简单版ViT(无attention部分)
主要记录一下Patch Embedding怎么处理和了解一下vit的简单基本框架,下一节写完整的ViT框架
图像上的Transformer怎么处理?如图
图片—>分块patch---->映射(可学习)---->特征
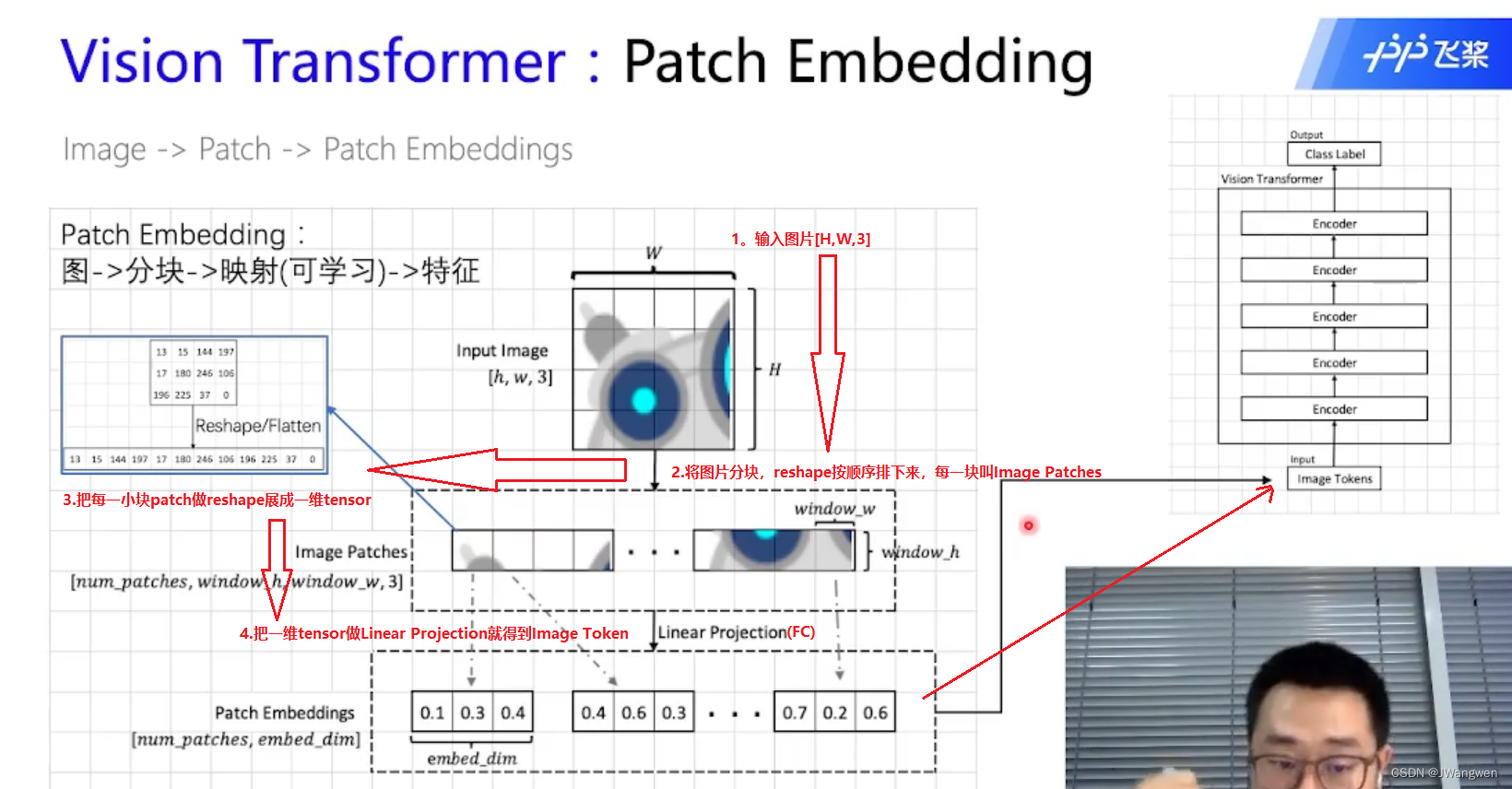
整体网络结构:
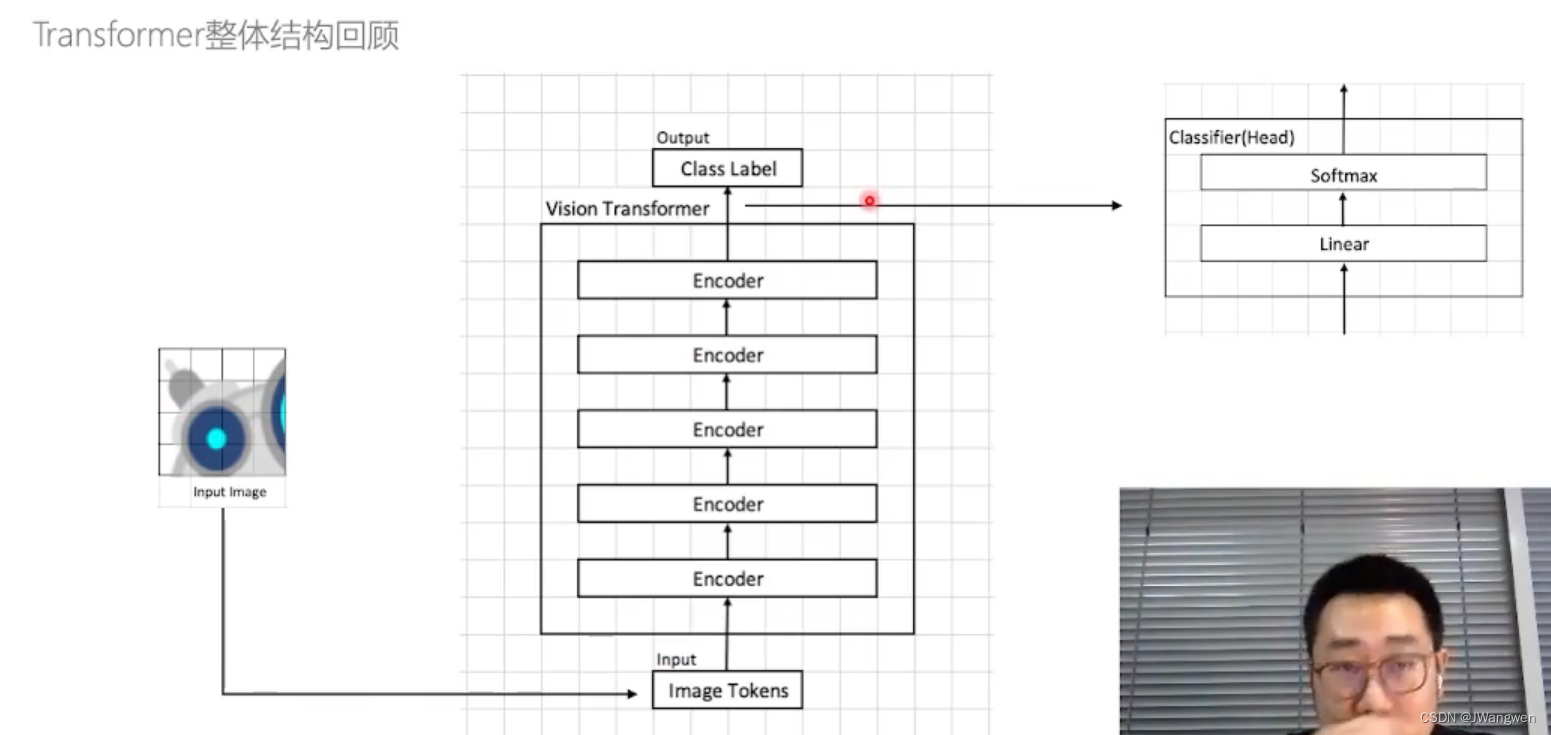
实践部分:
Patch Embedding用于将原始的2维图像转换成一系列的1维patch embeddings
Patch Embedding部分代码:
class PatchEmbedding(nn.Module):
def __init__(self,image_size, in_channels,patch_size, embed_dim,dropout=0.):
super(PatchEmbedding, self).__init__()
#patch_embed相当于做了一个卷积
self.patch_embed=nn.Conv2d(in_channels,embed_dim,kernel_size=patch_size,stride=patch_size,bias=False)
self.drop=nn.Dropout(dropout)
def forward(self,x):
# x[4, 3, 224, 224]
x=self.patch_embed(x)
# x [4, 16, 32, 32]
# x:[n,embed_dim,h',w']
x = x.flatten(2) #将x拉直,h'和w'合并 [n,embed,h'*w'] #x [4, 16, 1024]
x = x.permute(0,2,1) # [n,h'*w',embed] #x [4, 1024, 16]
x = self.drop(x)
print(x.shape) # [4, 1024, 16] 对应[batchsize,num_patch,embed_dim]
return x
ViT部分代码:
省略了attention部分
class Vit(nn.Module):
def __init__(self):
super(Vit, self).__init__()
self.patch_embed=PatchEmbedding(224, 3, 7, 16) # image tokens
layer_list = [Encoder(16) for i in range(5)] # 假设有5层encoder,Encoder维度16
self.encoders=nn.Sequential(*layer_list)
self.head=nn.Linear(16,10) #做完5层Encoder后的输出维度16,最后做分类num_classes为10
self.avg=nn.AdaptiveAvgPool1d(1) # 所有tensor去平均
def forward(self,x):
x=self.patch_embed(x) # #x [4, 1024, 16]
for i in self.encoders:
x=i(x)
# [n,h*w,c]
x=x.permute((0,2,1)) # [4, 16, 1024]
# [n,c,h*w]
x=self.avg(x) # [n,c,1] [4, 16, 1]
x=x.flatten(1) # [n,c] [4,16]
x=self.head(x)
return x
完整代码:
from PIL import Image
import numpy as np
import torch
import torch.nn as nn
# Identity 什么都不做
class Identity(nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
return x
#在Mlp中,其实就是两层全连接层,该mlp一般接在attention层后面。首先将16的通道膨胀4倍到64,然后再缩小4倍,最终保持通道数不变。
class Mlp(nn.Module):
def __init__(self, embed_dim, mlp_ratio=4.0, dropout=0.): # mlp_ratio就是膨胀参数
super(Mlp, self).__init__()
self.fc1 = nn.Linear(embed_dim, int(embed_dim * mlp_ratio)) # 膨胀
self.fc2 = nn.Linear(int(embed_dim * mlp_ratio), embed_dim) # 尺寸变回去
self.act = nn.GELU()
self.dropout = nn.Dropout(dropout)
def forward(self,x):
x = self.fc1(x)
x = self.act(x)
x = self.dropout(x)
x = self.fc2(x)
x = self.dropout(x)
return x
class PatchEmbedding(nn.Module):
def __init__(self,image_size, in_channels,patch_size, embed_dim,dropout=0.):
super(PatchEmbedding, self).__init__()
#patch_embed相当于做了一个卷积
self.patch_embed=nn.Conv2d(in_channels,embed_dim,kernel_size=patch_size,stride=patch_size,bias=False)
self.drop=nn.Dropout(dropout)
def forward(self,x):
# x[4, 3, 224, 224]
x=self.patch_embed(x)
# x [4, 16, 32, 32]
# x:[n,embed_dim,h',w']
x = x.flatten(2) #将x拉直,h'和w'合并 [n,embed,h'*w'] #x [4, 16, 1024]
x = x.permute(0,2,1) # [n,h'*w',embed] #x [4, 1024, 16]
x = self.drop(x)
print(x.shape) # [4, 1024, 16] 对应[batchsize,num_patch,embed_dim]
return x
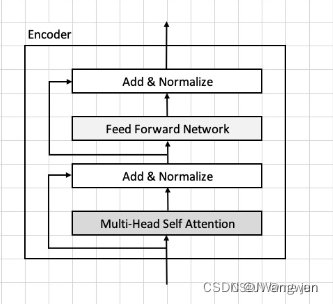
class Encoder(nn.Module):
def __init__(self,embed_dim):
super(Encoder, self).__init__()
self.atten = Identity() # self-attention部分先不去实现
self.layer_nomer = nn.LayerNorm(embed_dim) # LN层
self.mlp = Mlp(embed_dim)
self.mlp_nomer = nn.LayerNorm(embed_dim)
def forward(self,x):
# 参差结构
h = x
x = self.atten(x) # 先做self-attention
x = self.layer_nomer(x) # 再做LN层
x = h+x
h = x
x = self.mlp(x) #先做FC层
x = self.layer_nomer(x) # 再做LN层
x = h + x
return x
class Vit(nn.Module):
def __init__(self):
super(Vit, self).__init__()
self.patch_embed=PatchEmbedding(224, 3, 7, 16) # image tokens
layer_list = [Encoder(16) for i in range(5)] # 假设有5层encoder,Encoder维度16
self.encoders=nn.Sequential(*layer_list)
self.head=nn.Linear(16,10) #做完5层Encoder后的输出维度16,最后做分类num_classes为10
self.avg=nn.AdaptiveAvgPool1d(1) # 所有tensor去平均
def forward(self,x):
x=self.patch_embed(x) # #x [4, 1024, 16]
for i in self.encoders:
x=i(x)
# [n,h*w,c]
x=x.permute((0,2,1)) # [4, 16, 1024]
# [n,c,h*w]
x=self.avg(x) # [n,c,1] [4, 16, 1]
x=x.flatten(1) # [n,c] [4,16]
x=self.head(x)
return x
def test():
# 1. create a image
img=np.array(Image.open('test.jpg')) # 224x224
t = torch.tensor(img, dtype=torch.float32)
print(t.shape) # [224, 224, 3]
sample = t.reshape([4,3,224,224]) # 将[224, 224, 3]reshape成一行
print(sample)
#print(t.transpose(1,0))
# 2. patch embedding--------Patch Embedding用于将原始的2维图像转换成一系列的1维patch embeddings
# patch_size是切分的大小,原始224 ∗ 224 ∗ 3 的图片会首先变成32 ∗ 32 ∗ 16
# in_channel rgb图是3
# embed_dim是需要映射的dim
patch_embedding = PatchEmbedding(image_size=224, patch_size=7, in_channels=3, embed_dim=1)
# 做前向操作
out = patch_embedding(sample)
print(out)
#print(out.shape)
mlp=Mlp(embed_dim=1)
out = mlp(out)
print(out.shape)
def main():
t = torch.randn([4,3,224,224])
model=Vit()
out=model(t)
print(out.shape)
if __name__ == "__main__":
main()
最后输出[4,10]
下一节写完整的ViT代码