利用朴素贝叶斯算法实现新闻分类
实验背景
在新闻类APP中,按照不同标签对新闻分类可以令读者更快速的查找到自己想要阅读的新闻。新闻分类数据集有C000008财经、C000010IT、C000013健康、C000014体育、C000016旅游、C000020教育、C000022招聘、C000023文化、C000024军事九类组成。
分类思路
朴素贝叶斯理论认为假定给定目标值时属性之间相互条件独立,即多目标属性和单目标属性并不会产生太大差异。利用朴素贝叶斯,我们可以实现多目标的分类——欺诈分析、新闻分类。
想要实现新闻的分类,我们需要首先设计一下实验步骤。在这里,我们首先假定已经获取了新闻文本数据集,不需要爬虫再获取。
1、读取本地储存的新闻文本数据集。
2、把中文文本拆分成一个又一个的词。
3、将所有文本分成训练集和测试集,并对训练集中的所有单词进行词频统计,并按降序排序,过滤掉最高频的k个。因为例如“的”,“了”这种并不能反应出新闻类别。
4、测试过滤词的数量与测试准确率之间的关系。
5、找到最优过滤词数量后用测试集进行机器学习。
可能用到的方法
1、读取本地储存的文本需要用到os库。
2、拆分中文文本需要用到jieba库。
3、需要创建空list列表,储存拆分后的文本信息和删除高频词后的文本信息。
实际操作
引入类库
import os
import random
import jieba #中文语句分割
from sklearn.naive_bayes import MultinomialNB
import matplotlib.pyplot as plt
import matplotlib as mpl
遍历所有txt文件
所有的txt文件是储存在SogouC/Sample/C0000xx下的,所以需要用for循环把他们全部遍历一下,这里主要的难点在于构造文件路径。
folder_path = './SogouC/Sample'
folder_list = os.listdir(folder_path) # 查看folder_path下的文件
data_list = [] # 数据集数据
class_list = [] # 数据集类别
for folder in folder_list:
new_folder_path = os.path.join(folder_path, folder) # 根据子文件夹,生成新的路径
files = os.listdir(new_folder_path) # 存放子文件夹下的txt文件的列表
# 至此,所有的txt文件的路径已经可以全部生成,接下来之需要打开每一个txt文件把信息调取出来
# 这里files的路径为./SogouC/Sample/C0000xx,如果需要打开txt只需要join一下txt就行
j = 1
# 遍历每个txt文件
for file in files:
if j > 100: # 每类txt样本数最多100个
break
with open(os.path.join(new_folder_path, file), 'r', encoding='utf-8') as f: # 打开txt文件
raw = f.read()
word_cut = jieba.cut(raw, cut_all=False) # 精简模式,返回一个可迭代的generator
word_list = list(word_cut) # generator转换为list
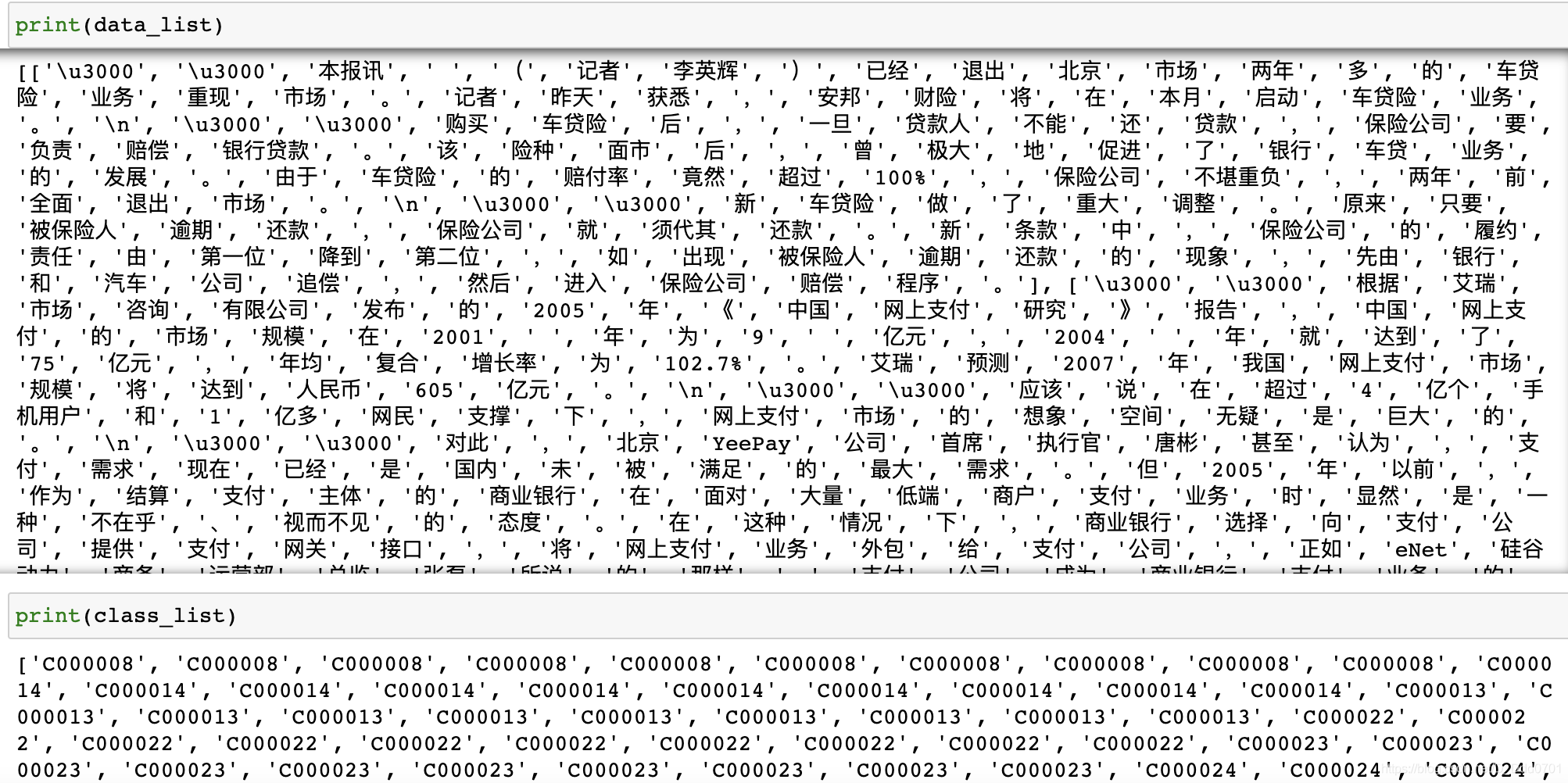
data_list.append(word_list) # 添加数据集数据
class_list.append(folder) # 添加数据集类别
j += 1
此时,所有的文字切片已经被储存在了data_list,所有的新闻分类标签已经被储存在了class_list。
组合切片文本和标签
但是这样会存在一个问题,前面的很多都是C000008,后面又都是C000014,这样就会导致学习出现一定的“惯性”,会影响最后的精度,所以我们需要对碎片文本信息先绑定各自的标签,然后进行随机打乱。
data_class_list = list(zip(data_list, class_list))
random.shuffle(data_class_list) # 将data_class_list乱序
创建训练集和测试集
打乱完成之后,把zip后的元祖拆开,并设定80%的数据用作训练,20%用于测试。
test_size = 0.2
index = int(len(data_class_list) * test_size) + 1 # 训练集和测试集切分的索引值
train_list = data_class_list[index:] # 训练集
test_list = data_class_list[:index] # 测试集
train_data_list, train_class_list = zip(*train_list) # 训练集解压缩
test_data_list, test_class_list = zip(*test_list) # 测试集解压缩
统计词频
统计词频一定是字典格式的,因为我们需要统计出{‘某文本’:‘次数’}。
all_words_dict = {
} # 统计训练集词频
for word_list in train_data_list:
for word in word_list:
if word in all_words_dict.keys():
all_words_dict[word] += 1
else:
all_words_dict[word] = 1
统计的词频倒序排列
# 根据键的值倒序排序
all_words_tuple_list = sorted(all_words_dict.items(), key=lambda f: f[1], reverse=True)
# 这里的key=lambda f: f[1]表示对前面的对象中的第二维数据(即value)的值进行排序。
# key=lambda 变量:变量[维数] 。维数可以按照自己的需要进行设置。
all_words_list, all_words_nums = zip(*all_words_tuple_list) # 解压缩
all_words_list = list(all_words_list) # 转换成列表
至此,所有的文本出现的次数已经全部统计完毕。接下来删除调高频词。
过滤停顿词
这里,我们准备了一个停顿词的文本:

接下来,我们要过滤这些停顿词。
stopwords_file = './stopwords_cn.txt'
stopwords_set = set() # 创建set集合
with open(stopwords_file, 'r', encoding='utf-8') as f: # 打开文件
for line in f.readlines(): # 一行一行读取
word = line.strip() # 去回车
if len(word) > 0: # 有文本,则添加到words_set中
stopwords_set.add(word)

创建机器学习
这一步比较复杂,需要好好理解。
我们应该定义某类新闻对应的特征词,这一类特征词应该具有以下特性:1、删除高频次之后的;2、不在stopwords_set内的;3、不是数字的;4、单词长度大于1小于5的。把这一类特征词收集下来,与对应的新闻种类对应起来学习。
因为到底过滤掉前面多少高频词语去掉对机器学习最好不得而知,所以我们设计很多个删除值,最后分别学习测试,来判断学习效果。机器学习过程中对文本实现一一比对实际上是很麻烦的一件事,所以我们可以用数字0和1替代——如果是该文本是特征词,则是1,如果不是,则是0。
deleteNs = range(0, 1000, 20)
test_accuracy_list = []
def text_features(text, feature_words): # 出现在特征集中,则置1
text_words = set(text)
features = [1 if word in text_words else 0 for word in feature_words]
return features
for deleteN in deleteNs:
feature_words = [] # 特征列表
n = 1
for t in range(deleteN, len(all_words_list), 1):
if n > 1000: # feature_words的维度为1000
break
# 如果这个词不是数字,并且不是指定的结束语,并且单词长度大于1小于5,那么这个词就可以作为特征词
if not all_words_list[t].isdigit() and all_words_list[t] not in stopwords_set and 1 < len(all_words_list[t]) < 5:
feature_words.append(all_words_list[t])
n += 1
train_feature_list = [text_features(text, feature_words) for text in train_data_list]
test_feature_list = [text_features(text, feature_words) for text in test_data_list]
classifier = MultinomialNB().fit(train_feature_list, train_class_list)
test_accuracy = classifier.score(test_feature_list, test_class_list)
test_accuracy_list.append(test_accuracy)
绘图查看过滤多少高频词学习效果最好
mpl.rcParams['font.sans-serif'] = ['SimHei']
plt.figure(dpi=100)
plt.plot(deleteNs, test_accuracy_list)
plt.title('删除词的数量与测试准确率之间的关系') #删除词的数量与测试准确率之间的关系
plt.xlabel('删除词的数量')
plt.ylabel('测试集准确度')
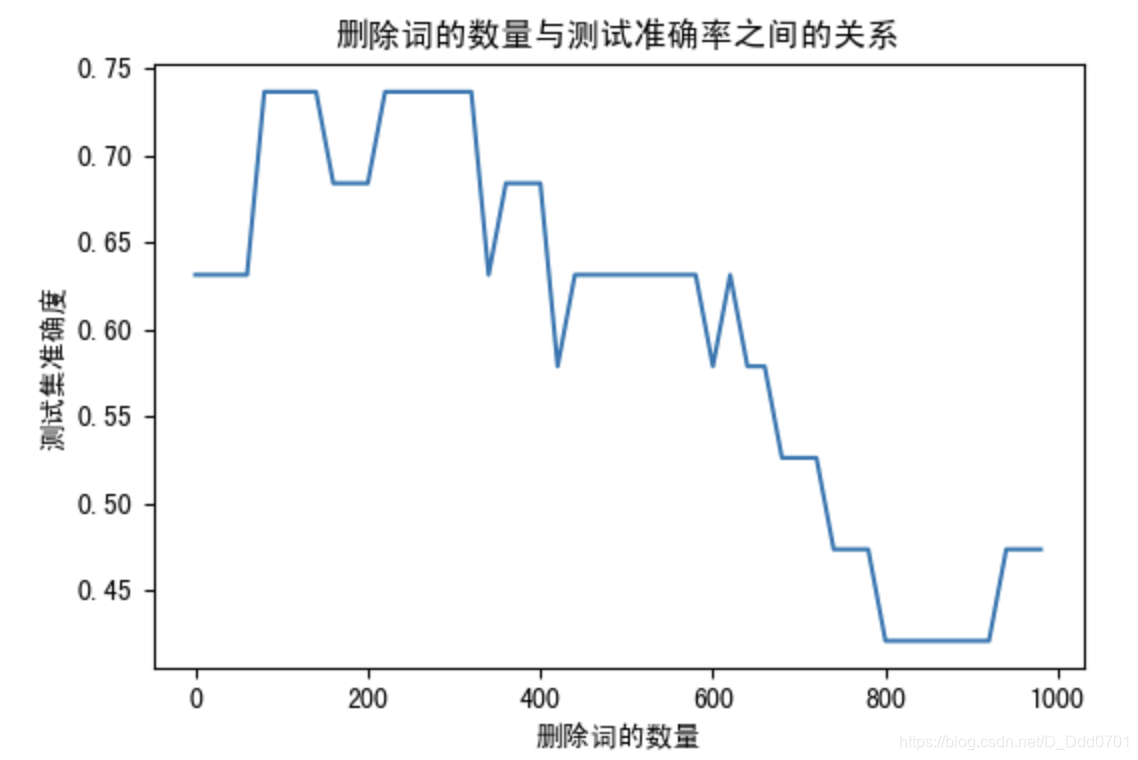
我们发现,过滤前300高频词的话效果最好。
选择最优解实现分类
deleteN=300
feature_words = [] # 特征列表
n = 1
for t in range(deleteN, len(all_words_list), 1):
if n > 1000: # feature_words的维度为1000
break
# 如果这个词不是数字,并且不是指定的结束语,并且单词长度大于1小于5,那么这个词就可以作为特征词
if not all_words_list[t].isdigit() and all_words_list[t] not in stopwords_set and 1 < len(all_words_list[t]) < 5:
feature_words.append(all_words_list[t])
n += 1
train_feature_list = [text_features(text, feature_words) for text in train_data_list]
test_feature_list = [text_features(text, feature_words) for text in test_data_list]
classifier = MultinomialNB().fit(train_feature_list, train_class_list)
test_accuracy = classifier.score(test_feature_list, test_class_list)
test_accuracy_list.append(test_accuracy)
print(feature_words[:50])
print('\n\n')
print('识别正确率:',sum(test_accuracy_list)/len(test_accuracy_list))
