一、全概率公式和贝叶斯公式
1、全概率公式


2、贝叶斯公式

二、朴素贝叶斯算法
1、算法简介
贝叶斯分类算法是统计学的一种分类方法,其分类原理就是利用贝叶斯公式根据某对象的先验概率计算出其后验概率,然后选择具有最大后验概率的类作为该对象所属的类。之所以称之为”朴素”,是因为贝叶斯分类只做最原始、最简单的假设:所有的特征之间是统计独立的(假设某样本x有a1,…,aM个属性,那么有P(x)=P(a1,…,aM) = P(a1)*…*P(aM);)
2、算法思想
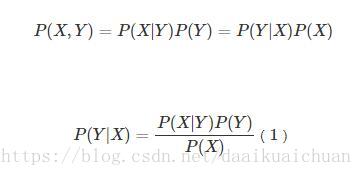


3、算法流程
(1)常规算法

(2)贝叶斯估计
由于使用极大似然估计可能会出现概率值为0的情况,所以引入拉普拉斯平滑,称为贝叶斯估计。

4、算法demo(常规贝叶斯估计)

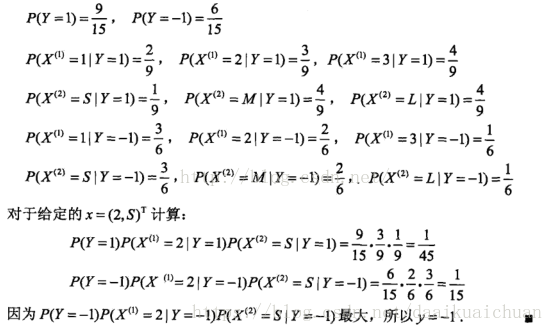
#include <iostream>
#include <iomanip>
#include <map>
#include <vector>
#include <string>
#include <algorithm>
#include <cstdio>
using namespace std;
int main()
{
vector<int> X1 = { 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3 };
vector<char> X2 = { 'S', 'M', 'M', 'S', 'S', 'S', 'M', 'M',
'L', 'L', 'L', 'M', 'M', 'L', 'L' };
vector<int> Y = { -1, -1, 1, 1, -1, -1, -1, 1, 1, 1, 1, 1, 1, 1, -1 };
int x1;
char x2;
cin >> x1;
cin.get();
cin >> x2;
map<string, double> ycount;//记录y = 1和-1的次数
map<string, double> x1count1;//记录y=1,-1 ,x1匹配的次数
map<string, double> x2count1;//记录y=1,-1 ,x2匹配的次数
int ysize = Y.size();
for (int i = 0; i < ysize; ++i)
{
if (Y[i] == 1)
{
ycount["y=1"]++;
if (X1[i] == x1)
x1count1["y=1"]++;
if (X2[i] == x2)
x2count1["y=1"]++;
}
else
{
ycount["y=-1"]++;
if (X1[i] == x1)
x1count1["y=-1"]++;
if (X2[i] == x2)
x2count1["y=-1"]++;
}
}
//计算概率
double rs1 = ycount["y=1"] / ysize * x1count1["y=1"] / ycount["y=1"] * x2count1["y=1"] / ycount["y=1"];
double rs2 = ycount["y=-1"] / ysize * x1count1["y=-1"] / ycount["y=-1"] * x2count1["y=-1"] / ycount["y=-1"];
cout << fixed << setprecision(2) << rs1 << " " << rs2 << endl;
(rs1 > rs2) ? cout << "y=1" : cout << "y=-1";
cout << endl;
system("pause");
return 0;
}二、朴素贝叶斯算法的优缺点及应用
1、优点
1. 算法简单;
2. 所需估计参数很少;
3. 对缺失数据不太敏感;
4. 朴素贝叶斯的条件概率计算彼此是独立的,因此特别适于分布式计算;
5. 朴素贝叶斯属于生成式模型,收敛速度将快于判别模型(如逻辑回归);
6. 天然可以处理多分类问题。
2、缺点
1. 因为朴素贝叶斯分类假设样本各个特征之间相互独立,这个假设在实际应用中往往是不成立的,从而影响分类正确性;
2. 不能学习特征间的相互作用;
3. 对输入数据的表达形式很敏感。
3、应用
贝叶斯定理广泛应用于决策分析。先验概率经常是由决策者主观估计的。在选择最佳决策时,会在取得样本信息后计算后验概率以供决策者使用。
用户流失预测,文本分类,垃圾邮件过滤等。
参考:https://blog.csdn.net/Hearthougan/article/details/75174210
https://blog.csdn.net/IDMer/article/details/48809677
https://blog.csdn.net/chunyun0716/article/details/51058948
https://www.cnblogs.com/arachis/p/NB.html