
代码:https://github.com/open-mmlab/mmocr/blob/main/configs/textrecog/svtr/README.md
原文标题:SVTR: Scene Text Recognition with a Single Visual Model
文章链接:https://arxiv.org/abs/2205.00159
一、问题提出
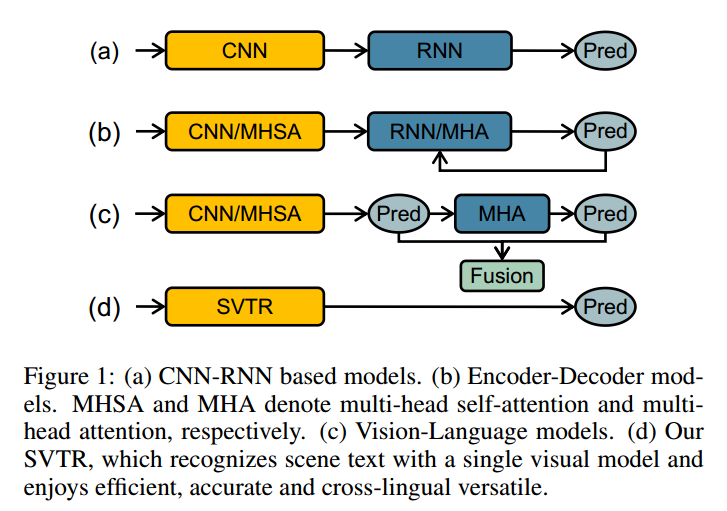
场景文字识别目前分三类:
(a). CNN→RNN,CNN提取特征,RNN回归特征
(b). CNN/MHSA→RNN/MHA, CNN/MHSA提取特征,RNN/MHA回归特征
(c). CNN/MHSA→MHA→Fusion, CNN/MHSA提取特征,MHA回归特征生成阶段性标签,Fusion融合视觉特征和阶段性标签,并回归新特征
(d). 该文章提出的SVTR模型,直接使用单个视觉特征提取预测
具体来说,该模型可以成功地捕捉到字符内的局部模式和字符间的长期依赖性。前者对描述字符细粒度特征的笔划状特征进行编码,是区分字符的关键来源。后者记录了从互补的角度描述人物的语言相似知识。然而,先前的特征提取器并没有很好地对这两个特性进行建模。
SVTR首先将图像文本分解为称为字符分量的二维小块,因为每个小块可能只包含字符的一部分。因此,将逐块图像标记化和自注意应用于捕捉字符成分之间的识别线索。具体来说,为此开发了一个文本定制架构。它是一个三级高度逐渐降低的主干,具有混合、合并和/或组合操作。
局部和全局混合块被设计并在每个阶段循环使用,以及合并或组合操作,获取表示字符的笔划特征的局部分量级仿射,以及不同字符之间的长期依赖性。因此,主干提取不同距离、多尺度的成分特征,形成多粒度的特征感知。结果,通过简单的线性预测来实现识别。
在整个过程中,只使用了一个视觉模型。构建了四种不同容量的架构变体。
二、模型
1、Overall Architecture
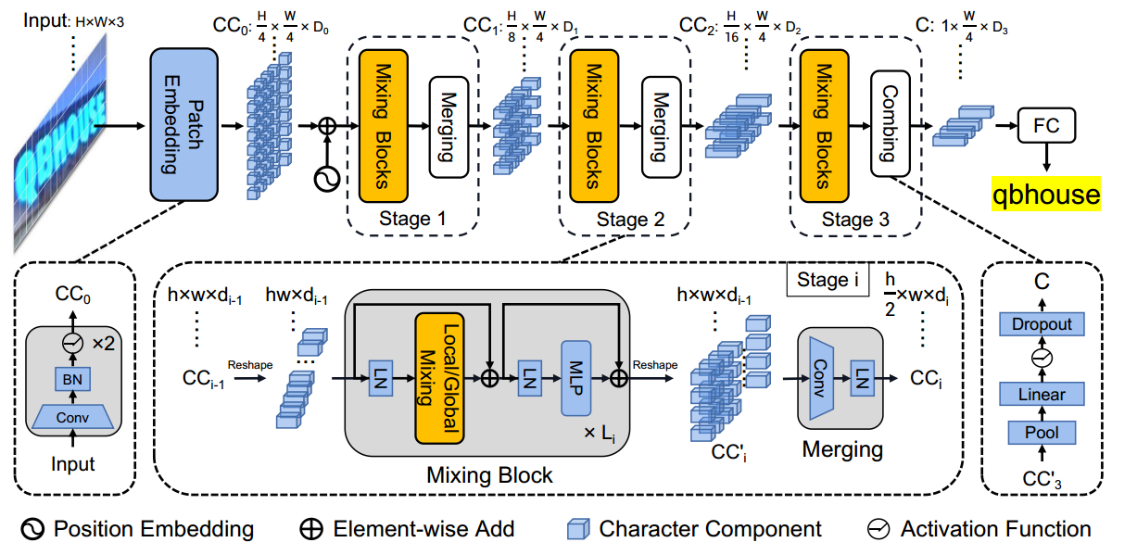
以不同的尺度执行三个阶段,每个阶段由一系列混合块组成,然后进行合并或组合操作,用于特征提取。局部和全局混合块被设计用于类似笔划的局部模式提取和分量间相关性捕获。利用backbone,对不同距离和多个尺度上的分量特征和依赖性进行了表征,生成了一个称为C的大小为1×(W/4)×D3的表示,该表示感知多粒度的特征。最后,进行了带去重的并行线性预测
2、Progressive Overlapping Patch Embedding
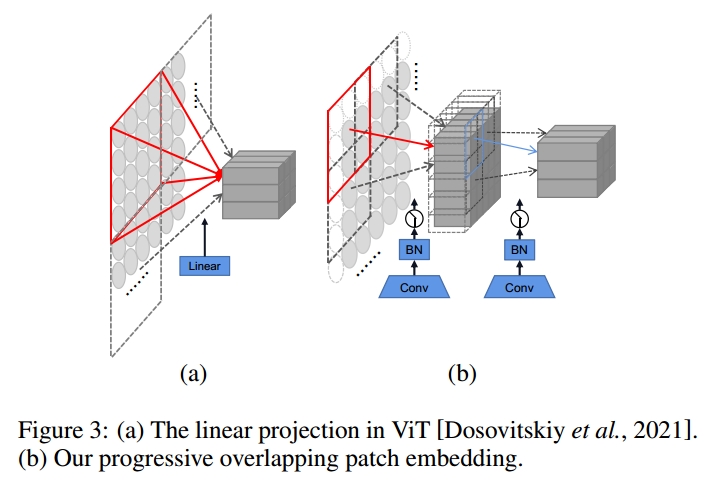
patch embedding
一步投影(a),即4×4不相交的线性投影,见图3(a)和步长为4的7×7卷积;
两个连续的3×3卷积,步长为2,BN层,如图3(b)所示。该方案虽然略微增加了计算成本,但逐渐增加了特征维数,有利于特征融合。
3、Mixing Block
先前的视觉提取器:每个特征对应于一个薄片图像区域,该区域通常是噪声的,尤其是对于不规则的文本。它不是描述角色的最佳方式。
作者认为文本识别需要两种特征。第一种是局部零部件图案,例如类似笔划的特征。它对一个字符的形态特征和不同部分之间的相关性进行编码。第二种是字符间相关性,例如不同字符之间或文本和非文本成分之间的相关性。
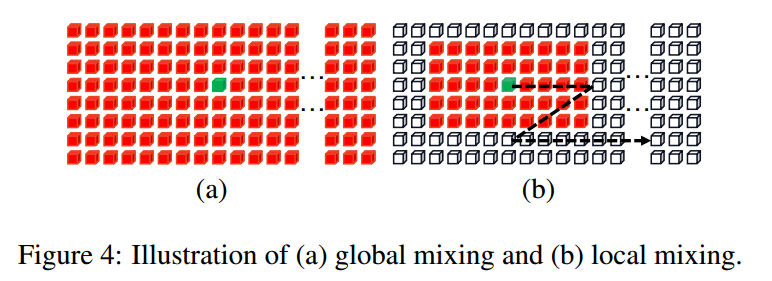
Global Mixing
全局混合评估所有角色组件之间的依赖性。由于文本和非文本是图像中的两个主要元素,这种通用的混合可以在不同字符的成分之间建立长期的依赖关系。此外,它还能够削弱非文本成分的影响,同时提高文本成分的重要性。从数学上讲,对于前一阶段的字符分量CCi−1,首先将其重塑为特征序列。当输入到混合块中时,应用层范数,然后使用多头自注意进行相关性建模。在下文中,层范数和MLP被顺序地应用于特征融合。与shortcut一起,形成全局混合块。
Local Mixing
如图4(b)所示,局部混合评估预定义窗口内组件之间的相关性。其目的是对字符形态特征进行编码,并建立字符内各成分之间的关联,从而模拟对字符识别至关重要的笔划状特征。与全局混合不同,局部混合为每个分量考虑一个邻域。与卷积类似,混合是以滑动窗口的方式进行的。窗口大小根据经验设置为7×11。与全局混合相比,它实现了自注意机制来捕获局部模式。
如上所述,两个混合块旨在提取互补的不同特征。在SVTR中,块在每个阶段被反复应用多次,以进行综合特征提取。这两种块的置换稍后将被消融
Merging
在每个阶段(除了最后一个阶段)的混合块之后设计合并操作。利用最后一个混合块输出的特征,首先将其重塑为大小为h×w×di−1的embedding。然后使用3×3卷积,height维度上的step为2,width维度上的step为1,然后是LN,生成大小为H2×w×di的embedding。
合并操作将高度减半,同时保持恒定的宽度。它不仅降低了计算成本,而且建立了一个文本自定义的层次结构。(大多数图像文本都是水平或接近水平显示的,这是数据决定的), 压缩高度维度可以为每个角色建立多尺度表示,而不会影响宽度维度上的补丁布局。它不会增加跨stage将相邻字符编码到同一组件中的机会。还增加了信道维度di来补偿信息损失。
4、Combining and Prediction
最后阶段,the merging operation 被combining operation替代,将height维度合并为1,然后是全连接层、非线性激活和Dropout。字符分量被进一步压缩为特征序列,其中每个元素由长度为D3的特征表示。与合并操作相比,合并操作可以避免将卷积应用于一个di中大小非常小的嵌入,利用组合特征,通过简单的并行线性预测来实现识别。具体地,采用了具有N个节点的线性分类器。理想情况下,相同字符的组成部分被转录为重复字符,非文本的组成部分则被转录为空白符号。序列会自动浓缩为最终结果。在实现中,N(英语)设为37,汉语设为6625。
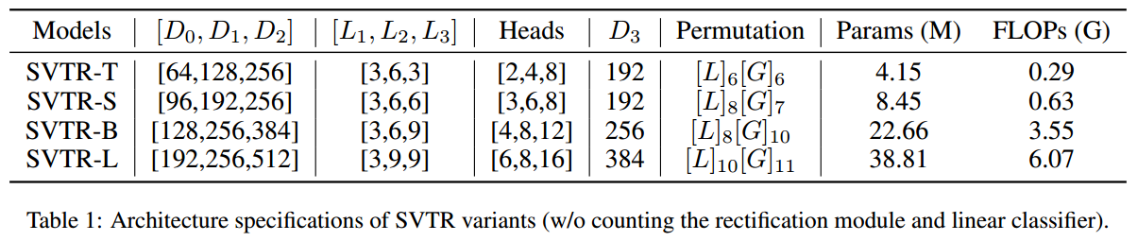
5、Architecture Variants
即SVTRT(微小)、SVTR-S(小)、SVTR-B(基本)和SVTR-L(大)
三、实验,Experiments
1、Datasets

2、Ablation Study
所有实验都是在没有整流模块和数据扩充的情况下使用SVTR-T进行的,
The Effectiveness of Patch Embedding

The Effectiveness of Merging
合并不仅降低了计算成本,而且提高了两个数据集的准确性。验证了在高度维度上进行多尺度采样对文本识别的有效性
The Permutation of Mixing Blocks
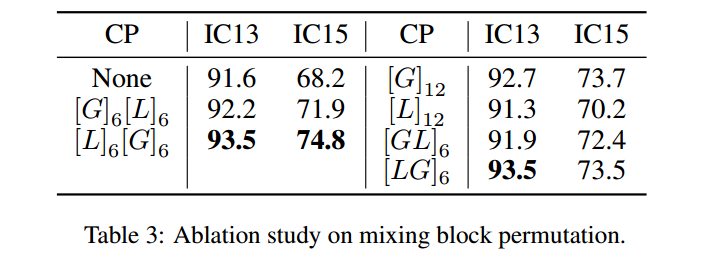
[G]6[L]6:对于每个阶段,首先进行六个全局混合块,然后进行六个局部混合块。几乎每种方案都有一定的精度提高。在不规则文本上相对较大的增益进一步解释了混合块有助于复杂场景中的特征学习。[L]6[G]6报告的准确度最好。通过将局部混合块置于全局混合块之前,有利于引导全局混合块专注于长期相关性捕获。
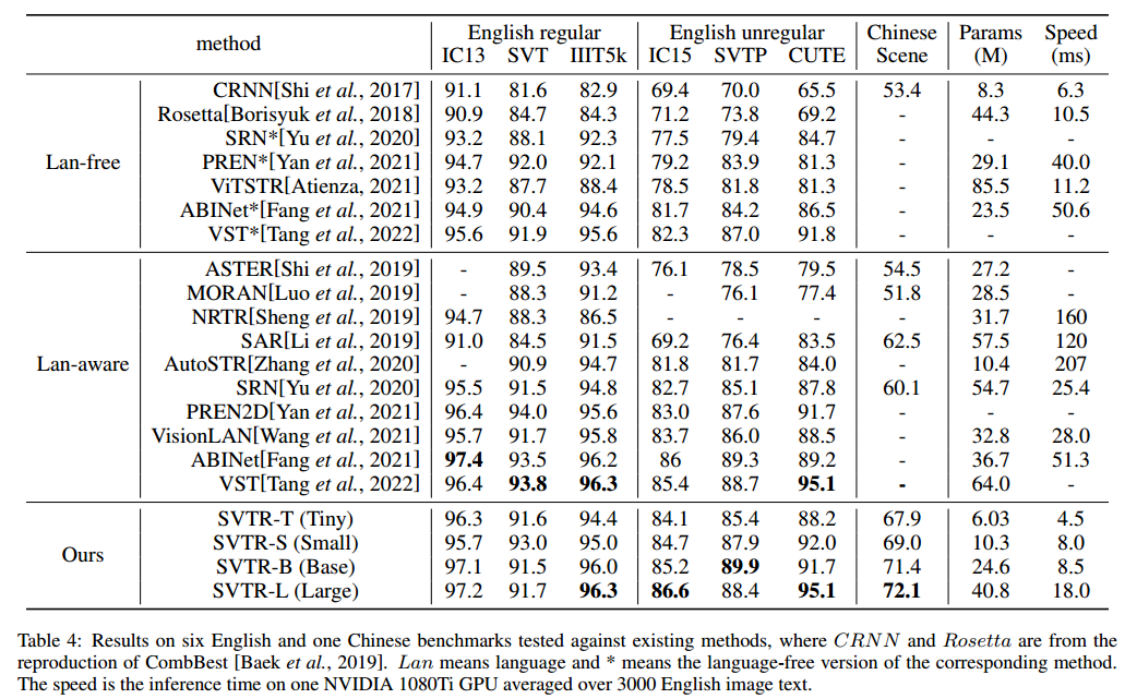
3、Comparison with State-of-the-Art
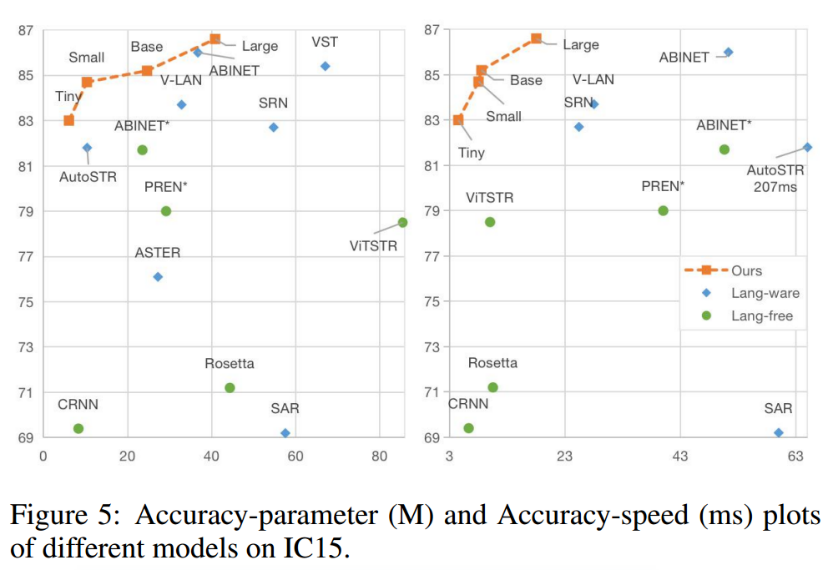
speed在1080ti上推理:
4、Visualization Analysis
