X3,以及BN层构成。这样不同的Patch之间是存在着重叠的,如图3所示。经过Patch Embedding后的序列将经过一系列的Stage,每一个Stage都由一系列的Mixing Block和Merging Layer构成。
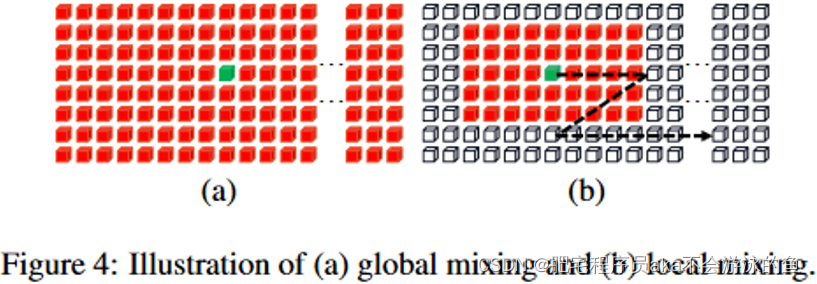
作者认为文本识别需要两种特征。第一种是局部特征,如笔画特征。它编码了字符的不同部分之间的形态特征和相关性。第二种是字符间的依赖性,如不同字符之间或文字与非文字成分之间的相关性。因此,作者设计了两个混合模块,即 Global Mixing 和 Local Mixing, 通过使用不同大小感受野的自注意层来实现。如图4 所示。Global Mixing层本质上就是一个Transformer block,由一个多头自注意层,一个Layer Norm 层,以及一个MLP层构成。通过自注意力机制的全局建模特性来进行全局字符建模。Local Mixing则是采用了带窗的自注意层,窗大小设置为了7 X 11。
Merging层扮演着将输入序列进行下采样的角色。其由高度方向步距为2,宽度方向步距为1,卷积核大小为3X3的卷积层构成。将输入序列的尺寸由图片缩小为图片。同时每经过一次Merging层,序列的Channel维度也会增大,从而弥补在高度上的信息损失。SVTR有四种参数配置,如表1所示

试验结果
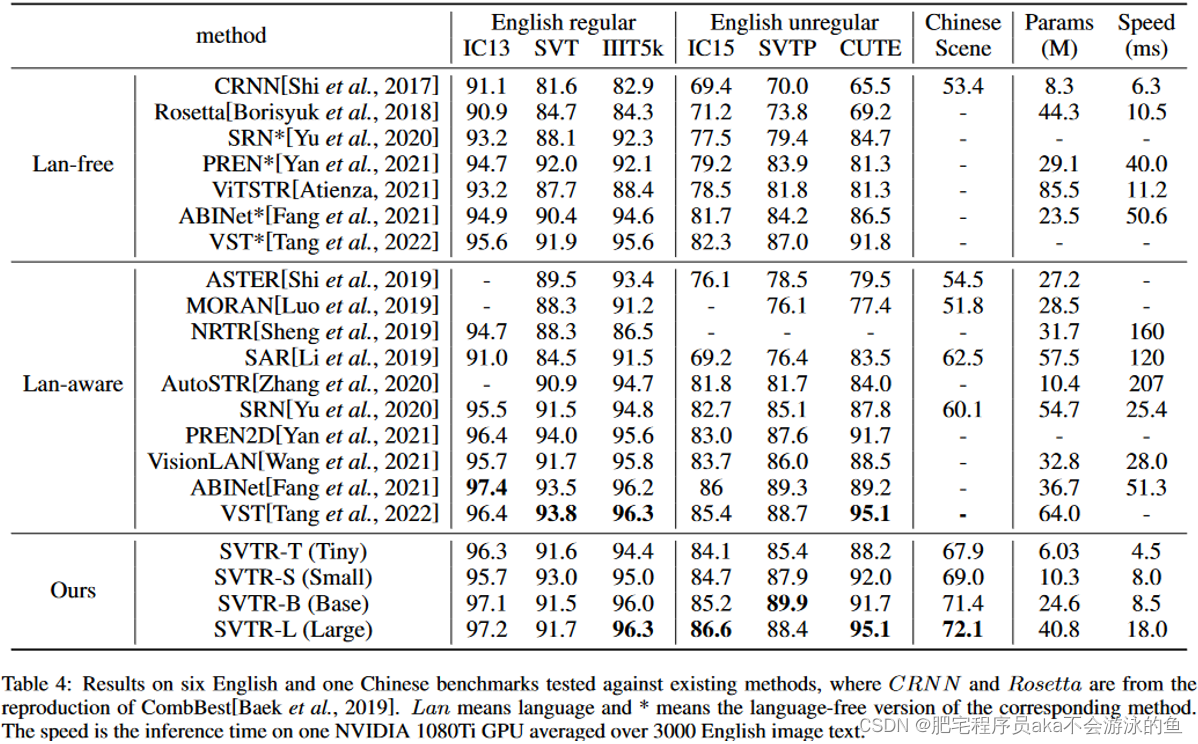
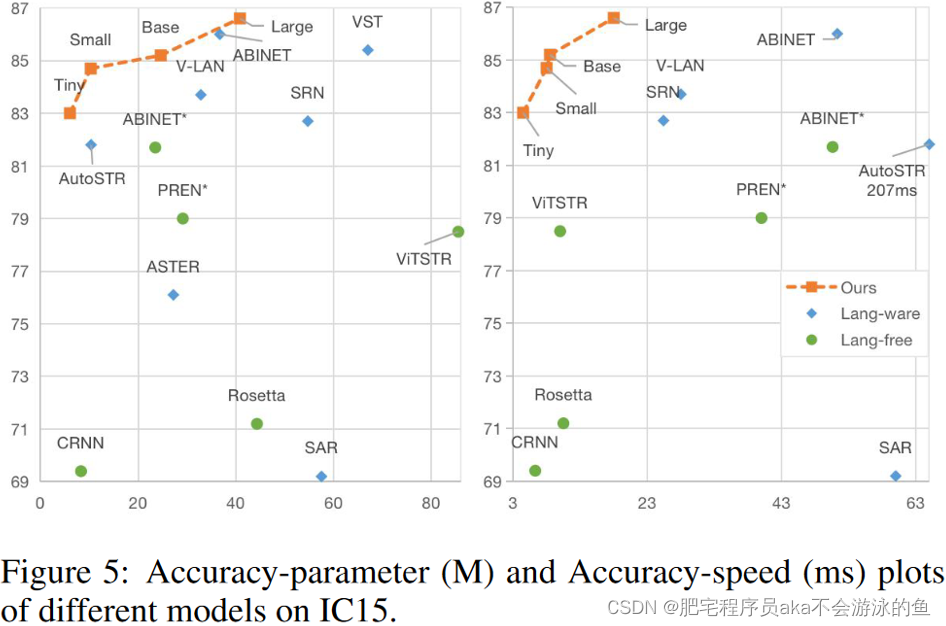
首先本文在英文场景文字识别上进行了实验,使用合成数据集进行训练,并在6个常用Benchmarks上进行测试,结果如表2所示。本文的方法在取得了较好的效果下,推理速度也非常快,模型参数量也较小。在图5中也进一步对比了不同算法之间的性能、推理速度、模型参数量。
本文也做了一些消融实验,首先是对比了不同的Patch Embedding 操作,如表3所示,结果表明本文提出的使用卷积层来进行Patch Emedding 的方法最好。

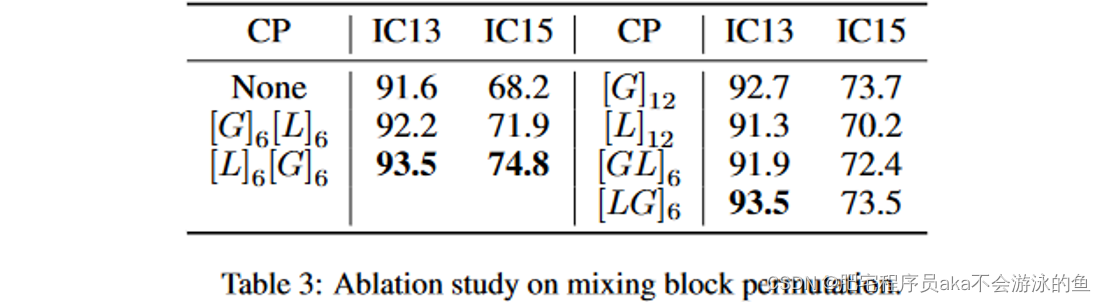
本文也验证了了Global Mixing和Local Mixing混合使用的有效性,发现先使用Local Mixing,再使用Global Mixing的效果是最好的,如表4所示。
总结及讨论
本文提出了一个由纯视觉模块构成的场景文字识别器SVTR,由Transformer和CTC Decoder构成,在模型性能和推理速度上都有很好的表现,对工业落地应用友好。
相关资源
论文地址: https://www.ijcai.org/proceedings/2022/0124.pdf
开源地址: https://github.com/PaddlePaddle/PaddleOCR
参考文献
[1] Baoguang Shi, Xiang Bai, and Cong Yao. An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition. IEEE Trans. Pattern Anal. Mach. Intell., 39(11):2298–2304, 2017.
[2] Ze Liu, Yutong Lin, Yue Cao, et al. Swin transformer: Hierarchical vision transformer using shifted windows[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021: 10012-10022.
[3] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An Image is Worth 16x16 Words: Transformers for image recognition at scale. ICLR, 2022.