美国康奈尔大学的大模型相关研究人员近日发布论文:
OctoPack:指令微调代码大语言模型
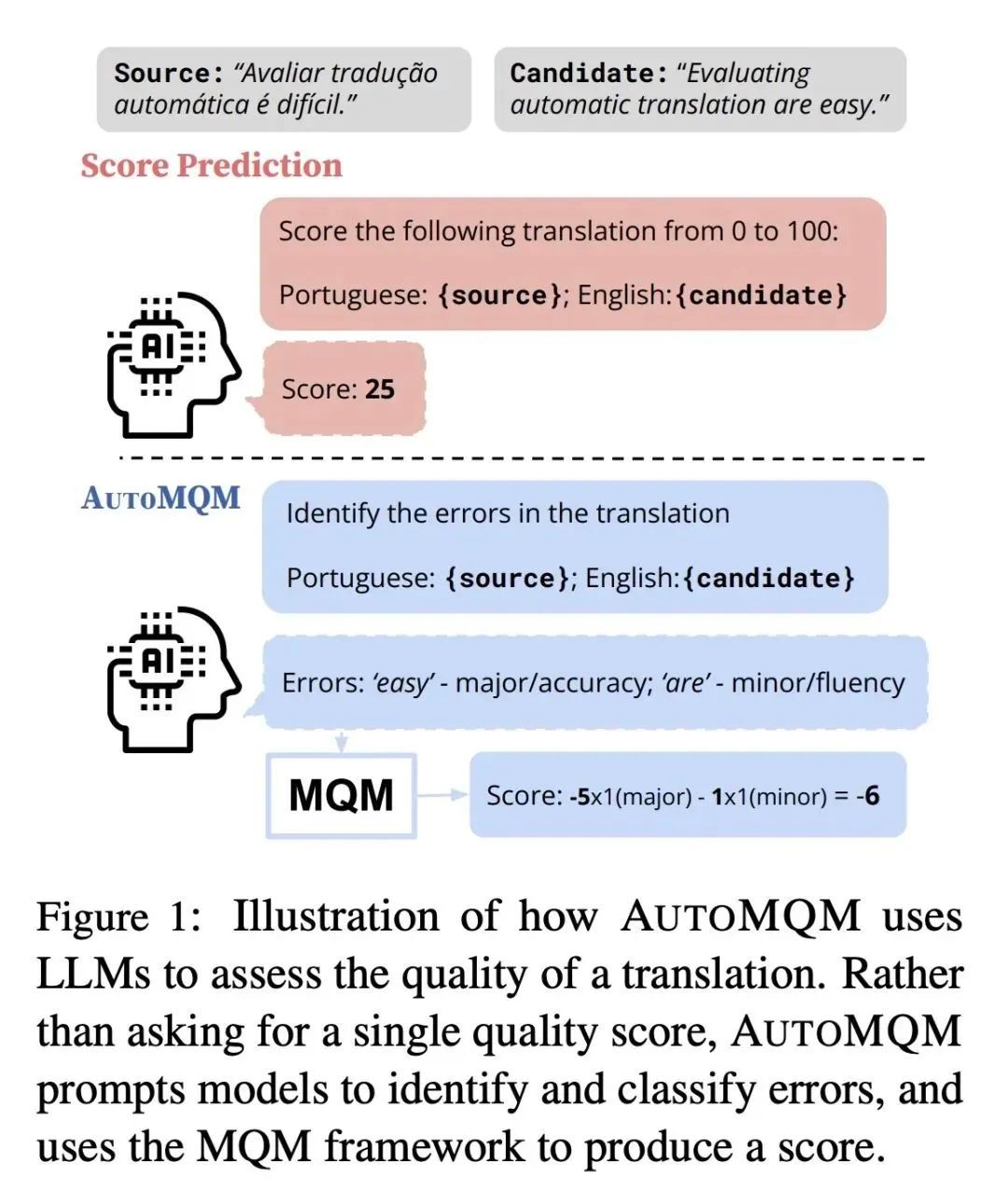
魔鬼就在错误中: 基于大型语言模型的细粒度机器翻译评估
原文链接 https://arxiv.org/abs/2308.07124
项目要点
- 提出COMMITPACK,一个包含350种编程语言,总量4TB的代码提交(commit)数据集,用于指令微调(instruction tuning),每个提交包含代码变更前后的对比、提交信息作为指令。
- 基于COMMITPACK过滤得到COMMITPACKFT,一个高质量子集,用于指令微调。
- 提出HUMANEVALPACK评估基准,扩展了之前的HUMANEVAL,包含3种任务:代码修复、代码解释和代码生成,覆盖6种语言,可以更全面评估代码生成模型的能力。
- 在StarCoder模型上微调各种指令数据,发现COMMITPACKFT数据集 mixed with OASST取得最佳效果,基于此训练了OCTOCODER和OCTOGEEX模型。
- 在HUMANEVALPACK上评测各模型,OCTOCODER在商用许可的模型中表现最好,封闭源的GPT-4效果最好。
- 讨论了一些模型的局限,如无法准确把控生成长度、只能处理单文件等,未来可考虑让模型执行代码、处理多文件、设计客观自动评测等。
- COMMITPACK也可用于预训练,本文进行了相关实验,未来可研究指令调优和预训练的统一。
项目动机
当前机器翻译自动评估的指标往往只提供单一的质量得分,缺乏详细的错误信息。因此,本文的动机是提出一种使用大型语言模型(LLM)的提示技术来识别和分类翻译中的错误,以填补这一缺口,并通过错误范围与人工标注对齐来提供可解释性的评估。
项目方法
利用Git提交的自然结构,将代码变更与人类指令配对,编译了包含4TB的Git提交的数据集COMMITPACK,并在16B参数的StarCoder模型上与其他自然语言和合成代码指令进行对比评估。
项目优势
在Python基准测试中,COMMITPACK在未经OpenAI训练的模型中取得了最先进的性能(46.2% pass@1),而在HUMANEVALPACK的编码任务中,OCTOCODER和OCTOGEEX表现最佳,展示了COMMITPACK在更广泛的语言和自然编码任务上的优势。