版权声明:本文为博主[email protected](阿King)原创文章,不得以任何理由任何形式进行转载 https://blog.csdn.net/lj501886285/article/details/84306434
动机:
目前的视频传输方法存在两大缺陷:
- 没有充分的利用客户端的计算力:客户端的计算力在逐年上升

- 当前视频编码能力受限制
很多视频在较大的时间区域内存在较大的信息冗余,而目前的视频编码只能减少小时间范围(GOP)内的信息冗余
目标:
提出一个新的视频传输架构,以低分辨率视频作为传输,在客户端通过DNN来提高视频的分辨率以达到高分辨率的效果。
系统设计
服务端
当视频上传时,服务器为其训练content-aware DNNs,用于提升客户端的视频质量
客户端
- 首先下载一个可用DNN文件列表(manifest list)

- 根据自身的计算力选择一个合适的DNN(一个轻量级的客户端处理器)
- 根据integrated adaptive bitrate (ABR) algorithm去下载相应DNN chunks和video chunks
- DNN chunks加载到DNN processor中
- video chunks加载到playback buffer中,准备播放
- 播放器同时将video chunks也放到DNN processor中去进行super-resolution,处理结束后放回playback buffer中替换原始video chunks
- 高分辨率的video被播放
对于DNN processor
- 将video chunks解码成frames
- 对每一个frame应用super-resolution
- 重新编码成video chunks
解码,super-resolution,编码 三个操作流水并行化处理,减少延迟
阿King说:1和3的编解码过程是否可以通过调整架构去掉?
Content-aware DNN
NAS是基于MDSR的拓展
要求
- DNN必须满足多分辨率输入
- DNN的计算时间必须能够满足实时的要求
- 为了满足前两条要求,DNN必须牺牲一些质量(layers和每个layer的通道数)来减少计算开销,这需要我们均衡DNN的品质和计算开销
MDSR的缺点
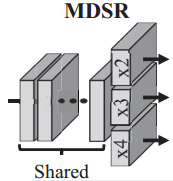
- MDSR通过一个简单的网络支持多分辨率输入,并通过共享中间层来减少连接
- 不同的分辨率对MDSR的计算开销影响非常大(高分辨率计算开销大,对分辨率计算开销小),为了满足高分辨率的实时要求,必须减小DNN的规模
- 由于MDSR共享中间层,在降低高分辨率的DNN规模时,同样会影响低分辨率
提出
让每个分辨率的DNN独立开来

独立开来的各网络能够满足实时要求的最高配置如下表

参数为(层数layors , 通道数channels , 连接权值大小footprints size)
阿King说:各高低分辨率对之间的映射是否有共同点?即是否存在权值共享?例如是否能在240p-1080p中间抽取一部分权值即可实现720p-1080p的映射?一对一对的训练感觉好麻烦呀!!!
训练
- 训练数据:低分辨率-高分辨率 对(训练DNN实际就是构造低分辨率到高分辨率的映射)
- 训练目标:使得 DNN的输入出 和 目标高分辨率 之间的差异最小化
- 为了减少训练开销,使用微调(fine-tunning)策略
- 先训练一个通用的DNN模型
- 再在通用DNN模型权值的基础上为每个video episode训练Content-aware DNN模型
根据计算力适应性选择DNN
服务端
提供四种DNN:Low,Medium,High,Ultra-high
客户端
- 在提供的DNN文件列表中获取四种DNN网络信息(layors , channels)
- 根据DNN网络信息以随机权值初始化四种DNN
- 在四种初始化的DNN中选择能够满足实时要求的最高品质的那个DNN
阿King说:当然不能把四种DNN都先下载下来,再计算最优,再选择,这样太慢了!!!
可扩展的DNN

服务端
- 完整的DNN较大,不可能全部下载下载后再去使用,可让客户端边下边播,已下载的DNN部分也可用于视频的质量提升,随着DNN的下载越来越完全,视频的质量提升的也越来越高
- DNN的中间层由许多残差块(residual blocks)组成,每一个残差块都包含两个卷积层,DNN计算运行的时候可以绕过连续的残差块
- 在训练的时候:
- 我们以50%的概率训练完整的DNN,另外50%的概率平均随机选择绕过路径(Bypassing paths)来训练DNN
- 计算DNN的输出与目标高分辨率之间的error,通过反向重传来更新权值
- 在传输的时候,将DNN分成许多块(chunks)来传输,第一个DNN块由基本层(base layers)组成,可接受多种分辨率的输入
客户端
- 下载第一个DNN块(base layers)后,构造起DNN
- 随着DNN块的下载越来越完全,DNN的构造也越来越完全,视频质量也越来越得到提升。
- DNN processor每个时间间隔(4s)会计算DNN的处理时间,计算满足实时要求的最大可用DNN层数
ABR算法
作用
- 决定是取DNN chunk还是取video chunk
- DNN优先策略则会牺牲视频流的质量
- 视频流优先策略则会延迟DNN的下载
- 如果第一次决定是取视频块,则改为取DNN块
阿King说:尼玛为毛不一开始就规定先下载那个带有base layor的DNN chunks,还要用算法取决定干嘛?决定错了还有修正回来???
采用A3C的增强学习框架RL
- 对于算法迭代次数 ,有针对来自环境的状态 做出相应的反应 ,随后环境产生回报 同时更新状态为
- 策略:定义一个函数,该函数计算对于状态
做出动作
的概率
。其中
包含是下载DNN chunks还是下载video chunks?
包含的内容如下表:(N=8)

- 目标:学习这个策略
,使得未来的回报总和
最大,其中表示
回报系数,
为目标QoE的度量,定义如下
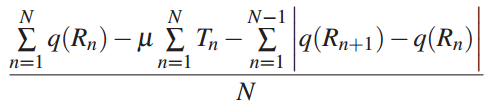
N是video chunks的数量
表示第N块video chunk下载的比特率
表示第N块video chunk下载后的rebuffering时间
表示rebuffering的惩罚
表示接受的比特率 的质量 - 为了表示在使用DNN后视频质量的提升,我们定义一个
来替代
,即对每一个video
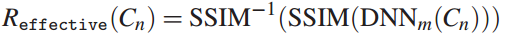
表示video chunk 在下载DNN chunk 后的提升的质量
是平均结构相似性(average structural similarity),用来视频的质量
将SSIM值由映射回视频比特率了 - 训练增强学习框架(RL framework)
- 两个参数:actor和critic, actor表示策略,critic用于评估策略actor
- 使用策略梯度法(policy gradient method)去训练actor和critic
例子

- player先下载一个manifest file
- DNN processor根据manifest file开始模拟四种DNN的开销,并选择一个可满足实时要求的最优DNN;同时player持续下载video chunks,下载了video chunk1-7
- DNN processor做出决定后开始下载DNN chunk1,该chunk中为DNN base layers
- video chunk1-5已经被播放,于是buffer中的chunk6-7使用已下载的部分DNN进行品质提升,效果为 DNN,此时为24sec
- 随后下载video chunk8-9和DNN chunk2
- 。。。
- 在32sec时达到 DNN
- 在44sec时达到 DNN
- 在52sec时达到 DNN
- 在60sec时达到full DNN
