1.人体姿态估计概述
人体姿态估计的概念
从给定的图像中识别人脸、手部、身体等关键点
输入:图像
输出:所有关键点的像素坐标

下游任务:
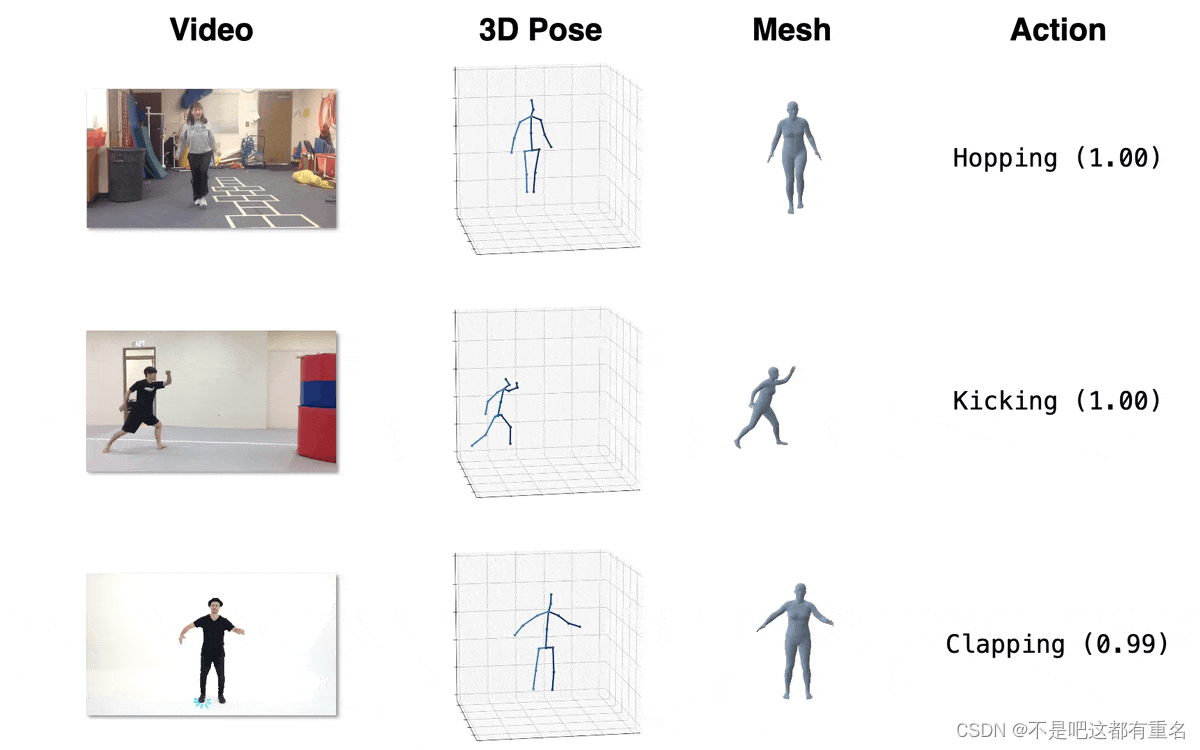
行为识别:
PoseC3D:基于人体姿态识别行为动作
CG、动画:

人机交互:
动物行为分析:

2.2D姿态估计
2D人体姿态估计的任务描述:在图像上定位人体关键点的坐标
2.1 实现的两种基本思路:
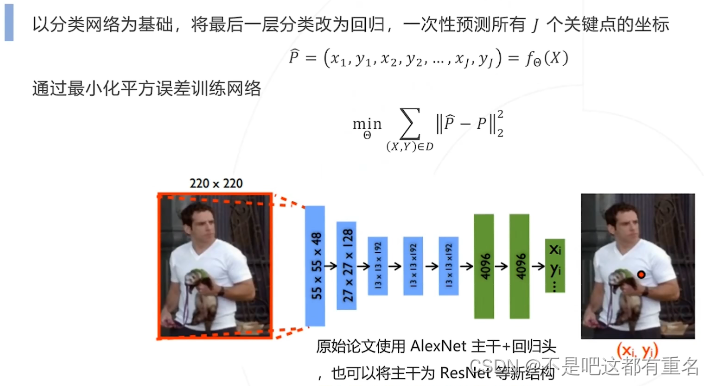
(1)基于回归(Regression Based)——将关键点检测问题建模成一个回归问题,让模型直接通过最后一层的线性回归预测关键点的坐标。
缺点:直接回归坐标有困难,精度不是最优。(历史经验)
(2)基于热力图(Heatmap Based)——预测关键点位于每个位置的概率
优点:模型预测热力图比直接回归坐标相对容易,模型精度相对更高(更符合神经网络的结构);
缺点:预测热力图的计算消耗大于直接回归(需要维护较大的信息,但已经有研究对这个问题改良)
基于热力图的方法的具体流程:
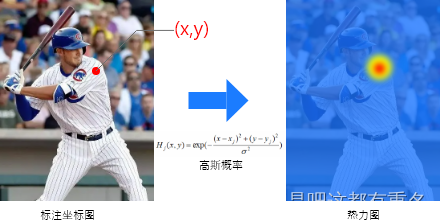
(1)从数据标注生成热力图,对于每个关键点都要通过如下图所示的过程。
(2)使用热力图训练模型
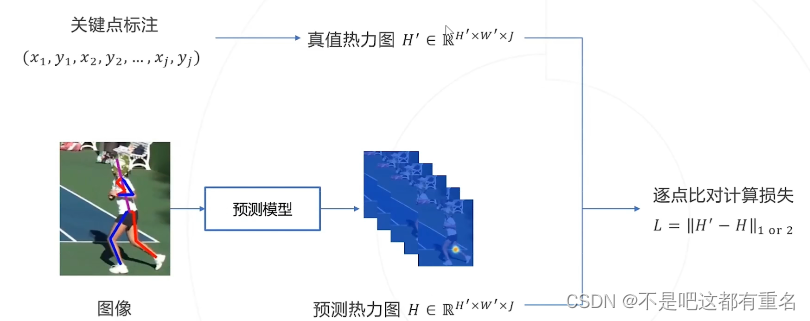
(3)从热力图还原关键点
从某个点的热力图中还原出关键点的坐标位置的方法:
朴素方法:求热力图最大值的位置
Integral Human Pose Regression:归一化热力图形成点位于不同位置的概率,再计算位置的期望
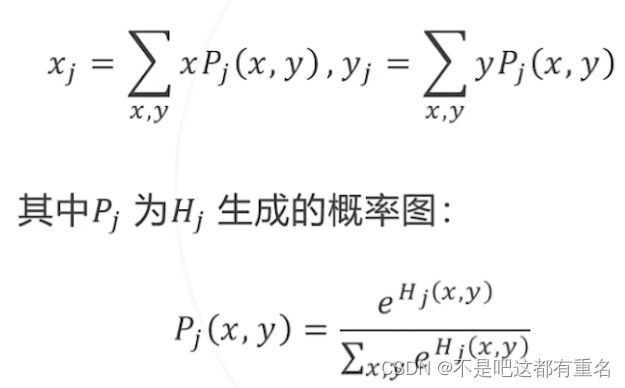
优点:可微分;连续,没有量化误差
2.2 实现方法
自顶向下方法(TopDown)
步骤:
Step 1.使用目标检测算法检测出每个人体
Step 2.基于单人图像估计每个人的姿态

缺点:
(1)整体的精度受限于检测器的精度
(2)速度和计算量会正比于人数
发展:
(1)一些新工作(如SPM)考虑将两个阶段聚合成一个阶段
自底向上方法(BottomUp)
步骤:
Step 1.使用关键点模型检测出所有人体关键点
Step 2.基于位置关系或其他辅助信息将关键点组合成不同的人

优点:
(1)推理速度与人数无关
单阶段方法
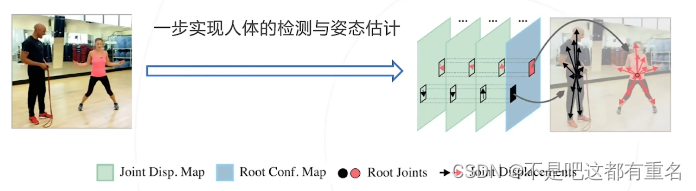
基于Transformer的方法
2.3 具体实现的论文
基于回归的自顶向下方法
-
DeepPose(2014)
通过级联提升精度
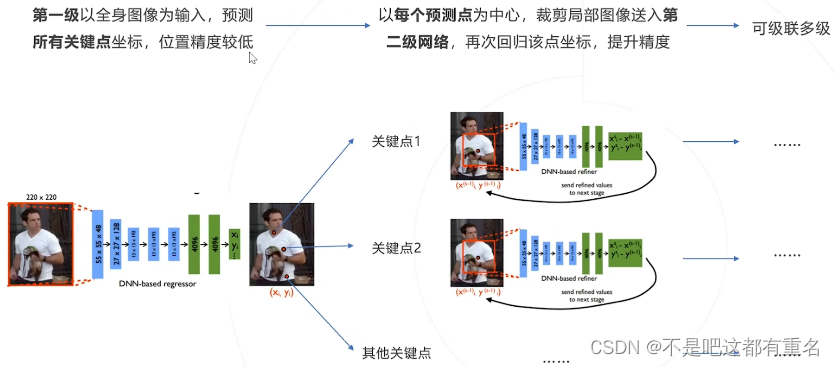
优点:
(1)回归模型理论上可以达到无限精度,热力图方法的精度受限于特征图的空间分辨率
(2)回归模型不需要维持高分辨率特征图,计算层面更高效,相比之下,热力图方法需要计算和存储高分辨率的热力图和特征图,计算成本更高。
缺点:
(1)图像到关键点坐标的映射高度非线性,导致回归坐标比回归热力图更难,回归方法的精度也弱于热力图方法 -
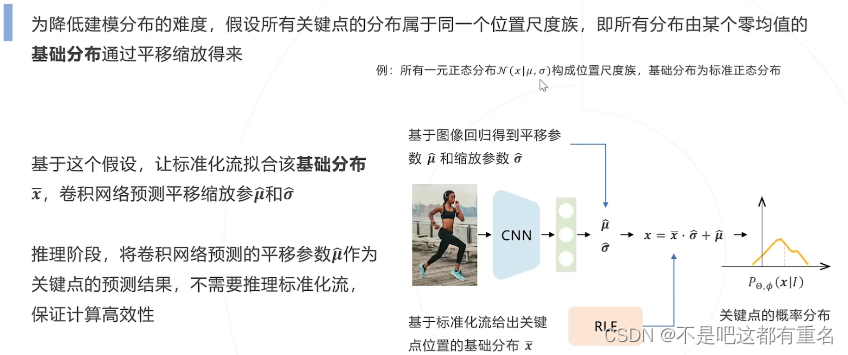
Residual Log-likelihood Estimation(RLE)(2021)
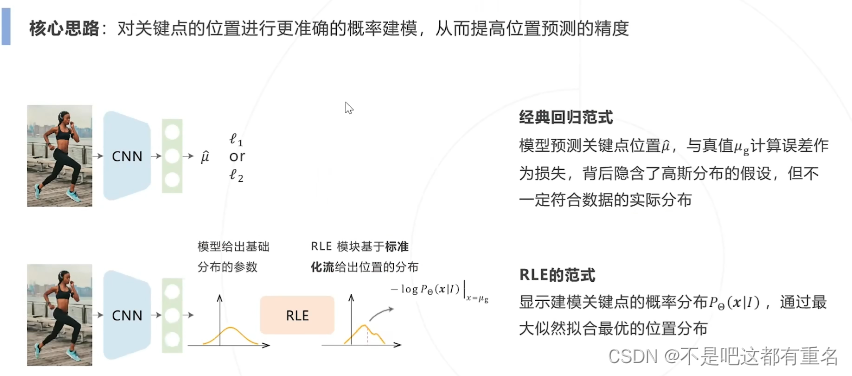
 重参数化设计
重参数化设计
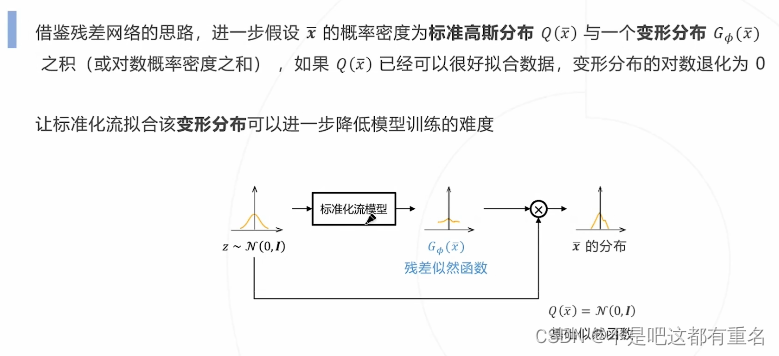
残差似然函数
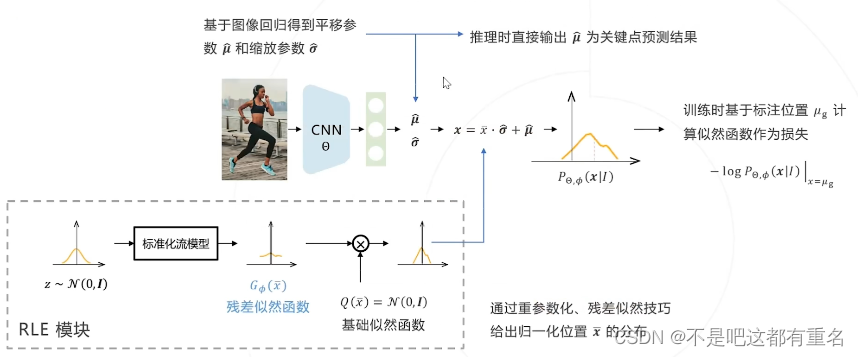
完整的RLE模型
补充背景知识:
1.回归和最大似然估计的联系

因此,二范数回归隐含了关键点位置符合固定方差的各向同性的高斯分布的假设
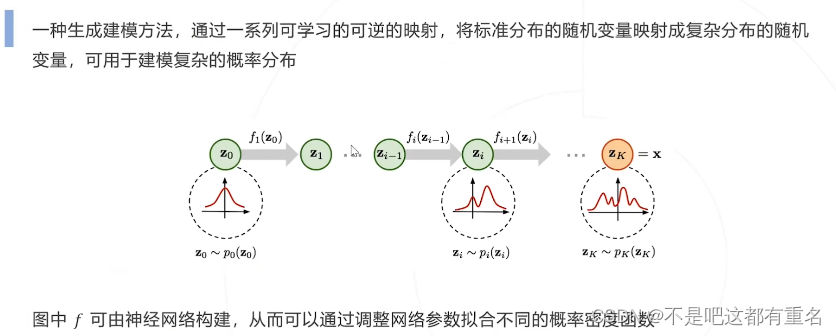
2.标准化流 Normalizing Flow
基于热力图的自顶向下方法
1.Hourglass(2016)——提出是达到SOTA,后逐渐被超过
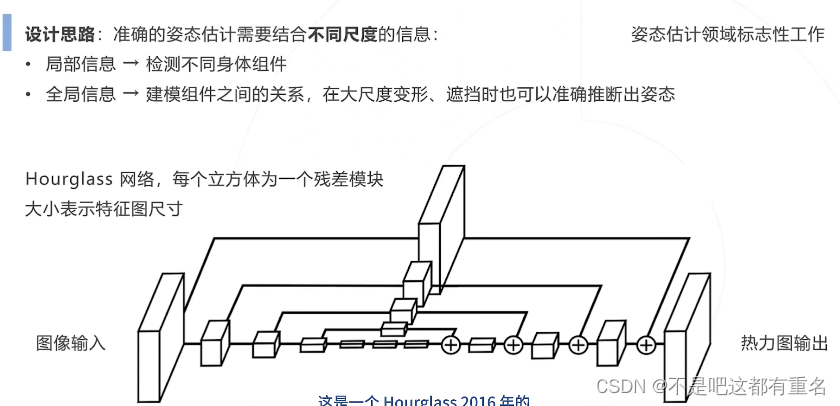
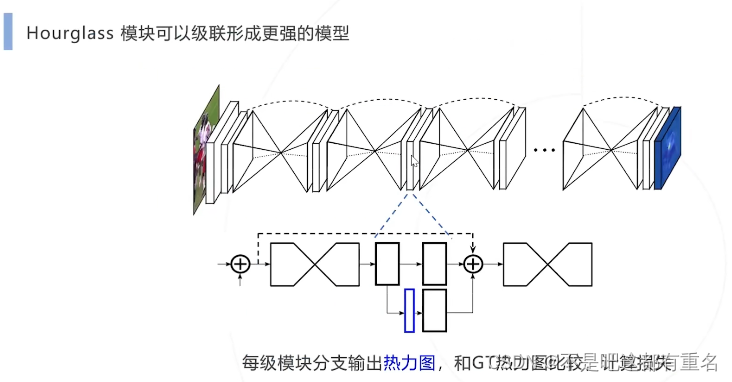
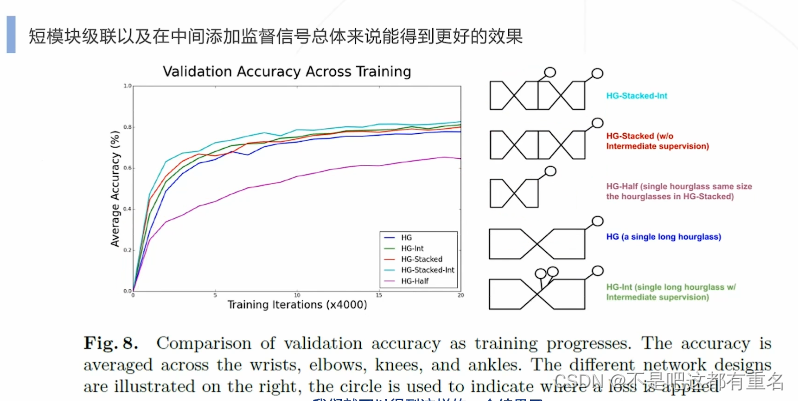
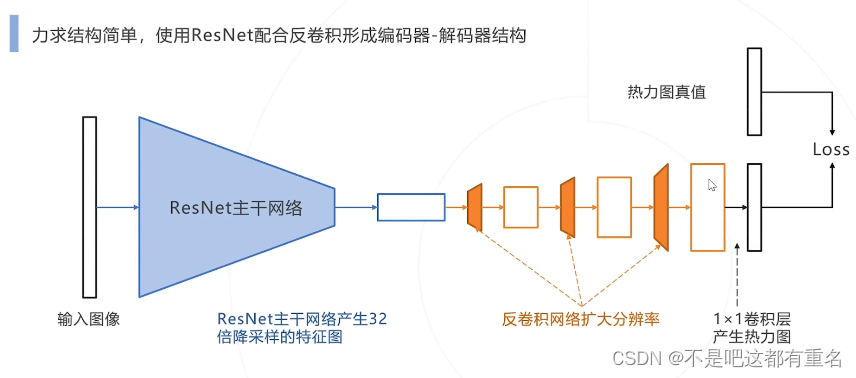
2.Simple Baseline(2018)——追求结构简单
3.HRNet(2020)
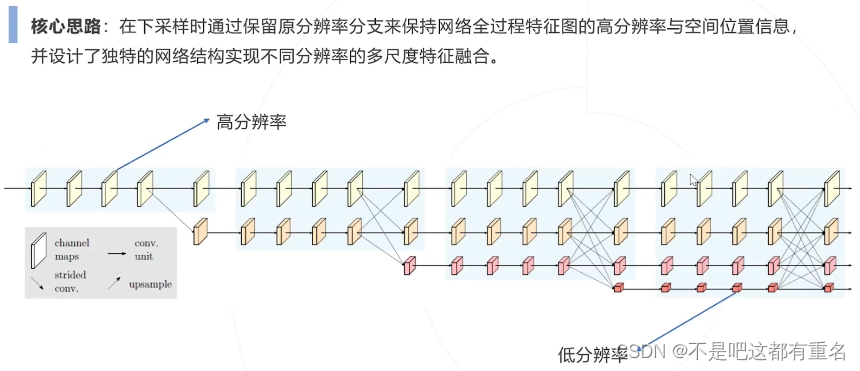
自底向上方法
1.Part Affinity Fields& OpenPose(2016)
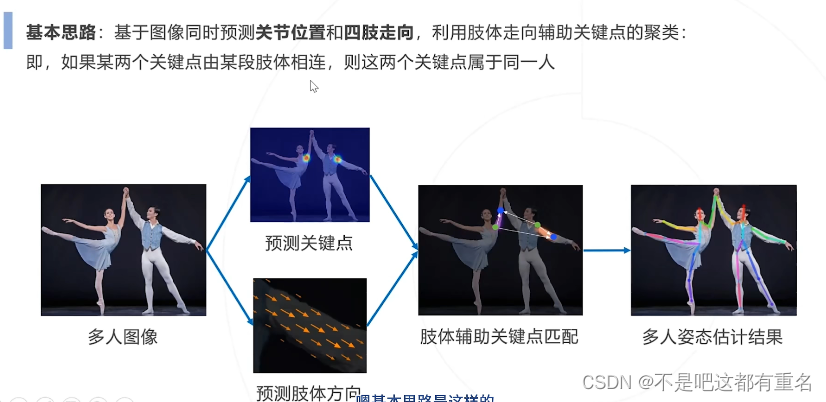
补充知识:
K部图匹配(待补充)
单阶段方法
1.SPM(2019)
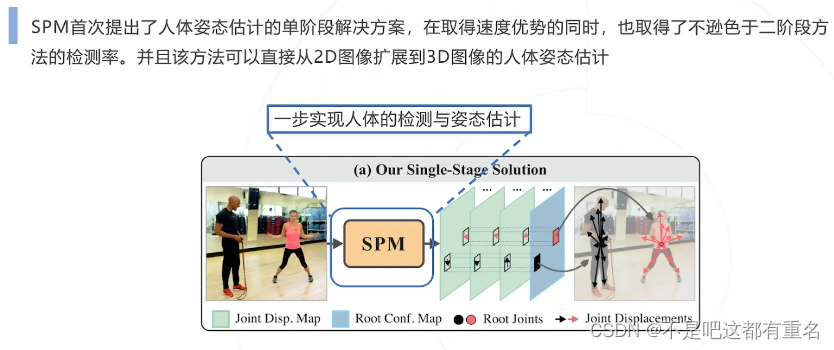
网络设计
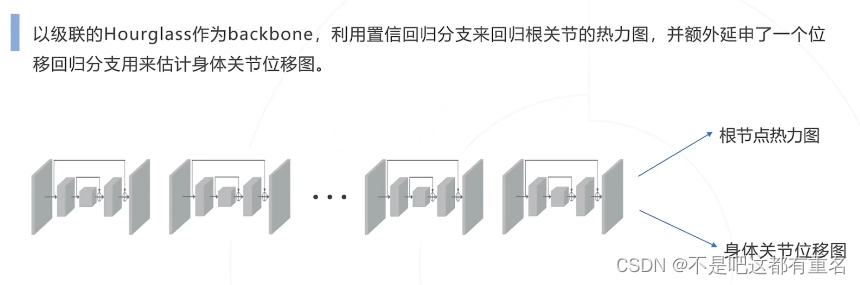
基于Transformer的方法
1.PRTR 2021
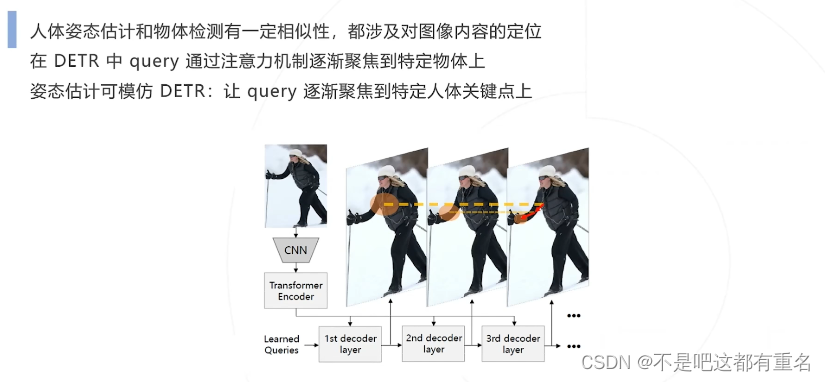
PRTR两阶段算法
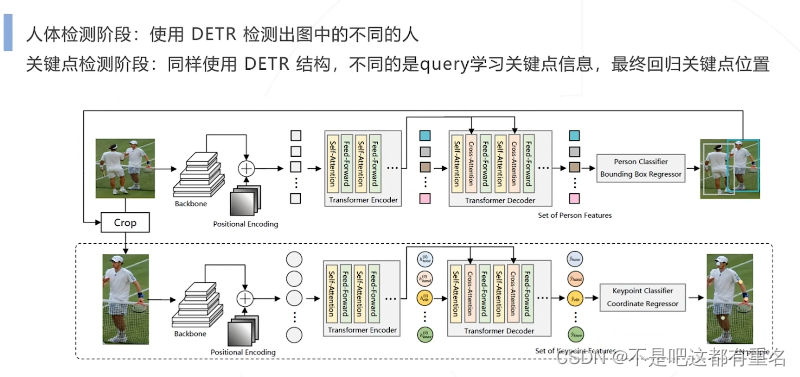
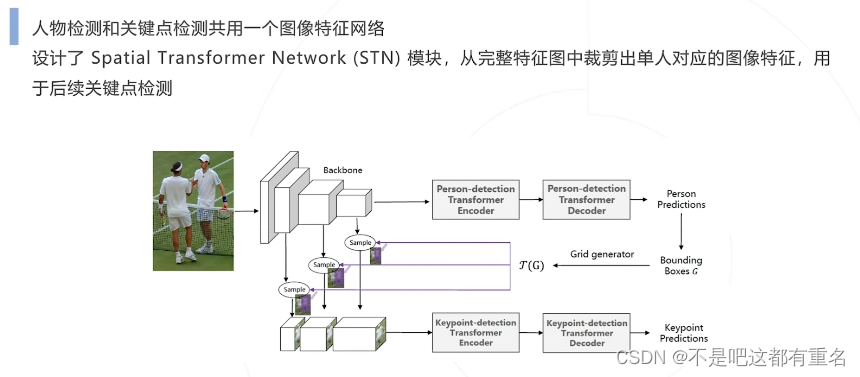
PRTR单阶段算法
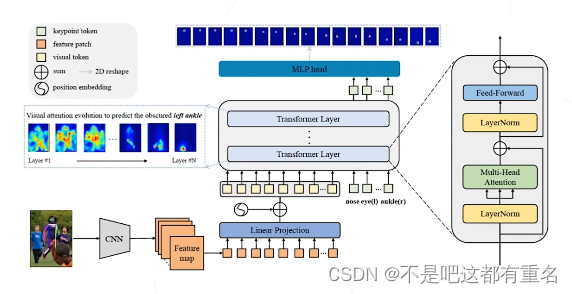
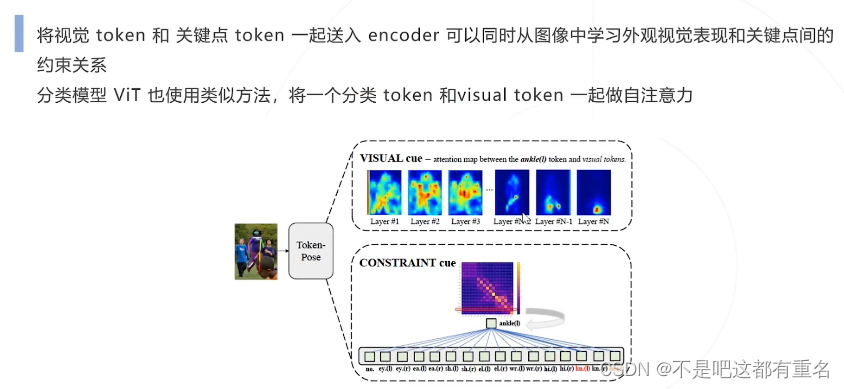
2.TokenPose(2021)
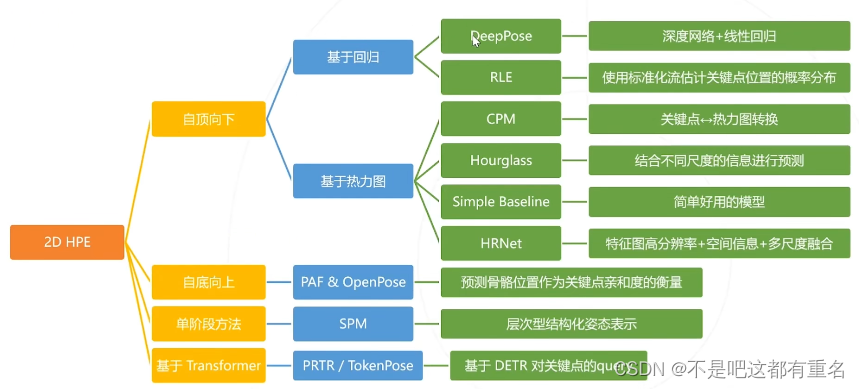
2D姿态估计小结
3.3D人体姿态估计
3.1 3D姿态估计的概念
通过给定的图像预测人体关键点在三维空间中的坐标,可以在三维空间中还原人体的姿态
输入:图像
输出:所有人的所有关键点的空间坐标
难点:从2D图像(或视频)恢复3D信息
3.2 实现思路
直接预测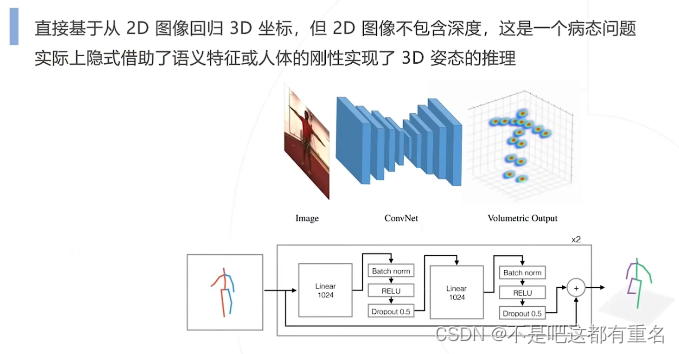
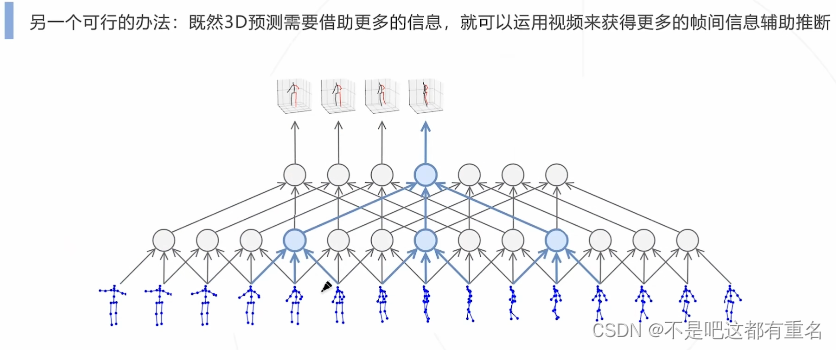
利用视频信息
利用多视角图像
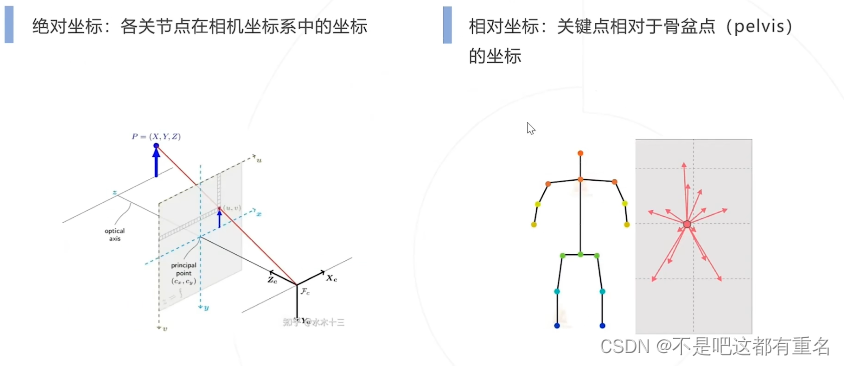
补充知识:
3.3 具体实现的论文
1.Coarse-to-Fine Volumetric Prediction 2017

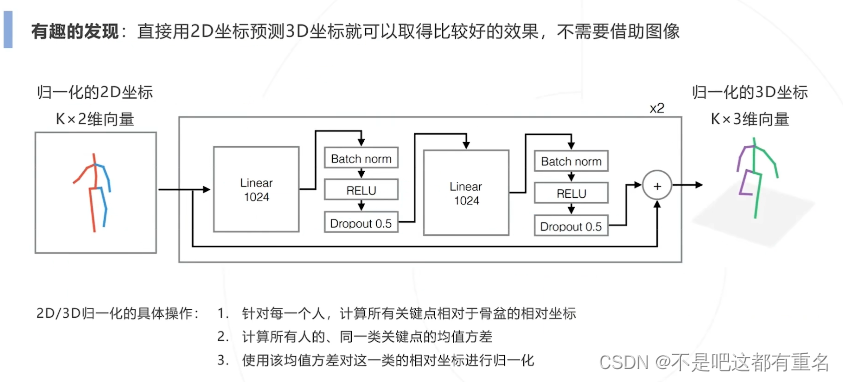
2.Simple Baseline 3D(2017)
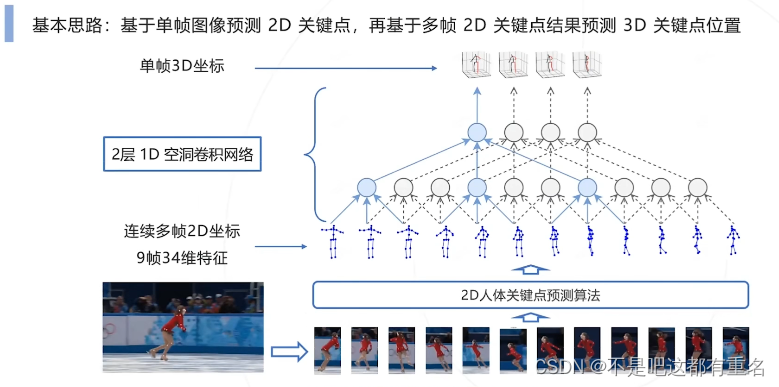
3.VideoPose3D(2018)
4.VoxelPose(2020)
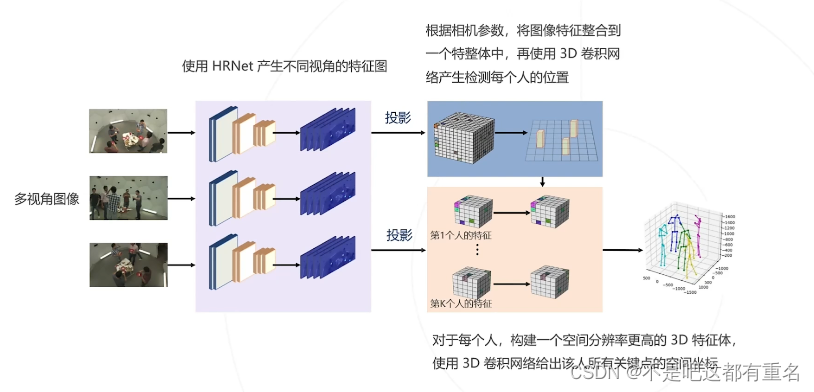
4.人体姿态估计的评估指标
(1)Percentage of Correct Parts(PCP)

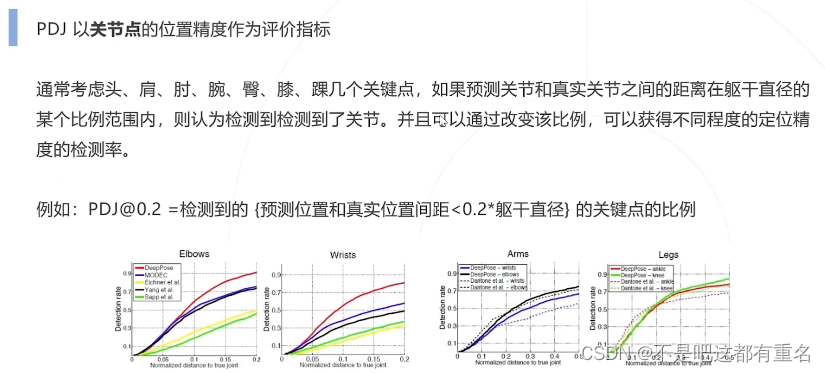
(2)Percentage of Detected Joints(PDJ)
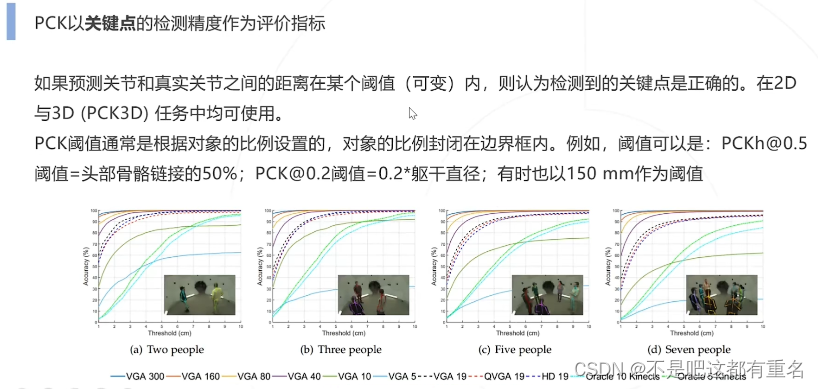
(3)Percentage of Correct Key-points(PCK)
(4)Object Keypoints Similarity(OKS) based mAP

5.DensePose
人体表面参数化
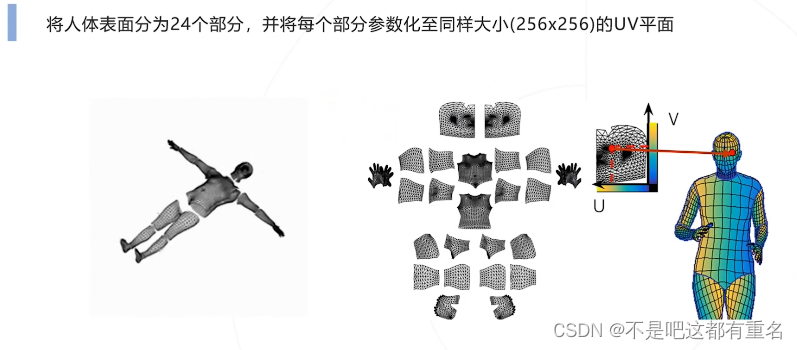
标注方法

网络结构
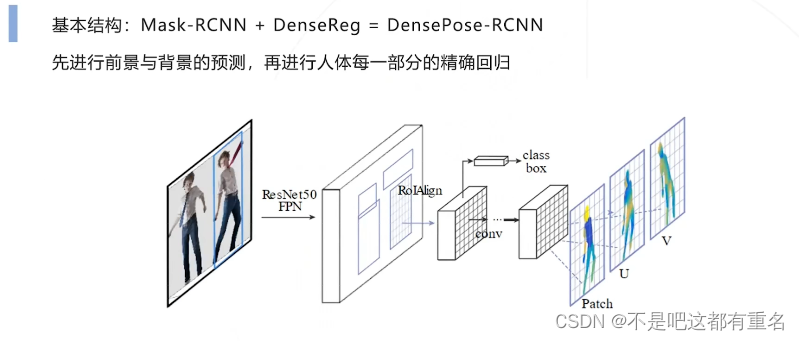
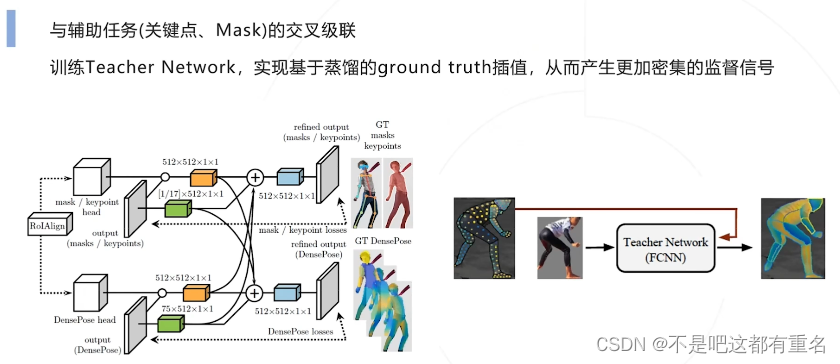
改进设计
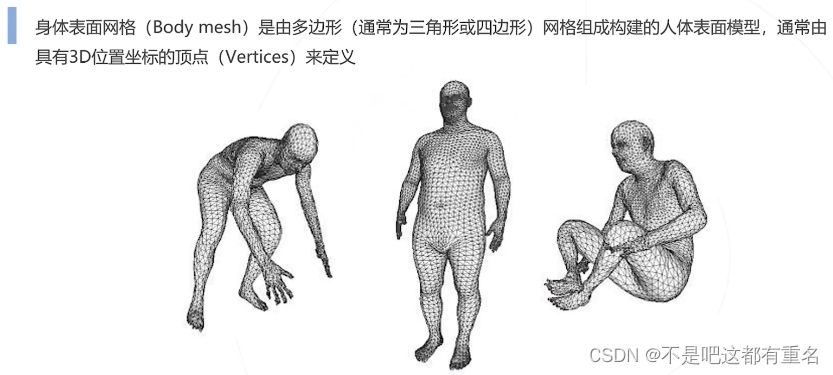
身体表面网格(Body Mesh)
混合蒙皮技术(Blend Skinning)
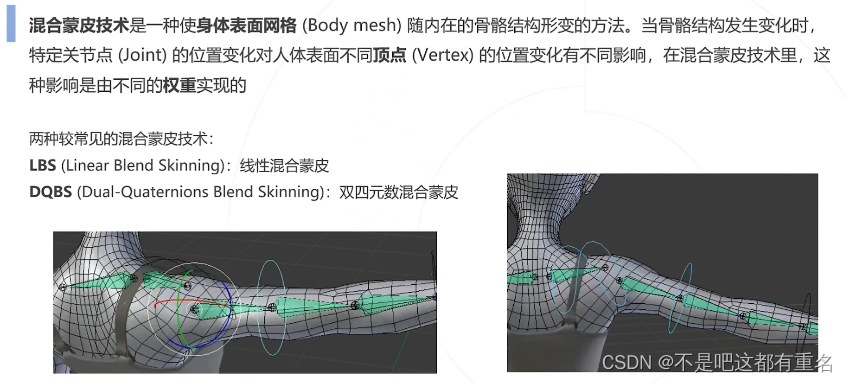
线性混合蒙皮LBS(Linear Blend Skinning)

6.人体参数化模型
SMPL人体参数化模型
从图像或者视频中恢复出运动的3D人体模型

SMPL的基本设计逻辑

SMPL人体模型表示
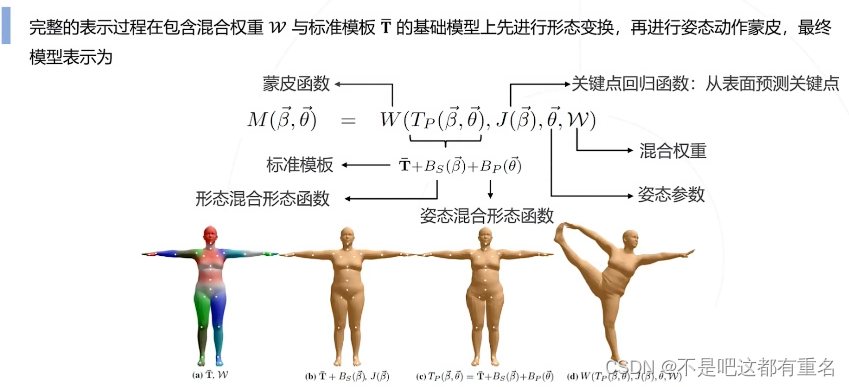
训练设计

SMPL模型的应用
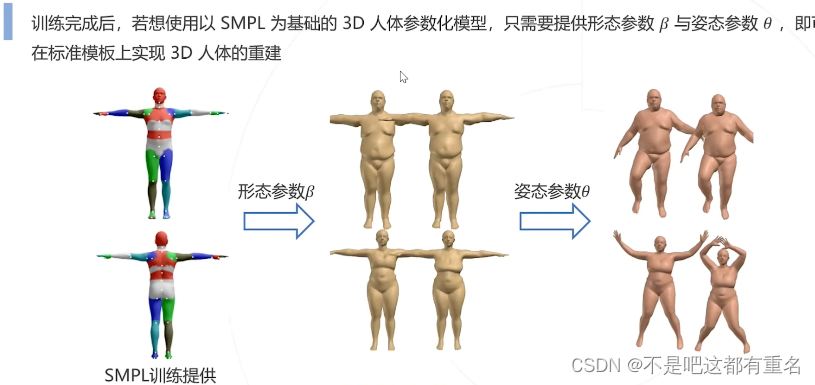
人体参数化模型
SMPL
SMPLify
HMR