0. 环境检测和安装
# 安装 mmengine 和 mmcv 依赖
# 为了防止后续版本变更导致的代码无法运行,暂时锁死版本
pip install -U "openmim==0.3.7"
mim install "mmengine==0.7.1"
mim install "mmcv==2.0.0"
# Install mmdetection
rm -rf mmdetection
# 为了防止后续更新导致的可能无法运行,特意新建了 tutorials 分支
git clone -b tutorials https://github.com/open-mmlab/mmdetection.git
cd mmdetection
pip install -e .
以下提供一个环境检查的小代码:
from mmengine.utils import get_git_hash
from mmengine.utils.dl_utils import collect_env as collect_base_env
import mmdet
# 环境信息收集和打印
def collect_env():
"""Collect the information of the running environments."""
env_info = collect_base_env()
env_info['MMDetection'] = f'{
mmdet.__version__}+{
get_git_hash()[:7]}'
return env_info
if __name__ == '__main__':
for name, val in collect_env().items():
print(f'{
name}: {
val}')
1.数据集准备和可视化
已经提供了一个猫的数据集,且已经划分了训练集和测试集
# 数据集下载
rm -rf cat_dataset*
wget https://download.openmmlab.com/mmyolo/data/cat_dataset.zip
unzip cat_dataset.zip -d cat_dataset && rm cat_dataset.zip
数据的可视化如下
# 数据集可视化
import os
import matplotlib.pyplot as plt
from PIL import Image
%matplotlib inline
%config InlineBackend.figure_format = 'retina'
original_images = []
images = []
texts = []
plt.figure(figsize=(16, 5))
image_paths= [filename for filename in os.listdir('cat_dataset/images')][:8]
for i,filename in enumerate(image_paths):
name = os.path.splitext(filename)[0]
image = Image.open('cat_dataset/images/'+filename).convert("RGB")
plt.subplot(2, 4, i+1)
plt.imshow(image)
plt.title(f"{
filename}")
plt.xticks([])
plt.yticks([])
plt.tight_layout()
该数据集的COCO json可视化如下所示
from pycocotools.coco import COCO
import numpy as np
import os.path as osp
from matplotlib.collections import PatchCollection
from matplotlib.patches import Polygon
def apply_exif_orientation(image):
_EXIF_ORIENT = 274
if not hasattr(image, 'getexif'):
return image
try:
exif = image.getexif()
except Exception:
exif = None
if exif is None:
return image
orientation = exif.get(_EXIF_ORIENT)
method = {
2: Image.FLIP_LEFT_RIGHT,
3: Image.ROTATE_180,
4: Image.FLIP_TOP_BOTTOM,
5: Image.TRANSPOSE,
6: Image.ROTATE_270,
7: Image.TRANSVERSE,
8: Image.ROTATE_90,
}.get(orientation)
if method is not None:
return image.transpose(method)
return image
def show_bbox_only(coco, anns, show_label_bbox=True, is_filling=True):
"""Show bounding box of annotations Only."""
if len(anns) == 0:
return
ax = plt.gca()
ax.set_autoscale_on(False)
image2color = dict()
for cat in coco.getCatIds():
image2color[cat] = (np.random.random((1, 3)) * 0.7 + 0.3).tolist()[0]
polygons = []
colors = []
for ann in anns:
color = image2color[ann['category_id']]
bbox_x, bbox_y, bbox_w, bbox_h = ann['bbox']
poly = [[bbox_x, bbox_y], [bbox_x, bbox_y + bbox_h],
[bbox_x + bbox_w, bbox_y + bbox_h], [bbox_x + bbox_w, bbox_y]]
polygons.append(Polygon(np.array(poly).reshape((4, 2))))
colors.append(color)
if show_label_bbox:
label_bbox = dict(facecolor=color)
else:
label_bbox = None
ax.text(
bbox_x,
bbox_y,
'%s' % (coco.loadCats(ann['category_id'])[0]['name']),
color='white',
bbox=label_bbox)
if is_filling:
p = PatchCollection(
polygons, facecolor=colors, linewidths=0, alpha=0.4)
ax.add_collection(p)
p = PatchCollection(
polygons, facecolor='none', edgecolors=colors, linewidths=2)
ax.add_collection(p)
coco = COCO('cat_dataset/annotations/test.json')
image_ids = coco.getImgIds()
np.random.shuffle(image_ids)
plt.figure(figsize=(16, 5))
# 只可视化 8 张图片
for i in range(8):
image_data = coco.loadImgs(image_ids[i])[0]
image_path = osp.join('cat_dataset/images/',image_data['file_name'])
annotation_ids = coco.getAnnIds(
imgIds=image_data['id'], catIds=[], iscrowd=0)
annotations = coco.loadAnns(annotation_ids)
ax = plt.subplot(2, 4, i+1)
image = Image.open(image_path).convert("RGB")
# 这行代码很关键,否则可能图片和标签对不上
image=apply_exif_orientation(image)
ax.imshow(image)
show_bbox_only(coco, annotations)
plt.title(f"{
filename}")
plt.xticks([])
plt.yticks([])
plt.tight_layout()
2.自定义配置文件
RTMDet
本教程采用 RTMDet 进行演示,在开始自定义配置文件前,先来了解下 RTMDet 算法。
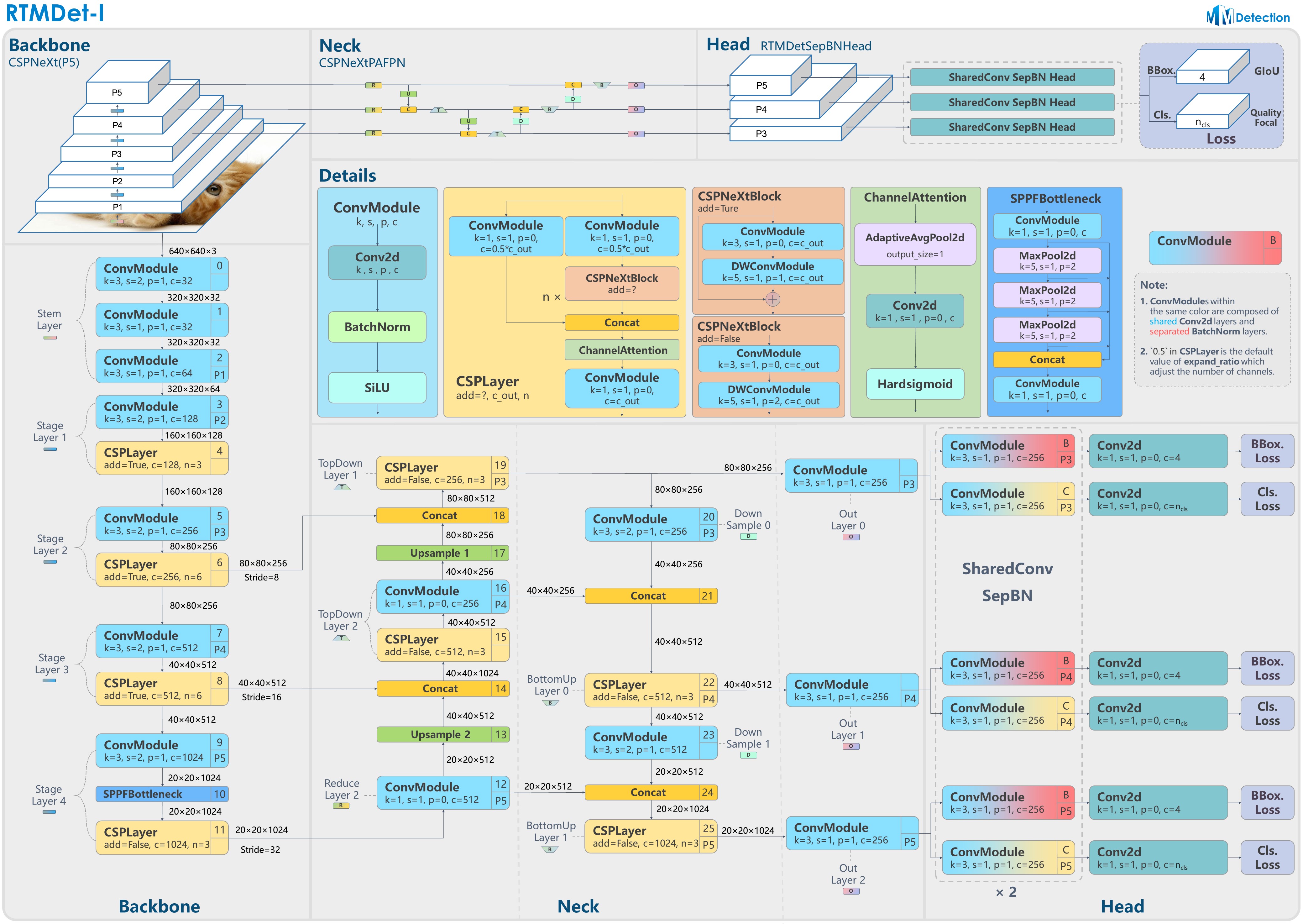
其模型架构图如上所示。RTMDet 是一个高性能低延时的检测算法,目前已经实现了目标检测、实例分割和旋转框检测任务。其简要描述为:为了获得更高效的模型架构,MMDetection 探索了一种具有骨干和 Neck 兼容容量的架构,由一个基本的构建块构成,其中包含大核深度卷积。MMDetection 进一步在动态标签分配中计算匹配成本时引入软标签,以提高准确性。结合更好的训练技巧,得到的目标检测器名为 RTMDet,在 NVIDIA 3090 GPU 上以超过 300 FPS 的速度实现了 52.8% 的 COCO AP,优于当前主流的工业检测器。RTMDet 在小/中/大/特大型模型尺寸中实现了最佳的参数-准确度权衡,适用于各种应用场景,并在实时实例分割和旋转对象检测方面取得了新的最先进性能。
自定义配置文件
目前使用的cat的数据集,是一个单类的数据集,相比MMdetection提供的coco的80类的配置需要进行一定的改动。
MMDetection3.0相比2.0的重要改动,添加了metainfo字段
metainfo = {
# 类别名,注意 classes 需要是一个 tuple,因此即使是单类,
# 你应该写成 `cat,` 很多初学者经常会在这犯错
'classes': ('cat',),#因为这里是个元组
'palette': [
(220, 20, 60),
]
}
具体的修改内容如下:
# 当前路径位于 mmdetection/tutorials, 配置将写到 mmdetection/tutorials 路径下
config_cat = """
_base_ = 'configs/rtmdet/rtmdet_tiny_8xb32-300e_coco.py'
data_root = 'cat_dataset/'
# 非常重要
metainfo = {
# 类别名,注意 classes 需要是一个 tuple,因此即使是单类,
# 你应该写成 `cat,` 很多初学者经常会在这犯错
'classes': ('cat',),
'palette': [
(220, 20, 60),
]
}
num_classes = 1
# 训练 40 epoch
max_epochs = 40
# 训练单卡 bs= 12
train_batch_size_per_gpu = 12
# 可以根据自己的电脑修改
train_num_workers = 4
# 验证集 batch size 为 1
val_batch_size_per_gpu = 1
val_num_workers = 2
# RTMDet 训练过程分成 2 个 stage,第二个 stage 会切换数据增强 pipeline
num_epochs_stage2 = 5
# batch 改变了,学习率也要跟着改变, 0.004 是 8卡x32 的学习率
base_lr = 12 * 0.004 / (32*8)
# 采用 COCO 预训练权重
load_from = 'https://download.openmmlab.com/mmdetection/v3.0/rtmdet/rtmdet_tiny_8xb32-300e_coco/rtmdet_tiny_8xb32-300e_coco_20220902_112414-78e30dcc.pth' # noqa
model = dict(
# 考虑到数据集太小,且训练时间很短,我们把 backbone 完全固定
# 用户自己的数据集可能需要解冻 backbone
backbone=dict(frozen_stages=4),
# 不要忘记修改 num_classes
bbox_head=dict(dict(num_classes=num_classes)))
# 数据集不同,dataset 输入参数也不一样
train_dataloader = dict(
batch_size=train_batch_size_per_gpu,
num_workers=train_num_workers,
pin_memory=False,
dataset=dict(
data_root=data_root,
metainfo=metainfo,
ann_file='annotations/trainval.json',
data_prefix=dict(img='images/')))
val_dataloader = dict(
batch_size=val_batch_size_per_gpu,
num_workers=val_num_workers,
dataset=dict(
metainfo=metainfo,
data_root=data_root,
ann_file='annotations/test.json',
data_prefix=dict(img='images/')))
test_dataloader = val_dataloader
# 默认的学习率调度器是 warmup 1000,但是 cat 数据集太小了,需要修改 为 30 iter
param_scheduler = [
dict(
type='LinearLR',
start_factor=1.0e-5,
by_epoch=False,
begin=0,
end=30),
dict(
type='CosineAnnealingLR',
eta_min=base_lr * 0.05,
begin=max_epochs // 2, # max_epoch 也改变了
end=max_epochs,
T_max=max_epochs // 2,
by_epoch=True,
convert_to_iter_based=True),
]
optim_wrapper = dict(optimizer=dict(lr=base_lr))
# 第二 stage 切换 pipeline 的 epoch 时刻也改变了
_base_.custom_hooks[1].switch_epoch = max_epochs - num_epochs_stage2
val_evaluator = dict(ann_file=data_root + 'annotations/test.json')
test_evaluator = val_evaluator
# 一些打印设置修改
default_hooks = dict(
checkpoint=dict(interval=10, max_keep_ckpts=2, save_best='auto'), # 同时保存最好性能权重
logger=dict(type='LoggerHook', interval=5))
train_cfg = dict(max_epochs=max_epochs, val_interval=10)
"""
with open('rtmdet_tiny_1xb12-40e_cat.py', 'w') as f:
f.write(config_cat)
需要注意几个问题:
-
自定义数据集中最重要的是 metainfo 字段,用户在配置完成后要记得将其传给 dataset,否则不生效(有些用户在自定义数据集时候喜欢去 直接修改 coco.py 源码,这个是强烈不推荐的做法,正确做法是配置 metainfo 并传给 dataset)
-
如果用户 metainfo 配置不正确,通常会出现几种情况:(1) 出现 num_classes 不匹配错误 (2) loss_bbox 始终为 0 (3) 出现训练后评估结果为空等典型情况
扫描二维码关注公众号,回复: 16603797 查看本文章
-
MMDetection 提供的学习率大部分都是基于 8 卡,如果你的总 bs 不同,一定要记得缩放学习率,否则有些算法很容易出现 NAN,具体参考 https://mmdetection.readthedocs.io/zh_CN/latest/user_guides/train.html#id3
3.训练前可视化验证
开始训练前推荐先验证一下你的整个数据流是否是对的。我们可以采用 mmdet 提供的 tools/analysis_tools/browse_dataset.py 脚本来对训练前的 dataloader 输出进行可视化,确保数据部分没有问题。
考虑到我们仅仅想可视化前几张图片,因此下面基于 browse_dataset.py 实现一个简单版本即可
from mmdet.registry import DATASETS, VISUALIZERS
from mmengine.config import Config
from mmengine.registry import init_default_scope
cfg = Config.fromfile('rtmdet_tiny_1xb12-40e_cat.py')
init_default_scope(cfg.get('default_scope', 'mmdet'))
dataset = DATASETS.build(cfg.train_dataloader.dataset)
visualizer = VISUALIZERS.build(cfg.visualizer)
visualizer.dataset_meta = dataset.metainfo
plt.figure(figsize=(16, 5))
# 只可视化前 8 张图片
for i in range(8):
item=dataset[i]
img = item['inputs'].permute(1, 2, 0).numpy()
data_sample = item['data_samples'].numpy()
gt_instances = data_sample.gt_instances
img_path = osp.basename(item['data_samples'].img_path)
gt_bboxes = gt_instances.get('bboxes', None)
gt_instances.bboxes = gt_bboxes.tensor
data_sample.gt_instances = gt_instances
visualizer.add_datasample(
osp.basename(img_path),
img,
data_sample,
draw_pred=False,
show=False)
drawed_image=visualizer.get_image()
plt.subplot(2, 4, i+1)
plt.imshow(drawed_image[..., [2, 1, 0]])
plt.title(f"{
osp.basename(img_path)}")
plt.xticks([])
plt.yticks([])
plt.tight_layout()
4.模型训练
在验证数据流没有问题之后,开始训练
python tools/train.py rtmdet_tiny_1xb12-40e_cat.py
5.模型测试和推理
选择训练得到的最佳权重来测试
python tools/test.py rtmdet_tiny_1xb12-40e_cat.py work_dirs/rtmdet_tiny_1xb12-40e_cat/best_coco/bbox_mAP_epoch_30.pth
python tools/test.py rtmdet_tiny_1xb12-40e_cat.py work_dirs/rtmdet_tiny_1xb12-40e_cat/best_coco/bbox_mAP_epoch_30.pth --show-dir results# 保存真实值和预测值
可视化
# 数据集可视化
import os
import matplotlib.pyplot as plt
from PIL import Image
%matplotlib inline
plt.figure(figsize=(20, 20))
# 你如果重新跑,这个时间戳是不一样的,需要自己修改
root_path='work_dirs/rtmdet_tiny_1xb12-40e_cat/20230608_120933/results/'
image_paths= [filename for filename in os.listdir(root_path)][:4]
for i,filename in enumerate(image_paths):
name = os.path.splitext(filename)[0]
image = Image.open(root_path+filename).convert("RGB")
plt.subplot(4, 1, i+1)
plt.imshow(image)
plt.title(f"{
filename}")
plt.xticks([])
plt.yticks([])
plt.tight_layout()
6.可视化分析
可视化分析包括特征图可视化以及类似 Grad CAM 等可视化分析手段。由于 MMDetection 中还没有实现,可以直接采用 MMYOLO 中提供的功能和脚本。
MMYOLO环境和依赖安装
cd ../
rm -rf mmyolo
# 为了防止后续更新导致的可能无法运行,特意新建了 tutorials 分支
git clone -b tutorials https://github.com/open-mmlab/mmyolo.git #下载
cd mmyolo
pip install -e .# 安装
特征图可视化
### 放缩图片的过程
import cv2
img = cv2.imread('../mmdetection/cat_dataset/images/IMG_20211024_223313.jpg')
h,w=img.shape[:2]
resized_img = cv2.resize(img, (640, 640))
cv2.imwrite('resized_image.jpg', resized_img)
可视化backbone输出的三个通道
python demo/featmap_vis_demo.py \
resized_image.jpg \
../mmdetection/rtmdet_tiny_1xb12-40e_cat.py \
../mmdetection/work_dirs/rtmdet_tiny_1xb12-40e_cat/best_coco/bbox_mAP_epoch_30.pth \
--target-layers backbone \
--channel-reduction squeeze_mean
Image.open('output/resized_image.jpg')
可视化neck输出的三个通道
python demo/featmap_vis_demo.py \
resized_image.jpg \
../mmdetection/rtmdet_tiny_1xb12-40e_cat.py \
../mmdetection/work_dirs/rtmdet_tiny_1xb12-40e_cat/best_coco/bbox_mAP_epoch_30.pth \
--target-layers neck \
--channel-reduction squeeze_mean
Image.open('output/resized_image.jpg')
Grad-Based CAM可视化
区分类别的可视化。由于目标检测的特殊性,这里实际上可视化的并不是 CAM 而是 Grad Box AM。使用前需要先安装 grad-cam 库
pip install "grad-cam"
可视化neck 输出的最小输出特征图的 Grad CAM
python demo/boxam_vis_demo.py \
resized_image.jpg \
../mmdetection/rtmdet_tiny_1xb12-40e_cat.py \
../mmdetection/work_dirs/rtmdet_tiny_1xb12-40e_cat/best_coco/bbox_mAP_epoch_30.pth \
--target-layer neck.out_convs[2]
Image.open('output/resized_image.jpg')
可视化neck 输出的最大输出特征图的 Grad CAM
python demo/boxam_vis_demo.py \
resized_image.jpg \
../mmdetection/rtmdet_tiny_1xb12-40e_cat.py \
../mmdetection/work_dirs/rtmdet_tiny_1xb12-40e_cat/best_coco/bbox_mAP_epoch_30.pth \
--target-layer neck.out_convs[0]
Image.open('output/resized_image.jpg')
由于大物体不会在该层预测,因此梯度可视化是 0,符合预期。
7.检测新趋势
典型的方向如:
- Open-Vocabulary Object Detection,即开放词汇目标检测,给定图片和类别词汇表,检测所有物体
- Grounding Object Detection,即给定图片和文本描述,预测文本中所提到的在图片中的物体位置
- 随着 ChatGPT 的强大功能,一个模型可以完成非常多不可思议的事情,在视觉领域大家也开始倾向于研究大一统模型,例如通用图像分割模型,一个模型可以实现封闭集和开放集语义分割、实例分割、全景分割、图像描述等等任务,典型的如 X-Decoder。