关于哈希表首先来看两个概念:
1.哈希函数
哈希函数是一个映像,因此哈希函数的设定很灵活,只要使得任何关键字由此所得的关键值都落在表长允许范围之内即可;
2.哈希冲突
对不同的关键字可能得到同一哈希地址,这种现象称为哈希冲突;
基于上面两个问题,我们来做说明:
哈希函数的构造
哈希函数的构造方法有很多,比如,直接定址法、数字分析法、平方取中法、折叠法、除留余数法等等,我们这里采用除留余数法来构造哈希函数
解决哈希冲突的方法
有两种解决哈希冲突的方法,线性探测法(开放定址法)、哈希桶(链地址法)和再哈希法,本文中使用的方法是线性探测法;
线性探测法如下图:
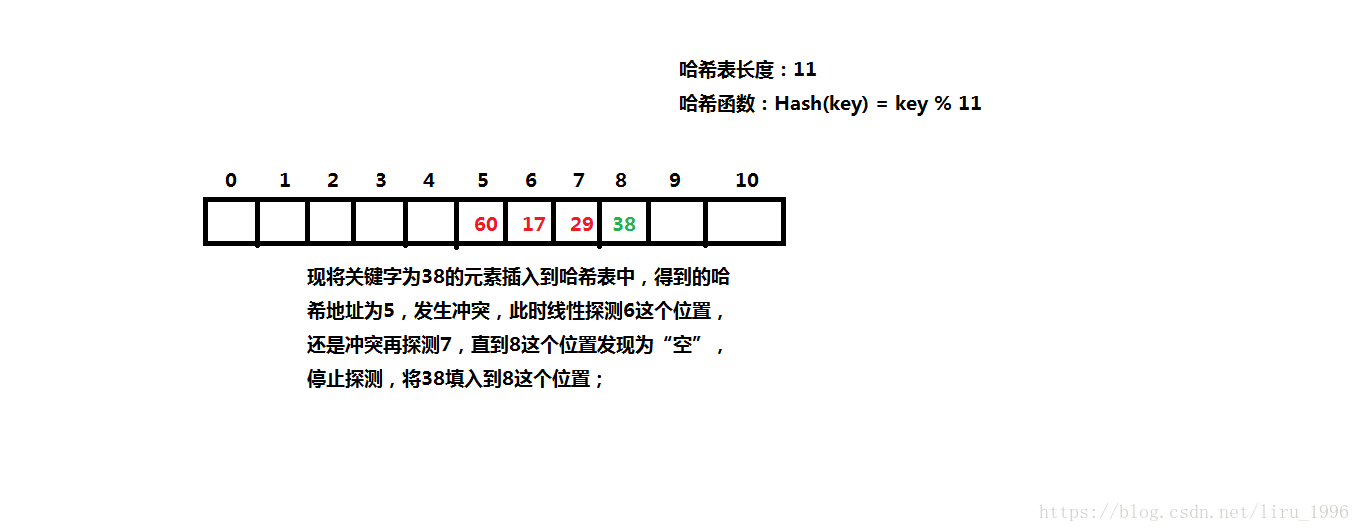
代码实现:
hash.h
#pragma once
#include <stddef.h>
#define HashMaxSize 1000
typedef enum{
Empty, //空状态
Valid, //有效状态
Deleted
}Stat;
typedef int KeyType;
typedef int ValType;
//这个结构体表示哈希表中的一个元素
//这个元素中同时表示了健值对
typedef struct HashElem{
KeyType key;
ValType value;
Stat stat;
}HashElem;
typedef size_t (*HashFunc)(KeyType key);
typedef struct HashTable{
HashElem data[HashMaxSize];
size_t size;
HashFunc func;
}HashTable;
void HashInit(HashTable* ht,HashFunc hash_func);
void HashDestroy(HashTable* ht);
void HashInsert(HashTable* ht,KeyType key,ValType value);
int HashFind(HashTable* ht,KeyType key,ValType* value);
void HashRemove(HashTable* ht,KeyType key);
hash.c
#include "hash.h"
size_t HashFuncDefault(KeyType key){
return key % HashMaxSize;
}
void HashInit(HashTable* ht,HashFunc hash_hunc){
ht->size = 0;
ht->func =hash_hunc;
size_t i = 0;
for(;i < HashMaxSize;i++){
ht->data[i].stat = Empty;
}
return;
}
void HashDestroy(HashTable* ht){
ht->size = 0;
ht->func = NULL;
size_t i = 0;
for(;i < HashMaxSize;i++){
ht->data[i].stat = Empty;
}
return;
}
void HashInsert(HashTable* ht,KeyType key,ValType value){
if(ht == NULL){
//非法输入
return;
}
//1.判定哈希表是否能继续插入(根据负载因子来进行判定)
//此处的负载因子为0.8
if(ht->size >= 0.8 * HashMaxSize){
//哈希表已经达到了负载因子的上线,插入失败
return;
}
//2.根据key来计算offset
size_t offset = ht->func(key);
//3.从offset位置线性往后查找,找到第一个状态为Empty然后插入
while(1){
if(ht->data[offset].stat != Valid){
//找到了一个位置
ht->data[offset].stat = Valid;
ht->data[offset].key = key;
ht->data[offset].value = value;
++ht->size;
return;
}else if(ht->data[offset].stat == Valid && ht->data[offset].key == key){
return;
}else{
++offset;
offset = offset >= HashMaxSize ? 0:offset;
}
}
return;
}
//思路:1.根据key算出offset
//2.从offset位置循环的进行查找,每次取到一个元素,用key去比较
//a)如果找到了key相同的元素,返回value,并且查找成功
//b)如果当前key不相等就继续往后找
//c)如果发现当前的元素是一个空元素,此时认为查找失败
int HashFind(HashTable* ht,KeyType key,ValType* value){
if(ht == NULL){
return 0;
}
size_t offset = ht->func(key);
while(1){
if(ht->data[offset].stat == Valid
&& ht->data[offset].key == key){
*value = ht->data[offset].value;
return 1;
}else if(ht->data[offset].stat == Empty){
return 0;
}else{
++offset;
offset = offset >= HashMaxSize ? 0:offset;
}
}
return 0;
}
void HashRemove(HashTable* ht,KeyType key){
if(ht == NULL){
return;
}
size_t offset = ht->func(key);
while(1){
if(ht->data[offset].stat == Valid
&& ht->data[offset].key == key){
ht->data[offset].stat = Deleted;
ht->size--;
return;
}else if(ht->data[offset].stat == Empty){
return;
}else{
offset++;
offset = offset >= HashMaxSize ? 0:offset;
}
}
return;
}