前言
本文隶属于专栏《大数据技术体系》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢!
本专栏目录结构和参考文献请见大数据技术体系
PPT 下载
WHAT
Apache Doris 是一个基于MPP架构的高性能实时分析 OLAP 引擎,以其极快的速度和易用性而闻名。
它只需要亚秒的响应时间即可在海量数据下返回查询结果,并且不仅可以支持高并发点查询场景,还可以支持高吞吐量复杂分析场景。
发展历程
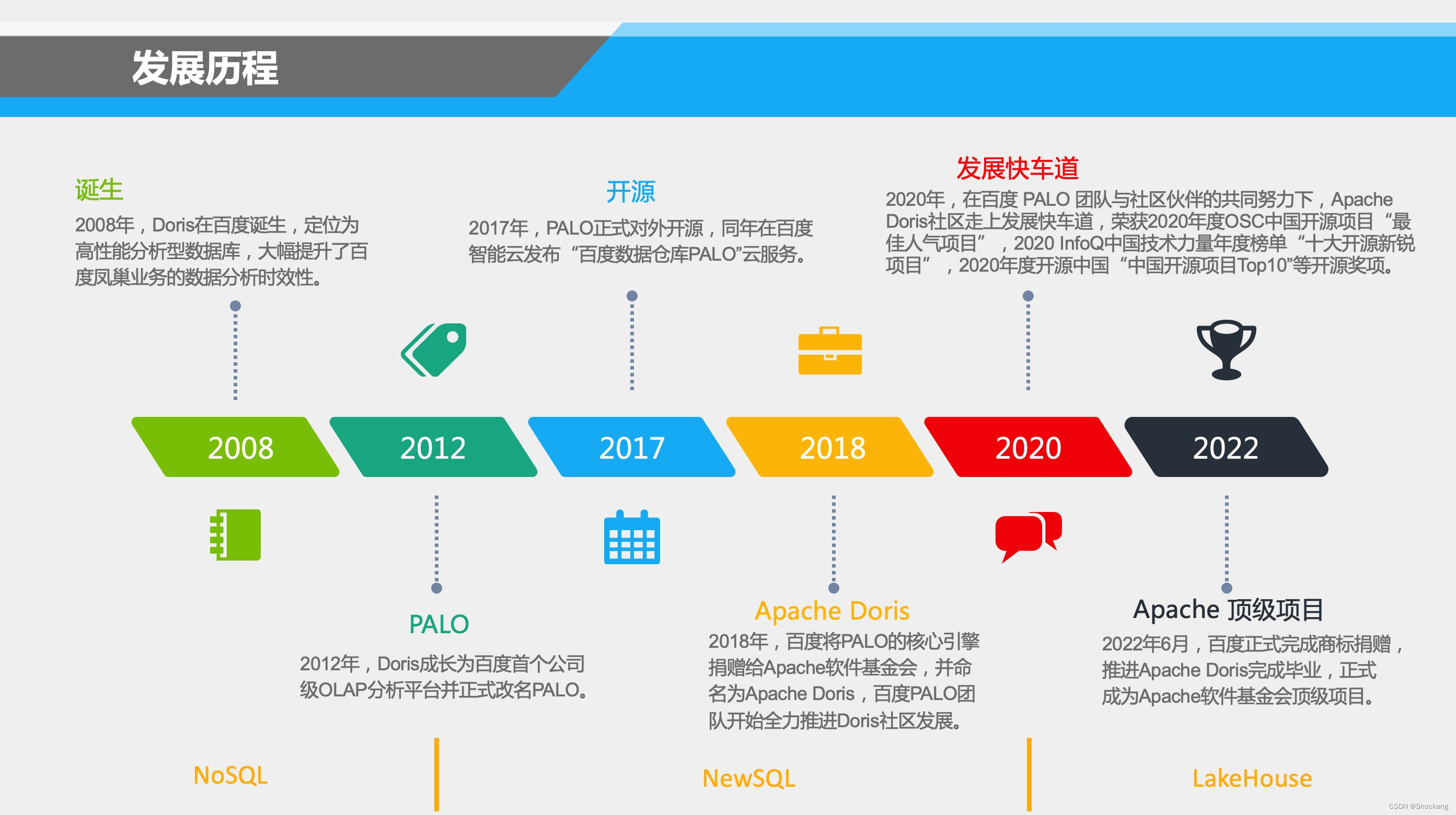
2008年,2008年,Doris在百度诞生,定位为高性能分析型数据库,大幅提升了百度凤巢业务的数据分析时效性。
2012年,Doris 成长为百度首个公司级 OLAP 分析平台并正式改名 PALO。
PALO 的倒写正是 OLAP
2017年,PALO 正式对外开源,同年在百度智能云发布“百度数据仓库 PALO”云服务。
2018年,百度将 PALO 的核心引擎捐赠给 Apache 软件基金会,并命名为 Apache Doris,百度 PALO 团队开始全力推进 Doris 社区发展。
2020年,在百度 PALO 团队与社区伙伴的共同努力下,Apache Doris 社区走上发展快车道,获取了多个开源项目大奖,包括:2020 年度 OSC 中国开源项目“最佳人气项目”,2020 InfoQ 中国技术力量年度榜单“十大开源新锐项目”,2020 年度开源中国“中国开源项目 Top10”等开源奖项。
2022 年 6 月,百度正式完成商标捐赠,推进 Apache Doris 完成毕业,正式成为 Apache 软件基金会顶级项目。
2012 年之前,Doris 的定位就是一个 NoSQL 数据库。
关于 NoSQL 请参考我的博客——NoSQL是什么?
2012~2020 年期间,Doris 的定位是 NewSQL,也就是说除了要兼顾存储海量数据,也要具备 RDBMS 的 ACID 特性以及对于 SQL 的支持能力。
2020 年以后,Doris 的定位是 Lakehouse。
关于 Lakehouse 请参考我的博客——湖仓一体(Lakehouse)是什么?
使用场景

- 报表分析可视化
- 实时仪表板
- 内部分析师和经理的报告
- 高度并发的面向用户或面向客户的报表分析
- ad-hoc
- 以分析师为导向的自助服务分析,具有不规则的查询模式和高吞吐量要求。
- 统一数据仓库建设
- 一个满足统一数据仓库建设需求和简化复杂数据软件堆栈的平台。
- 流批一体
- 实时数仓
- 数据湖查询
- 通过使用外部表联合位于 Apache Hive、Apache Iceberg 和Apache Hudi 中的数据,查询性能大大提高,同时避免了数据复制。
设计目标
因为技术和需求会随着时间发生变化,Doris 也会跟着每个阶段去制定不同的目标。
第一阶段 Doris 主要还是满足专用系统的统计分析需求,第二阶段主要是满足通用的报表与数据分析可视化需求。
到今天,我们发现用户或者客户对数据的分析需求,逐渐收敛为三大块:
50% 的需求依旧是各类报表和数据分析可视化需求,就是我们经常提的 BI 的需求;
20-30% 的需求,是对日志等半结构化数据的搜索分析需求;
20-30% 的需求,是对数据科学与机器学习的需求;
而新的 Doris 将会针对这三类场景,进行重点功能和性能设计,以便支撑这三类需求。
Doris 最初的定位是新式数仓,满足在线的数据分析场景,主要以高并发小查询的性能最为出色。
但是发展到今天,它的定位正在发生变化,这个主要变化可以用 一个 T 形(一纵两横) 来说明。
一纵就是指把原来 Doris 最擅长的在线结构化 MPP 数据分析性能优化到最快,而导入实时化、存储读写性能优化、计算性能优化,这些会学习和借鉴 ClickHouse 的一些设计。
两横之一是支持半结构化数据,当前全球很多对日志等半结构化数据分析都使用 Elasticsearch,Doris 后续会加强对 ES 所支持场景的满足能力;
另一横,就是拥抱云原生技术,支持存算分离,支持较大的查询,满足对数据科学与机器学习场景的支持,这一块需要多去借鉴 Snowflake 和 Databricks 的一些设计。
当前 Doris 的新目标,就是主攻这个类似 T 形的一纵两横。
优劣势
优势
- 支持实时、离线导入,支持外部表
- 支持高并发查询,支持单表查询明细,多表联合查询
- 支持 MySQL 协议,完全兼容 MySQL 语法
- 支持 3 种数据模型,Aggregate/Unique/Duplicate
- 极简运维,架构简单,扩容简单,滚动升级
- 支持物化视图,动态分区,冷热分层
- 百度背书,社区比较活跃
Apache Doris 的单表查询明细性能略逊于 ClickHouse,但是多表JOIN 却比 CK 强,在所有开源产品中排名第一。
Apache Doris 诞生之初就定位于兼容 MySQL,它对于 MySQL 的支持的非常好,最近几年因为拥抱开源选择去兼容 Hive SQL,所以,不可能做到兼容得比较好,一些 Hive 内置函数和 UDF 等都做的不太好,如果公司有历史数仓的包袱,暂时不太建议立即转 Doris。
Aggregate 表示的是将键相同的值进行聚合;Unique 代表的是唯一的键值对;Duplicate 代码的是允许重复(键值都可以重复)
Apache Doris 的集群角色只有两个:Frontend(FE,前台节点,负责元数据保存与请求分发),Backend(BE,后台节点,负责具体的计算与存储),所以运维起来非常的方便。
劣势
- 不够成熟
- 对传统数仓兼容性比较低
- 云原生支持低
- 不支持半结构化数据
- 不支持大窗口
- C++
Apache Doris 需要借助 Elasticsearch 才能支持半结构化的数据。
Apache Doris 由于是内存计算,大窗口场景内存显然扛不住。
Apache Doris 的 FE 是 Java 开发的,BE 是 C++ 开发的,性能要好,但是社区活跃度相对来说比 Java 的要低。另外,笔者目前不太会 C++,底层问题定位与二次开发起来有难度。
主流的 OLAP 引擎对比
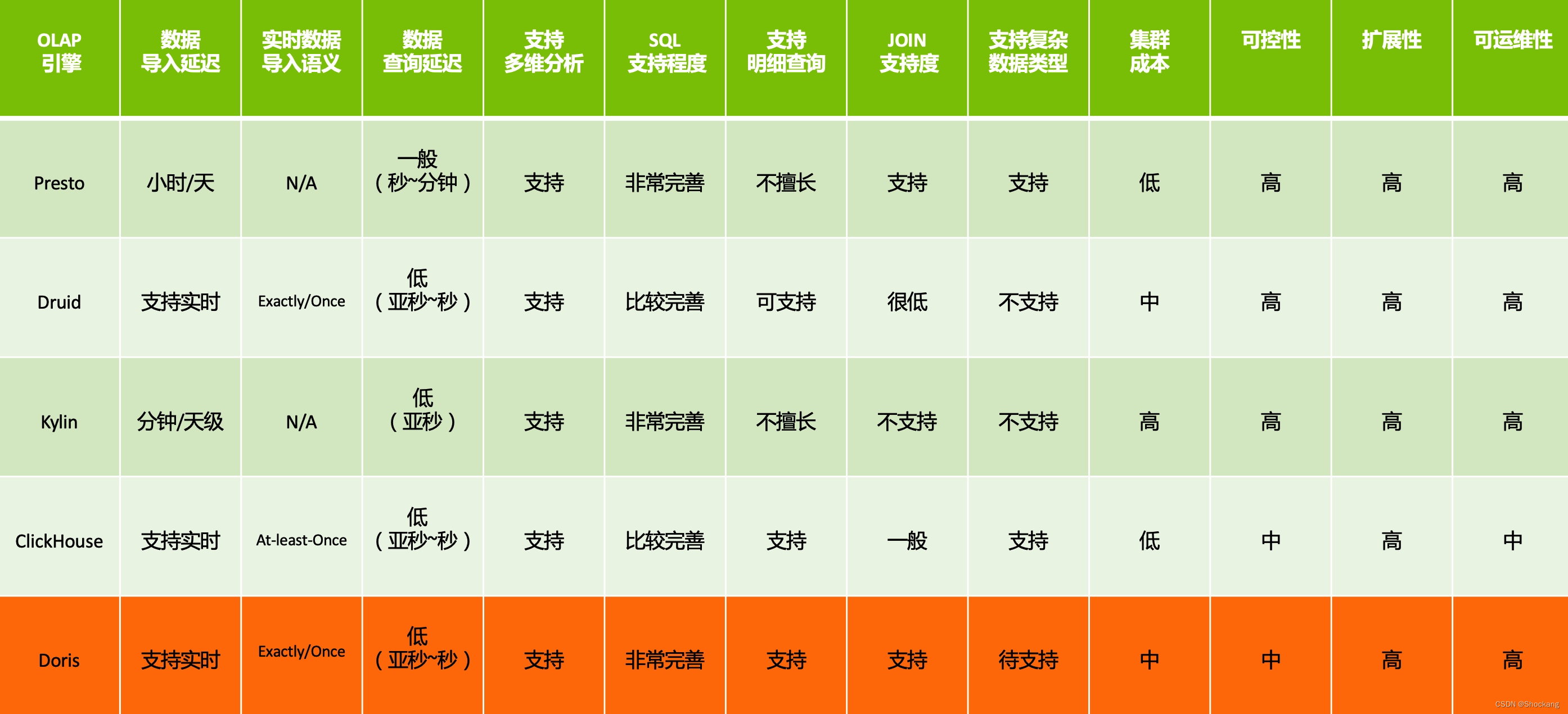
- Presto 相对来说显著的优点是社区成熟度较高,不同的场景都有与之对应的解决方案,但是不支持实时导入,另外也不擅长单表明细查询。
- Druid 和 Kylin 都是 MOLAP 引擎,不是当前的主流(主流是 ROLAP),其中 Doris 显著的缺点是集群角色过多(有 5,6 个之多),集群运维管理起来非常麻烦;Kylin 的缺点是部署依赖也过多,构建依赖 Spark,存储依赖 HBase(Kylin 4.x 后使用的 Parquet)。
- ClickHouse 和 Doris 两者是针锋相对的,CK 是俄罗斯最大的搜索引擎公司开发的,而 Doris 是我国最大的搜索引擎公司;CK 2016 年开源之后,紧接着 2017 年,百度就将 Doris 也开源了;CK 的单表查询明细性能稍强于 Doris,但是 Doris 的多表 JOIN 性能也是领先于 CK。
Doris 适合现在的企业级开发吗?
Apache Doris 支持实时数据的快速分析,支持多源联邦构建,支持高性能的多表 JOIN,支持 MySQL 协议,简单易上手,独立于 Hadoop 生态,相对来说运维成本较低,而且有百度为其背书,国内众多的互联网大厂都有在使用,社区相对来说也比较活跃,整体发展形式还好;但是 Doris 目前也有着比较显著的缺点,一方面不够成熟,bug 比较多(主要集中在兼容开源生态的过程中,内核是很稳定的,毕竟在百度跑了这么多年),生态不够完善,也不太兼容 Hive 等传统数仓;另一方面内核是 C++ 开发的,对于 Java 开发者来说底层的问题定位和二次开发等不太方便,另外社区生态也比不上 Java 这边。
具体怎么选择需要企业来平衡利弊,如果没有比较深的历史数仓包袱,Doris 也是一个不错的选择,否则建议还是稍等两年。