5、doris的查询语法
5.1、doris查询语法整体结构
SELECT
[ALL | DISTINCT | DISTINCTROW ] -- 对查询字段的结果是否需要去重,还是全部保留等参数
select_expr [, select_expr ...] -- select的查询字段
[FROM table_references
[PARTITION partition_list] -- from 哪个库里面的那张表甚至哪一个(几个)分区
[WHERE where_condition] -- WHERE 查询
[GROUP BY {col_name | expr | position} -- group by 聚合
[ASC | DESC], ... [WITH ROLLUP]]
[HAVING where_condition] -- having 针对聚合函数的再一次过滤
[ORDER BY {col_name | expr | position} -- 对结果数据按照字段进行排序
[ASC | DESC], ...] -- 排序规则
[LIMIT {
[offset,] row_count | row_count OFFSET offset}] -- 限制输出多少行内容
[INTO OUTFILE 'file_name'] -- 将查询的结果导出到文件中
5.2、doris内置函数
1、条件函数
1、if条件函数
if(boolean condition, type valueTrue, type valueFalseOrNull)
--如果表达式 condition 成立,返回结果 valueTrue;否则,返回结果 valueFalseOrNull
--返回值类型:valueTrue 表达式结果的类型
mysql> select user_id, if(user_id = 1, "true", "false") as test_if from test;
+---------+---------+
| user_id | test_if |
+---------+---------+
| 1 | true |
| 2 | false |
+---------+---------+
2、ifnull,nvl,coalesce,nullif函数
ifnull(expr1, expr2)
--如果 expr1 的值不为 NULL 则返回 expr1,否则返回 expr2
nvl(expr1, expr2)
--如果 expr1 的值不为 NULL 则返回 expr1,否则返回 expr2
coalesce(expr1, expr2, ...., expr_n))
--返回参数中的第一个非空表达式(从左向右)
nullif(expr1, expr2)
-- 如果两个参数相等,则返回NULL。否则返回第一个参数的值
mysql> select ifnull(1,0);
+--------------+
| ifnull(1, 0) |
+--------------+
| 1 |
+--------------+
mysql> select nvl(null,10);
+------------------+
| nvl(null,10) |
+------------------+
| 10 |
+------------------+
mysql> select coalesce(NULL, '1111', '0000');
+--------------------------------+
| coalesce(NULL, '1111', '0000') |
+--------------------------------+
| 1111 |
+--------------------------------+
mysql> select coalesce(NULL, NULL,NULL,'0000', NULL);
+----------------------------------------+
| coalesce(NULL, NULL,NULL,'0000', NULL) |
+----------------------------------------+
| 0000 |
+----------------------------------------+
mysql> select nullif(1,1);
+--------------+
| nullif(1, 1) |
+--------------+
| NULL |
+--------------+
mysql> select nullif(1,0);
+--------------+
| nullif(1, 0) |
+--------------+
| 1 |
+--------------+
3、case
-- 方式一
CASE expression
WHEN condition1 THEN result1
[WHEN condition2 THEN result2]
...
[WHEN conditionN THEN resultN]
[ELSE result]
END
-- 方式二
CASE WHEN condition1 THEN result1
[WHEN condition2 THEN result2]
...
[WHEN conditionN THEN resultN]
[ELSE result]
END
-- 将表达式和多个可能的值进行比较,当匹配时返回相应的结果
mysql> select user_id,
case user_id
when 1 then 'user_id = 1'
when 2 then 'user_id = 2'
else 'user_id not exist'
end as test_case
from test;
+---------+-------------+
| user_id | test_case |
+---------+-------------+
| 1 | user_id = 1 |
| 2 | user_id = 2 |
| 3 | 'user_id not exist' |
+---------+-------------+
mysql> select user_id,
case
when user_id = 1 then 'user_id = 1'
when user_id = 2 then 'user_id = 2'
else 'user_id not exist'
end as test_case
from test;
+---------+-------------+
| user_id | test_case |
+---------+-------------+
| 1 | user_id = 1 |
| 2 | user_id = 2 |
+---------+-------------+
2、聚合函数
1、min,max,sum,avg,count
2、min_by和max_by
MAX_BY(expr1, expr2)
返回expr2最大值所在行的 expr1 字段值 (求分组top1的简介函数)
MySQL > select * from tbl;
+------+------+------+------+
| k1 | k2 | k3 | k4 |
+------+------+------+------+
| 0 | 3 | 2 | 100 |
| 1 | 2 | 3 | 4 |
| 4 | 3 | 2 | 2 |
| 3 | 4 | 2 | 1 |
+------+------+------+------+
MySQL > select max_by(k1, k4) from tbl;
select max_by(k1, k4) from tbl;
--取k4这个列中的最大值对应的k1这个列的值
+--------------------+
| max_by(`k1`, `k4`) |
+--------------------+
| 0 |
+--------------------+
练习数据
name subject score
zss,chinese,99
zss,math,89
zss,English,79
lss,chinese,88
lss,math,88
lss,English,22
www,chinese,99
www,math,45
zll,chinese,23
zll,math,88
zll,English,80
www,English,94
-- 建表语句
create table score
(
name varchar(50),
subject varchar(50),
score double
)
DUPLICATE KEY(name)
DISTRIBUTED BY HASH(name) BUCKETS 1;
-- 通过本地文件的方式导入数据
curl \
-u root: \
-H "label:salary" \
-H "column_separator:," \
-T /root/data/salary.txt \
http://zuomm01:8040/api/test/salary/_stream_load
-- 求每门课程成绩最高分的那个人
select
subject,max_by(name,score) as name
from score
group by subject
+---------+------+
| subject | name |
+---------+------+
| English | www |
| math | lss |
| chinese | www |
+---------+------+
3、group_concat
简单来说:就是分组聚合的指定字段进行聚合,默认以 “,”进行分隔
求:每一个人有考试成绩的所有科目
select name, group_concat(subject,‘,’) as all_subject from score group by name
VARCHAR GROUP_CONCAT([DISTINCT] VARCHAR 列名[, VARCHAR sep]
该函数是类似于 sum() 的聚合函数,group_concat 将结果集中的多行结果连接成一个字符串
-- group_concat对于收集的字段只能是string,varchar,char类型
--当不指定分隔符的时候,默认使用 ','
VARCHAR :代表GROUP_CONCAT函数返回值类型
[DISTINCT]:可选参数,针对需要拼接的列的值进行去重
[, VARCHAR sep]:拼接成字符串的分隔符,默认是 ','
示例
--建表
create table example(
id int,
name varchar(50),
age int,
gender string,
is_marry boolean,
marry_date date,
marry_datetime datetime
)engine = olap
distributed by hash(id) buckets 3;
--插入数据
insert into example values \
(1,'zss',18,'male',0,null,null),\
(2,'lss',28,'female',1,'2022-01-01','2022-01-01 11:11:11'),\
(3,'ww',38,'male',1,'2022-02-01','2022-02-01 11:11:11'),\
(4,'zl',48,'female',0,null,null),\
(5,'tq',58,'male',1,'2022-03-01','2022-03-01 11:11:11'),\
(6,'mly',18,'male',1,'2022-04-01','2022-04-01 11:11:11'),\
(7,null,18,'male',1,'2022-05-01','2022-05-01 11:11:11');
--当收集的那一列,有值为null时,他会自动将null的值过滤掉
select
gender,
group_concat(name,',') as gc_name
from example
group by gender;
+--------+---------------+
| gender | gc_name |
+--------+---------------+
| female | zl,lss |
| male | zss,ww,tq,mly |
+--------+---------------+
select
gender,
group_concat(DISTINCT cast(age as string)) as gc_age
from example
group by gender;
+--------+------------+
| gender | gc_age |
+--------+------------+
| female | 48, 28 |
| male | 58, 38, 18 |
+--------+------------+
**4、collect_list,collect_set **
ARRAY<T> collect_list(expr)
--返回一个包含 expr 中所有元素(不包括NULL)的数组,数组中元素顺序是不确定的。
ARRAY<T> collect_set(expr)
--返回一个包含 expr 中所有去重后元素(不包括NULL)的数组,数组中元素顺序是不确定的。
3、日期函数
1、获取当前时间
curdate,current_date,now,curtime,current_time,current_timestamp
select current_date();
+----------------+
| current_date() |
+----------------+
| 2022-11-25 |
+----------------+
select curdate();
+------------+
| curdate() |
+------------+
| 2022-11-25 |
+------------+
select now();
+---------------------+
| now() |
+---------------------+
| 2022-11-25 00:55:15 |
+---------------------+
select curtime();
+-----------+
| curtime() |
+-----------+
| 00:42:13 |
+-----------+
select current_timestamp();
+---------------------+
| current_timestamp() |
+---------------------+
| 2022-11-25 00:42:30 |
+---------------------+
2、last_day
DATE last_day(DATETIME date)
-- 返回输入日期中月份的最后一天;
--'28'(非闰年的二月份),
--'29'(闰年的二月份),
--'30'(四月,六月,九月,十一月),
--'31'(一月,三月,五月,七月,八月,十月,十二月)
select last_day('2000-03-03 01:00:00'); -- 给我返回这个月份中的最后一天的日期 年月日
ERROR 1105 (HY000): errCode = 2, detailMessage = No matching function with signature: last_day(varchar(-1)).
10、from_unixtime
DATETIME FROM_UNIXTIME(INT unix_timestamp[, VARCHAR string_format])
-- 将 unix 时间戳转化为对应的 time 格式,返回的格式由 string_format 指定
--支持date_format中的format格式,默认为 %Y-%m-%d %H:%i:%s
-- 正常使用的三种格式
yyyyMMdd
yyyy-MM-dd
yyyy-MM-dd HH:mm:ss
mysql> select from_unixtime(1196440219);
+---------------------------+
| from_unixtime(1196440219) |
+---------------------------+
| 2007-12-01 00:30:19 |
+---------------------------+
mysql> select from_unixtime(1196440219, 'yyyy-MM-dd HH:mm:ss');
+--------------------------------------------------+
| from_unixtime(1196440219, 'yyyy-MM-dd HH:mm:ss') |
+--------------------------------------------------+
| 2007-12-01 00:30:19 |
+--------------------------------------------------+
mysql> select from_unixtime(1196440219, '%Y-%m-%d');
+-----------------------------------------+
| from_unixtime(1196440219, '%Y-%m-%d') |
+-----------------------------------------+
| 2007-12-01 |
+-----------------------------------------+
3、unix_timestamp
UNIX_TIMESTAMP(),
UNIX_TIMESTAMP(DATETIME date),
UNIX_TIMESTAMP(DATETIME date, STRING fmt) -- 给一个日期,指定这个日期的格式
-- 将日期转换成时间戳,返回值是一个int类型
-- 获取当前日期的时间戳
select unix_timestamp();
+------------------+
| unix_timestamp() |
+------------------+
| 1669309722 |
+------------------+
-- 获取指定日期的时间戳
select unix_timestamp('2022-11-26 01:09:01');
+---------------------------------------+
| unix_timestamp('2022-11-26 01:09:01') |
+---------------------------------------+
| 1669396141 |
+---------------------------------------+
-- 给定一个特殊日期格式的时间戳,指定格式
select unix_timestamp('2022-11-26 01:09-01', '%Y-%m-%d %H:%i-%s');
+------------------------------------------------------------+
| unix_timestamp('2022-11-26 01:09-01', '%Y-%m-%d %H:%i-%s') |
+------------------------------------------------------------+
| 1669396141 |
+------------------------------------------------------------+
4、to_date
DATE TO_DATE(DATETIME)
--返回 DATETIME 类型中的日期部分。
select to_date("2022-11-20 00:00:00");
+--------------------------------+
| to_date('2022-11-20 00:00:00') |
+--------------------------------+
| 2022-11-20 |
+--------------------------------+
13、extract
extract(unit FROM DATETIME) --抽取
-- 提取DATETIME某个指定单位的值。
--unit单位可以为year, month, day, hour, minute或者second
select
extract(year from '2022-09-22 17:01:30') as year,
extract(month from '2022-09-22 17:01:30') as month,
extract(day from '2022-09-22 17:01:30') as day,
extract(hour from '2022-09-22 17:01:30') as hour,
extract(minute from '2022-09-22 17:01:30') as minute,
extract(second from '2022-09-22 17:01:30') as second;
+------+-------+------+------+--------+--------+
| year | month | day | hour | minute | second |
+------+-------+------+------+--------+--------+
| 2022 | 9 | 22 | 17 | 1 | 30 |
+------+-------+------+------+--------+--------+
5、date_add,date_sub,datediff
DATE_ADD(DATETIME date,INTERVAL expr type)
DATE_SUB(DATETIME date,INTERVAL expr type)
DATEDIFF(DATETIME expr1,DATETIME expr2)
-- 计算两个日期相差多少天,结果精确到天。
-- 向日期添加指定的时间间隔。
-- date 参数是合法的日期表达式。
-- expr 参数是您希望添加的时间间隔。
-- type 参数可以是下列值:YEAR, MONTH, DAY, HOUR, MINUTE, SECOND
elect date_add('2010-11-30 23:59:59', INTERVAL 2 DAY);
+-------------------------------------------------+
| date_add('2010-11-30 23:59:59', INTERVAL 2 DAY) |
+-------------------------------------------------+
| 2010-12-02 23:59:59 |
+-------------------------------------------------+
--传一个负数进去也就等同于date_sub
select date_add('2010-11-30 23:59:59', INTERVAL -2 DAY);
+--------------------------------------------------+
| date_add('2010-11-30 23:59:59', INTERVAL -2 DAY) |
+--------------------------------------------------+
| 2010-11-28 23:59:59 |
+--------------------------------------------------+
mysql> select datediff('2022-11-27 22:51:56','2022-11-24 22:50:56');
+--------------------------------------------------------+
| datediff('2022-11-27 22:51:56', '2022-11-24 22:50:56') |
+--------------------------------------------------------+
| 3 |
+--------------------------------------------------------+
6、date_format
VARCHAR DATE_FORMAT(DATETIME date, VARCHAR format)
--将日期类型按照format的类型转化为字符串
select date_format('2007-10-04 22:23:00', '%H:%i:%s');
+------------------------------------------------+
| date_format('2007-10-04 22:23:00', '%H:%i:%s') |
+------------------------------------------------+
| 22:23:00 |
+------------------------------------------------+
select date_format('2007-10-04 22:23:00', 'yyyy-MM-dd');
+------------------------------------------------+
| date_format('2007-10-04 22:23:00', '%Y-%m-%d') |
+------------------------------------------------+
| 2007-10-04 |
+------------------------------------------------+
4、字符串函数
1、length,lower,upper,reverse
获取到字符串的长度,对字符串转大小写和字符串的反转
2、lpad,rpad
VARCHAR rpad(VARCHAR str, INT len, VARCHAR pad)
VARCHAR lpad(VARCHAR str, INT len, VARCHAR pad)
-- 返回 str 中长度为 len(从首字母开始算起)的字符串。
--如果 len 大于 str 的长度,则在 str 的后面不断补充 pad 字符,
--直到该字符串的长度达到 len 为止。如果 len 小于 str 的长度,
--该函数相当于截断 str 字符串,只返回长度为 len 的字符串。
--len 指的是字符长度而不是字节长度。
-- 向左边补齐
SELECT lpad("1", 5, "0");
+---------------------+
| lpad("1", 5, "0") |
+---------------------+
| 00001 |
+---------------------+
-- 向右边补齐
SELECT rpad('11', 5, '0');
+---------------------+
| rpad('11', 5, '0') |
+---------------------+
| 11000 |
+---------------------+
3、concat,concat_ws
select concat("a", "b");
+------------------+
| concat('a', 'b') |
+------------------+
| ab |
+------------------+
select concat("a", "b", "c");
+-----------------------+
| concat('a', 'b', 'c') |
+-----------------------+
| abc |
+-----------------------+
-- concat中,如果有一个值为null,那么得到的结果就是null
mysql> select concat("a", null, "c");
+------------------------+
| concat('a', NULL, 'c') |
+------------------------+
| NULL |
+------------------------+
--使用第一个参数 sep 作为连接符
--将第二个参数以及后续所有参数(或ARRAY中的所有字符串)拼接成一个字符串。
-- 如果分隔符是 NULL,返回 NULL。concat_ws函数不会跳过空字符串,会跳过 NULL 值。
mysql> select concat_ws("_", "a", "b");
+----------------------------+
| concat_ws("_", "a", "b") |
+----------------------------+
| a_b |
+----------------------------+
mysql> select concat_ws(NULL, "d", "is");
+----------------------------+
| concat_ws(NULL, 'd', 'is') |
+----------------------------+
| NULL |
+----------------------------+
4、substr
-求子字符串,返回第一个参数描述的字符串中从start开始长度为len的部分字符串。
--首字母的下标为1。
mysql> select substr("Hello doris", 2, 1);
+-----------------------------+
| substr('Hello doris', 2, 1) |
+-----------------------------+
| e |
+-----------------------------+
mysql> select substr("Hello doris", 1, 2);
+-----------------------------+
| substr('Hello doris', 1, 2) |
+-----------------------------+
| He |
+-----------------------------+
5、ends_with,starts_with
BOOLEAN ENDS_WITH (VARCHAR str, VARCHAR suffix)
--如果字符串以指定后缀结尾,返回true。否则,返回false。
--任意参数为NULL,返回NULL。
BOOLEAN STARTS_WITH (VARCHAR str, VARCHAR prefix)
--如果字符串以指定前缀开头,返回true。否则,返回false。
--任意参数为NULL,返回NULL。
mysql> select ends_with("Hello doris", "doris");
+-----------------------------------+
| ends_with('Hello doris', 'doris') |
+-----------------------------------+
| 1 |
+-----------------------------------+
mysql> select ends_with("Hello doris", "Hello");
+-----------------------------------+
| ends_with('Hello doris', 'Hello') |
+-----------------------------------+
| 0 |
+-----------------------------------+
MySQL [(none)]> select starts_with("hello world","hello");
+-------------------------------------+
| starts_with('hello world', 'hello') |
+-------------------------------------+
| 1 |
+-------------------------------------+
MySQL [(none)]> select starts_with("hello world","world");
+-------------------------------------+
| starts_with('hello world', 'world') |
+-------------------------------------+
| 0 |
+-------------------------------------+
6、trim,ltrim,rtrim
VARCHAR trim(VARCHAR str)
-- 将参数 str 中左侧和右侧开始部分连续出现的空格去掉
mysql> SELECT trim(' ab d ') str;
+------+
| str |
+------+
| ab d |
+------+
VARCHAR ltrim(VARCHAR str)
-- 将参数 str 中从左侧部分开始部分连续出现的空格去掉
mysql> SELECT ltrim(' ab d') str;
+------+
| str |
+------+
| ab d |
+------+
VARCHAR rtrim(VARCHAR str)
--将参数 str 中从右侧部分开始部分连续出现的空格去掉
mysql> SELECT rtrim('ab d ') str;
+------+
| str |
+------+
| ab d |
+------+
7、null_or_empty,not_null_or_empty
BOOLEAN NULL_OR_EMPTY (VARCHAR str)
-- 如果字符串为空字符串或者NULL,返回true。否则,返回false。
MySQL [(none)]> select null_or_empty(null);
+---------------------+
| null_or_empty(NULL) |
+---------------------+
| 1 |
+---------------------+
MySQL [(none)]> select null_or_empty("");
+-------------------+
| null_or_empty('') |
+-------------------+
| 1 |
+-------------------+
MySQL [(none)]> select null_or_empty("a");
+--------------------+
| null_or_empty('a') |
+--------------------+
| 0 |
+--------------------+
BOOLEAN NOT_NULL_OR_EMPTY (VARCHAR str)
如果字符串为空字符串或者NULL,返回false。否则,返回true。
MySQL [(none)]> select not_null_or_empty(null);
+-------------------------+
| not_null_or_empty(NULL) |
+-------------------------+
| 0 |
+-------------------------+
MySQL [(none)]> select not_null_or_empty("");
+-----------------------+
| not_null_or_empty('') |
+-----------------------+
| 0 |
+-----------------------+
MySQL [(none)]> select not_null_or_empty("a");
+------------------------+
| not_null_or_empty('a') |
+------------------------+
| 1 |
+------------------------+
8、replace
VARCHAR REPLACE (VARCHAR str, VARCHAR old, VARCHAR new)
-- 将str字符串中的old子串全部替换为new串
mysql> select replace("http://www.baidu.com:9090", "9090", "");
+------------------------------------------------------+
| replace('http://www.baidu.com:9090', '9090', '') |
+------------------------------------------------------+
| http://www.baidu.com: |
+------------------------------------------------------+
9、split_part
VARCHAR split_part(VARCHAR content, VARCHAR delimiter, INT field)
-- 根据分割符拆分字符串, 返回指定的分割部分(从一开始计数)。
mysql> select split_part("hello world", " ", 1);
+----------------------------------+
| split_part('hello world', ' ', 1) |
+----------------------------------+
| hello |
+----------------------------------+
mysql> select split_part("hello world", " ", 2);
+----------------------------------+
| split_part('hello world', ' ', 2) |
+----------------------------------+
| world |
+----------------------------------+
mysql> select split_part("2019年7月8号", "月", 1);
+-----------------------------------------+
| split_part('2019年7月8号', '月', 1) |
+-----------------------------------------+
| 2019年7 |
+-----------------------------------------+
mysql> select split_part("abca", "a", 1);
+----------------------------+
| split_part('abca', 'a', 1) |
+----------------------------+
| |
+----------------------------+
10、money_format
VARCHAR money_format(Number)
-- 将数字按照货币格式输出,整数部分每隔3位用逗号分隔,小数部分保留2位
mysql> select money_format(17014116);
+------------------------+
| money_format(17014116) |
+------------------------+
| 17,014,116.00 |
+------------------------+
mysql> select money_format(1123.456);
+------------------------+
| money_format(1123.456) |
+------------------------+
| 1,123.46 |
+------------------------+
mysql> select money_format(1123.4);
+----------------------+
| money_format(1123.4) |
+----------------------+
| 1,123.40 |
+----------------------+
5、数字函数
1、ceil和floor
向上取整和向下取整
BIGINT ceil(DOUBLE x)
-- 返回大于或等于x的最小整数值.
mysql> select ceil(1);
+-----------+
| ceil(1.0) |
+-----------+
| 1 |
+-----------+
mysql> select ceil(2.4);
+-----------+
| ceil(2.4) |
+-----------+
| 3 |
+-----------+
mysql> select ceil(-10.3);
+-------------+
| ceil(-10.3) |
+-------------+
| -10 |
+-------------+
BIGINT floor(DOUBLE x)
-- 返回小于或等于x的最大整数值.
mysql> select floor(1);
+------------+
| floor(1.0) |
+------------+
| 1 |
+------------+
mysql> select floor(2.4);
+------------+
| floor(2.4) |
+------------+
| 2 |
+------------+
mysql> select floor(-10.3);
+--------------+
| floor(-10.3) |
+--------------+
| -11 |
+--------------+
2、round
四舍五入
round(x), round(x, d)
-- 将x四舍五入后保留d位小数,d默认为0。
-- 如果d为负数,则小数点左边d位为0。如果x或d为null,返回null。
mysql> select round(2.4);
+------------+
| round(2.4) |
+------------+
| 2 |
+------------+
mysql> select round(2.5);
+------------+
| round(2.5) |
+------------+
| 3 |
+------------+
mysql> select round(-3.4);
+-------------+
| round(-3.4) |
+-------------+
| -3 |
+-------------+
mysql> select round(-3.5);
+-------------+
| round(-3.5) |
+-------------+
| -4 |
+-------------+
mysql> select round(1667.2725, 2);
+---------------------+
| round(1667.2725, 2) |
+---------------------+
| 1667.27 |
+---------------------+
mysql> select round(1667.2725, -2);
+----------------------+
| round(1667.2725, -2) |
+----------------------+
| 1700 |
+----------------------+
3、abs
绝对值
数值类型 abs(数值类型 x)
-- 返回x的绝对值.
mysql> select abs(-2);
+---------+
| abs(-2) |
+---------+
| 2 |
+---------+
mysql> select abs(3.254655654);
+------------------+
| abs(3.254655654) |
+------------------+
| 3.254655654 |
+------------------+
mysql> select abs(-3254654236547654354654767);
+---------------------------------+
| abs(-3254654236547654354654767) |
+---------------------------------+
| 3254654236547654354654767 |
+---------------------------------+
4、pow
求幂
DOUBLE pow(DOUBLE a, DOUBLE b)
-- 求幂次:返回a的b次方.
mysql> select pow(2,0);
+---------------+
| pow(2.0, 0.0) |
+---------------+
| 1 |
+---------------+
mysql> select pow(2,3);
+---------------+
| pow(2.0, 3.0) |
+---------------+
| 8 |
+---------------+
mysql> select round(pow(3,2.4),2);
+--------------------+
| pow(3.0, 2.4) |
+--------------------+
| 13.966610165238235 |
+--------------------+
5、greatest和 least
greatest(col_a, col_b, …, col_n)
-- 返回一行中 n个column的最大值.若column中有NULL,则返回NULL.
least(col_a, col_b, …, col_n)
-- 返回一行中 n个column的最小值.若column中有NULL,则返回NULL.
mysql> select greatest(-1, 0, 5, 8);
+-----------------------+
| greatest(-1, 0, 5, 8) |
+-----------------------+
| 8 |
+-----------------------+
mysql> select greatest(-1, 0, 5, NULL);
+--------------------------+
| greatest(-1, 0, 5, NULL) |
+--------------------------+
| NULL |
+--------------------------+
mysql> select greatest(6.3, 4.29, 7.6876);
+-----------------------------+
| greatest(6.3, 4.29, 7.6876) |
+-----------------------------+
| 7.6876 |
+-----------------------------+
mysql> select greatest("2022-02-26 20:02:11","2020-01-23 20:02:11","2020-06-22 20:02:11");
+-------------------------------------------------------------------------------+
| greatest('2022-02-26 20:02:11', '2020-01-23 20:02:11', '2020-06-22 20:02:11') |
+-------------------------------------------------------------------------------+
| 2022-02-26 20:02:11 |
+-------------------------------------------------------------------------------+
6、数组函数
仅支持向量化引擎中使用
1、array
ARRAY<T> array(T, ...)
-- 把多个字段构造成一个数组
mysql> set enable_vectorized_engine=true;
mysql> select array("1", 2, 1.1);
+----------------------+
| array('1', 2, '1.1') |
+----------------------+
| ['1', '2', '1.1'] |
+----------------------+
1 row in set (0.00 sec)
mysql> select array(null, 1);
+----------------+
| array(NULL, 1) |
+----------------+
| [NULL, 1] |
+----------------+
1 row in set (0.00 sec)
mysql> select array(1, 2, 3);
+----------------+
| array(1, 2, 3) |
+----------------+
| [1, 2, 3] |
+----------------+
1 row in set (0.00 sec)
2、array_min,array_max,array_avg,array_sum,array_size
求数组中的最小值,最大值,平均值,数组中所有元素的和,数组的长度
-- 数组中的NULL值会被跳过。空数组以及元素全为NULL值的数组,结果返回NULL值。
3、array_remove
ARRAY<T> array_remove(ARRAY<T> arr, T val)
-- 返回移除所有的指定元素后的数组,如果输入参数为NULL,则返回NULL
mysql> set enable_vectorized_engine=true;
mysql> select array_remove(['test', NULL, 'value'], 'value');
+-----------------------------------------------------+
| array_remove(ARRAY('test', NULL, 'value'), 'value') |
+-----------------------------------------------------+
| [test, NULL] |
+-----------------------------------------------------+
mysql> select k1, k2, array_remove(k2, 1) from array_type_table_1;
+------+--------------------+-----------------------+
| k1 | k2 | array_remove(`k2`, 1) |
+------+--------------------+-----------------------+
| 1 | [1, 2, 3] | [2, 3] |
| 2 | [1, 3] | [3] |
| 3 | NULL | NULL |
| 4 | [1, 3] | [3] |
| 5 | [NULL, 1, NULL, 2] | [NULL, NULL, 2] |
+------+--------------------+-----------------------+
mysql> select k1, k2, array_remove(k2, k1) from array_type_table_1;
+------+--------------------+--------------------------+
| k1 | k2 | array_remove(`k2`, `k1`) |
+------+--------------------+--------------------------+
| 1 | [1, 2, 3] | [2, 3] |
| 2 | [1, 3] | [1, 3] |
| 3 | NULL | NULL |
| 4 | [1, 3] | [1, 3] |
| 5 | [NULL, 1, NULL, 2] | [NULL, 1, NULL, 2] |
+------+--------------------+--------------------------+
4、array_sort
ARRAY<T> array_sort(ARRAY<T> arr)
-- 返回按升序排列后的数组,如果输入数组为NULL,则返回NULL。
-- 如果数组元素包含NULL, 则输出的排序数组会将NULL放在最前面。
mysql> set enable_vectorized_engine=true;
mysql> select k1, k2, array_sort(k2) array_test;
+------+-----------------------------+-----------------------------+
| k1 | k2 | array_sort(`k2`) |
+------+-----------------------------+-----------------------------+
| 1 | [1, 2, 3, 4, 5] | [1, 2, 3, 4, 5] |
| 2 | [6, 7, 8] | [6, 7, 8] |
| 3 | [] | [] |
| 4 | NULL | NULL |
| 5 | [1, 2, 3, 4, 5, 4, 3, 2, 1] | [1, 1, 2, 2, 3, 3, 4, 4, 5] |
| 6 | [1, 2, 3, NULL] | [NULL, 1, 2, 3] |
| 7 | [1, 2, 3, NULL, NULL] | [NULL, NULL, 1, 2, 3] |
| 8 | [1, 1, 2, NULL, NULL] | [NULL, NULL, 1, 1, 2] |
| 9 | [1, NULL, 1, 2, NULL, NULL] | [NULL, NULL, NULL, 1, 1, 2] |
+------+-----------------------------+-----------------------------
5、array_contains
BOOLEAN array_contains(ARRAY<T> arr, T value)
-- 判断数组中是否包含value。返回结果如下:
-- 1 - value在数组arr中存在;
-- 0 - value不存在数组arr中;
-- NULL - arr为NULL时。
mysql> set enable_vectorized_engine=true;
mysql> SELECT id,c_array,array_contains(c_array, 5) FROM `array_test`;
+------+-----------------+------------------------------+
| id | c_array | array_contains(`c_array`, 5) |
+------+-----------------+------------------------------+
| 1 | [1, 2, 3, 4, 5] | 1 |
| 2 | [6, 7, 8] | 0 |
| 3 | [] | 0 |
| 4 | NULL | NULL |
+------+-----------------+------------------------------+
6、array_except
ARRAY<T> array_except(ARRAY<T> array1, ARRAY<T> array2)
-- 返回一个数组,包含所有在array1内但不在array2内的元素,会对返回的结果数组去重
-- 类似于取差集,将返回的差集结果数组去重
mysql> set enable_vectorized_engine=true;
mysql> select k1,k2,k3,array_except(k2,k3) from array_type_table;
+------+-----------------+--------------+--------------------------+
| k1 | k2 | k3 | array_except(`k2`, `k3`) |
+------+-----------------+--------------+--------------------------+
| 1 | [1, 2, 3] | [2, 4, 5] | [1, 3] |
| 2 | [2, 3] | [1, 5] | [2, 3] |
| 3 | [1, 1, 1] | [2, 2, 2] | [1] |
+------+-----------------+--------------+--------------------------+
7、array_intersect
ARRAY<T> array_intersect(ARRAY<T> array1, ARRAY<T> array2)
-- 返回一个数组,包含array1和array2的交集中的所有元素,不包含重复项
-- 两个数组去交集后。将返回的结果去重
mysql> set enable_vectorized_engine=true;
mysql> select k1,k2,k3,array_intersect(k2,k3) from array_type_table;
+------+-----------------+--------------+-----------------------------+
| k1 | k2 | k3 | array_intersect(`k2`, `k3`) |
+------+-----------------+--------------+-----------------------------+
| 1 | [1, 2, 3] | [2, 4, 5] | [2] |
| 2 | [2, 3] | [1, 5] | [] |
| 3 | [1, 1, 1] | [2, 2, 2] | [] |
+------+-----------------+--------------+-----------------------------+
mysql> select k1,k2,k3,array_intersect(k2,k3) from array_type_table_nullable;
+------+-----------------+--------------+-----------------------------+
| k1 | k2 | k3 | array_intersect(`k2`, `k3`) |
+------+-----------------+--------------+-----------------------------+
| 1 | [1, NULL, 3] | [1, 3, 5] | [1, 3] |
| 2 | [NULL, NULL, 2] | [2, NULL, 4] | [NULL, 2] |
| 3 | NULL | [1, 2, 3] | NULL |
+------+-----------------+--------------+-----------------------------+
8、array_union
union自动去重
ARRAY<T> array_union(ARRAY<T> array1, ARRAY<T> array2)
-- 返回一个数组,包含array1和array2的并集中的所有元素,不包含重复项
-- 取两个数组的并集,将返回的结果去重
mysql> set enable_vectorized_engine=true;
mysql> select k1,k2,k3,array_union(k2,k3) from array_type_table;
+------+-----------------+--------------+-------------------------+
| k1 | k2 | k3 | array_union(`k2`, `k3`) |
+------+-----------------+--------------+-------------------------+
| 1 | [1, 2, 3] | [2, 4, 5] | [1, 2, 3, 4, 5] |
| 2 | [2, 3] | [1, 5] | [2, 3, 1, 5] |
| 3 | [1, 1, 1] | [2, 2, 2] | [1, 2] |
+------+-----------------+--------------+-------------------------+
9、array_distinct
ARRAY<T> array_distinct(ARRAY<T> arr)
-- 返回去除了重复元素的数组,如果输入数组为NULL,则返回NULL。
mysql> set enable_vectorized_engine=true;
mysql> select k1, k2, array_distinct(k2) from array_test;
+------+-----------------------------+---------------------------+
| k1 | k2 | array_distinct(k2) |
+------+-----------------------------+---------------------------+
| 1 | [1, 2, 3, 4, 5] | [1, 2, 3, 4, 5] |
| 2 | [6, 7, 8] | [6, 7, 8] |
| 3 | [] | [] |
| 4 | NULL | NULL |
| 5 | [1, 2, 3, 4, 5, 4, 3, 2, 1] | [1, 2, 3, 4, 5] |
| 6 | [1, 2, 3, NULL] | [1, 2, 3, NULL] |
| 7 | [1, 2, 3, NULL, NULL] | [1, 2, 3, NULL] |
+------+-----------------------------+---------------------------+
7、json函数
建表,导入测试数据
CREATE TABLE test_json (
id INT,
json_string String
)
DUPLICATE KEY(id)
DISTRIBUTED BY HASH(id) BUCKETS 3
PROPERTIES("replication_num" = "1");
--测试数据
{
"k1":"v31", "k2": 300, "a1": [{
"k1":"v41", "k2": 400}, 1, "a", 3.14]}
{
"k1":"v32", "k2": 400, "a1": [{
"k1":"v41", "k2": 400}, 2, "a", 4.14],"a2":{
"k3":"v33", "k4": 200,"a2": [{
"k1":"v41", "k2": 400}, 2, "a", 4.14]}}
{
"k1":"v33", "k2": 500, "a1": [{
"k1":"v41", "k2": 400}, 3, "a", 5.14],"a2":{
"k3":"v33", "k4": 200,"a2": [{
"k5":"v42", "k6": 600}]}}
{
"k1":"v31"}
{
"k1":"v31", "k2": 300}
{
"k1":"v31", "k2": 200 "a1": []}
--json是一种里面存着一对对key,value类型的结构
--针对值类型的不同:
1.简单值:"k1":"v31"
2.数组:[{
"k1":"v41", "k2": 400}, 1, "a", 3.14]
3.对象:"a2":{
"k3":"v33", "k4": 200,"a2": [{
"k5":"v42", "k6": 600}]}
取值的时候,指定的'$.k1'==>这样的东西我们称之为json path ,json的路劲
-- 通过本地文件的方式导入
curl \
-u root: \
-H "label:load_local_file1" \
-H "column_separator:_" \
-T /root/data/json.txt \
http://zuomm01:8040/api/test/test_json/_stream_load
-- 用insert into 的方式导入一条
INSERT INTO test_json VALUES(7, '{"k1":"v1", "k2": 200}');
1、get_json_double,get_json_int,get_json_string
语法:
DOUBLE get_json_int(VARCHAR json_str, VARCHAR json_path)
INT get_json_int(VARCHAR json_str, VARCHAR json_path)
VARCHAR get_json_string(VARCHAR json_str, VARCHAR json_path)
-- 解析并获取 json 字符串内指定路径的double,int,string 类型的内容。
-- 其中 json_path 必须以 $ 符号作为开头,使用 . 作为路径分割符。
-- 如果路径中包含 . ,则可以使用双引号包围。
-- 使用 [ ] 表示数组下标,从 0 开始。
-- path 的内容不能包含 ", [ 和 ]。
-- 如果 json_string 格式不对,或 json_path 格式不对,或无法找到匹配项,则返回 NULL。
--1.获取到k1对应的value的值
mysql> select id, get_json_string(json_string,'$.k1') as k1 from test_json;
+------+------+
| id | k1 |
+------+------+
| 2 | v32 |
| 4 | v31 |
| 5 | v31 |
| 6 | v31 |
| 1 | v31 |
| 3 | v33 |
+------+------+
--2.获取到key 为a1 里面的数组
mysql> select id, get_json_string(json_string,'$.a1') as arr from test_json;
+------+------------------------------------+
| id | arr |
+------+------------------------------------+
| 1 | [{
"k1":"v41","k2":400},1,"a",3.14] |
| 3 | [{
"k1":"v41","k2":400},3,"a",5.14] |
| 2 | [{
"k1":"v41","k2":400},2,"a",4.14] |
| 4 | NULL |
| 5 | NULL |
| 6 | [] |
+------+------------------------------------+
--3.获取到key 为a1 里面的数组中第一个元素的值
mysql> select id, get_json_string(json_string,'$.a1[0]') as arr from test_json;
+------+-----------------------+
| id | arr |
+------+-----------------------+
| 2 | {
"k1":"v41","k2":400} |
| 1 | {
"k1":"v41","k2":400} |
| 3 | {
"k1":"v41","k2":400} |
| 4 | NULL |
| 5 | NULL |
| 6 | NULL |
+------+-----------------------+
--4.获取到key 为a1 里面的数组中第一个元素的值(这个值是一个json串,再次获取到这个字符串中)
select id, get_json_string(get_json_string(json_string,'$.a1[0]'),'$.k1') as arr from test_json;
+------+------+
| id | arr |
+------+------+
| 2 | v41 |
| 1 | v41 |
| 3 | v41 |
| 4 | NULL |
| 5 | NULL |
| 6 | NULL |
+------+------+
6 rows in set (0.02 sec)
2、json_object
VARCHAR json_object(VARCHAR,...)
-- 生成一个包含指定Key-Value对的json object,
-- 传入的参数是key,value对,且key不能为null
87
MySQL> select json_object('time',curtime());
+--------------------------------+
| json_object('time', curtime()) |
+--------------------------------+
| {
"time": "10:49:18"} |
+--------------------------------+
MySQL> SELECT json_object('id', 87, 'name', 'carrot');
+-----------------------------------------+
| json_object('id', 87, 'name', 'carrot') |
+-----------------------------------------+
| {
"id": 87, "name": "carrot"} |
+-----------------------------------------+
json_object('id', 87, 'name', 'carrot');
MySQL> select json_object('username',null);
+---------------------------------+
| json_object('username', 'NULL') |
+---------------------------------+
| {
"username": NULL} |
+---------------------------------+
8、窗口函数
over为进行怎么开窗,over前面放置开窗之后的处理函数
1、ROW_NUMBER(),DENSE_RANK(),RANK()
elect x, y, rank() over(partition by x order by y) as rank from int_t;
| x | y | rank |
|----|------|----------|
| 1 | 1 | 1 |
| 1 | 2 | 2 |
| 1 | 2 | 2 |
| 2 | 1 | 1 |
| 2 | 2 | 2 |
| 2 | 3 | 3 |
| 3 | 1 | 1 |
| 3 | 1 | 1 |
| 3 | 2 | 3 |
-- 测试dense_rank(),名词相同会并列排名,比如两个第一名,就是1 1 然后第二名会显示2
select x, y, dense_rank() over(partition by x order by y) as rank from int_t;
| x | y | rank |
|----|------|----------|
| 1 | 1 | 1 |
| 1 | 2 | 2 |
| 1 | 2 | 2 |
| 2 | 1 | 1 |
| 2 | 2 | 2 |
| 2 | 3 | 3 |
| 3 | 1 | 1 |
| 3 | 1 | 1 |
| 3 | 2 | 2 |
-- 测试ROW_NUMBER() 按照分组排序要求,返回的编号依次底层,1 2 3 4 5 ,
-- 不会有重复值,也不会有空缺值,就是连续递增的整数,从1 开始
select x, y, row_number() over(partition by x order by y) as rank from int_t;
| x | y | rank |
|---|------|----------|
| 1 | 1 | 1 |
| 1 | 2 | 2 |
| 1 | 2 | 3 |
| 2 | 1 | 1 |
| 2 | 2 | 2 |
| 2 | 3 | 3 |
| 3 | 1 | 1 |
| 3 | 1 | 2 |
| 3 | 2 | 3 |
测试
-- 案例数据
孙悟空,语文,87
孙悟空,数学,95
娜娜,英语,84
宋宋,语文,64
孙悟空,英语,68
宋宋,英语,84
婷婷,语文,65
娜娜,语文,94
宋宋,数学,86
婷婷,数学,85
娜娜,数学,56
婷婷,英语,78
-- 建表语句
create table stu
(
name varchar(50),
subject varchar(50),
score double
)
DUPLICATE KEY(name)
DISTRIBUTED BY HASH(name) BUCKETS 1;
-- 通过本地文件的方式导入数据
curl \
-u root: \
-H "label:num_test" \
-H "column_separator:," \
-T /root/data/stu.txt \
http://zuomm01:8040/api/test/stu/_stream_load
需求:
【相同分数并列(假设第一名有两个,排名就是并列第一,然后第三名从2开始)】
1.按照分数降序排序,求每个学科中每个人的名次
2.按照每个人的总分进行升序排列,得到每个人总分名次的名次
【相同分数并列(假设第一名有两个,排名就是并列第一,然后第三名从3开始)】
3.按照学科进行升序排列,得到每个人的每个学科的名次
4.按照每个人的总分进行升序排列,得到每个人总分名次的名次
【相同分数并列
(假设第一名有两个,排名就是并列第一,
就再单独比语文的成绩,然后数学,最后英语,
分数全部一样,按照学生名字的字典顺序,在前的为第一)】
5.按照每个人的总分进行升序排列,得到每个人总分名次的名次
-- 1.按照学科进行升序排列,得到每个人的每个学科的名次
select
name,subject,score,
dense_rank() over(partition by subject order by score desc) as rank
from stu
+-----------+---------+-------+------+
| name | subject | score | rank |
+-----------+---------+-------+------+
| 孙悟空 | 数学 | 95 | 1 |
| 宋宋 | 数学 | 86 | 2 |
| 婷婷 | 数学 | 85 | 3 |
| 娜娜 | 数学 | 56 | 4 |
| 娜娜 | 英语 | 84 | 1 |
| 宋宋 | 英语 | 84 | 1 |
| 婷婷 | 英语 | 78 | 2 |
| 孙悟空 | 英语 | 68 | 3 |
| 娜娜 | 语文 | 94 | 1 |
| 孙悟空 | 语文 | 87 | 2 |
| 婷婷 | 语文 | 65 | 3 |
| 宋宋 | 语文 | 64 | 4 |
+-----------+---------+-------+------+
-- 2.按照每个人的总分进行升序排列,得到每个人总分名次的名次
select
name,sum_score,
-- 因为是整体按照学生的总分进行求名次,所有学生为1组,就不需要分组了
dense_rank() over(order by sum_score desc) as rank
from
(
select
name,sum(score) as sum_score
from stu
group by name
) as t ;
+-----------+-----------+------+
| name | sum_score | rank |
+-----------+-----------+------+
| 孙悟空 | 250 | 1 |
| 宋宋 | 234 | 2 |
| 娜娜 | 234 | 2 |
| 婷婷 | 228 | 3 |
+-----------+-----------+------+
【相同分数并列(假设第一名有两个,排名就是并列第一,然后第三名从3开始)】
-- 3.按照学科进行升序排列,得到每个人的每个学科的名次
select
name,subject,score,
rank() over(partition by subject order by score desc) as rank
from stu
+-----------+---------+-------+------+
| name | subject | score | rank |
+-----------+---------+-------+------+
| 孙悟空 | 数学 | 95 | 1 |
| 宋宋 | 数学 | 86 | 2 |
| 婷婷 | 数学 | 85 | 3 |
| 娜娜 | 数学 | 56 | 4 |
| 娜娜 | 英语 | 84 | 1 |
| 宋宋 | 英语 | 84 | 1 |
| 婷婷 | 英语 | 78 | 3 |
| 孙悟空 | 英语 | 68 | 4 |
| 娜娜 | 语文 | 94 | 1 |
| 孙悟空 | 语文 | 87 | 2 |
| 婷婷 | 语文 | 65 | 3 |
| 宋宋 | 语文 | 64 | 4 |
+-----------+---------+-------+------+
-- 4.按照每个人的总分进行升序排列,得到每个人总分名次的名次
select
name,sum_score,
-- 因为是整体按照学生的总分进行求名次,所有学生为1组,就不需要分组了
rank() over(order by sum_score desc) as rank
from
(
select
name,sum(score) as sum_score
from stu
group by name
) as t ;
+-----------+-----------+------+
| name | sum_score | rank |
+-----------+-----------+------+
| 孙悟空 | 250 | 1 |
| 宋宋 | 234 | 2 |
| 娜娜 | 234 | 2 |
| 婷婷 | 228 | 4 |
+-----------+-----------+------+
【相同分数并列
(假设第一名有两个,排名就是并列第一,
就再单独比语文的成绩,然后数学,最后英语,
分数全部一样,按照学生名字的字典顺序,在前的为第一)】
-- 5.按照每个人的总分进行升序排列,得到每个人总分名次的名次
--方案1:利用窗口函数来列转行
select
name,subject,score as math_score,english_score,chinese_score,sum_score,
row_number()over(order by sum_score desc ,chinese_score desc ,score desc ,english_score desc,name asc) as num
from
(
select
name,subject,score,
lead(score,1,0)over(partition by name order by subject) as english_score,
lead(score,2,0)over(partition by name order by subject) as chinese_score,
sum(score)over(partition by name) as sum_score,
row_number()over(partition by name) as num
from stu
) as tmp
where num = 1
-- 方案2:利用if判断来列转行
select
name,chinese_score,match_score,english_score,sum_score,
row_number()over(order by sum_score desc ,chinese_score desc ,match_score desc ,english_score desc,name asc) as num
from
(
select
name,
sum(chinese_score) as chinese_score,
sum(match_score) as match_score,
sum(english_score) as english_score,
sum(chinese_score) + sum(match_score) + sum(english_score) as sum_score
from
(
select name,subject,
if(subject = '语文',score,0) as chinese_score,
if(subject = '数学',score,0) as match_score,
if(subject = '英语',score,0) as english_score
from stu
)as t
group by name
) as t1
+-----------+---------+------------+---------------+---------------+-----------+------+
| name | subject | math_score | english_score | chinese_score | sum_score | num |
+-----------+---------+------------+---------------+---------------+-----------+------+
| 孙悟空 | 数学 | 95 | 68 | 87 | 250 | 1 |
| 娜娜 | 数学 | 56 | 84 | 94 | 234 | 2 |
| 宋宋 | 数学 | 86 | 84 | 64 | 234 | 3 |
| 婷婷 | 数学 | 85 | 78 | 65 | 228 | 4 |
2、min,max,sum,avg,count
min(x)over() -- 取窗口中x列的最小值
max(x)over() -- 取窗口中x列的最大值
sum(x)over() -- 取窗口中x列的数据总和
avg(x)over() -- 取窗口中x列的数据平均值
count(x)over() -- 取窗口中x列有多少行
unbounded preceding
current row
1 following
1 PRECEDING
rows between unbounded preceding and current row --指在当前窗口中第一行到当前行的范围
rows between unbounded preceding and 1 following --指在当前窗口中第一行到当前行下一行的范围
rows between unbounded preceding and 1 PRECEDING --指在当前窗口中第一行到当前行前一行的范围
3、LEAD() ,LAG()
-- LAG() 方法用来计算当前行向前数若干行的值。
LAG(expr, offset, default) OVER (partition_by_clause order_by_clause)
-- LEAD() 方法用来计算当前行向后数若干行的值。
LEAD(expr, offset, default]) OVER (partition_by_clause order_by_clause)
9、窗口案例
打地鼠案例
需求:连续4次命中的人
-- seq:第几次打地鼠
-- m:是否命中,1-》命中,0-》未命中
uid,seq,m
u01,1,1
u01,2,0
u01,3,1
u01,6,1
u02,5,1
u02,6,0
u02,7,0
u02,1,1
u02,2,1
u03,4,1
u03,5,1
u03,6,0
u02,3,0
u02,4,1
u02,8,1
u01,4,1
u01,5,0
u02,9,1
u03,1,1
u03,2,1
u03,3,1
--建表语句
create table hit_mouse
(
user_id varchar(50),
seq int,
m int
)
DUPLICATE KEY(user_id)
DISTRIBUTED BY HASH(user_id) BUCKETS 1;
-- 通过本地文件的方式导入数据
curl \
-u root: \
-H "label:hit_mouse" \
-H "column_separator:," \
-T /root/data/hit_mouse.txt \
http://zuomm01:8040/api/test/hit_mouse/_stream_load
1.首先排除没有命中的数据
2.对每个用户进行分组,按照打地鼠编号的升序进行排序,打行号
3.用打地鼠的编号 - 所打的行号 ==》 如果连续命中的话,最后得到的结果应该是相等的
4.count出一样的结果的个数,满足大于等于4的就是我们需要的结果
-- 排除没有命中的数据,开窗打编号
select
user_id,seq,m,
row_number()over(partition by user_id order by seq asc) as num
from hit_mouse
where m != 0 ;
+---------+------+------+------+
| user_id | seq | m | num |
+---------+------+------+------+
| u01 | 1 | 1 | 1 | ==新的值
| u01 | 3 | 1 | 2 |
| u01 | 4 | 1 | 3 |
| u01 | 6 | 1 | 4 |
| u02 | 1 | 1 | 1 |
| u02 | 2 | 1 | 2 |
| u02 | 4 | 1 | 3 |
| u02 | 5 | 1 | 4 |
| u02 | 8 | 1 | 5 |
| u02 | 9 | 1 | 6 |
| u03 | 1 | 1 | 1 |
| u03 | 2 | 1 | 2 |
| u03 | 3 | 1 | 3 |
| u03 | 4 | 1 | 4 |
| u03 | 5 | 1 | 5 |
+---------+------+------+------+
-- 将上面的语句改变下,现在需要的是编号减去行号,可否直接拿编号减行号呢?
select
user_id,seq,m,
seq -row_number()over(partition by user_id order by seq asc) as num
from hit_mouse
where m != 0 ;
+---------+------+------+------+
| user_id | seq | m | num |
+---------+------+------+------+
| u01 | 1 | 1 | 0 |
| u01 | 3 | 1 | 1 |
| u01 | 4 | 1 | 1 |
| u01 | 6 | 1 | 2 |
| u02 | 1 | 1 | 0 |
| u02 | 2 | 1 | 0 |
| u02 | 4 | 1 | 1 |
| u02 | 5 | 1 | 1 |
| u02 | 8 | 1 | 3 |
| u02 | 9 | 1 | 3 |
| u03 | 1 | 1 | 0 |
| u03 | 2 | 1 | 0 |
| u03 | 3 | 1 | 0 |
| u03 | 4 | 1 | 0 |
| u03 | 5 | 1 | 0 |
+---------+------+------+------+
-- 看num重复的个数(在同一个user_id中)
select
user_id,
count(1) as cnt
from
(
select
user_id,seq,m,
seq -row_number()over(partition by user_id order by seq asc) as num
from hit_mouse
where m != 0
) as t
group by user_id,num
having cnt>=4
-- 得到最后的结果
+---------+------+
| user_id | cnt |
+---------+------+
| u03 | 5 |
+---------+------+
方案二:在不需要返回具体连续命中多少次,只需要返回user_id的情况下,还可以这么做
1.在去掉了未命中数据后
2.开窗,拿当前行下面的第三行数据,如果说该用户是连续登录的,
必然下面第三行的序号等于第一行的序号加3,如果结果不等于3,他们必然是不连续的,
并且结果只可能大于3,中间有为名中的被过滤了
3.最后查看结果等于3的用户并返回即可
select
user_id,seq,m,
(lead(seq,3,-4)over(partition by user_id order by seq asc) - seq) as diff
from hit_mouse
where m != 0
+---------+------+------+------+
| user_id | seq | m | diff |
+---------+------+------+------+
| u01 | 1 | 1 | 5 |
| u01 | 3 | 1 | -7 |
| u01 | 4 | 1 | -8 |
| u01 | 6 | 1 | -10 |
| u02 | 1 | 1 | 4 |
| u02 | 2 | 1 | 6 |
| u02 | 4 | 1 | 5 |
| u02 | 5 | 1 | -9 |
| u02 | 8 | 1 | -12 |
| u02 | 9 | 1 | -13 |
| u03 | 1 | 1 | 3 |
| u03 | 2 | 1 | 3 |
| u03 | 3 | 1 | -7 |
| u03 | 4 | 1 | -8 |
| u03 | 5 | 1 | -9 |
+---------+------+------+------+
-- 最后判断diff的差值是否=3,然后返回对应的user_id(有可能会有多条相同的数据,去重)
select
user_id
from
(
select
user_id,seq,m,
(lead(seq,3,-4)over(partition by user_id order by seq asc) - seq) as res
from hit_mouse
where m != 0
) as t
where res = 3
-- group by 去重
group by user_id
+---------+
| user_id |
+---------+
| u03 |
+---------+
连续购买案例
需求:连续三天以上有销售记录的店铺名称
-- 数据准备
a,2017-02-05,100
a,2017-02-06,300
a,2017-02-07,800
a,2017-02-08,500
a,2017-02-10,700
b,2017-02-05,200
b,2017-02-06,400
b,2017-02-08,100
b,2017-02-09,400
b,2017-02-10,600
c,2017-01-31,200
c,2017-02-01,600
c,2017-02-02,600
c,2017-02-03,600
c,2017-02-10,700
a,2017-03-01,400
a,2017-03-02,300
a,2017-03-03,700
a,2017-03-04,400
--建表语句
create table shop_sale
(
shop_id varchar(50),
dt date,
amount double
)
DUPLICATE KEY(shop_id)
DISTRIBUTED BY HASH(shop_id) BUCKETS 1;
-- 通过本地文件的方式导入数据
curl \
-u root: \
-H "label:shop_sale" \
-H "column_separator:," \
-T /root/data/shop_sale.txt \
http://zuomm01:8040/api/test/shop_sale/_stream_load
这样的连续销售记录问题(连续登录问题)和上面打地鼠的需求是一样的
1.按照店铺分组,对日期排序后打行号
2.用日期减去行号,得到的新的日期值,如果新的日期相同的话就代表是连续的
3.统计相同新日期的个数,来判断连续登录了几天
select
shop_id,new_date,
count(1) as cnt
from
(
select shop_id,dt,
date_sub(dt,row_number()over(partition by shop_id order by dt))as new_date
from shop_sale
) as t
group by shop_id,new_date
having cnt >=3;
+---------+------+
| shop_id | cnt |
+---------+------+
| a | 4 |
| a | 4 |
| b | 3 |
| c | 4 |
+---------+------+
方案二:
需要求连续三天的,我们取下面的第二行日期,拿取过来的下面的日期对当前行的日期相减,取间隔几天
如果他们的值 = 2 就代表是连续的
select
shop_id
from
(
select shop_id,dt,
datediff(lead(dt,2,'9999-12-31')over(partition by shop_id order by dt),dt)as day_diff_num
from shop_sale
) as t
where day_diff_num = 2
-- 给店铺去重
group by shop_id
+---------+
| shop_id |
+---------+
| c |
| a |
| b |
+---------+
分组topN案例
需求:
基于上面的表,求每个店铺金额最大的前三条订单 (row_number over)
求每个店铺销售金额前三名的订单
a,2017-02-07,800
a,2017-02-10,700
a,2017-02-08,500
a,2017-02-06,300
a,2017-02-05,100
b,2017-02-05,200
b,2017-02-06,400
b,2017-02-08,100
b,2017-02-09,400
b,2017-02-10,600
c,2017-02-10,700
c,2017-02-01,600
c,2017-02-02,600
c,2017-02-03,600
c,2017-01-31,200
d,2017-03-01,400
d,2017-03-02,300
d,2017-03-03,700
d,2017-03-04,400
select
shop_id,dt,amount
from
(
select
shop_id,dt,amount,
row_number()over(partition by shop_id order by amount desc) as num
from shop_sale
) as tmp
where num <=3
遇到标志划分组按理
需求:将上面的表转化成下面的形式,首先按照用户进行分组,
在用户分组的基础上,name字段每遇到一个e*就分一组
user_id,name
u1,e1
u1,e1
u1,e*
u1,e2
u1,e3
u1,e*
u2,e1
u2,e2
u2,e*
u2,e1
u2,e3
u2,e*
u2,e*
上面的用户行为记录,每遇到一个e*,就分到一组,得到如下结果:
u1, [e1,e1,e*]
u1, [e2,e3,e*]
u2, [e1,e2,e*]
u2, [e1,e3,e*]
u2, [e*]
--建表语句
drop table if exists window_test;
create table window_test
(
user_id varchar(10),
name string
)
DUPLICATE KEY(user_id)
DISTRIBUTED BY HASH(user_id) BUCKETS 1;
-- 为了保证原数据的插入顺序,一条一条的inert 进去
insert into window_test values ('u1','e1');
insert into window_test values ('u1','e1');
insert into window_test values ('u1','e*');
insert into window_test values ('u1','e2');
insert into window_test values ('u1','e3');
insert into window_test values ('u1','e*');
insert into window_test values ('u2','e1');
insert into window_test values ('u2','e2');
insert into window_test values ('u2','e*');
insert into window_test values ('u2','e1');
insert into window_test values ('u2','e3');
insert into window_test values ('u2','e*');
insert into window_test values ('u2','e*');
1.我们需要关注的是name字段中的值是不是e*,所以可以将它转换成flag,1 0这样的标签
2.按照用户分组,来打行号(注意:这边必须要按照原来数据的顺序)
3.开窗,将flag的值从第一行加到当前行
4.将开窗的结果和原flag进行相减,得到一个新的flag标签结果
5.按照用户和新的标签结果进行分组,收集即可
-- 添加标签
select
user_id,
name,
if(name = 'e*',1,0) as flag
from window_test
+---------+------+------+
| user_id | name | flag |
+---------+------+------+
| u1 | e1 | 0 |
| u1 | e1 | 0 |
| u1 | e* | 1 |
| u1 | e2 | 0 |
| u1 | e3 | 0 |
| u1 | e* | 1 |
| u2 | e1 | 0 |
| u2 | e2 | 0 |
| u2 | e* | 1 |
| u2 | e1 | 0 |
| u2 | e3 | 0 |
| u2 | e* | 1 |
| u2 | e* | 1 |
+---------+------+------+
select
user_id,
name,
flag,
sum(flag)over(partition by user_id order by user_id rows between unbounded preceding and current row) as sum_flag
from
(
select
user_id,
name,
if(name = 'e*',1,0) as flag
from window_test
) as t;
+---------+------+------+----------+
| user_id | name | flag | sum_flag |
+---------+------+------+----------+
| u1 | e1 | 0 | 0 |
| u1 | e1 | 0 | 0 |
| u1 | e* | 1 | 1 |
| u1 | e2 | 0 | 1 |
| u1 | e3 | 0 | 1 |
| u1 | e* | 1 | 2 |
| u2 | e1 | 0 | 0 |
| u2 | e2 | 0 | 0 |
| u2 | e* | 1 | 1 |
| u2 | e1 | 0 | 1 |
| u2 | e3 | 0 | 1 |
| u2 | e* | 1 | 2 |
| u2 | e* | 1 | 3 |
+---------+------+------+----------+
观察现象,现在想把user_id和按照遇到e*就分组的这哥逻辑去处理的话,需要一个新标签,同一组相等
可以拿sum_flag - flag 得到的结果就是我们想要的
(plan2:或者拿取sum_flag 上面的一行数据,如果没有数据拿,默认就是0 ,这样的话也行)
select
user_id,
name,
flag,
sum(flag)over(partition by user_id order by user_id rows between unbounded preceding and current row) -flag as diff_flag
from
(
select
user_id,
name,
if(name = 'e*',1,0) as flag
from window_test
) as t;
+---------+------+------+-----------+
| user_id | name | flag | diff_flag |
+---------+------+------+-----------+
| u1 | e1 | 0 | 0 |
| u1 | e1 | 0 | 0 |
| u1 | e* | 1 | 0 |
| u1 | e2 | 0 | 1 |
| u1 | e3 | 0 | 1 |
| u1 | e* | 1 | 1 |
| u2 | e1 | 0 | 0 |
| u2 | e2 | 0 | 0 |
| u2 | e* | 1 | 0 |
| u2 | e1 | 0 | 1 |
| u2 | e3 | 0 | 1 |
| u2 | e* | 1 | 1 |
| u2 | e* | 1 | 2 |
+---------+------+------+-----------+
最后只要group by之后收集就行了,注意收集的时候没有collect_set 和ollect_list,只有group_concat()
select
user_id,
group_concat(name,',') as res
from
(
select
user_id,
name,
flag,
sum(flag)over(partition by user_id order by user_id rows between unbounded preceding and current row) -flag as diff_flag
from
(
select
user_id,
name,
if(name = 'e*',1,0) as flag
from window_test
) as t
) as t1
group by user_id,diff_flag
+---------+----------+
| user_id | res |
+---------+----------+
| u1 | e1,e1,e* |
| u2 | e* |
| u1 | e2,e3,e* |
| u2 | e1,e2,e* |
| u2 | e1,e3,e* |
+---------+----------+
5.3、综合案例之漏斗转化分析
业务目标、到达路径,路径步骤、步骤人数,步骤之间的相对转换率和绝对转换率
每一种业务都有他的核心任务和流程,而流程的每一个步骤,都可能有用户流失。所以如果把每一个步骤及其对应的数据(如UV)拼接起来,就会形成一个上大下小的漏斗形态,这就是漏斗模型。
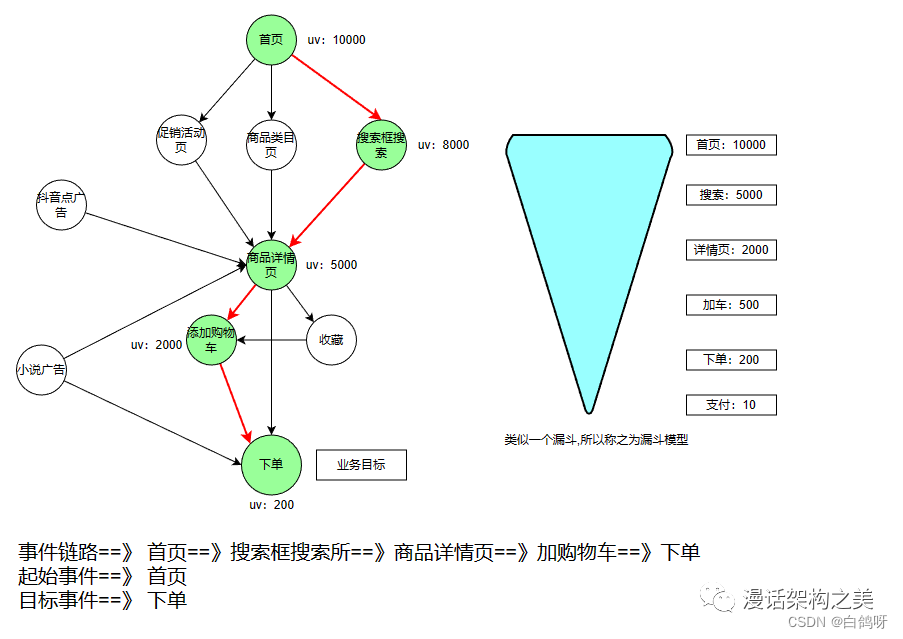
漏斗模型示例:
不同的业务场景有不同的业务路径 : 有先后顺序, 事件可以出现多次
注册转化漏斗 : 启动APP --> APP注册页面—>注册结果 -->提交订单–>支付成功
搜购转化漏斗 : 搜索商品–> 点击商品—>加入购物车–>提交订单–>支付成功
秒杀活动选购转化漏斗: 点击秒杀活动–>参加活动—>参与秒杀–>秒杀成功—>成功支付
电商的购买转化漏斗模型图:
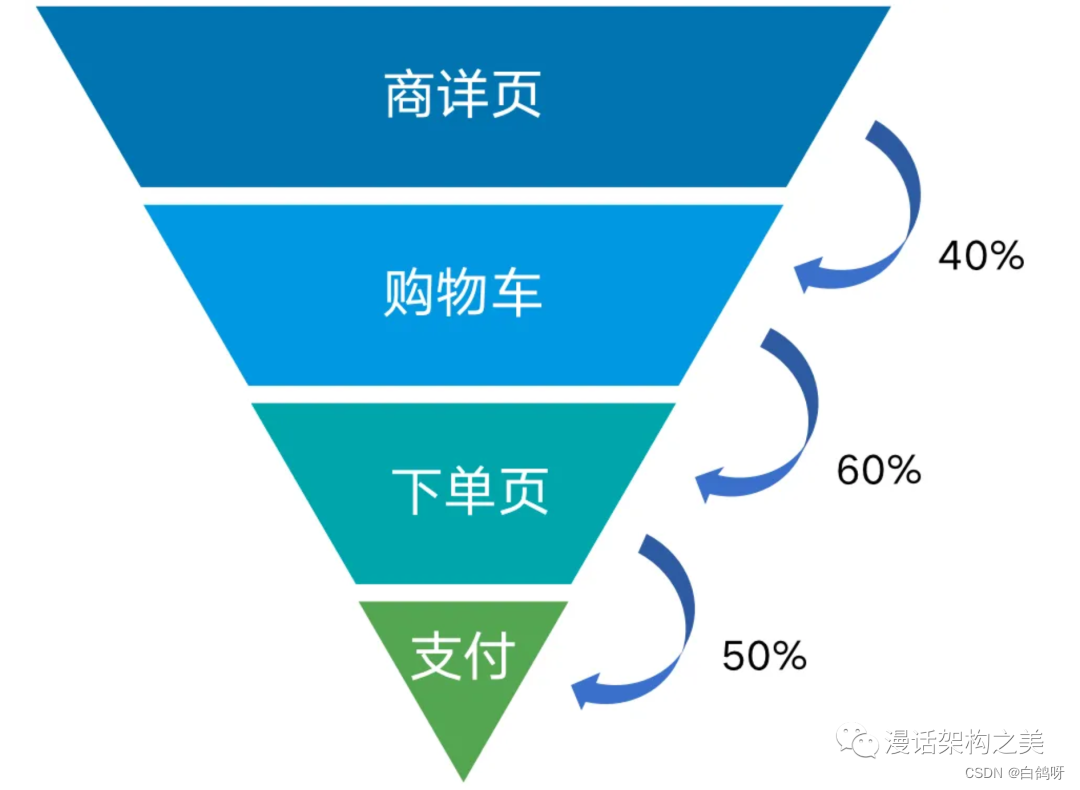
处理步骤 :
明确漏斗名称:购买转化漏斗
起始事件:浏览了商品的详情页
目标事件:支付
业务流程事件链路:详情页->购物车->下单页->支付
[事件之间有没有时间间隔要求 , 链路中相邻的两个事件是否可以有其他事件]
需求:求购买转化漏斗模型的转换率(事件和事件之间没有时间间隔要求,并且相邻两个事件可以去干其他的事)
1.每一个步骤的uv
2.相对的转换率(下一个步骤的uv/上一个步骤的UV),绝对的转换率(当前步骤的UV第一步骤的UV)
关心的事件:e1,e2,e4,e5 ==> 先后顺序不能乱
-- 准备数据
user_id event_id event_action event_time
u001,e1,view_detail_page,2022-11-01 01:10:21
u001,e2,add_bag_page,2022-11-01 01:11:13
u001,e3,collect_goods_page,2022-11-01 02:07:11
u002,e3,collect_goods_page,2022-11-01 01:10:21
u002,e4,order_detail_page,2022-11-01 01:11:13
u002,e5,pay_detail_page,2022-11-01 02:07:11
u002,e6,click_adver_page,2022-11-01 13:07:23
u002,e7,home_page,2022-11-01 08:18:12
u002,e8,list_detail_page,2022-11-01 23:34:29
u002,e1,view_detail_page,2022-11-01 11:25:32
u002,e2,add_bag_page,2022-11-01 12:41:21
u002,e3,collect_goods_page,2022-11-01 16:21:15
u002,e4,order_detail_page,2022-11-01 21:41:12
u003,e5,pay_detail_page,2022-11-01 01:10:21
u003,e6,click_adver_page,2022-11-01 01:11:13
u003,e7,home_page,2022-11-01 02:07:11
u001,e4,order_detail_page,2022-11-01 13:07:23
u001,e5,pay_detail_page,2022-11-01 08:18:12
u001,e6,click_adver_page,2022-11-01 23:34:29
u001,e7,home_page,2022-11-01 11:25:32
u001,e8,list_detail_page,2022-11-01 12:41:21
u001,e1,view_detail_page,2022-11-01 16:21:15
u001,e2,add_bag_page,2022-11-01 21:41:12
u003,e8,list_detail_page,2022-11-01 13:07:23
u003,e1,view_detail_page,2022-11-01 08:18:12
u003,e2,add_bag_page,2022-11-01 23:34:29
u003,e3,collect_goods_page,2022-11-01 11:25:32
u003,e4,order_detail_page,2022-11-01 12:41:21
u003,e5,pay_detail_page,2022-11-01 16:21:15
u003,e6,click_adver_page,2022-11-01 21:41:12
u004,e7,home_page,2022-11-01 01:10:21
u004,e8,list_detail_page,2022-11-01 01:11:13
u004,e1,view_detail_page,2022-11-01 02:07:11
u004,e2,add_bag_page,2022-11-01 13:07:23
u004,e3,collect_goods_page,2022-11-01 08:18:12
u004,e4,order_detail_page,2022-11-01 23:34:29
u004,e5,pay_detail_page,2022-11-01 11:25:32
u004,e6,click_adver_page,2022-11-01 12:41:21
u004,e7,home_page,2022-11-01 16:21:15
u004,e8,list_detail_page,2022-11-01 21:41:12
u005,e1,view_detail_page,2022-11-01 01:10:21
u005,e2,add_bag_page,2022-11-01 01:11:13
u005,e3,collect_goods_page,2022-11-01 02:07:11
u005,e4,order_detail_page,2022-11-01 13:07:23
u005,e5,pay_detail_page,2022-11-01 08:18:12
u005,e6,click_adver_page,2022-11-01 23:34:29
u005,e7,home_page,2022-11-01 11:25:32
u005,e8,list_detail_page,2022-11-01 12:41:21
u005,e1,view_detail_page,2022-11-01 16:21:15
u005,e2,add_bag_page,2022-11-01 21:41:12
u005,e3,collect_goods_page,2022-11-01 01:10:21
u006,e4,order_detail_page,2022-11-01 01:11:13
u006,e5,pay_detail_page,2022-11-01 02:07:11
u006,e6,click_adver_page,2022-11-01 13:07:23
u006,e7,home_page,2022-11-01 08:18:12
u006,e8,list_detail_page,2022-11-01 23:34:29
u006,e1,view_detail_page,2022-11-01 11:25:32
u006,e2,add_bag_page,2022-11-01 12:41:21
u006,e3,collect_goods_page,2022-11-01 16:21:15
u006,e4,order_detail_page,2022-11-01 21:41:12
u006,e5,pay_detail_page,2022-11-01 23:10:21
u006,e6,click_adver_page,2022-11-01 01:11:13
u007,e7,home_page,2022-11-01 02:07:11
u007,e8,list_detail_page,2022-11-01 13:07:23
u007,e1,view_detail_page,2022-11-01 08:18:12
u007,e2,add_bag_page,2022-11-01 23:34:29
u007,e3,collect_goods_page,2022-11-01 11:25:32
u007,e4,order_detail_page,2022-11-01 12:41:21
u007,e5,pay_detail_page,2022-11-01 16:21:15
u007,e6,click_adver_page,2022-11-01 21:41:12
u007,e7,home_page,2022-11-01 01:10:21
u008,e8,list_detail_page,2022-11-01 01:11:13
u008,e1,view_detail_page,2022-11-01 02:07:11
u008,e2,add_bag_page,2022-11-01 13:07:23
u008,e3,collect_goods_page,2022-11-01 08:18:12
u008,e4,order_detail_page,2022-11-01 23:34:29
u008,e5,pay_detail_page,2022-11-01 11:25:32
u008,e6,click_adver_page,2022-11-01 12:41:21
u008,e7,home_page,2022-11-01 16:21:15
u008,e8,list_detail_page,2022-11-01 21:41:12
u008,e1,view_detail_page,2022-11-01 01:10:21
u009,e2,add_bag_page,2022-11-01 01:11:13
u009,e3,collect_goods_page,2022-11-01 02:07:11
u009,e4,order_detail_page,2022-11-01 13:07:23
u009,e5,pay_detail_page,2022-11-01 08:18:12
u009,e6,click_adver_page,2022-11-01 23:34:29
u009,e7,home_page,2022-11-01 11:25:32
u009,e8,list_detail_page,2022-11-01 12:41:21
u009,e1,view_detail_page,2022-11-01 16:21:15
u009,e2,add_bag_page,2022-11-01 21:41:12
u009,e3,collect_goods_page,2022-11-01 01:10:21
u010,e4,order_detail_page,2022-11-01 01:11:13
u010,e5,pay_detail_page,2022-11-01 02:07:11
u010,e6,click_adver_page,2022-11-01 13:07:23
u010,e7,home_page,2022-11-01 08:18:12
u010,e8,list_detail_page,2022-11-01 23:34:29
u010,e5,pay_detail_page,2022-11-01 11:25:32
u010,e6,click_adver_page,2022-11-01 12:41:21
u010,e7,home_page,2022-11-01 16:21:15
u010,e8,list_detail_page,2022-11-01 21:41:12
-- 创建表
drop table if exists event_info_log;
create table event_info_log
(
user_id varchar(20),
event_id varchar(20),
event_action varchar(20),
event_time datetime
)
DUPLICATE KEY(user_id)
DISTRIBUTED BY HASH(user_id) BUCKETS 1;
-- 通过本地文件的方式导入数据
curl \
-u root: \
-H "label:event_info_log" \
-H "column_separator:," \
-T /root/data/event_log.txt \
http://linux01:8040/api/test/event_info_log/_stream_load
--1. 先将用户的事件序列,按照漏斗模型定义的条件进行过滤,留下满足条件的事件
--2. 将同一个人的满足条件的事件ID收集到数组,按时间先后排序,拼接成字符串
--3. 将拼接好的字符串,匹配漏斗模型抽象出来的正则表达式
1.筛选时间条件,确定每个人的事件序列
select
user_id,
max(event_ll) as event_seq
from
(
select
user_id,
group_concat(event_id)over(partition by user_id order by report_date) as event_ll
from
(
select
user_id,event_id,report_date
from event_info_log
where event_id in ('e1','e2','e4','e5')
and to_date(report_date) = '2022-11-01'
order by user_id,report_date
) as temp
) as temp2
group by user_id;
+---------+------------------------+
| user_id | event_ll |
+---------+------------------------+
| u006 | e4, e5, e1, e2, e4, e5 |
| u007 | e1, e4, e5, e2 |
| u005 | e1, e2, e5, e4, e1, e2 |
| u004 | e1, e5, e2, e4 |
| u010 | e4, e5, e5 |
| u001 | e1, e2, e5, e4, e1, e2 |
| u003 | e5, e1, e4, e5, e2 |
| u002 | e4, e5, e1, e2, e4 |
| u008 | e1, e1, e5, e2, e4 |
| u009 | e2, e5, e4, e1, e2 |
+---------+------------------------+
2.确定匹配规则模型
select
user_id,
'购买转化漏斗' as funnel_name ,
case
-- 正则匹配,先触发过e1,在触发过e2,在触发过e4,在触发过e5
when event_seq rlike('e1.*e2.*e4.*e5') then 4
-- 正则匹配,先触发过e1,在触发过e2,在触发过e4
when event_seq rlike('e1.*e2.*e4') then 3
-- 正则匹配,先触发过e1,在触发过e2
when event_seq rlike('e1.*e2') then 2
-- 正则匹配,只触发过e1
when event_seq rlike('e1') then 1
else 0 end step
from
(
select
user_id,
max(event_ll) as event_seq
from
(
select
user_id,
group_concat(event_id)over(partition by user_id order by report_date) as event_ll
from
(
select
user_id,event_id,report_date
from event_info_log
where event_id in ('e1','e2','e4','e5')
and to_date(report_date) = '2022-11-01'
order by user_id,report_date
) as temp
) as temp2
group by user_id
) as tmp3;
+---------+--------------------+------+
| user_id | funnel_name | step |
+---------+--------------------+------+
| u006 | 购买转化漏斗 | 4 |
| u007 | 购买转化漏斗 | 2 |
| u005 | 购买转化漏斗 | 3 |
| u004 | 购买转化漏斗 | 3 |
| u010 | 购买转化漏斗 | 0 |
| u001 | 购买转化漏斗 | 3 |
| u003 | 购买转化漏斗 | 2 |
| u002 | 购买转化漏斗 | 3 |
| u008 | 购买转化漏斗 | 3 |
| u009 | 购买转化漏斗 | 2 |
+---------+--------------------+------+
-- 最后计算转换率
select
funnel_name,
sum(if(step >= 1 ,1,0)) as step1,
sum(if(step >= 2 ,1,0)) as step2,
sum(if(step >= 3 ,1,0)) as step3,
sum(if(step >= 4 ,1,0)) as step4,
round(sum(if(step >= 2 ,1,0))/sum(if(step >= 1 ,1,0)),2) as 'step1->step2_radio',
round(sum(if(step >= 3 ,1,0))/sum(if(step >= 2 ,1,0)),2) as 'step2->step3_radio',
round(sum(if(step >= 4 ,1,0))/sum(if(step >= 3 ,1,0)),2) as 'step3->step4_radio'
from
(
select
'购买转化漏斗' as funnel_name ,
case
-- 正则匹配,先触发过e1,在触发过e2,在触发过e4,在触发过e5
when event_seq regexp('e1.*e2.*e4.*e5') then 4
-- 正则匹配,先触发过e1,在触发过e2,在触发过e4
when event_seq regexp('e1.*e2.*.*e4') then 3
-- 正则匹配,先触发过e1,在触发过e2
when event_seq regexp('e1.*e2') then 2
-- 正则匹配,只触发过e1
when event_seq regexp('e1') then 1
else 0 end step
from
(
select
user_id,
max(event_seq) as event_seq
from
-- 因为在doris1.1版本中还不支持数组,所以拼接字符串的时候还没办法排序
(
select
user_id,
-- 用开窗的方式进行排序,然后在有序的按照时间升序,将事件拼接
group_concat(concat(report_date,'_',event_id),'|')over(partition by user_id order by report_date) as event_seq
from event_info_log
where to_date(report_date) = '2022-11-01'
and event_id in('e1','e4','e5','e2')
) as tmp
group by user_id
) as t1
) as t2
group by funnel_name;
+--------------------+-------+-------+-------+-------+--------------------+--------------------+--------------------+
| funnel_name | step1 | step2 | step3 | step4 | step1->step2_radio | step2->step3_radio | step3->step4_radio |
+--------------------+-------+-------+-------+-------+--------------------+--------------------+--------------------+
| 购买转化漏斗 | 9 | 9 | 6 | 1 | 1 | 0.67 | 0.17 |
+--------------------+-------+-------+-------+-------+--------------------+-------------
5.4、漏斗模型分析函数window_funnel
封装、要素(时间范围,事件的排序时间依据,漏斗模型的事件链)
语法:
window_funnel(window, mode, timestamp_column, event1, event2, ... , eventN)
漏斗分析函数搜索滑动时间窗口内最大的发生的最大事件序列长度。
-- window :滑动时间窗口大小,单位为秒。
-- mode :保留,目前只支持default。-- 相邻两个事件之间没有时间间隔要求,并且相邻两个事件中可以做其他的事件
-- timestamp_column :指定时间列,类型为DATETIME, 滑动窗口沿着此列工作。
-- eventN :表示事件的布尔表达式。
select
user_id,
window_funnel(3600*24, 'default', event_time, event_id='e1', event_id='e2' , event_id='e4', event_id='e5') as step
from event_info_log
group by user_id
+---------+------+
| user_id | step |
+---------+------+
| u006 | 4 |
| u007 | 2 |
| u005 | 3 |
| u004 | 3 |
| u010 | 0 |
| u001 | 3 |
| u003 | 2 |
| u002 | 3 |
| u008 | 3 |
| u009 | 2 |
+---------+------+
-- 算每一层级的转换率
select
'购买转化漏斗' as funnel_name,
sum(if(step >= 1 ,1,0)) as step1,
sum(if(step >= 2 ,1,0)) as step2,
sum(if(step >= 3 ,1,0)) as step3,
sum(if(step >= 4 ,1,0)) as step4,
round(sum(if(step >= 2 ,1,0))/sum(if(step >= 1 ,1,0)),2) as 'step1->step2_radio',
round(sum(if(step >= 3 ,1,0))/sum(if(step >= 2 ,1,0)),2) as 'step2->step3_radio',
round(sum(if(step >= 4 ,1,0))/sum(if(step >= 3 ,1,0)),2) as 'step3->step4_radio'
from
(
select
user_id,
window_funnel(3600*24, 'default', report_date, event_id='e1', event_id='e2' , event_id='e4', event_id='e5') as step
from event_info_log
where to_date(report_date) = '2022-11-01'
and event_id in('e1','e4','e5','e2')
group by user_id
) as t1
-- res
+--------------------+-------+-------+-------+-------+--------------------+--------------------+--------------------+
| funnel_name | step1 | step2 | step3 | step4 | step1->step2_radio | step2->step3_radio | step3->step4_radio |
+--------------------+-------+-------+-------+-------+--------------------+--------------------+--------------------+
| 购买转化漏斗 | 9 | 9 | 6 | 1 | 1 | 0.67 | 0.17 |
+--------------------+-------+-------+-------+-------+--------------------+--------------------+--------------------+
6、doris进阶
6.1、修改表
1、将名为 table1 的表修改为 table2
ALTER TABLE table1 RENAME table2;
-- 示例
ALTER TABLE aggregate_test RENAME aggregate_test1;
2、将表 example_table 中名为 p1 的 partition 修改为 p2
ALTER TABLE example_table RENAME PARTITION old_partition_name new_partition_name ;
-- 示例:
ALTER TABLE expamle_range_tbl RENAME PARTITION p201701 newp201701;
mysql> show partitions from expamle_range_tbl \G;
*************************** 1. row ***************************
PartitionId: 11738
PartitionName: newp201701
VisibleVersion: 1
VisibleVersionTime: 2023-01-03 16:06:05
State: NORMAL
PartitionKey: date
Range: [types: [DATE]; keys: [0000-01-01]; ..types: [DATE]; keys: [2017-02-01]; )
DistributionKey: user_id
Buckets: 1
ReplicationNum: 3
StorageMedium: HDD
CooldownTime: 9999-12-31 23:59:59
LastConsistencyCheckTime: NULL
DataSize: 0.000
IsInMemory: false
ReplicaAllocation: tag.location.default: 3
3、表结构的变更
用户可以通过 Schema Change 操作来修改已存在表的 Schema。目前 Doris 支持以下几种修改:
- 增加、删除列
- 修改列类型
- 调整列顺序
- 增加、修改 Bloom Filter index
- 增加、删除 bitmap index
原理介绍
执行 Schema Change 的基本过程,是通过原 Index 的数据,生成一份新 Schema 的 Index 的数据。其中主要需要进行两部分数据转换:
一:是已存在的历史数据的转换;
二:是在 Schema Change 执行过程中,新到达的导入数据的转换。
+----------+
| Load Job |
+----+-----+
|
| Load job generates both origin and new index data
|
| +------------------+ +---------------+
| | Origin Index | | Origin Index |
+------> New Incoming Data| | History Data |
| +------------------+ +------+--------+
| |
| | Convert history data
| |
| +------------------+ +------v--------+
| | New Index | | New Index |
+------> New Incoming Data| | History Data |
+------------------+ +---------------+
创建作业
Schema Change 的创建是一个异步过程,作业提交成功后,用户需要通过 SHOW ALTER TABLE COLUMN 命令来查看作业进度。
ALTER TABLE [database.]table alter_clause;
向指定 index 的指定位置添加一列
ALTER TABLE db.table_name
-- 如果增加的是key列 那么,需要在 列类型后面增加key 这个关键字
-- 如果增加的是value列 那么,是聚合表模型,需要指定列的聚合类型 如果是明细模型和唯一模型,不需要指定
ADD COLUMN column_name column_type [KEY | agg_type] [DEFAULT "default_value"]
[AFTER column_name|FIRST] -- 确定列的位置 如果不写,默认插在最后
[TO rollup_index_name] -- 如果你是针对rollup表新增一个列,那么这个列明基表中不能有
[PROPERTIES ("key"="value", ...)]
-- 明细模型中添加value列
ALTER TABLE test.expamle_range_tbl ADD COLUMN abc varchar AFTER age;
-- 明细模型中添加key 列
ALTER TABLE test.expamle_range_tbl ADD COLUMN abckey varchar key AFTER user_id;
-- 聚合模型中添加一个value列
mysql> ALTER TABLE test.ex_user ADD COLUMN abckey int sum AFTER cost;
注意:
- 聚合模型如果增加 value 列,需要指定 agg_type
- 非聚合模型(如 DUPLICATE KEY)如果增加key列,需要指定KEY关键字
- 不能在 rollup index 中增加 base index 中已经存在的列(如有需要,可以重新创建一个 rollup index)
4、向指定 表添加多列
ALTER TABLE db.table_name
ADD COLUMN (column_name1 column_type [KEY | agg_type] DEFAULT "default_value", ...)
[TO rollup_index_name]
[PROPERTIES ("key"="value", ...)]
-- 添加的时候根据key和value列,添加在对应的列之后
ALTER TABLE test.expamle_range_tbl ADD COLUMN (abc int,bcd int);
mysql> ALTER TABLE test.expamle_range_tbl ADD COLUMN (a int key ,b int);
Query OK, 0 rows affected (0.01 sec)
mysql> desc expamle_range_tbl all;
+-------------------+---------------+-----------+-------------+------+-------+---------+-------+---------+
| IndexName | IndexKeysType | Field | Type | Null | Key | Default | Extra | Visible |
+-------------------+---------------+-----------+-------------+------+-------+---------+-------+---------+
| expamle_range_tbl | DUP_KEYS | user_id | LARGEINT | No | true | NULL | | true |
| | | abckey | VARCHAR(1) | Yes | true | NULL | | true |
| | | date | DATE | No | true | NULL | | true |
| | | a | INT | Yes | true | NULL | | true |
| | | timestamp | DATETIME | No | false | NULL | NONE | true |
| | | city | VARCHAR(20) | Yes | false | NULL | NONE | true |
| | | age | SMALLINT | Yes | false | NULL | NONE | true |
| | | sex | TINYINT | Yes | false | NULL | NONE | true |
| | | abc | INT | Yes | false | NULL | NONE | true |
| | | bcd | INT | Yes | false | NULL | NONE | true |
| | | b | INT | Yes | false | NULL | NONE | true |
+-------------------+---------------+-----------+-------------+------+-------+---------+-------+---------+
5、从指定 表中删除一列
ALTER TABLE db.table_name
DROP COLUMN column_name
[FROM rollup_index_name]
-- 删除明细表中的value列
ALTER TABLE test.expamle_range_tbl DROP COLUMN abc;
-- 删除明细表中的key列
ALTER TABLE test.expamle_range_tbl DROP COLUMN abckey;
-- 删除聚合模型中的value列
ALTER TABLE test.ex_user DROP COLUMN abckey;
注意:
- 不能删除分区列
- 如果是从 base index 中删除列,则如果 rollup index 中包含该列,也会被删除
6、查看作业
SHOW ALTER TABLE COLUMN 可以查看当前正在执行或已经完成的 Schema Change 作业。当一次 Schema Change 作业涉及到多个 Index 时,该命令会显示多行,每行对应一个 Index
mysql> SHOW ALTER TABLE COLUMN\G;
*************************** 1. row ***************************
JobId: 20021
TableName: tbl1
CreateTime: 2019-08-05 23:03:13
FinishTime: 2019-08-05 23:03:42
IndexName: tbl1
IndexId: 20022
OriginIndexId: 20017
SchemaVersion: 2:792557838
TransactionId: 10023
State: FINISHED
Msg:
Progress: NULL
Timeout: 86400
1 row in set (0.00 sec)
- JobId:每个 Schema Change 作业的唯一 ID。
- TableName:Schema Change 对应的基表的表名。
- CreateTime:作业创建时间。
- FinishedTime:作业结束时间。如未结束,则显示 “N/A”。
- IndexName:本次修改所涉及的某一个 Index 的名称。
- IndexId:新的 Index 的唯一 ID。
- OriginIndexId:旧的 Index 的唯一 ID。
- SchemaVersion:以 M:N 的格式展示。其中 M 表示本次 Schema Change 变更的版本,N 表示对应的 Hash 值。每次 Schema Change,版本都会递增。
- TransactionId:转换历史数据的分水岭 transaction ID。
- State:作业所在阶段。
- PENDING:作业在队列中等待被调度。
- WAITING_TXN:等待分水岭 transaction ID 之前的导入任务完成。
- RUNNING:历史数据转换中。
- FINISHED:作业成功。
- CANCELLED:作业失败。
- Msg:如果作业失败,这里会显示失败信息。
- Progress:作业进度。只有在 RUNNING 状态才会显示进度。进度是以 M/N 的形式显示。其中 N 为 Schema Change 涉及的总副本数。M 为已完成历史数据转换的副本数。
- Timeout:作业超时时间。单位秒。
7、取消作业
在作业状态不为 FINISHED 或 CANCELLED 的情况下,可以通过以下命令取消Schema Change作业:
CANCEL ALTER TABLE COLUMN FROM tbl_name;
注意事项
- 一张表在同一时间只能有一个 Schema Change 作业在运行。
- Schema Change 操作不阻塞导入和查询操作。
- 分区列和分桶列不能修改。
- 如果 Schema 中有 REPLACE 方式聚合的 value 列,则不允许删除 Key 列。
- 如果删除 Key 列,Doris 无法决定 REPLACE 列的取值。
- Unique 数据模型表的所有非 Key 列都是 REPLACE 聚合方式。
- 在新增聚合类型为 SUM 或者 REPLACE 的 value 列时,该列的默认值对历史数据没有含义。
- 因为历史数据已经失去明细信息,所以默认值的取值并不能实际反映聚合后的取值。
- 当修改列类型时,除 Type 以外的字段都需要按原列上的信息补全。
- 如修改列 k1 INT SUM NULL DEFAULT “1” 类型为 BIGINT,则需执行命令如下:
- ALTER TABLE tbl1 MODIFY COLUMN k1 BIGINT SUM NULL DEFAULT “1”;
- 注意,除新的列类型外,如聚合方式,Nullable 属性,以及默认值都要按照原信息补全。
- 不支持修改列名称、聚合类型、Nullable 属性、默认值以及列注释。
8、partition分区的增减
1、增加分区, 使用默认分桶方式:现有分区 [MIN, 2013-01-01),增加分区 [2013-01-01, 2014-01-01)
ALTER TABLE example_db.my_table ADD PARTITION p1 VALUES LESS THAN ("2014-01-01");
2、增加分区,使用新的分桶数
ALTER TABLE example_db.my_table ADD PARTITION p1 VALUES LESS THAN ("2015-01-01")
DISTRIBUTED BY HASH(k1) BUCKETS 20;
3、增加分区,使用新的副本数
ALTER TABLE example_db.my_table ADD PARTITION p1 VALUES LESS THAN ("2015-01-01")
("replication_num"="1");
4、修改分区副本数
ALTER TABLE example_db.my_table MODIFY PARTITION p1 SET("replication_num"="1");
5、批量修改指定分区
ALTER TABLE example_db.my_table MODIFY PARTITION (p1, p2, p4) SET("in_memory"="true");
6、批量修改所有分区
ALTER TABLE example_db.my_table MODIFY PARTITION (*) SET("storage_medium"="HDD");
7、删除分区
ALTER TABLE example_db.my_table DROP PARTITION p1;
8、增加一个指定上下界的分区
ALTER TABLE example_db.my_table ADD PARTITION p1 VALUES [("2014-01-01"), ("2014-02-01"));
6.2、动态分区和临时分区
1、动态分区
旨在对表级别的分区实现生命周期管理(TTL),减少用户的使用负担。
目前实现了动态添加分区及动态删除分区的功能。只支持 Range 分区。
原理
在某些使用场景下,用户会将表按照天进行分区划分,每天定时执行例行任务,这时需要使用方手动管理分区,否则可能由于使用方没有创建分区导致数据导入失败,这给使用方带来了额外的维护成本。通过动态分区功能,用户可以在建表时设定动态分区的规则。FE 会启动一个后台线程,根据用户指定的规则创建或删除分区。用户也可以在运行时对现有规则进行变更。
使用方式
动态分区的规则可以在建表时指定,或者在运行时进行修改。当前仅支持对单分区列的分区表设定动态分区规则
建表时指定:
CREATE TABLE tbl1
(...)
PROPERTIES
(
-- 添加动态分区的规则
"dynamic_partition.prop1" = "value1",
"dynamic_partition.prop2" = "value2",
...
)
运行时修改:
ALTER TABLE tbl1 SET
(
"dynamic_partition.prop1" = "value1",
"dynamic_partition.prop2" = "value2",
...
)
动态分区规则参数
1、dynamic_partition.enable:是否开启动态分区特性。默认是true
2、dynamic_partition.time_unit:动态分区调度的单位。可指定为 HOUR、DAY、WEEK、MONTH。分别表示按小时、按天、按星期、按月进行分区创建或删除。
3、dynamic_partition.time_zone:动态分区的时区,如果不填写,则默认为当前机器的系统的时区
4、dynamic_partition.start:动态分区的起始偏移,为负数。以当天(星期/月)为基准,分区范围在此偏移之前的分区将会被删除。如果不填写,则默认为 -2147483648,即不删除历史分区。
5、dynamic_partition.end:动态分区的结束偏移,为正数。根据 time_unit 属性的不同,以当天(星期/月)为基准,提前创建对应范围的分区。
6、dynamic_partition.prefix:动态创建的分区名前缀。
7、dynamic_partition.buckets:动态创建的分区所对应的分桶数量
8、dynamic_partition.replication_num:动态创建的分区所对应的副本数量,如果不填写,则默认为该表创建时指定的副本数量
9、dynamic_partition.start_day_of_week:当 time_unit 为 WEEK 时,该参数用于指定每周的起始点。取值为 1 到 7。其中 1 表示周一,7 表示周日。默认为 1,即表示每周以周一为起始点。
10、dynamic_partition.start_day_of_month:当 time_unit 为 MONTH 时,该参数用于指定每月的起始日期。取值为 1 到 28。其中 1 表示每月1号,28 表示每月28号。默认为 1,即表示每月以1号位起始点。暂不支持以29、30、31号为起始日,以避免因闰年或闰月带来的歧义
11、dynamic_partition.create_history_partition:为 true 时代表可以创建历史分区,默认是false
12、dynamic_partition.history_partition_num:当 create_history_partition 为 true 时,该参数用于指定创建历史分区数量。默认值为 -1, 即未设置。
13、dynamic_partition.hot_partition_num:指定最新的多少个分区为热分区。对于热分区,系统会自动设置其 storage_medium 参数为SSD,并且设置 storage_cooldown_time 。hot_partition_num:设置往前 n 天和未来所有分区为热分区,并自动设置冷却时间
举例说明
假设今天是 2021-05-20,按天分区,动态分区的属性设置为:
hot_partition_num=2,
end=3,
start=-3。
则系统会自动创建以下分区,并且设置 storage_medium 和 storage_cooldown_time 参数:
p20210517:["2021-05-17", "2021-05-18") storage_medium=HDD storage_cooldown_time=9999-12-31 23:59:59
p20210518:["2021-05-18", "2021-05-19") storage_medium=HDD storage_cooldown_time=9999-12-31 23:59:59
p20210519:["2021-05-19", "2021-05-20") storage_medium=SSD storage_cooldown_time=2021-05-21 00:00:00
p20210520:["2021-05-20", "2021-05-21") storage_medium=SSD storage_cooldown_time=2021-05-22 00:00:00
p20210521:["2021-05-21", "2021-05-22") storage_medium=SSD storage_cooldown_time=2021-05-23 00:00:00
p20210522:["2021-05-22", "2021-05-23") storage_medium=SSD storage_cooldown_time=2021-05-24 00:00:00
p20210523:["2021-05-23", "2021-05-24") storage_medium=SSD storage_cooldown_time=2021-05-25 00:00:00
查看动态分区表调度情况
mysql> SHOW DYNAMIC PARTITION TABLES;
+-----------+--------+----------+-------------+------+--------+---------+-----------+----------------+---------------------+--------+------------------------+----------------------+-------------------------+
| TableName | Enable | TimeUnit | Start | End | Prefix | Buckets | StartOf | LastUpdateTime | LastSchedulerTime | State | LastCreatePartitionMsg | LastDropPartitionMsg | ReservedHistoryPeriods |
+-----------+--------+----------+-------------+------+--------+---------+-----------+----------------+---------------------+--------+------------------------+----------------------+-------------------------+
| d3 | true | WEEK | -3 | 3 | p | 1 | MONDAY | N/A | 2020-05-25 14:29:24 | NORMAL | N/A | N/A | [2021-12-01,2021-12-31] |
| d5 | true | DAY | -7 | 3 | p | 32 | N/A | N/A | 2020-05-25 14:29:24 | NORMAL | N/A | N/A | NULL |
| d4 | true | WEEK | -3 | 3 | p | 1 | WEDNESDAY | N/A | 2020-05-25 14:29:24 | NORMAL | N/A | N/A | NULL |
| d6 | true | MONTH | -2147483648 | 2 | p | 8 | 3rd | N/A | 2020-05-25 14:29:24 | NORMAL | N/A | N/A | NULL |
| d2 | true | DAY | -3 | 3 | p | 32 | N/A | N/A | 2020-05-25 14:29:24 | NORMAL | N/A | N/A | NULL |
| d7 | true | MONTH | -2147483648 | 5 | p | 8 | 24th | N/A | 2020-05-25 14:29:24 | NORMAL | N/A | N/A | NULL |
+-----------+--------+----------+-------------+------+--------+---------+-----------+----------------+---------------------+--------+------------------------+----------------------+-------------------------+
7 rows in set (0.02 sec)
2、临时分区
1、临时分区的分区列和正式分区相同,且不可修改。
2、一张表所有临时分区之间的分区范围不可重叠,但临时分区的范围和正式分区范围可以重叠。
3、临时分区的分区名称不能和正式分区以及其他临时分区重复。
添加临时分区
ALTER TABLE tbl1 ADD TEMPORARY PARTITION tp1 VALUES LESS THAN("2020-02-01");
ALTER TABLE tbl1 ADD TEMPORARY PARTITION tp2 VALUES LESS THAN("2020-02-02")
("in_memory" = "true", "replication_num" = "1")
DISTRIBUTED BY HASH(k1) BUCKETS 5;
ALTER TABLE tbl3 ADD TEMPORARY PARTITION tp1 VALUES IN ("Beijing", "Shanghai");
ALTER TABLE tbl3 ADD TEMPORARY PARTITION tp1 VALUES IN ("Beijing", "Shanghai")
("in_memory" = "true", "replication_num" = "1")
DISTRIBUTED BY HASH(k1) BUCKETS 5;
注意:
1、临时分区的添加和正式分区的添加操作相似。临时分区的分区范围独立于正式分区。
2、临时分区可以独立指定一些属性。包括分桶数、副本数、是否是内存表、存储介质等信息。
3、删除临时分区,不影响正式分区的数据。
删除临时分区
ALTER TABLE tbl1 DROP TEMPORARY PARTITION tp1;
替换分区
可以通过 ALTER TABLE REPLACE PARTITION 语句将一个表的正式分区替换为临时分区。
-- 正式分区替换成临时分区以后,正是分区的数据会被删除,并且这个过程是不可逆的
-- 用之前要小心
ALTER TABLE tbl1 REPLACE PARTITION (p1) WITH TEMPORARY PARTITION (tp1);
ALTER TABLE partition_test REPLACE PARTITION (p20230104) WITH TEMPORARY PARTITION (tp1);
ALTER TABLE tbl1 REPLACE PARTITION (p1, p2) WITH TEMPORARY PARTITION (tp1, tp2)
PROPERTIES (
"strict_range" = "false",
"use_temp_partition_name" = "true"
);
-
strict_range:默认为 true。
对于 Range 分区,当该参数为 true 时,表示要被替换的所有正式分区的范围并集需要和替换的临时分区的范围并集完全相同。当置为 false 时,只需要保证替换后,新的正式分区间的范围不重叠即可。
对于 List 分区,该参数恒为 true。要被替换的所有正式分区的枚举值必须和替换的临时分区枚举值完全相同。 -
use_temp_partition_name:默认为 false。
当该参数为 false,并且待替换的分区和替换分区的个数相同时,则替换后的正式分区名称维持不变。如果为 true,则替换后,正式分区的名称为替换分区的名称。
导入临时分区
NSERT INTO tbl TEMPORARY PARTITION(tp1, tp2, ...) SELECT ....
查看临时分区数据
SELECT ... FROM
tbl1 TEMPORARY PARTITION(tp1, tp2, ...)
JOIN
tbl2 TEMPORARY PARTITION(tp1, tp2, ...)
ON ...
WHERE ...;
6.3、 doris中join的优化原理
1、 Shuffle Join(Partitioned Join)
和mr中的shuffle过程是一样的,针对每个节点上的数据进行shuffle,相同数据分发到下游的节点上的join方式叫shuffle join
订单详细表
CREATE TABLE test.order_info_shuffle
(
`order_id` varchar(20) COMMENT "订单id",
`user_id` varchar(20) COMMENT "用户id",
`goods_id` VARCHAR(20) COMMENT "商品id",
`goods_num` Int COMMENT "商品数量",
`price` double COMMENT "商品价格"
)
duplicate KEY(`order_id`)
DISTRIBUTED BY HASH(`order_id`) BUCKETS 5;
导入数据:
insert into test.order_info_shuffle values\
('o001','u001','g001',1,9.9 ),\
('o001','u001','g002',2,19.9),\
('o001','u001','g003',2,39.9),\
('o002','u002','g001',3,9.9 ),\
('o002','u002','g002',1,19.9),\
('o003','u002','g003',1,39.9),\
('o003','u002','g002',2,19.9),\
('o003','u002','g004',3,99.9),\
('o003','u002','g005',1,99.9),\
('o004','u003','g001',2,9.9 ),\
('o004','u003','g002',1,19.9),\
('o004','u003','g003',4,39.9),\
('o004','u003','g004',1,99.9),\
('o004','u003','g005',4,89.9);
商品表
CREATE TABLE test.goods_shuffle
(
`goods_id` VARCHAR(20) COMMENT "商品id",
`goods_name` VARCHAR(20) COMMENT "商品名称",
`category_id` VARCHAR(20) COMMENT "商品品类id"
)
duplicate KEY(`goods_id`)
DISTRIBUTED BY HASH(`goods_id`) BUCKETS 5;
导入数据:
insert into test.goods_shuffle values\
('g001','iphon13','c001'),\
('g002','ipad','c002'),\
('g003','xiaomi12','c001'),\
('g004','huaweip40','c001'),\
('g005','headset','c003');
sql
EXPLAIN
select
oi.order_id,
oi.user_id,
oi.goods_id,
gs.goods_name,
gs.category_id,
oi.goods_num,
oi.price
from order_info_shuffle as oi
-- 我们可以不指定哪一种join方式,doris会自己根据数据的实际情况帮我们选择
JOIN goods_shuffle as gs
on oi.goods_id = gs.goods_id;
EXPLAIN select
oi.order_id,
oi.user_id,
oi.goods_id,
gs.goods_name,
gs.category_id,
oi.goods_num,
oi.price
from order_info_shuffle as oi
-- 可以显式的hint指定我们想要的join类型
JOIN [shuffle] goods_shuffle as gs
on oi.goods_id = gs.goods_id;
适用场景:不管数据量,不管是大表join大表还是大表join小表都可以用
优点:通用
缺点:需要shuffle内存和网络开销比较大,效率不高
2、Broadcast Join
当一个大表join小表的时候,将小表广播到每一个大表所在的每一个节点上(以hash表的形式放在内存中)这样的方式叫做Broadcast Join,类似于mr里面的一个map端join
 订单明细表
订单明细表
CREATE TABLE test.order_info_broadcast
(
`order_id` varchar(20) COMMENT "订单id",
`user_id` varchar(20) COMMENT "用户id",
`goods_id` VARCHAR(20) COMMENT "商品id",
`goods_num` Int COMMENT "商品数量",
`price` double COMMENT "商品价格"
)
duplicate KEY(`order_id`)
DISTRIBUTED BY HASH(`goods_id`) BUCKETS 5;
导入数据:
insert into test.order_info_broadcast values\
('o001','u001','g001',1,9.9 ),\
('o001','u001','g002',2,19.9),\
('o001','u001','g003',2,39.9),\
('o002','u002','g001',3,9.9 ),\
('o002','u002','g002',1,19.9),\
('o003','u002','g003',1,39.9),\
('o003','u002','g002',2,19.9),\
('o003','u002','g004',3,99.9),\
('o003','u002','g005',1,99.9),\
('o004','u003','g001',2,9.9 ),\
('o004','u003','g002',1,19.9),\
('o004','u003','g003',4,39.9),\
('o004','u003','g004',1,99.9),\
('o004','u003','g005',4,89.9);
商品表
CREATE TABLE test.goods_broadcast
(
`goods_id` VARCHAR(20) COMMENT "商品id",
`goods_name` VARCHAR(20) COMMENT "商品名称",
`category_id` VARCHAR(20) COMMENT "商品品类id"
)
duplicate KEY(`goods_id`)
DISTRIBUTED BY HASH(`goods_id`) BUCKETS 5;
导入数据:
insert into test.goods_broadcast values\
('g001','iphon13','c001'),\
('g002','ipad','c002'),\
('g003','xiaomi12','c001'),\
('g004','huaweip40','c001'),\
('g005','headset','c003');
显式使用 Broadcast Join:
EXPLAIN
select
oi.order_id,
oi.user_id,
oi.goods_id,
gs.goods_name,
gs.category_id,
oi.goods_num,
oi.price
from order_info_broadcast as oi
JOIN [broadcast] goods_broadcast as gs
on oi.goods_id = gs.goods_id;
一般用在什么场景下:左表join右表,要求左表的数据量相对来说比较大,右表数据量比较小
优点:避免了shuffle,提高了运算效率
缺点:有限制,必须右表数据量比较小
3、Bucket Shuffle Join
利用建表时候分桶的特性,当join的时候,join的条件和左表的分桶字段一样的时候,将右表按照左表分桶的规则进行shuffle操作,使右表中需要join的数据落在左表中需要join数据的BE节点上的join方式叫做Bucket Shuffle Join。
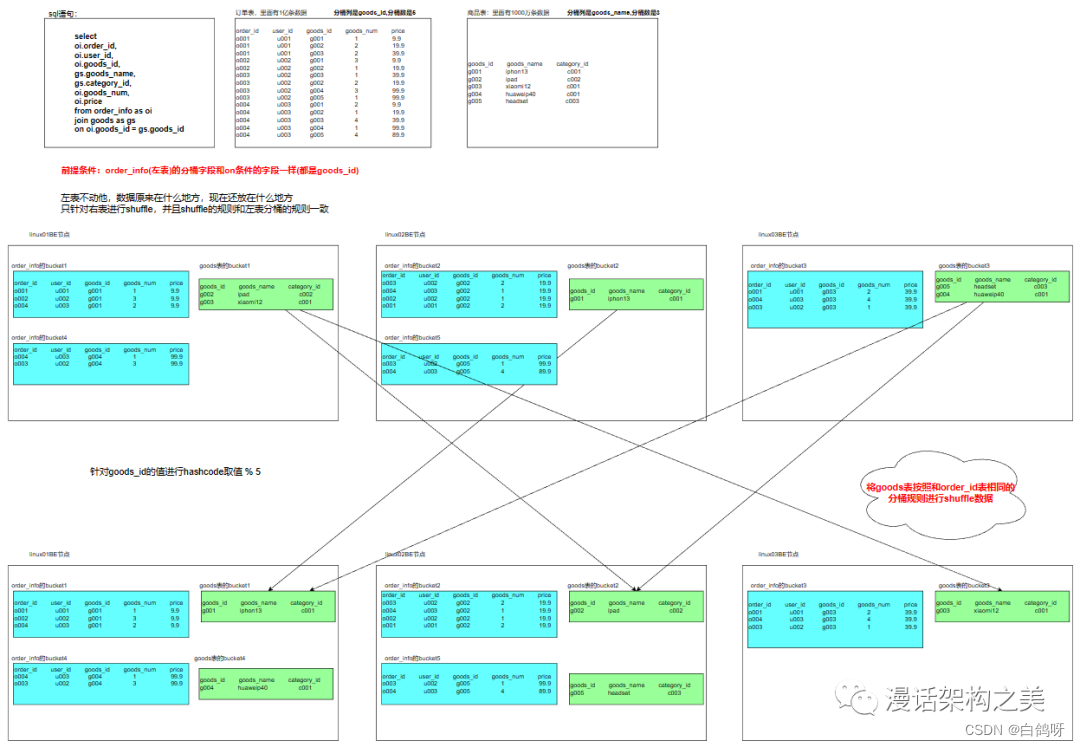 订单表
订单表
CREATE TABLE test.order_info_bucket
(
`order_id` varchar(20) COMMENT "订单id",
`user_id` varchar(20) COMMENT "用户id",
`goods_id` VARCHAR(20) COMMENT "商品id",
`goods_num` Int COMMENT "商品数量",
`price` double COMMENT "商品价格"
)
duplicate KEY(`order_id`)
DISTRIBUTED BY HASH(`goods_id`) BUCKETS 5;
导入数据:
insert into test.order_info_bucket values\
('o001','u001','g001',1,9.9 ),\
('o001','u001','g002',2,19.9),\
('o001','u001','g003',2,39.9),\
('o002','u002','g001',3,9.9 ),\
('o002','u002','g002',1,19.9),\
('o003','u002','g003',1,39.9),\
('o003','u002','g002',2,19.9),\
('o003','u002','g004',3,99.9),\
('o003','u002','g005',1,99.9),\
('o004','u003','g001',2,9.9 ),\
('o004','u003','g002',1,19.9),\
('o004','u003','g003',4,39.9),\
('o004','u003','g004',1,99.9),\
('o004','u003','g005',4,89.9);
商品表
CREATE TABLE test.goods_bucket
(
`goods_id` VARCHAR(20) COMMENT "商品id",
`goods_name` VARCHAR(20) COMMENT "商品名称",
`category_id` VARCHAR(20) COMMENT "商品品类id"
)
duplicate KEY(`goods_id`)
DISTRIBUTED BY HASH(`goods_id`) BUCKETS 3;
CREATE TABLE test.goods_bucket1
(
`goods_id` VARCHAR(20) COMMENT "商品id",
`goods_name` VARCHAR(20) COMMENT "商品名称",
`category_id` VARCHAR(20) COMMENT "商品品类id"
)
duplicate KEY(`goods_id`)
DISTRIBUTED BY HASH(`goods_name`) BUCKETS 3;
导入数据:
insert into test.goods_bucket1 values\
('g001','iphon13','c001'),\
('g002','ipad','c002'),\
('g003','xiaomi12','c001'),\
('g004','huaweip40','c001'),\
('g005','headset','c003');
sql
EXPLAIN
select
oi.order_id,
oi.user_id,
oi.goods_id,
gs.goods_name,
gs.category_id,
oi.goods_num,
oi.price
from order_info_bucket as oi
-- 目前 Bucket Shuffle Join不能像Shuffle Join那样可以显示指定Join方式,
-- 只能让执行引擎自动选择,
-- 选择的顺序:Colocate Join -> Bucket Shuffle Join -> Broadcast Join -> Shuffle Join。
JOIN goods_bucket1 as gs
where oi.goods_id = gs.goods_id;
EXPLAIN select
oi.order_id,
oi.user_id,
oi.goods_id,
gs.goods_name,
gs.category_id,
oi.goods_num,
oi.price
from order_info_bucket as oi
-- 目前 Bucket Shuffle Join不能像Shuffle Join那样可以显示指定Join方式,
-- 只能让执行引擎自动选择,
-- 选择的顺序:Colocate Join -> Bucket Shuffle Join -> Broadcast Join -> Shuffle Join。
JOIN goods_bucket1 as gs
where oi.goods_id = gs.goods_id;
1、Bucket Shuffle Join 只生效于 Join 条件为等值的场景
2、Bucket Shuffle Join 要求左表的分桶列的类型与右表等值 join 列的类型需要保持一致,否则无法进行对应的规划。
3、Bucket Shuffle Join 只作用于 Doris 原生的 OLAP 表,对于 ODBC,MySQL,ES 等外表,当其作为左表时是无法规划生效的。
4、Bucket Shuffle Join只能保证左表为单分区时生效。所以在 SQL 执行之中,需要尽量使用 where 条件使分区裁剪的策略能够生效。
4、Colocation Join
协同分组join,指需要join的两份数据都在同一个BE节点上,这样在join的时候,直接本地join计算即可,不需要进行shuffle。
Colocation Group(位置协同组CG):在同一个 CG内的 Table 有着相同的 Colocation Group Schema,并且有着相同的数据分片分布(满足三个条件**)**。
Colocation Group Schema(CGS):用于描述一个 CG 中的 Table,和 Colocation 相关的通用 Schema 信息。包括分桶列类型,分桶数以及分区的副本数等。

使用限制
1、建表时两张表的分桶列的类型和数量需要完全一致,并且桶数一致,才能保证多张表的数据分片能够一一对应的进行分布控制。
2、同一个 CG 内所有表的所有分区(Partition)的副本数必须一致。如果不一致,可能出现某一个Tablet 的某一个副本,在同一个 BE 上没有其他的表分片的副本对应
3、同一个 CG 内的表,分区的个数、范围以及分区列的类型不要求一致。
5、Runtime Filter
Runtime Filter会在有join动作的 sql运行时,创建一个HashJoinNode和一个ScanNode来对join的数据进行过滤优化,使得join的时候数据量变少,从而提高效率。
使用
指定 RuntimeFilter 类型
set runtime_filter_type="BLOOM_FILTER,IN,MIN_MAX";
set runtime_filter_type="MIN_MAX";
1、runtime_filter_type: 包括Bloom Filter、MinMax Filter、IN predicate、IN Or Bloom Filter
2、Bloom Filter: 针对右表中的join字段的所有数据标注在一个布隆过滤器中,从而判断左表中需要join的数据在还是不在
3、MinMax Filter: 获取到右表表中数据的最大值和最小值,看左表中查看,将超出这个最大值最小值范围的数据过滤掉
4、IN predicate: 将右表中需要join字段所有数据构建一个IN predicate,再去左表表中过滤无意义数据
5、runtime_filter_wait_time_ms: 左表的ScanNode等待每个Runtime Filter的时间,默认1000ms
6、runtime_filters_max_num: 每个查询可应用的Runtime Filter中Bloom Filter的最大数量,默认10
7、runtime_bloom_filter_min_size: Runtime Filter中Bloom Filter的最小长度,默认1M
8、runtime_bloom_filter_max_size: Runtime Filter中Bloom Filter的最大长度,默认16M
9、runtime_bloom_filter_size: Runtime Filter中Bloom Filter的默认长度,默认2M
10、runtime_filter_max_in_num: 如果join右表数据行数大于这个值,我们将不生成IN predicate,默认102400
示例
建表
CREATE TABLE test (t1 INT) DISTRIBUTED BY HASH (t1) BUCKETS 2
PROPERTIES("replication_num" = "1");
INSERT INTO test VALUES (1), (2), (3), (4);
CREATE TABLE test2 (t2 INT) DISTRIBUTED BY HASH (t2) BUCKETS 2
PROPERTIES("replication_num" = "1");
INSERT INTO test2 VALUES (3), (4), (5);
分析
EXPLAIN SELECT t1 FROM test JOIN test2 where test.t1 = test2.t2;
+----------------------------------------------------------------------------+
| Explain String |
+----------------------------------------------------------------------------+
| PLAN FRAGMENT 0 |
| OUTPUT EXPRS:<slot 2> |
| PARTITION: UNPARTITIONED |
| |
| VRESULT SINK |
| |
| 4:VEXCHANGE |
| |
| PLAN FRAGMENT 1 |
| |
| PARTITION: HASH_PARTITIONED: `default_cluster:test`.`test`.`t1` |
| |
| STREAM DATA SINK |
| EXCHANGE ID: 04 |
| UNPARTITIONED |
| |
| 2:VHASH JOIN |
-- 这边能够看到使用的join方式是BUCKET_SHUFFLE
| | join op: INNER JOIN(BUCKET_SHUFFLE)[Tables are not in the same group] |
| | equal join conjunct: `test`.`t1` = `test2`.`t2` |
-- 这边能够看到使用的运行时过滤方式是in_or_bloom
| | runtime filters: RF000[in_or_bloom] <- `test2`.`t2` |
| | cardinality=0 |
| | vec output tuple id: 2 | |
| |----3:VEXCHANGE |
| | |
| 0:VOlapScanNode |
| TABLE: test(test), PREAGGREGATION: ON |
| runtime filters: RF000[in_or_bloom] -> `test`.`t1` |
| partitions=1/1, tablets=2/2, tabletList=14114,14116 |
| cardinality=0, avgRowSize=4.0, numNodes=1 |
| |
| PLAN FRAGMENT 2 |
| |
| PARTITION: HASH_PARTITIONED: `default_cluster:test`.`test2`.`t2` |
| |
| STREAM DATA SINK |
| EXCHANGE ID: 03 |
| BUCKET_SHFFULE_HASH_PARTITIONED: `test2`.`t2` |
| |
| 1:VOlapScanNode |
| TABLE: test2(test2), PREAGGREGATION: ON |
| partitions=1/1, tablets=2/2, tabletList=14122,14124 |
| cardinality=0, avgRowSize=4.0, numNodes=1 |
+----------------------------------------------------------------------------+
原文:https://mp.weixin.qq.com/s/LDIgiDBXGUdpbmloopADAQ