一道题了解哈希
首先题目告诉我们这个字符串中只含有小写的英文字母而小写的英文字母只有26个,所以我们可以创建一个大小为26的字符数组用来记录字符串中每个字符出现的次数,然后就创建一个for循环遍历整个字符串得到字符串中每个字符出现的次数,比如说下面的代码:
char firstUniqChar(string s) {
int arr[26]={
0};
for(auto ch:s)
{
arr[ch-'a']++;
}
}
得到每个字符出现的次数之后我们就可以按照从左往右的顺序再遍历字符串根据数组中相应字符出现的次数来得到第一个只出现一次的字符,最后将其进行返回即可,如果不存在只出现一次的字符的话就返回空格字符,那么这里的代码就如下:
char firstUniqChar(string s) {
int arr[26]={
0};
for(auto ch:s)
{
arr[ch-'a']++;
}
for(auto ch:s)
{
if(arr[ch-'a']==1)
{
return ch;
}
}
return ' ';
}
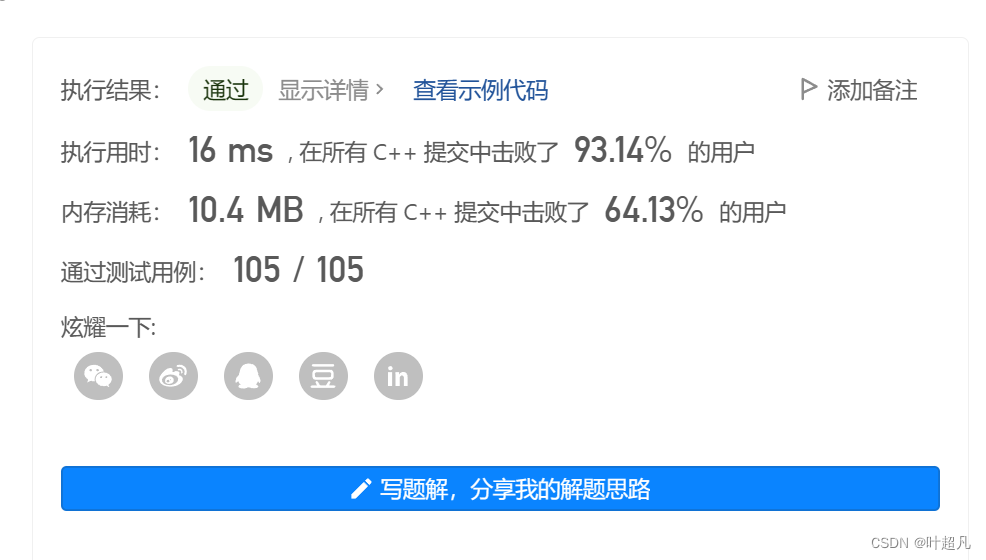
提交代码就可以看到这里的代码运行的是正确的:
那么上面的思路就类似于哈希,我们创建一个含有26个元素的整型数组,数组中的每个元素都代表着字符串中的某个元素比如说下标为0的元素就代表的是字符a,下标为1的元素就代表的是字符b等等依次类推,数组中每个元素的大小反应的就是字符串中某个元素出现的个数,如果数组下标为1的元素大小为3的话就表示字符串中元素b出现的次数为3,如果数组下标为2的元素大小为4的话就说明字符串中元素c出现的次数为4等等依此类推,那么我们就把这种通过数组来实现的一一对应的关系称为哈希结构,一堆数据中每个元素都在数组中对应着一个位置,而该位置元素的大小则反应了数据某个元素的属性,比如说上面数组中的元素大小就反应的是字符串中某个元素出现的个数,那么这就是哈希结构希望大家能够理解。
哈希的实现原理
方法一
哈希的本质就是哈希映射也就是让key值跟存储位置建立关联关系,比如说我们想要得到一堆数据中每个数据出现的个数,这些数据的特征是都是整型且数据大小的范围是0到1000,那么我们就可以创建一个大小为1001的数组,数组中的元素表示的就是数据中的元素出现的个数,这种方法我们就称为直接定值法:就是直接拿值来确定位置,或者用值来相对的确定位置比如说数据的范围是1000到2000,那么我们还是创建一个大小为1001的数组但是数组中下标为0的数组表示的是数据1000那么这就是相对对应,这种方法仅仅适用于数据十分集中的情况如果数据十分分散的话这种方法的效率就非常的低,比如说数据的范围是1到10000,那么我们就得创建一个大小为10000的数组,但是大多数数据都分布在9900到10000之间比如说只有一个数据为1其他都大于9900,那么这就会导致有9899个空间产生了浪费没有起到任何作用,所以这种做法就只适合数据十分集中的情况。
方法二
除留余数法:这个方法就不会管你的空间有多大,而是根据你提供的数据个数来确定要开辟多大的空间,比如说当前有7个数据,那么这里就会开辟10个空间,然后用空间的值摸上数据的值,得到的结果就是要存储位置的下标,比如说当前空间的大小为10如果处理的数据是18的话就将18摸上10得到的结果就是8,所以就将18放到下标为8的位置上,这样不管多大的数据都可以在一个很小的数组上找到对应的位置,但是这样的处理方法又会带来一个新的问题就是哈希碰撞,比如说一个值为3另外一个值为13,数组的空间大小为10,那么这两个数摸出来的结果是一样的,那下标为3的空间到底存储什么?这就存在一个问题,我们把这种现象称为哈希冲突,那么我们这里就有两个方法来解决,我们接下来就首先讲解一下第一个方法:闭散列—开放顶址法,这个方法就是映射的位置已经有值了,那就按某种规律找其他的位置比如说向后占领这个就是线性探测,你占领了我的位置,我就占领当前位置的后一个位置,如果后一个位置也被占领了我就占领后面的后面的位置,比如说下面的图片:

3对应的位置上存储了13如果再插入23的话,这个23就应该对应到下标为3的位置上,可是3上已经有数据了啊,所以我们就往后插入放到3的后面也就是4的位置上:

如果我们再插入数据33的话他对应的位置依然是3,可是3上存储了数据,3后面的4也存储了数据但是4后面的5没有存储数据所以我们就将数据放到5上面比如说下面的图片:

那么这就是插入的规则,对于查找也是相同的道理从对应位置开始一直往后进行查找如果找到了或者查找的位置为空的话就停止查找,那删除呢?这里的删除怎么删除呢?通过上面的思路我们确实可以找到想要删除的数据,那删除的话将这个数值置为什么呢?置为空吗?空是多少呢?是0吗?好像不是吧如果我们要查找的数据刚好为0的话是不是就出错了啊,那可以将空视为负数吗?好像也不行对吧,如果空为负数的话那这个哈希表就肯定不能存储负数,那这个空为多少呢?对于这个问题我们先不解决,假设我们找到了一个合理的值为空,删除就是将指定的数据置为空的话,那这个方法就真的没有问题吗?比如说下面的图片:

我们想要删除23的话就是将下标为4的数据置为空,那这里的代码就如下:

这时我们想要查找数据33的话是不是就会出错啊,查找的规则是找到元素或者当前的元素为空的话就停止查找,如果这里要查找元素33的话是从下标3开始查找,3对应的值是13显然不相等所以就往后跳动了一格来到了4,可是下标4对应的值为空,根据规则我们就应该结束了查找所以虽然数据33确实存在但是因为删除元素的方法不正确使得查找失败,那这就说明将一个元素置为空并不能解决问题,首先空不知道是哪个值其次这样的方法还会导致查找出现问题,所以有小伙伴就想到另外一格方法,能不能将被删除元素的后面的值依次往前一格来实现删除呢?比如说下面的图片

如果删除23的话就得将后面的数据全部向前挪动一格一直遇到空为止,比如说下面的图片:

挪动数据使得之前原本对应上来的数据现在无法对应起来了所以这里肯定不能采用直接挪动的方法来删除数据,那么这里解决的方法就是添加一个数组用来表示状态,这里的状态分为三种一个是empty表示当前位置没有数据,一个是erase表示当前位置之前有数据但是数据被删除了,一个是exist表示当前位置的元素存在,那么删除就是将当前位置的状态修改成为exist存在即可,查找的时候就是从指定位置查找一直找到状态为空的位置即可,如果找到了数据但是该数据对应的位置状态为不存在的依然返回不存在,那么这就是查找插入和删除的逻辑,接下来我们将一一模拟实现上述功能代码。
准备工作
首先每个节点都有状态,状态有三种所以我们这里可以创建一个枚举来描述三个状态,哈希的底层是一个vector其次每个元素的都有一个pair来存储数据还有一个名为state变量来记录当前节点的状态,所以这里得创建一个结构体来描述节点,又因为节点要存储各种类型的数据,所以这里要添加模板给节点类并且模板中存在两个参数,那么这里的代码如下:
enum state
{
EMPTY,
EXIST,
ERASE,
};
template<class K, class V>
struct HashNode
{
pair<K, V> _kv;
state _state = EMPTY;
};
因为哈希是通过数组来模拟实现的,所以这里的哈希类的底层就是通过vector来进行实现,其中vector中的数据类型就是HashNode,因为哈希会面临各种各样的数据,所以这里也得添加一个模板并且模板中有两个参数,那么这里的代码就如下:
template<class K,class V>
struct HashTable
{
public:
private:
vector<HashNode<K,V>> _tables;
};
因为我们插入的逻辑是将数据转换成为一个正整数然后根据这个正整数将数据·插入到vector当中,但是哈希表处理的数据可以会存在自定义类型,所以这里得给模板添加一个参数用来接收仿函数,仿函数的作用就是得到存储数据的类型所转换出来的值,我们用这个值来计算数据应该存储的位置,比如说一个string类型的数据内容为abcd,那么经过仿函数的处理之后abcd会转换成为一个值假设这个值就是每个字符的总和,所以abcd就会转换成为394,然后我们就会通过这个394来计算存储的位置比如说此时的数组的容量为10,那么它存储的位置就是4但是大家平时在使用哈希表处理整型数据和string类型数据时没有传递仿函数依然能够正常运行那这是为什么呢?答案是给这个模板参数传递了处理整型数据的仿函数缺省值,并且处理string类型的仿函数是处理整型数据的特化。这里有一个问题,哈希表有效字符的个数能等于vector的大小吗?好像可以吧,但是真的可以吗?当vector中含有很多数据的时候我们查找删除插入的时候,哈希冲突会十分的明显,这会导致哈希冲突变得越来越明显,接着就会导致哈希表的效率变得越来越低,所以这里得添加一个东西叫做负载因子,它的值等于表中有效数据的个数/表的大小,这个负载因子的值最好在0.7左右最好,如果负载因子等于0.7的话我们就扩容,负载因子越小的话冲突额度概率会越小,但是消耗的空间也就越大,所以我们得在类中添加一个变量用来记录当前表中的有效值,那么这里的代码就如下:
template<class K, class V>
struct HashNode
{
pair<K, V> _kv;
state _state = EMPTY;
};
template<class K>
struct HashFunc
{
size_t operator()(const K& key)
{
//对于内置类型直接将其转换成为无符号整型进行处理
return (size_t)key;
}
};
template<>
struct HashFunc<string>
{
size_t operator()(const string& key)
{
size_t res = 0;
for (auto ch : key)
{
res *= 131;
res += 131;
}
//这样的处理方式可以更好的降低重复率
return res;
}
};
template<class K,class V,class Hash=HashFunc<K>>
struct HashTable
{
public:
private:
vector<HashNode<K,V>> _tables;
size_t _n;//记录有效值的个数
};
那么最后一步就是添加构造函数,这里的构造函数就是将vector数据进行扩容,将变量_n初始化为0即可,那么这里的代码就如下:
HashTable()
:_n(0)
{
_tables.resize(10);
}
那么这就是准备工作接下来我们就要实现insert函数
insert
首先insert函数需要一个pair类型的参数,然后函数体的第一步就是创建一个仿函数对象,其次就是计算该数据应该插入的位置,那么这里的代码就如下:
bool Insert(const pair<K, V>& kv)
{
Hash hf;
size_t hashi = hf(kv.first) % _tables.size();
}
那么找到要位置之后我们就可以从该位置一直往后遍历,如果当前位置的状态为存在的话就继续往后,如果为删除或者为空的话就可以插入元素,当然这里为了防止越界每次遍历都将i的值模等上size,找到了就插入元素并修改当前的状态,并且对size变量加一,那么这里的代码就如下:
bool Insert(const pair<K, V>& kv)
{
Hash hf;
size_t hashi = hf(kv.first) % _tables.size();
while (_tables[hashi]._state == EXIST)
{
if (_tables[hashi]._kv.first == kv.first)
{
cout << "数据重复" << endl;
return false;
}
++hashi;
hashi%= _tables.size();
}
_tables[hashi]._kv = kv;
_tables[hashi]._state = EXIST;
++_n;
return true;
}
接下来就要实现扩容,当有效数据的个数占表中所有元素的70%时就得对其进行扩容,所以我们这里就再创建一个新哈希表该表的大小时老表的两倍,然后通过for循环遍历原来哈希表的每个元素,然后将每个元素都插入到新哈希表里面,最后再交换两个哈希表中的内部vector,那么这里的代码如下:
bool Insert(const pair<K, V>& kv)
{
if (_n * 10 / _tables.size()>=7)
{
HashTable<K, V, HashFunc<K>> newHash;
newHash._tables.resize(_tables.size() * 2);
for (auto &ch : _tables)
{
if (ch._state == EXIST)
{
newHash.Insert(ch._kv);
}
}
_tables.swap(newHash._tables);
}
Hash hf;
size_t hashi = hf(kv.first) % _tables.size();
while (_tables[hashi]._state == EXIST)
{
if (_tables[hashi]._kv.first == kv.first)
{
cout << "数据重复" << endl;
return false;
}
++hashi;
hashi%= _tables.size();
}
_tables[hashi]._kv = kv;
_tables[hashi]._state = EXIST;
++_n;
return true;
}
这里在扩容的时候不能简单的将内部的vector扩容为两倍,因为扩容之后内部数据的对应关系就全部都改变了,比如说容量为10的时候18对应的数据是8,扩容之后大小变成了20这时18就对应到了18位置上,所以这里不能简单的扩容,其次这里还有一个方法来实现扩容就是将数组的再创建vector变量将其大小变为现在的两倍,然后遍历原来的老数组找到每个值所对应的新下标再一个一个的插入,但是这么实现的话就会出现很多的重复工作,我们上面的写法就是借用了已有的东西减少了很多重复的工作。
find函数
先找到这个元素应该存在的位置,然后再往后查找为空的位置,如果为空了则返回false,如果出现值相等了并且当前位置的元素是存在的我们就返回true,但是找到之后会出现可以修改值得情况我们这里没找到就返回nullptr,如果找到了我们就返回这个元素所在的地址,那么这就是find函数的实现思路,该函数的代码实现如下:
HashNode<K,V>* Find(const K& key)
{
HashFunc<K> hf;
size_t hashi = hf(key) % _tables.size();
while (_tables[hashi]._state != EMPTY)
{
if (_tables[hashi]._kv.first == key&&
_tables[hashi]._state==EXIST)
{
return &_tables[hashi];
}
++hashi;
hashi%= _tables.size();
}
return nullptr;
}
erase函数
首先通过find函数找到数据存在的位置,因为find函数返回的是数据的地址,所以当数据存在的话我们就直接将数据的状态修改成为erase,如果数据不存在的话就直接返回false,那么这里的代码就如下:
bool erase(const K& key)
{
HashNode<K, V>* Date = Find(key);
if (Date)
{
Date->_state = ERASE;
--_n;
return true;
}
else
{
return false;
}
}
检测代码
检测的代码如下:
void TestHT1()
{
HashTable<int, int> ht;
int a[] = {
18, 8, 7, 27, 57, 3, 38, 18 };
for (auto e : a)
{
ht.Insert(make_pair(e, e));
}
ht.Insert(make_pair(17, 17));
ht.Insert(make_pair(5, 5));
if (ht.Find(7)){
cout << "存在" << endl;}
else{
cout << "不存在" << endl;}
ht.erase(7);
if (ht.Find(7)) {
cout << "存在" << endl; }
else {
cout << "不存在" << endl; }
}
代码的运行结果如下:
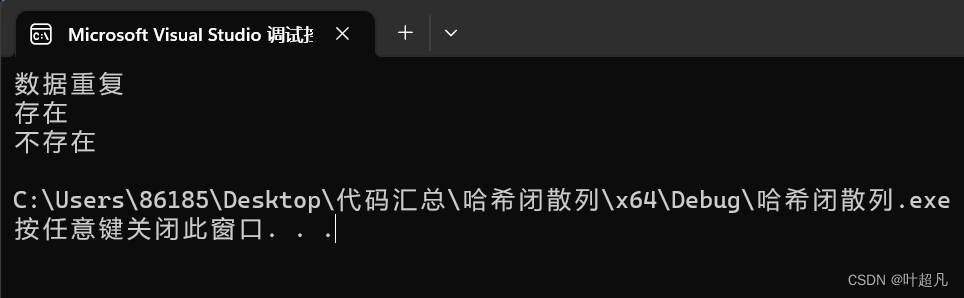
符合我们的预期,那么再来看看下面的检测代码:
void TestHT2()
{
string arr[] = {
"苹果", "西瓜", "香蕉", "草莓", "苹果", "西瓜", "苹果", "苹果", "西瓜", "苹果", "香蕉", "苹果", "香蕉" };
//HashTable<string, int, HashFuncString> countHT;
HashTable<string, int> countHT;
for (auto& e : arr)
{
HashNode<string, int>* ret = countHT.Find(e);
if (ret)
{
ret->_kv.second++;
}
else
{
countHT.Insert(make_pair(e, 1));
}
}
}
这段代码的运行结果如下:
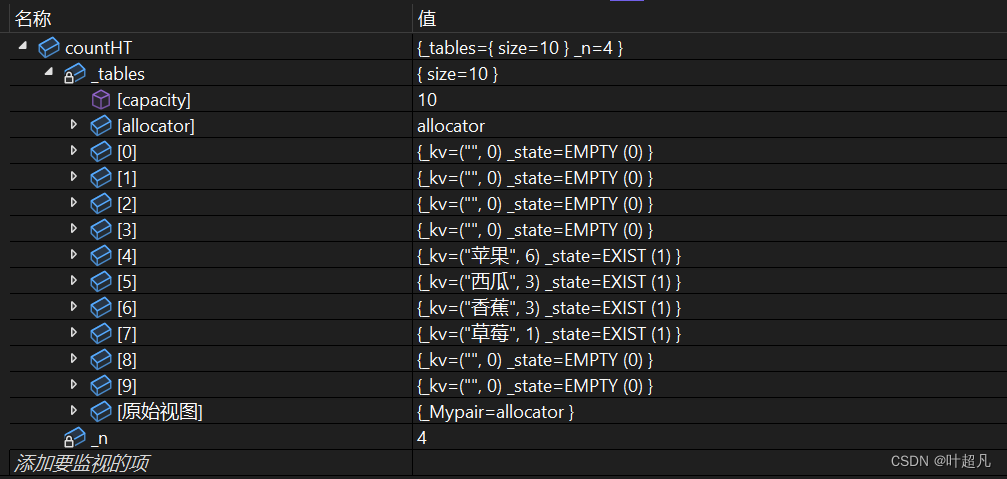
符合我们的预期,那么这就说明我们的代码完成的是正确的。本篇文章到此结束。