注1:本文系“计算成像最新论文速览”系列之一,致力于简洁清晰地介绍、解读非视距成像领域最新的顶会/顶刊论文(包括但不限于 Nature/Science及其子刊; CVPR, ICCV, ECCV, SIGGRAPH, TPAMI; Light‐Science & Applications, Optica 等)。

本次介绍的论文是: IJCAI, 2023, Acoustic NLOS Imaging with Cross-Modal Knowledge Distillation
文章DOI: https://www.ijcai.org/proceedings/2023/
IJCAI 2023 | 基于跨模态知识蒸馏的声学非视距成像
1 引言
非视距成像是一种通过分析信号的反射来重建隐藏场景的技术。它具有广阔的应用前景,如自动驾驶、医学成像等。但是传统的基于光学的非视距成像方法容易受到噪声的影响。最近,利用声波进行非视距成像的研究层出不穷。但是现有的方法要么依赖于脆弱的物理模型,要么难以重建未见过的物体。本文提出了一种跨模态知识蒸馏(CMKD)的方法,有效地结合了图像和音频两个模态,使得模型既对噪声鲁棒,又能很好地推广到未见过的物体上。
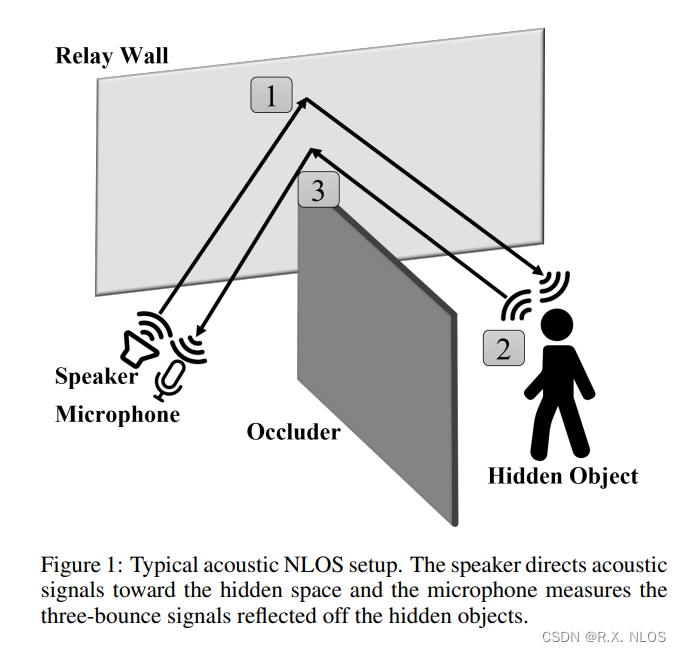
2 动机
物理模型方法依赖于声波的飞行时间等信息,但是环境噪声很容易对其造成干扰。利用深度学习的方法虽然能够从数据中学习有效的特征,但是对未见过的物体的重建效果不佳。如何结合两个模态的优势是本文的一个关键思路。
图像 modal 能很好地表示视觉细节和空间信息。而音频 modal 则擅长捕捉动态信息。如果把图像网络作为教师网络,让音频网络在训练过程中学习它的知识,那么音频网络就可以获得更强的推广性。这种跨模态的知识迁移也可以增强模型对噪声的鲁棒性。
所以本文提出了一种跨模态知识蒸馏的框架,通过让音频网络模仿图像网络的输出,来获得图像网络提取全局信息的能力,从而在只用音频的条件下也可以进行高质量的非视距重建。
3 方法
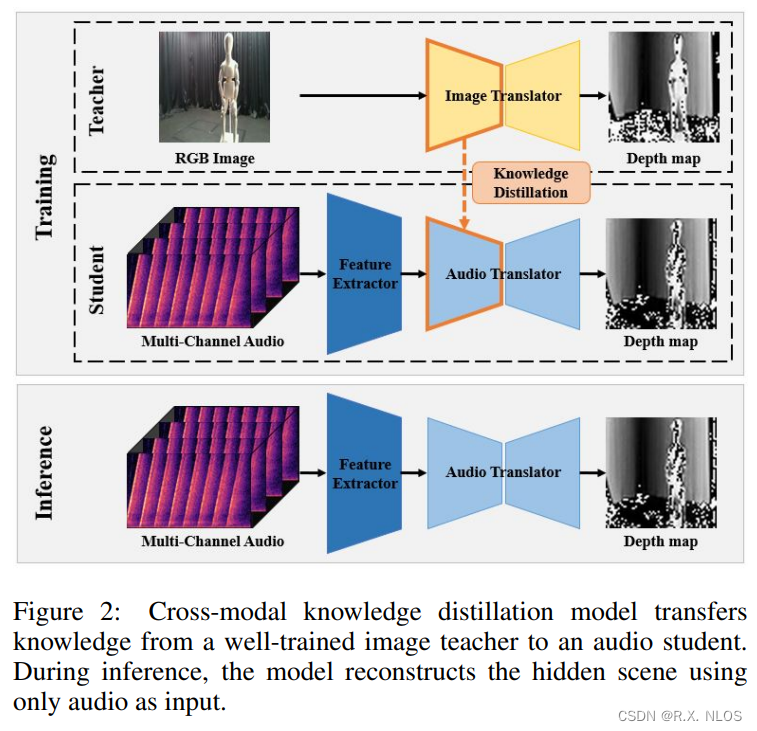

整个框架由图像教师网络和音频学生网络组成,如上图所示。训练分两个阶段:

(1) 先训练好图像网络,使其能够从 RGB 图像生成深度图。
(2) 固定图像网络参数,训练音频网络转换多音道音频信号为深度图,同时通过知识蒸馏损失迫使其模仿图像网络的输出。
3.1 图像教师网络
图像网络采用 U-Net 结构的自动编码器,包含编码器和解码器。编码器从 RGB 图像中提取特征,解码器将特征重构为深度图。
3.2 音频学生网络
音频网络包含三个部分:
-
音频特征提取器:将多音道音频作为输入,输出特征表示
-
转换器:将特征转换为深度图
-
判别器:判断预测的深度图是否真实
这里的关键是音频特征提取器用了3D 卷积来提取音频的时空特征。而转换器与图像网络具有相同的结构,以便进行知识迁移。
3.3 目标函数
图像网络使用 L 1 L1 L1 损失进行监督。
G t ∗ = min G t L Depth ( G t ) G_t^*=\min _{G_t} \mathcal{L}_{\text {Depth }}\left(G_t\right) Gt∗=minGtLDepth (Gt)
音频网络除了有转换器的重建损失、判别器的对抗损失,还加入了师生网络编码器之间的知识蒸馏损失。这个损失用来减小两个网络在特征空间的距离,迫使音频网络模仿图像网络的特征提取能力。
G s ∗ = min G s max D s 1 2 L G A N ( D s ) + L G A N ( G s ) + α L Depth ( G s ) + β L K D ( G s ) \begin{array}{r}G_s^*=\min _{G_s} \max _{D_s} \frac{1}{2} \mathcal{L}_{G A N}\left(D_s\right)+\mathcal{L}_{G A N}\left(G_s\right)+ \\ \alpha \mathcal{L}_{\text {Depth }}\left(G_s\right)+\beta \mathcal{L}_{K D}\left(G_s\right)\end{array} Gs∗=minGsmaxDs21LGAN(Ds)+LGAN(Gs)+αLDepth (Gs)+βLKD(Gs)
4 实验与结果
作者构建了实际的音频采集系统,收集了大量对应的图像、深度图和多音道音频数据。在这个数据集上进行训练和评估。
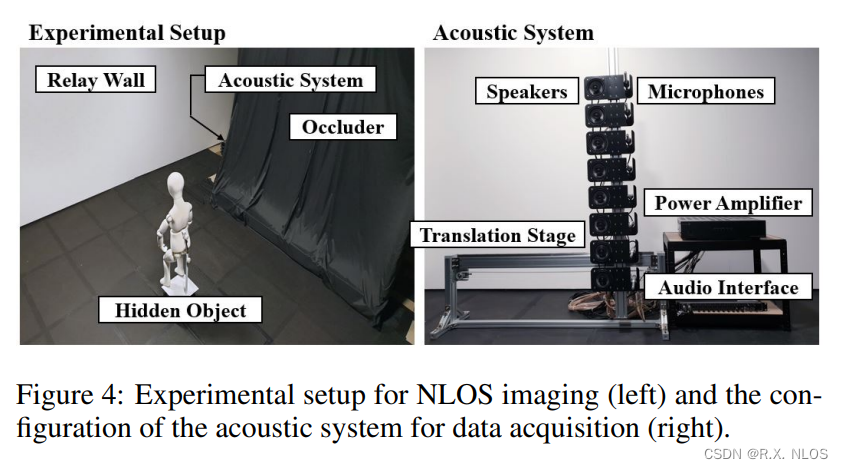

主要的比较方法包括:
- 基于物理模型的方法
- 直接从音频重建场景的方法
- 利用层次音频编码器的方法
实验结果表明,提出的 CMKD 方法在重建训练物体和未见物体上都优于其他基准方法。这充分验证了跨模态知识迁移的有效性。
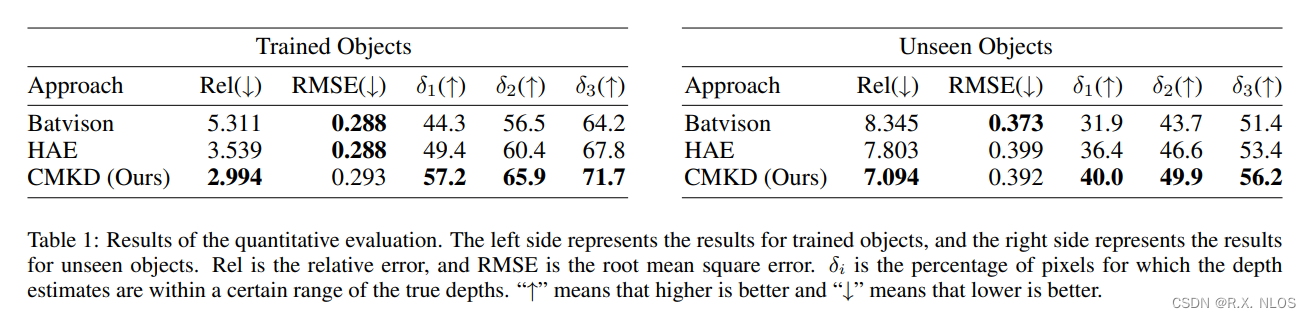

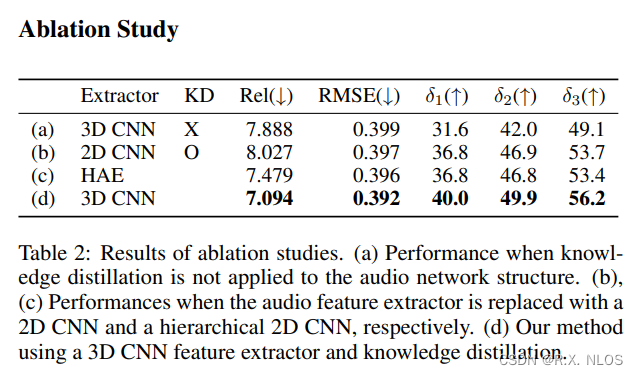
另外作者还进行了详细的ablation study。结果证明了3D卷积特征提取器和知识蒸馏的重要性。
5 不足与展望
本文方法在重建材质和类别不同的未见物体上仍存在一定困难。这可能与数据集物体种类的局限性有关。未来的数据收集可以覆盖更丰富、形状各异的物体。
另外,也可以尝试不同的跨模态框架,如让音频网络反过来指导图像网络,实现知识的双向迁移。
6 总结
本文提出了跨模态知识蒸馏的声学非视距成像方法。实验表明,这种方法可以充分利用两个模态的优势,使得模型对噪声更加鲁棒,同时能够很好地推广到未见过的物体。这为声学非视距成像提供了一个有前景的思路。
通过图像网络指导音频网络的训练,音频网络获得了提取全局信息、进行高质量重建的能力。这种跨模态的框架设计也可推广到其他领域,是一种有效的知识迁移范式。