本人是一名Android Developer, 对人工智能比较感兴趣,所以决定自学进入这一领域,一边学一边通过写日志的方式巩固自己的知识,也许写的不是很好,但是希望能够给志同道合的人们一些帮助。
朴素贝叶斯
朴素贝叶斯法是基于贝叶斯定理与特征条件独立假设的分类方法 。最为广泛的两种分类模型是决策树模型(Decision Tree Model)和朴素贝叶斯模型(Naive Bayesian Model,NBM)。
和决策树模型相比,朴素贝叶斯分类器(Naive Bayes Classifier,或 NBC)发源于古典数学理论,有着坚实的数学基础,以及稳定的分类效率。同时,NBC模型所需估计的参数很少,对缺失数据不太敏感,算法也比较简单。理论上,NBC模型与其他分类方法相比具有最小的误差率。但是实际上并非总是如此,这是因为NBC模型假设属性之间相互独立,这个假设在实际应用中往往是不成立的,这给NBC模型的正确分类带来了一定影响。
- 例子
我们举一个例子,Linda和Tom喜欢写邮件,我们把Linda和Tom写的邮件的内容的词语进行标记,我们需要达到一个目的,根据一条未读邮件的相关词汇,就能够预测这个这篇邮件是属于Tom还是属于Linda。首先,我们为了让大家更好理解一点,我们把两位目标的邮件内容模型进行简化,简化成只有三个词语。如下图:
上图中,分别从Linda和Tom的所使用的语句中选取Love、Work和Life作为关键词,经过对两位的大量的email的数据分析,总结了上面蓝颜色的概率统计,分别是对应的出现频率,那么现在对一封出现了Love和Work的email进行预测,应该是属于谁的email?我们首先需要假定一个初始概率系统,不需要要求对,因为这个系数会不断被训练进行纠正。假设属于Linda和Tom的概率都为50%
现在进行分析:
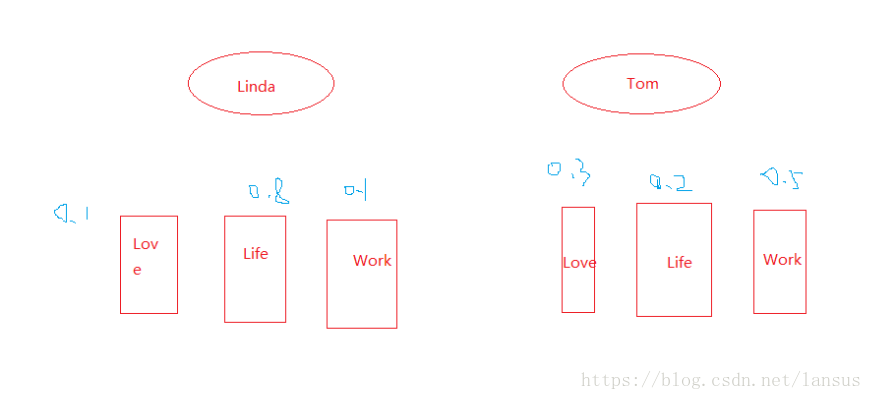
Linda的事件: P(Love)=0.1 , P(Life)=0.8 ,P(Work)=0.1
P(Love,LIfe)=P(Love)*P(Work)=0.1*0.1=0.01
Tom的事件: P(Love)=0.3 , P(Life)=0.2 ,P(Work)=0.5
P(Love,LIfe)=P(Love)*P(Work)=0.3*0.5=0.15
进行归一:
Linda :P(Love,Life)=(0.01*0.5)=0.005
Tom :P(Love,Life)=0.015*0.5=0.075
所以这封信属于Linda的概率:
P((LOve,Work)|All)=0.005/(0.005+0.075)=6.25%
所以这封信属于Tom的概率:
P((LOve,Work)|All)=0.005/(0.005+0.075)=93.75%,所以很有可能是Tom的。
- 含义
上面描述的是简单的朴素贝叶斯的例子,也许跟很多人写出的贝叶斯公式进行对比,感觉好简单,但是这的的确确就是使用了朴素贝叶斯.
这个在250多年前发明的算法,在信息领域内有着无与伦比的地位。贝叶斯分类是一系列分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类。朴素贝叶斯算法(Naive Bayesian) 是其中应用最为广泛的分类算法之一。
朴素贝叶斯分类器基于一个简单的假定:给定目标值时属性之间相互条件独立。
通过以上定理和“朴素”的假定,我们知道:
P( Category | Document) = P ( Document | Category ) * P( Category) / P(Document) - 说明
朴素贝叶斯,有很多有点,比较大的一个优点是可以忽略事件的顺序,例如上面例子,就可以不用考虑词语使用的前后顺序,但是也有很多缺点,有时候会非常的不准确,所以又必须使用到另外一个方法,支持向量机(Support Vector Mechine),是一个俄罗斯人提出来的。下个章节我们接着说。