文章目录
1 RNN第一部分
1.1 概念和工具介绍
tokenization 就是通常所说的分词,分出的每一个词语我们称之为token。
常用的分词工具有很多:
jieba分词: https://github.com/fxsjy/jieba
分词方法:
1.转换为单个字
2.转换为单词
例如:我爱深度学习
(1) 我,爱,深度学习
(2)我, 爱,深,度,学,习
1.2 N-garm表示方法
- 在终端(terminal)
pip install jieba
- 写代码
import jieba
text = "深度学习,(英文:DeepLearning),是机器学习的分支," \
"是一种以人工神经网络为架构的,对数据进行表征学习的算法."
cuted =jieba.lcut(text)
print(cuted)
print(len(cuted))
[print(i, cuted[i:i+2]) for i in range(len(cuted)-1)]
2 文本转换为向量
2.1 one-hot
使用稀疏的向量表示文本,占用空间多,一般不用
2.2 word embedding
a. 使用稠密的浮点型矩阵来表示token
解释:每一个词用一个向量表示,长度可以是100,256,300 等等,由用户指定。
其中,向量中的每一个数据都是随机生成的,之后会在训练的过程中进行学习而获得的。
那么一个句子比如说分为了30个词,每个词用一个256d向量表示,那么这个句子就是30*256 的稠密矩阵。
2.3 word embedding API
参数介绍:
(1)num_embeddings : 词典的大小
(2)embedding_dim : embedding 的维度
embedding = nn.Embedding(vocab_size, 300) # 实例化
input_embeded = embedding(input) # 进行embedding的操作
2.4 数据的形状变化
[batch_size , seq_len] => [batch_size, seq_len, seq_dim]

【我也不是很清楚20是什么…应该是vocab_size,总而言之4 的意思就是每个词语用4d的向量来表示就是了,所以最后的维度应该是 batch_size * seq_len * seq_dim】
3 举例:文本情感分类
3.1 数据集
采用的是一个简单的数据集:IMDB
http://ai.stanford.edu/~amaas/data/sentiment/

train集 25000条,pos标签12500条;
test 集 25000条,neg标签12500条。
注意:
这里的标签的是打在文件名上的。
名称 = 序号+标签(label)
其中1-4是neg评论,5-10是pos评论。
txt其中的是文本内容。
- /train/neg 目录下:
3.2 思路分析
- 准备数据集
- 构建模型
- 模型训练
- 模型评估
3.3 准备数据集

第一步:实例化Dataset
第二步:准备DataLoader
- 注意:
(1)每个batch 中的文本长度不一致
(2)每个batch的文本如何转换为数字序列
import torch
from torch.utils.data import DataLoader, Dataset
import os
class ImdbDataset(Dataset):
def __init__(self, train=True):
self.train_data_path = r"E:\study_self\LearnPytorch\dataset\sentiment\aclImdb\train"
self.test_data_path = r"E:\study_self\LearnPytorch\dataset\sentiment\aclImdb\test"
data_path = self.train_data_path if train else self.test_data_path
# 把所有的文件名放入列表
temp_data_path = [os.path.join(data_path, "pos"), os.path.join(data_path, "neg")]
self.total_file_path = [] # 所有的评论的文件的path
for path in temp_data_path:
file_name_list = os.listdir(path)
file_path_list = [os.path.join(path, i) for i in file_name_list]
self.total_file_path.extend(file_path_list)
- 注意
__init__函数,其中的self.train_data_path = r"E:\study_self\LearnPytorch\dataset\sentiment\aclImdb\train"r+路径 就表示对后面的字符串当做文本处理,( 也就不需要在写路径的时候注意转义字符的问题啦!!)
- 如果
train=True就加载训练集,如果是False就加载测试集。
data_path = self.train_data_path if train else self.test_data_path
- 需要把所有的文件名读入列表
函数:os.path.join()
函数用于路径拼接文件路径,可以传入多个路径
自动补\,可以传入多个路径,用,隔开
if __name__ == "__main__":
train_data_path = r"E:\study_self\LearnPytorch\dataset\sentiment\aclImdb\train"
temp_data_path = os.path.join(train_data_path, "pos")
print(temp_data_path)
temp_data_path = os.path.join(train_data_path, "pos", "neg", "aaa")
print(temp_data_path)
输出:
E:\study_self\LearnPytorch\dataset\sentiment\aclImdb\train\pos
E:\study_self\LearnPytorch\dataset\sentiment\aclImdb\train\pos\neg\aaa
os.listdir(path)中有一个参数,就是传入相应的路径,将会返回那个目录下的所有文件名。
file_name_list = os.listdir(path)
# path = E:\study_self\LearnPytorch\dataset\sentiment\aclImdb\train\pos
返回所有的文件名,添加到列表。
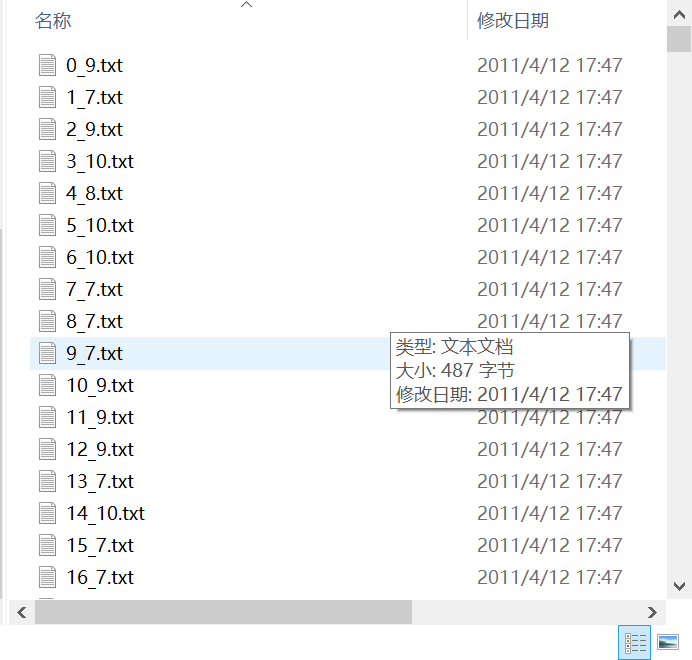
- 文件夹下的txt文件一共是12500个,这里是pycharm的打印结果,pycharm打印就是会截断一部分,比如说这里从 0_9.txt 直接跳到了 10000_8.txt ,理解一下就好。
- 根据刚刚得到的所有文件名,然后再进行拼接,最终得到每一条评论的绝对路径、
for path in temp_data_path:
print(path)
file_name_list = os.listdir(path) # 12500条
# print(file_name_list)
file_path_list = [os.path.join(path, i) for i in file_name_list]
print(file_name_list)
self.total_file_path.extend(file_path_list)
exit()
3.4 综上代码
from torch.utils.data import DataLoader, Dataset
import os
class ImdbDataset(Dataset):
def __init__(self, train=True):
self.train_data_path = r"E:\study_self\LearnPytorch\dataset\sentiment\aclImdb\train"
self.test_data_path = r"E:\study_self\LearnPytorch\dataset\sentiment\aclImdb\test"
data_path = self.train_data_path if train else self.test_data_path
# 把所有的文件名放入列表
temp_data_path = [os.path.join(data_path, "pos"), os.path.join(data_path, "neg")] # 两个值,一个是pos的路径,一个是neg的路径
self.total_file_path = [] # 所有的评论的文件的path
for path in temp_data_path:
print(path)
file_name_list = os.listdir(path) # 12500条
# print(file_name_list)
file_path_list = [os.path.join(path, i) for i in file_name_list]
print(file_name_list)
self.total_file_path.extend(file_path_list)
3.5 分词操作
- 在分词之前,需要对文本数据进行清洗。
- 如下是0_2.txt 文件内容,可以看出这里是没有什么奇奇怪怪的数字或者符号的,但是其他本文中存在一些奇怪符号,所以要进行数据清洗。(换行是我手动加的,方便阅读,原数据是一行。)
Once again Mr. Costner has dragged out a movie for far longer than necessary.
Aside from the terrific sea rescue sequences,
of which there are very few I just did not care about any of the characters.
Most of us have ghosts in the closet, and Costner's character are realized early on,
and then forgotten until much later,
by which time I did not care. The character we should really care about is a very cocky, overconfident Ashton Kutcher.
The problem is he comes off as kid who thinks he's better than anyone else
around him and shows no signs of a cluttered closet. His only obstacle
appears to be winning over Costner. Finally when we are well past the half
way point of this stinker, Costner tells us all about Kutcher's ghosts.
We are told why Kutcher is driven to be the best with no prior inkling
or foreshadowing. No magic here,
it was all I could do to keep from turning it off an hour in.
- 原作者给出的代码如下:

这个代码的意思很直接,就是去除原文中的特殊符号,比如是* \t ? # $ % & 等等,将这些全部替换为空格。
然后再调用 content.split() 进行分词,然后对每个分词 i.strip() 去除首位空格。
得到的结果是这样的:

原作者老师也提到了这些可以改进的地方,比如说's 和每句话最后单词的句点。这些都是代码可以再优化的地方。
这里放上的我自己的思路:(可能有些简单粗暴了..)
对于每个文本内容content,我们可以用:
content = re.sub(r'[^A-Za-z ]+', '', content)
content = re.sub(r'[ ]+', ' ', content)
意思就是将除了字母外的所有内容都替换为空格。也就是说,只保留字母。
- 如下面代码所示:
seq = r'Huh??? This character also uses tears to manipulate her former lover into staying, and coaxes him into sexually oriented behavior (which she initially denies as a motive) all the while assuring him "this isn\'t sex."'
seq = re.sub(r'[^A-Za-z]', ' ', seq)
print(seq)
输出:
Huh This character also uses tears to manipulate her former lover into staying and coaxes him into sexually oriented behavior which she initially denies as a motive all the while assuring him this isn t sex
【可以看到,除了字母外的所有内容都被替换为空格包括一些's 've 等等缩写,这也是需要优化的地方】
- 在分词的时候,注意去除两边的空格。
tokens = [i.strip() for i in seq.split()]
print(tokens)
输出:
['Huh', 'This', 'character', 'also', 'uses', 'tears', 'to', 'manipulate', 'her', 'former', 'lover', 'into', 'staying', 'and', 'coaxes', 'him', 'into', 'sexually', 'oriented', 'behavior', 'which', 'she', 'initially', 'denies', 'as', 'a', 'motive', 'all', 'the', 'while', 'assuring', 'him', 'this', 'isn', 't', 'sex']
- OK,所以我的
tokenlize就很简单了:
def tokenlize(content):
content = re.sub(r'[^A-Za-z]', ' ', content) # 只保留字母
tokens = [i.strip() for i in content.split()] # 分词,去除空格
return tokens
3.6 DataLoader中collate_fn异常返回
- 问题:将两条评论文本zip,第一个()内是第一条评论的第一个单词,和第二条评论的第一个单词。
- 而我们需要的是第一条评论的全部单词在前,第二条评论的全部单词在后。

- 因此,采用下面的代码对
collate_fn函数重写
def collate_fn(batch):
content, label = list(zip(*batch))
return content, label
- 输出结果如下:(两条评论的内容我把中间的删去了,为了方便阅读)
0
(
['This', 'is', 'a', 'years', 'Even', 'Hollywood', 'Ending', 'had', 'a', 'great', 'central', 'idea', 'Sadly', 'his', 'inspiration', 'has', 'deserted', 'him', 'this', 'time'],
['I', 'saw', 'this', 'movie', 'twice', 'specializing', 'in', 'childhood', 'trauma'])
(0, 0)
3.7 综上完整代码
import torch
from torch.utils.data import DataLoader, Dataset
import os
import re
def tokenlize(content):
content = re.sub(r'[^A-Za-z]', ' ', content)
tokens = [i.strip() for i in content.split()]
return tokens
def collate_fn(batch):
content, label = list(zip(*batch))
return content, label
class ImdbDataset(Dataset):
def __init__(self, train=True):
self.train_data_path = r"E:\study_self\LearnPytorch\dataset\sentiment\aclImdb\train"
self.test_data_path = r"E:\study_self\LearnPytorch\dataset\sentiment\aclImdb\test"
data_path = self.train_data_path if train else self.test_data_path
# 把所有的文件名放入列表
temp_data_path = [os.path.join(data_path, "pos"), os.path.join(data_path, "neg")] # 两个值,一个是pos的路径,一个是neg的路径
self.total_file_path = [] # 所有的评论的文件的path
for path in temp_data_path:
# print(path)
file_name_list = os.listdir(path) # 12500条
# print(file_name_list)
file_path_list = [os.path.join(path, i) for i in file_name_list]
# print(file_name_list)
self.total_file_path.extend(file_path_list)
def __getitem__(self, index):
file_path = self.total_file_path[index]
# 获取label
label_str = file_path.split("\\")[-2]
label = 0 if label_str == "neg" else 1
# 获取内容
tokens = tokenlize(open(file_path).read())
return tokens, label
def __len__(self):
return len(self.total_file_path)
def get_dataloader(train=True):
imdb_dataset = ImdbDataset(train)
data_loader = DataLoader(imdb_dataset, batch_size=2, shuffle=True, collate_fn=collate_fn)
return data_loader
if __name__ == "__main__":
for idx, (input, target) in enumerate(get_dataloader()):
print(idx)
print(input)
print(target)
break