RNN也就是循环神经网络,多用于处理时间序列上的数据,比如自然语言处理。
如下图所示,x<1>为输入的第一个数据,x<2>为第二个,以此类推。在普通的神经网络中,x<1>就通过神经网络直接输出y<1>,同理x<2>对应y<2>,但在RNN中,之前的输入对之后的输出也同样有影响。
如图所示,在输出y<2>时,既输入了x<2>,也同样输入了x<1>激活后的a<1>,时间步为多少就意味着y考虑了该时间步内的所有输入。
但是这样就有一个问题,y<1>前没有更早的输入,此时一般用0来初始化a<0>。
但是这个RNN网络也有缺点,只考虑了之前序列的输入,而没有考虑到之后的输入。对此可以用双向RNN解决(Bi-RNN)。
需要注意的是图中的这些权重是共享的,每一个时间步的Wax、Waa、Wya是相同的。

OK。我们继续看一看RNN是如何进行前向传播的。如下图所示。
公式图中已经给出,一般a<t>的激活函数为tanh或是relu,而y<t>的激活函数视情况而定,若是二分类自然sigmoid好,多分类softmax。

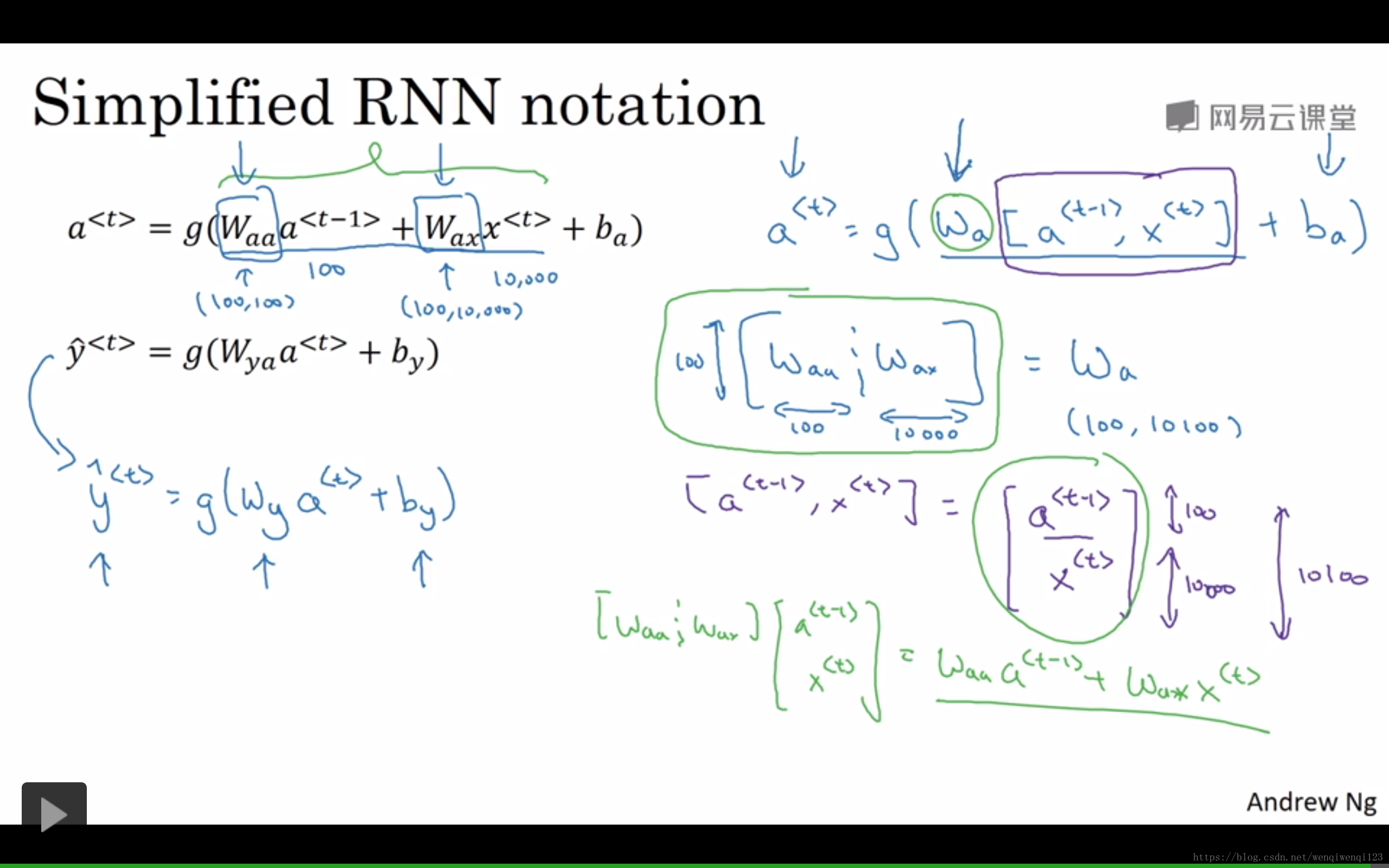
简化一下上图中的公式,如下图所示。将Waa和Wax堆叠起来成为Wa,并将a<t-1>和x<t>也堆叠起来,结果不变。
以上就是基本的循环神经网络,接下来我们看看它如何进行反向传播并学习。
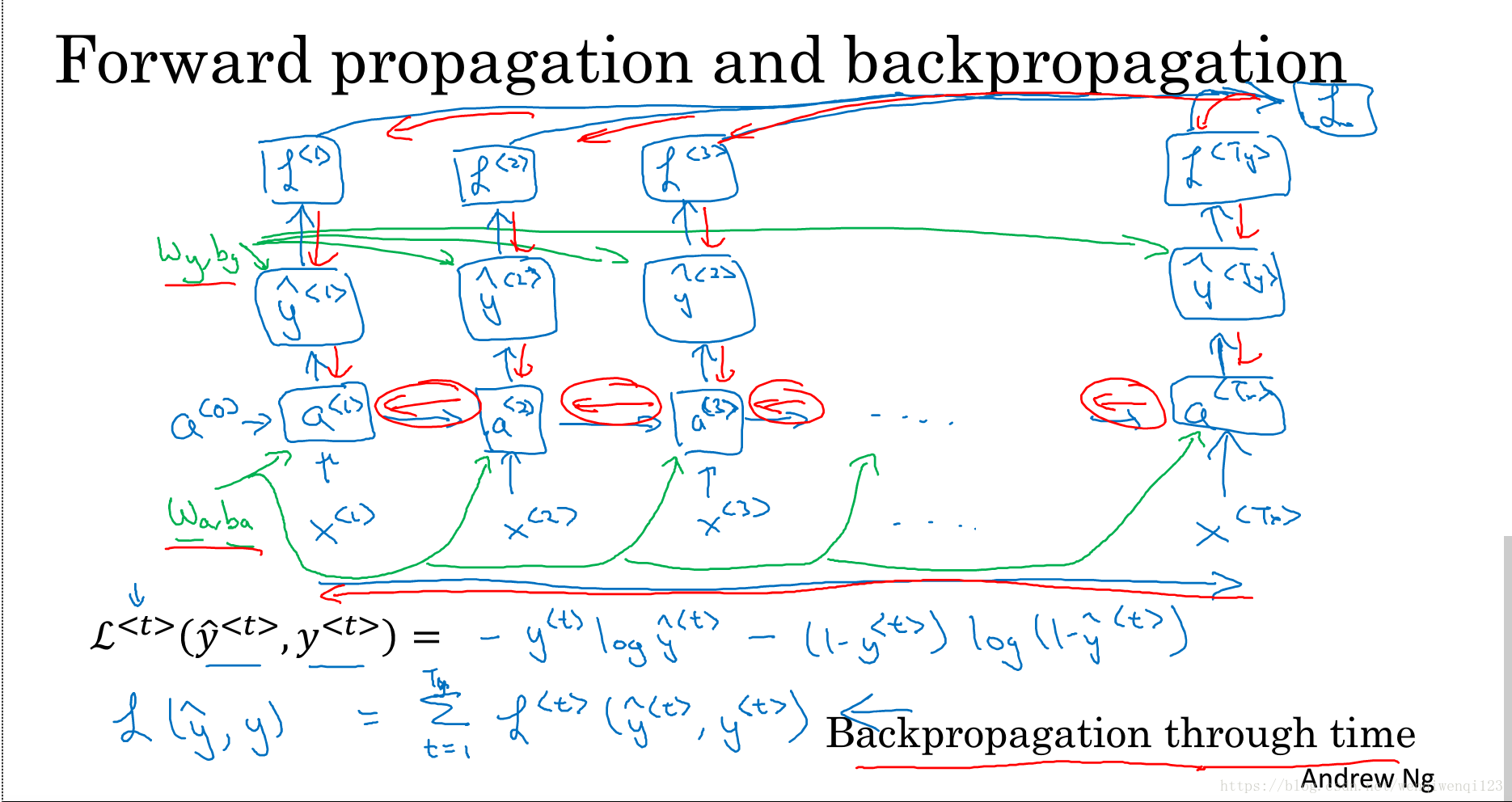
如下图所示,假设损失函数为交叉熵,在所有前向传播中进行反向计算,并计算梯度,使用梯度下降等算法来更新权重。
当然RNN的变种还有很多,如下图:

深层的RNN如下:

以上就是RNN的基本模型,关于GRU和LSTM之后会讲。