原文链接:
www.zhihu.com/question/607397171/answer/3148846973
最近在做一些大模型微调的工作。开始的时候比较头疼怎么调超参数,毕竟不能像小模型那样疯狂跑实验,看结果积累经验了,一是计算量太大,二是大模型比较不好评估(毕竟让模型做选择题不能准确的评估性能,一些垂类领域也很难搞到相关测试集,大部分在微调的工程师都是在调垂类模型吧:)。其次,如果用GPT4评估又涉及到数据隐私问题,同时下边列举的一篇文章显示,GPT4更倾向于给句子长的、回答更多样性的答案更高的分数,有时候也是不准的。最后也只能多看看微调/训练相关的论文借鉴借鉴经验了。下边会列出一些最近看的文章,给出重要结论以及我的一些个人观点,如果有感兴趣就去精读一下,希望能帮助到一些微调er,本文章不定期更新。。。
1.Towards Better Instruction Following Language Models for Chinese.
BELLE项目对应的研究报告,基于LLAMA进行微调。在1200W行中文数据上用BPE算法重新训练了一个tokenizer。将词表扩充到79458个,然后在3.4B的中文单词上进行二次预训练。发现扩充词表,更高的微调数据质量(GPT4比GPT3.5生成的指令数据质量好),更多的微调数据有利于微调出更好的模型。LLAMA本身带有多语言能力,只要加入少量新语言数据,就能微调出不错的效果。
2. Exploring the Impact of Instruction Data Scaling on Large Language Models An Empirical Study on Real-World Use Cases
BELLE项目团队的文章,主要研究不同数量的指令数据对模型性能的影响。发现增加指令数据量就能不断提高模型性能。同时也发现,随着微调数据量增加(这个是不是和《LIMA:Less Is More for Alignment》冲突了,LIMA的观点是用非常少的高质量的数据微调就能得到比较好的效果,增加微调数据量不会增加模型效果。可能是因为评估方式的问题?BELLE是做选择题,LIMA是用人和GPT4进行评估,欢迎评论区讨论),不同的任务类型表现出不同的特性:a)对于翻译、改写、生成和头脑风暴等任务,200万甚至更少的数据量可以使模型表现良好;b)对于提取、分类、封闭式QA和总结任务,模型的性能可以随着数据量的增加而继续提高,这表明我们仍然可以通过简单地增加训练数据量来提高模型的性能。但是改进的潜力可能是有限的。c)在数学、代码和COT内部结构上的表现仍然很差,需要在数据质量、模型规模和训练策略上进一步探索。基本总结为:基础模型做的比较差的任务也很难通过微调提升效果。
3. A Comparative Study between Full-Parameter and LoRA-based Fine-Tuning on Chinese Instruction Data for Instruction Following Large Language Model
BELLE项目团队的文章,对比了LoRA和全量参数微调的差距。微调基础模型(如llama这样的不具有对话能力的模型)LoRA还是比全量微调差一些的,微调对话模型差距不大。个人任务有时候全量微调是不如LoRA的,全量微调灾难遗忘现象会更加严重,微调效果好坏还要看数据量和超参数吧。而且lora rank=8会不会有点小。
4. Efficient and Effective Text Encoding for Chinese LLaMA and Alpaca
Chinese-LLaMA-Alpaca项目的技术报告。该项目在原版lamma的基础上词表扩充了2w中文字/词。原版lamma的词表里就几百个中文字,如果遇到没遇到过的中文字,会退化到3-4个byte,然后进行id编码,这样输入中文句子,生成的token id list会比较长,不利于训练和推理性能,也会影响模型学习到中文语意信息。使用LoRA高效微调方法进行二次预训练(chinese llama,第一版20G语料,plus版本120G语料)和有监督微调(chinese alpaca,在chinese llama的基础上进行,微调数据量为200w-300w,plus版本400w,最大长度512),LoRA作用于所有全连接网络(包括QKVO网络以及FFN层的两个神经网络)。指令微调时,使用了和alpaca项目不用的模版,不管有没有input,都只用一个模版,insruct和input合并(模版的变化应该对训练出来的模型性能没有影响吧:)。
和原版的alpaca项目相比,insruct和input合并
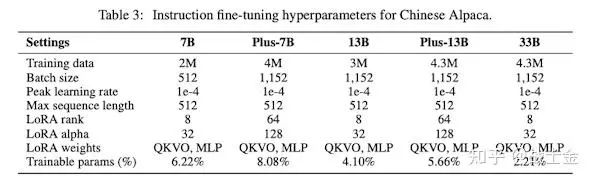
plus版本有更大的lora rank
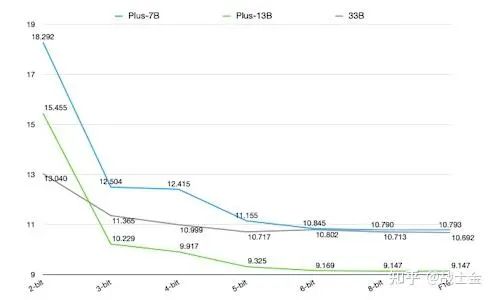
8bit量化不会影响太多精度
5. BloombergGPT: A Large Language Model for Finance
彭博社训练的金融垂类大模型,50B,从头训练的那种。文章写的十分细致,比如训练过程中遇到的各种bug,训练了几版,每版遇到了啥问题,怎么改进,各版的损失函数下降曲线。。。全文76页,非常务实的一篇文章。为了保证模型兼顾金融专业能力以及通用能力,使用51%金融数据和49%通用数据混合起来训练。使用Unigram 训练tokenizer,通过计算确定了词表大小为125,000。使用ALiBi位置编码,根据chinchilla扩展规律制定模型大小和训练数据量(给定固定的算力,计算出最合适的模型大小和训练数据大小),根据公式计算不同层数用多少隐藏单元维度最好。
6. How Far Can Camels Go? Exploring the State ofInstruction Tuning on Open Resources
发现没有任何一个有监督微调数据集,能使微调后的模型在各方面性能上都保持良好的状态,想要哪方面任务能提升,需要在微调数据集中加入相关微调数据。实验发现,将市面上一些能搜集到微调数据集放到一起一块训练模型能达到最好的效果(说白了就是微调数据要多样性,也可以理解为任务类型尽量cover所有下游任务)。发现用GPT4评估模型效果也不准确,GPT4更倾向于给句子更长的、更多样性的答案高分。
7. XuanYuan 2.0: A Large Chinese Financial Chat Model with Hundreds of Billions Parameters
度小满轩辕金融大模型的技术报告。大家普遍认为,注入知识在预训练阶段,有监督微调只是用来规范“说话方式”(有监督微调数据足够多也能注入知识,只不过数据不太好弄)。对于基于通用模型构建某一领域的垂类模型,可以先二次预训练注入知识,然后再做有监督微调。但是这样会带来两次“灾难遗忘”。该文章尝试将原始文本数据和有监督微调数据(均包含通用领域和金融领域)揉在一起,对BLOOM-176B进行继续训练。微调数据和原始文本数据混合起来一块训练的方式笔者尝试过了,注入知识和指令跟随的效果还不错。用LoRA方式灾难遗忘现象也不严重。
8. Lawyer LLaMA Technical Report
lawyer-llama的技术报告,中文法律大模型,基于英文原版LLaMA,做了继续预训练和微调。之前试过他们的模型,感觉效果一般。继续预训练包含两个阶段,第一阶段用多语言语料训练LLaMA,让其拥有更好的中文能力(明明可以用别人弄的更好的中文模型,比如文献4提到的Chinese-LLaMA-Alpaca,原版LLaMA没扩充中文词表会比较差。但是这篇报告在第4页还特意说了他们发现扩充词表没啥用。。扩充词表至少从生成效率上都是有优势的)。第二阶段用大量法律条文、司法解释、和人民法院的司法文件等原始文本做训练,增强法律基础知识。微调数据有2部分:1)拿到法考题数据,让ChatGPT对答案做出解释。2)收集法律咨询数据,让Chatgpt生成单轮或者多轮的对话数据。除此之外,为了解决模型幻觉问题,该项目还设计了一个法律条文检索模块,通过向量化召回技术(不了解可以看我这篇文章),根据用户问题召回相关的法律条文,让模型综合用户问题和法律条文进行回答。为了增强模型使用法律条文的能力,在构建微调数据集时也在上下文中放入了法律条文。作者发现,如果直接将法律条文给模型,模型会直接用,而不加以区分提供的法律条文是否真的和用户问题相关,如果召回的法律条文不准确,那么会严重影响模型回答效果。因此向微调数据中加入法律条文的过程中,特意加入一些不相关的条文,让模型在微调过程中学到忽略不相关条文的能力(果然有多少人工就有多少智能:) )
9.ChatLaw: Open-Source Legal Large Language Model with Integrated External Knowledge Bases
ChatLaw的技术报告。前阵子非常火的一款产品,人家是真的拿这东西当产品来做的,有自己的网站。但是我试了下他github上放的13B模型,并没有感觉法律能力有多突出,并且通用能力丧失太多。。。不过他的产品思路还是不错的。作为一款产品,模型幻觉是必须要解决的,为了在法律领域上达到更好的向量召回效果,还专门用法律数据训练了一个sentence2vec模型。除此之外,用户的问题通常是十分口语化的,直接用用户问题进行向量化检索可能会影响召回相关法律条文的准确率(为什么会影响看一下向量化召回原理就明白了,可以看我这篇文章),他们还专门微调了一个LLM,专门用来提取用户问题中的和法律相关的关键词,利用关键词来对法律条文进行向量化检索,增加召回精度。

10.Scaling Instruction-Finetuned Language Models
作者发现只要对模型进行指令微调,就能提升模型效果(即使微调任务数量只有9个的时候),也就是说即使少量微调数据,带来的收益也比灾难遗忘的程度大(这块笔者其实有一点困惑,比如chatglm2,对齐后的模型效果是比对齐之前效果差的。。。但是chatglm2是经过强化学习的,难道是强化学习负面影响太大了?欢迎评论区讨论)。同时发现,更多的微调数据任务种类(收集了1800个任务),更大的模型,微调数据里边增加COT数据,能进一步增加微调效果。
11.LIMA: Less Is More for Alignment
比较有名的一篇文章,核心思想是模型的知识都是在预训练时候得到的,微调知识为了学会和用户交互的风格或格式。用1000条精心挑选过的数据对65BLLaMA模型进行微调,就能得到比较好的效果。800条数据从Stack Exchange, wikiHow, Reddit上边人工挑选,200条数据人工标注。实验表明,微调数据的多样性有利于提高模型性能,但是提高微调数据的数量没有左右。对于大部分人来讲,个人认为这篇文章的思想借鉴意义不是很大,首先他用的65B模型,基础本来就已经很好了,但是大部分人还是在微调6/7B吧。而且有相当一部分人在微调垂类模型,为了注入知识,肯定是要把微调数据量加上去的。
12.ChatHome: Development and Evaluation of a Domain-Specific Language Model for Home Renovation
依然是BELLE团队的一篇文章,毕竟贝壳团队,开始做和自己业务相关的大模型了,ChatHome是家具和装修领域模型。在二次训练/微调垂类模型时,为了减轻灾难遗忘问题带来的负面影响,常用手段是把训练语料里加一点通用数据,作者探究了垂类数据和通用数据的比例问题。对于二次训练base模型(不具有对话能力),垂直数据:通用数据=1:5比较好。利用一些对话数据进一步微调模型,结果发现,即使是基于垂直数据:通用数据=1:5二次预训练的base模型,也不如直接在开源的chat模型上进行微调。。。所以二次预训练有点无用功的意思。base模型是baichuan13B,可能人家训练语料里本身就包含一些家装数据。除此之外,作者发现直接把垂类原始文本和对话数据掺合起来,直接对base模型训练一次,能达到最好的效果(即使不用通用数据)。这也和笔者之前的实验经验相吻合。二次预训练+微调的范式,造成两次灾难遗忘,负面影响比较大。
推荐阅读:
公众号:AI蜗牛车
保持谦逊、保持自律、保持进步

发送【蜗牛】获取一份《手把手AI项目》(AI蜗牛车著)
发送【1222】获取一份不错的leetcode刷题笔记
发送【AI四大名著】获取四本经典AI电子书