1,编译安装过程就不说了,我没弄,让同事弄的。
2,与zeppelin的整合,实际很简单,就是zeppelin与mysql的整合,下面都是图,都是实操验证过的:
参考zeppelin的文档:
https://github.com/apache/zeppelin/blob/master/docs/interpreter/flink.md#paragraph-local-properties
http://zeppelin.apache.org/docs/latest/interpreter/jdbc.html#mysql


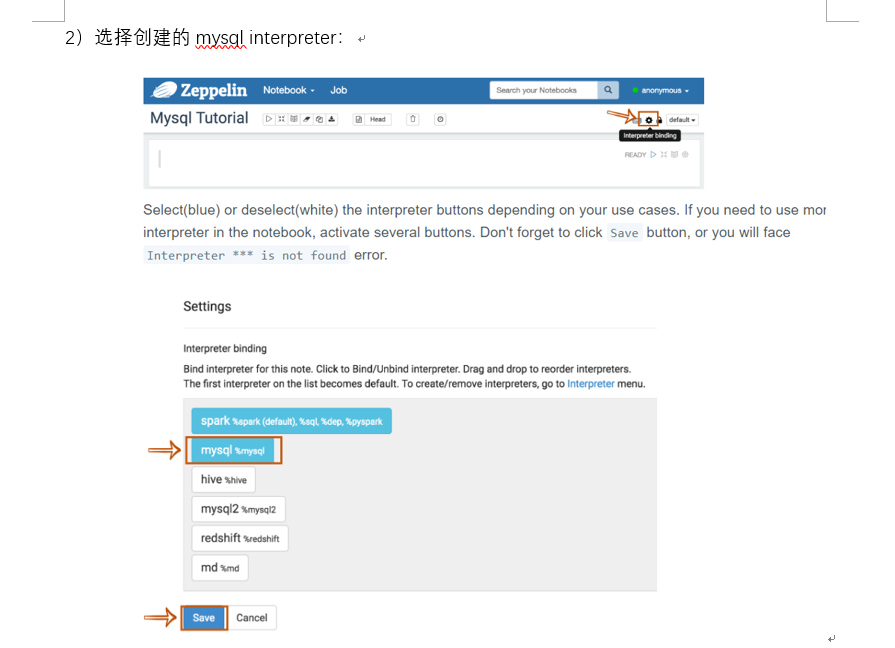

3,这个时候我们要在doris先创建表,在mysql客户端可以看的很清楚,当然在zeppelin也可以看到。
在zeppelin执行sql(我这里是2个模型):
先创建的是doris的要写入的表,后面的表是对应的读取kafka的表。一个sink源,一个是source源.
‘AGGREGATE模型’测试语句:%mysql
CREATE TABLE example_db.testing_table
(
siteid INT DEFAULT '10',
username VARCHAR(32) DEFAULT '',
pv BIGINT SUM DEFAULT '0'
)
AGGREGATE KEY(siteid, username)
DISTRIBUTED BY HASH(siteid) BUCKETS 10
PROPERTIES("replication_num" = "1");CREATE ROUTINE LOAD example_db.testing_topic ON testing_table
COLUMNS TERMINATED BY "|",
COLUMNS(siteid,username,pv)
PROPERTIES(
"desired_concurrent_number"="1",
"max_batch_interval" = "20",
"max_batch_rows" = "300000",
"max_batch_size" = "209715200",
"strict_mode" = "false"
)
FROM KAFKA
(
"kafka_broker_list" = "192.168.12.186:9092",
"kafka_topic" = "test_topic",
"kafka_partitions" = "0",
"kafka_offsets" = "OFFSET_BEGINNING"
);
================
‘Uniq模型’测试语句:%mysql
CREATE TABLE example_db.testing_table
(
siteid INT DEFAULT '10',
username VARCHAR(32) DEFAULT '',
pv BIGINT SUM DEFAULT '0'
)
AGGREGATE KEY(siteid, username)
DISTRIBUTED BY HASH(siteid) BUCKETS 10
PROPERTIES("replication_num" = "1");CREATE TABLE IF NOT EXISTS example_db.testing_table2
(
`siteid` INT NOT NULL COMMENT "用户id",
`username` VARCHAR(50) NOT NULL COMMENT "用户昵称",
`city` VARCHAR(20) COMMENT "用户所在城市",
`pv` BIGINT COMMENT "用户年龄",
`register_time` VARCHAR(50) COMMENT "用户注册时间"
)
UNIQUE KEY(`siteid`, `username`)
DISTRIBUTED BY HASH(siteid) BUCKETS 10
PROPERTIES("replication_num" = "1");CREATE ROUTINE LOAD example_db.testing_topic2 ON testing_table2
COLUMNS TERMINATED BY "|",
COLUMNS(`siteid`,`username`,`pv`,`register_time`)
PROPERTIES(
"desired_concurrent_number"="1",
"max_batch_interval" = "20",
"max_batch_rows" = "5000",
"max_batch_size" = "209715200",
"strict_mode" = "false"
)
FROM KAFKA
(
"kafka_broker_list" = "192.168.12.186:9092",
"kafka_topic" = "test_topic2",
"kafka_partitions" = "0",
"kafka_offsets" = "OFFSET_BEGINNING"
);
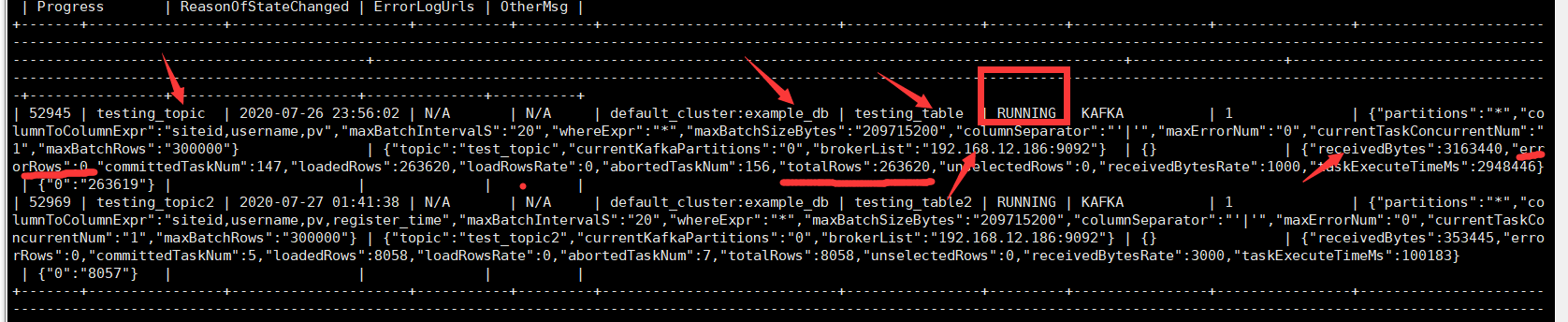
4,在执行sql后我们在zeppelin或者mysql客户端执行命令,查看相关的任务信息:
SHOW ROUTINE LOAD;
下图箭头,很标识的地方看一下就知道是啥意思了。红框很重要,如果这个任务不是running,那么看日志是什么错误,也要看‘errorRows’这个显示是不是为0,不为0代表数据消费error了,要看数据了。
5,我这里的doris是远古版本了,要安装最新的版本,需要加入顶顶群或者微信群。

6,写的很简陋,最后是广告时间:
先跟鸡哥打个广告 ,博客地址: https://me.csdn.net/weixin_47482194
写的博客很有水平的,上了几次官网推荐了。
