Embedding 字面理解是 “嵌入”,实质是一种映射,从语义空间到向量空间的映射,同时尽可能在向量空间保持原样本在语义空间的关系,如语义接近的两个词汇在向量空间中的位置也比较接近。
下面以一个基于Keras的简单的文本情感分类问题为例解释Embedding的训练过程:
首先,导入Keras的相关库
from keras.layers import Dense, Flatten, Input
from keras.layers.embeddings import Embedding
from keras.models import Model
from keras.preprocessing.sequence import pad_sequences
from keras.preprocessing.text import one_hot
import numpy as np
给出文本内容和label
# define documents
docs = ['Well done!',
'Good work',
'Great effort',
'nice work',
'Excellent!',
'Weak',
'Poor effort!',
'not good',
'poor work',
'Could have done better.']
# define class labels
labels = [1, 1, 1, 1, 1, 0, 0, 0, 0, 0]
然后将文本编码成数字格式并padding到相同长度
# integer encode the documents
vocab_size = 50
encoded_docs = [one_hot(d, vocab_size) for d in docs]
print(encoded_docs)
# pad documents to a max length of 4 words
max_length = 4
padded_docs = pad_sequences(encoded_docs, maxlen=max_length, padding='post')
print(padded_docs)
上面两个print输出如下,每次运行得到的数字可能会不一样,但同一个单词对应相同的数字。上述one_hot编码映射到[1,n],不包括0,n为上述的vocab_size,为估计的词汇表大小。然后padding到最大的词汇长度,用0向后填充,这也是为什么前面one-hot不会映射到0的原因。
[[41, 13], [14, 5], [11, 19], [30, 5], [47], [16], [37, 19], [26, 14], [37, 5], [38, 40, 13, 19], [37], [14]]
[[41 13 0 0]
[14 5 0 0]
[11 19 0 0]
[30 5 0 0]
[47 0 0 0]
[16 0 0 0]
[37 19 0 0]
[26 14 0 0]
[37 5 0 0]
[38 40 13 19]
[37 0 0 0]
[14 0 0 0]]
模型的定义
# define the model
input = Input(shape=(4, ))
x = Embedding(vocab_size, 8, input_length=max_length)(input) #这一步对应的参数量为50*8
x = Flatten()(x)
x = Dense(1, activation='sigmoid')(x)
model = Model(inputs=input, outputs=x)
# compile the model
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['acc'])
# summarize the model
print(model.summary()) #输出模型结构
输出的模型结构如下所示:
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) (None, 4) 0
_________________________________________________________________
embedding_1 (Embedding) (None, 4, 8) 400
_________________________________________________________________
flatten_1 (Flatten) (None, 32) 0
_________________________________________________________________
dense_1 (Dense) (None, 1) 33
=================================================================
这里先介绍一下Keras中的Embedding函数,详细见z官方文档:Embedding
keras.layers.Embedding(input_dim, output_dim, input_length)
- input_dim:这是文本数据中词汇的取值可能数。例如,如果您的数据是整数编码为0-9之间的值,那么词汇的大小就是10个单词;
- output_dim:这是嵌入单词的向量空间的大小。它为每个单词定义了这个层的输出向量的大小。例如,它可能是32或100甚至更大,可以视为具体问题的超参数;
- input_length:这是输入序列的长度,就像您为Keras模型的任何输入层所定义的一样,也就是一次输入带有的词汇个数。例如,如果您的所有输入文档都由1000个字组成,那么input_length就是1000。
再看一下keras中embeddings的源码,其构建函数如下:
def build(self, input_shape):
self.embeddings = self.add_weight(
shape=(self.input_dim, self.output_dim),
initializer=self.embeddings_initializer,
name='embeddings',
regularizer=self.embeddings_regularizer,
constraint=self.embeddings_constraint,
dtype=self.dtype)
self.built = True
可以看到它的参数shape为(self.input_dim, self.output_dim),在上述例子中即(50,8)
上面输出的模型结构中Embedding层的参数为400,它实质就是50*8得到的,这是一个关键要理解的信息。
我们知道one-hot 是无法考虑语义间的相互关系的,但embedding向量的训练是要借助one-hot的。上面的one-hot把每一个单词映射成一个整数,但实际上这个整数就表示了50维向量中 1 所在的索引位置,用整数显示是为了更好理解和表示,而实际在网络中,它的形式可以理解为如下图(下面相当于one-hot向量为5维,输出embedding向量为3维)
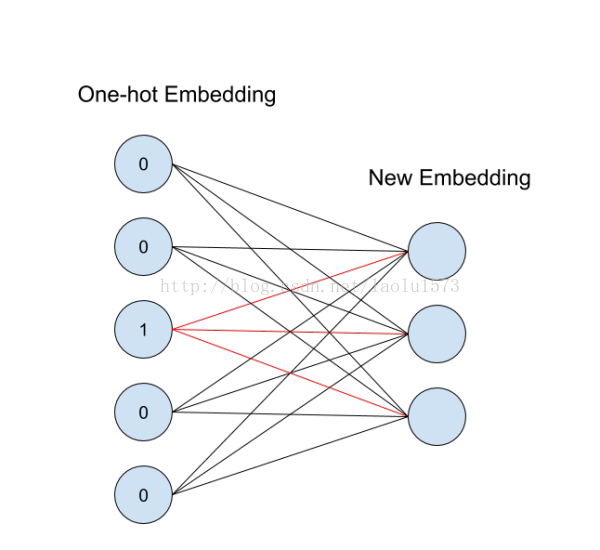
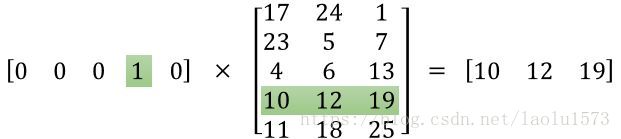
右边的神经元为one-hot输入,左边为得到的embedding表示,图中1所对应的红线权重就是该单词对应的词向量,这一层神经元只能作为第一层嵌入,是没有偏置和激活函数的,它也可以被理解为如下的一个矩阵相乘,输出就是该单词的词向量。然后词向量再输入到下一层。这一层总的参数量就是这些权重,也是下面中间的矩阵。
一个词组中有多个单词,如上面例子中有四个,那就分别经过这一层得到四个词向量,然后Flatten 到一层,再后接全连接层进行分类。因此,在这个模型中,embedding向量和分类模型是同时训练的,当然也可以用他人在大预料库中已经训练好的向量来直接训练分类。
上述例子的完整代码如下:
from keras.layers import Dense, Flatten, Input
from keras.layers.embeddings import Embedding
from keras.models import Model
from keras.preprocessing.sequence import pad_sequences
from keras.preprocessing.text import one_hot
import numpy as np
# define documents
docs = ['Well done!',
'Good work',
'Great effort',
'nice work',
'Excellent!',
'Weak',
'Poor effort!',
'not good',
'poor work',
'Could have done better.']
# define class labels
labels = [1, 1, 1, 1, 1, 0, 0, 0, 0, 0]
# integer encode the documents
vocab_size = 50
encoded_docs = [one_hot(d, vocab_size) for d in docs] #one_hot编码到[1,n],不包括0
print(encoded_docs)
# pad documents to a max length of 4 words
max_length = 4
padded_docs = pad_sequences(encoded_docs, maxlen=max_length, padding='post')
print(padded_docs)
# define the model
input = Input(shape=(4, ))
x = Embedding(vocab_size, 8, input_length=max_length)(input) #这一步对应的参数量为50*8
x = Flatten()(x)
x = Dense(1, activation='sigmoid')(x)
model = Model(inputs=input, outputs=x)
# compile the model
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['acc'])
# summarize the model
print(model.summary())
# fit the model
model.fit(padded_docs, labels, epochs=100, verbose=0)
# evaluate the model
loss, accuracy = model.evaluate(padded_docs, labels, verbose=0)
loss_test, accuracy_test = model.evaluate(padded_docs, labels, verbose=0)
print('Accuracy: %f' % (accuracy * 100))
# test the model
test = one_hot('good',50)
padded_test = pad_sequences([test], maxlen=max_length, padding='post')
print(model.predict(padded_test))
图片参考自:https://blog.csdn.net/laolu1573/article/details/77170407