哈希(一)闭散列法
哈希概念
在二叉树搜索中,我们总是要对数据进行排序然后在根据排序结果进行查找。然而对于某些场景来说,总是要进行多次比较才可以搜索到数据,这样复杂度较高,较为复杂。于是我们想出了一种新的方法根据关键码进行映射查找类似于我们去书店借书时,店长有一个小本本记录当天借书与还书的情况来搜素数据。于是我们将这种关键码映射的方法称作哈希结构。
理想的搜索方式为我们进行一次搜索便可以找到想要的数据。那么我们可以构建一个类似于上面书店这个例子的账本,每一页存一本书的信息,提到书名我们便可以通过其中特殊的映射方式只寻找一次便找到账本关于这本书的这一页。我们将这种映射方式定义为HashFunc。
当我们向该结构中:
- 插入数据时:根据该数据的关键码算出插入位置,然后进行插入。状态置为存在。
- 删除数据时:根据该数据关键码算出删除位置,若位置已经存在数据则为哈希冲突,重新映射插入数据。
现在让我们总结下哈希结构开散列的特点:
数据通过映射插入哈希表中,每一个位置只可以存在一个数据。
我们用以下哈希表为例 :
映射方式为 :key(数据)%N(表容量)除留余数法
假设我们插入 13,15
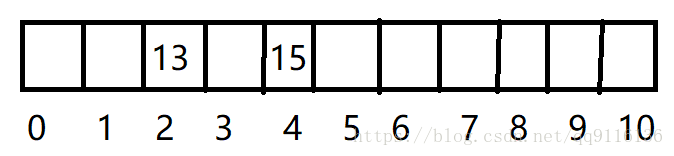
不过我们可以发现,当我们需要插入的数据变多时,将会出现问题,例如当我们插入24时,映射位置也是2,那么会发生冲突,这就产生了一个新的概念“哈希冲突”。
哈希冲突
产生哈希冲突的本质是由于一对一映射的时候,由于两种数据产生了同一种映射导致位置不够。那么我们可以将第二个数放在其他方便查找的位置。这里提供两种方式解决哈希冲突。
1. 找到该位置后第一个空的位置插入即可。
2. 找到该位置后第i平方的位置插入,第一次找到后面第一个位置,如果有数据那就找第4个位置,以此类推。
查找数据时我们先找到映射位置,如果该数据与映射位置的数据不相等时,我们在根据放置方式进行再次查找即可。不过这样又会产生新的问题,当我们插入了11个数据时,由于我们解决了哈希冲突每一个位置都插入了数据,这样我们在插入数据时将会无法插入。我们引入下一个概念,负载因子。
负载因子
我们定义负载因子为哈希表当前数据除以哈希表容量,那么当负载因子过大时将会产生很大的哈希冲突,我们找一个数将会无比麻烦,所以当负载因子高于某一个值时我们要进行扩容操作。根据研究,闭散列的负载因子一般控制在0.7到0.8之间。例如JAVA的系统库将负载因子设在了0.75.
可是我们扩容来说又有新的问题,当我们下一个容量选择不恰当的话,将会产生很多值映射在一个位置的尴尬情况,为了解决这个问题,我们每一次的扩容都选择质数,这里给出下面代码实现所采用的素数表。

代码实现
下面给出哈希闭散列的代码实现以供参考。
定义哈希表结构体
typedef int KeyType;
typedef int ValueType;
enum Status
{
EMPTY,
EXITS,
_DELETE,
};//每一个位置的状态
typedef struct HashNodeAZ
{
KeyType _key;
ValueType _value;
Status _status;
}HashNode;//节点
typedef struct HashTable
{
HashNode* _tables;
size_t _size;
size_t _N;
}HashTable;扩容用素数表
size_t GetNextPrimeNum(size_t cur)
{
static int prime_array[] = {
17,/* 0 */ 37, /* 1 */79,/* 2 */
163,/* 3 */331,/* 4 */673,/* 5 */
1361,/* 6 */2729,/* 7 */5471,/* 8 */
10949,/* 9 */21911,/* 10 */43853,/* 11 */
87719,/* 12 */175447,/* 13 */350899,/* 14 */
};
if (cur == 0)
{
return prime_array[0];
}
for (int i = 0;i < 27;i++)
{
if (cur == prime_array[i])
{
return prime_array[i + 1];
}
}
return 0;
}计算映射方法
size_t HashFunc(KeyType key, size_t N)
{
return key % N;
}初始化
void HashTableInit(HashTable* ht)
{
ht->_N = GetNextPrimeNum(0);
ht->_tables = (HashNode*)malloc(sizeof(HashNode)*ht->_N);
ht->_size = 0;
int i = 0;
for (;i < ht->_N;i++)
{
ht->_tables[i]._status = EMPTY;
}
}扩容
void HashInsertCapacity(HashTable* ht)
{
if (((ht)->_size * 10) >((ht)->_N * 7))
{
HashTable newhash;
newhash._N = GetNextPrimeNum(ht->_N);
newhash._tables = (HashNode*)malloc(sizeof(HashNode)*newhash._N);
for (int i = 0;i < newhash._N;i++)
{
newhash._tables[i]._status = EMPTY;
}
newhash._size = 0;
for (int j = 0;j < (ht)->_N;j++)
{
if ((ht)->_tables[j]._status == EXITS)
{
HashTableInsert(&newhash,
ht->_tables[j]._key, ht->_tables[j]._value);
}
}
HashTableDestory(ht);
ht->_N = newhash._N;
ht->_size = newhash._size;
ht->_tables = newhash._tables;
}
}插入
int HashTableInsert(HashTable* ht, KeyType key, ValueType value)
{
HashInsertCapacity(ht);
int i = HashFunc(key, ht->_N);
while (ht->_tables[i]._status == EXITS)
{
if (ht->_tables[i]._key == key)
{
return -1;
}
if (i == ht->_N)
{
i = 0;
}
i++;
}
ht->_tables[i]._key = key;
ht->_tables[i]._value = value;
ht->_tables[i]._status = EXITS;
ht->_size++;
return 0;
}查找
HashNode* HashTableFind(HashTable* ht, KeyType key)
{
int i = HashFunc(key, ht->_N);
while (ht->_tables[i]._status == EXITS)
{
if (ht->_tables[i]._key == key)
{
return &ht->_tables[i];
}
if (i == ht->_N)
{
i = 0;
}
i++;
}
return NULL;
}删除
int HashTableRemove(HashTable* ht, KeyType key)
{
int i = HashFunc(key, ht->_N);
while (ht->_tables[i]._status == EXITS)
{
if (ht->_tables[i]._key == key)
{
ht->_tables[i]._status = _DELETE;
ht->_size--;
return 0;
}
i++;
}
return -1;
}打印哈希表
void HashPrint(HashTable* ht)
{
int i = 0;
for (;i < ht->_N;i++)
{
if (ht->_tables[i]._status == EMPTY)
{
printf("[%d EMPTY] ", i);
}
if (ht->_tables[i]._status == EXITS)
{
printf("[EXITS : %d ] ", ht->_tables[i]._key);
}
if (ht->_tables[i]._status == _DELETE)
{
printf("[%d DELETE] ", i);
}
}
}