目录
2.4 数据湖联邦查询
进入正文之前,欢迎订阅专题、对博文点赞、评论、收藏,关注IT贫道,获取高质量博客内容!
1.Apache Doris 介绍
Apache Doris 是一个基于 MPP 架构的高性能、实时的分析型数据库,以极速易用的特点被人们所熟知,仅需亚秒级响应时间即可返回海量数据下的查询结果,不仅可以支持高并发的点查询场景,也能支持高吞吐的复杂分析场景。基于此,Apache Doris 能够较好的满足报表分析、即席查询、统一数仓构建、数据湖联邦查询加速等使用场景,用户可以在此之上构建用户行为分析、AB 实验平台、日志检索分析、用户画像分析、订单分析等应用。
Apache Doris 最早是诞生于百度广告报表业务的 Palo 项目,2017 年正式对外开源,2018 年 7 月由百度捐赠给 Apache 基金会进行孵化,之后在 Apache 导师的指导下由孵化器项目管理委员会成员进行孵化和运营。目前 Apache Doris 社区已经聚集了来自不同行业近百家企业的 400 余位贡献者,并且每月活跃贡献者人数也接近 100 位。 2022 年 6 月,Apache Doris 成功从 Apache 孵化器毕业,正式成为 Apache 顶级项目(Top-Level Project,TLP)。
Apache Doris 如今在中国乃至全球范围内都拥有着广泛的用户群体,截止目前, Apache Doris 已经在全球超过 1000 家企业的生产环境中得到应用,在中国市值或估值排行前 50 的互联网公司中,有超过 80% 长期使用 Apache Doris,包括百度、美团、小米、京东、字节跳动、腾讯、网易、快手、微博、贝壳等。同时在一些传统行业如金融、能源、制造、电信等领域也有着丰富的应用。
Apache Doris官网为https://doris.apache.org。
注意:MPP:Massively Parallel Processing ,大规模并行处理。一般说的MPP架构指的是分布式数据库,数据处理时有多个节点,每个节点有独立的磁盘和内存,并发task分散到各个节点各自处理各自的数据,计算完成后最终把结果汇集在一起形成最后结果。
MPP可以看成分为MPP DB 和MPP架构,例如Hadoop架构就是MPP架构,都是大规模分布式处理,也就是分布式处理架构,只是MPP 这个词是数据库厂商早期提出的,一般特指分布式数据库。所以理解MPP这个概念可以理解成MPP是一个高纬度概念,MPP可以分成 MPP DB 和MPP架构两个概念,Hadoop 或者MR 就是MPP 架构,MPPDB 就是说的分布式数据库,跟严格来说Doris是一个MPP DB ,只是业界普遍称为MPP架构的分布式数据库。
Apache Doris并非是DorisDB ,由于各种复杂原因,DorisDB后期改名为StarRocks,也就是说DorisDB 是StarRocks的前身。Doris 最早是解决百度凤巢统计报表的专用系统,随着百度业务的飞速发展对系统进行了多次迭代,逐渐承担起百度内部业务的统计报表和多维分析需求。2013 年,百度把 Doris 进行了 MPP 框架的升级,并将新系统命名为 Palo ,2017 年更改为百度 Palo 的名字在 GitHub 上进行了开源,2018 年贡献给 Apache 基金会时,由于与国外数据库厂商重名,因此选择用回最初 Doris 名字,这就是 Apache Doris 的由来。
2020 年 2 月,百度 Doris 团队的个别同学离职创业,基于 Apache Doris 之前的版本做了自己的商业化闭源产品 DorisDB ,这就是 StarRocks 的前身。具体可以参考:https://www.sohu.com/a/488816742_827544。
2. Apache Doris使用场景
如下图所示,数据源经过各种数据集成和加工处理后,通常会入库到实时数仓 Doris 和离线湖仓(Hive, Iceberg, Hudi 中),Apache Doris 被广泛应用在以下场景中。
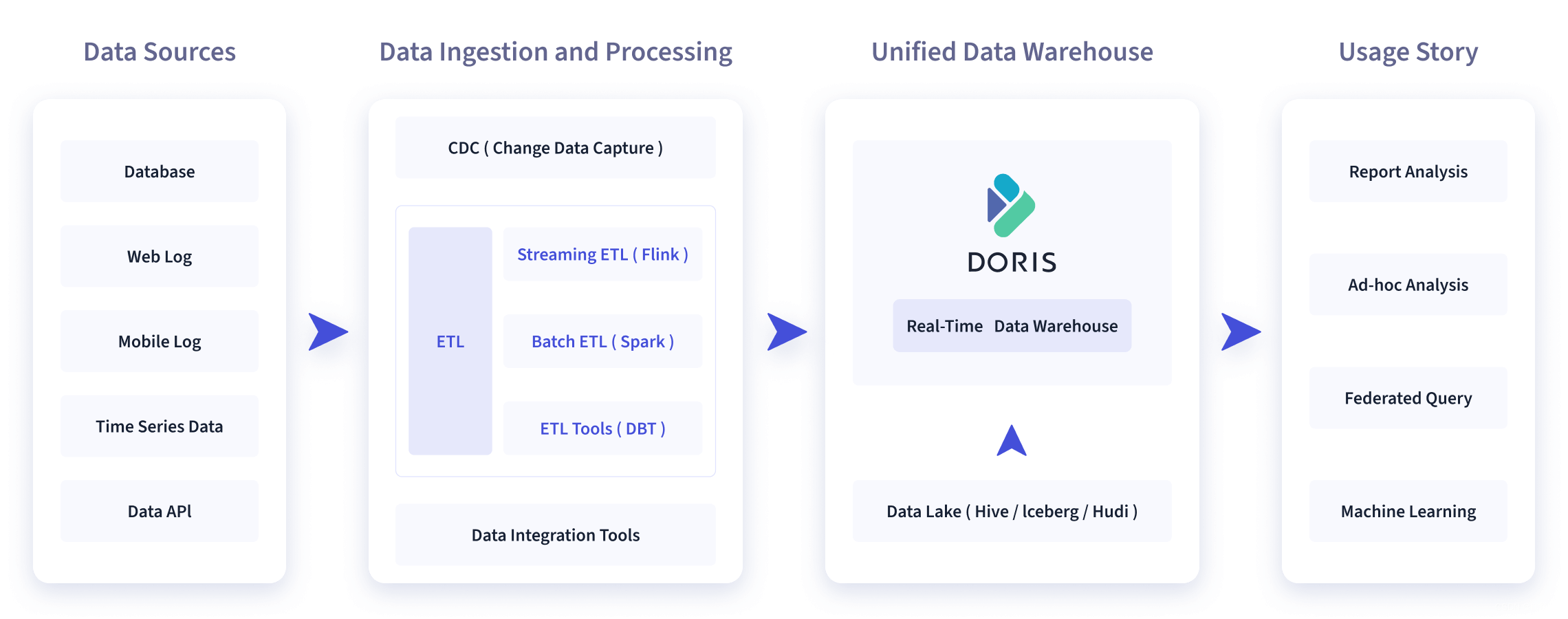
2.1 报表分析
- 实时看板 (Dashboards)。
- 面向企业内部分析师和管理者的报表。
- 面向用户或者客户的高并发报表分析(Customer Facing Analytics)。比如面向网站主的站点分析、面向广告主的广告报表,并发通常要求成千上万的 QPS ,查询延时要求毫秒级响应。著名的电商公司京东在广告报表中使用 Apache Doris ,每天写入 100 亿行数据,查询并发 QPS 上万,99 分位的查询延时 150ms。
2.2 即席查询(Ad-hoc Query)
面向分析师的自助分析,查询模式不固定,要求较高的吞吐。小米公司基于 Doris 构建了增长分析平台(Growing Analytics,GA),利用用户行为数据对业务进行增长分析,平均查询延时 10s,95 分位的查询延时 30s 以内,每天的 SQL 查询量为数万条。
2.3 统一数仓构建
一个平台满足统一的数据仓库建设需求,简化繁琐的大数据软件栈。海底捞基于 Doris 构建的统一数仓,替换了原来由 Spark、Hive、Kudu、Hbase、Phoenix 组成的旧架构,架构大大简化。
2.4 数据湖联邦查询
通过外表的方式联邦分析位于 Hive、Iceberg、Hudi 中的数据,在避免数据拷贝的前提下,查询性能大幅提升。