如何自动化地挑选出大模型所需的高质量指令微调数据
原创 戴剑波 SparksofAGI 2023-07-16 11:54
收录于合集#指令微调5个


Instruction Mining: High-Quality Instruction Data Selection for Large Language Models
如何自动化地挑选出大模型所需的高质量指令微调数据
LLM通常经历与训练和微调阶段,尽管前者给了模型强大的能力但有时候还是不能理解用户指令,指令微调是解决方法。近期研究发现即使只用很少且高质量的指令遵从数据,LLM就能被微调的比较好。但如何选择高质量微调数据集仍缺乏清晰的规则。这篇文章里作者提出“INSTRUCTMINING指令挖掘”,一种评估指令遵从质量的线性规则,其由特定的自然语言指标所构造出来(指标详见table1)。
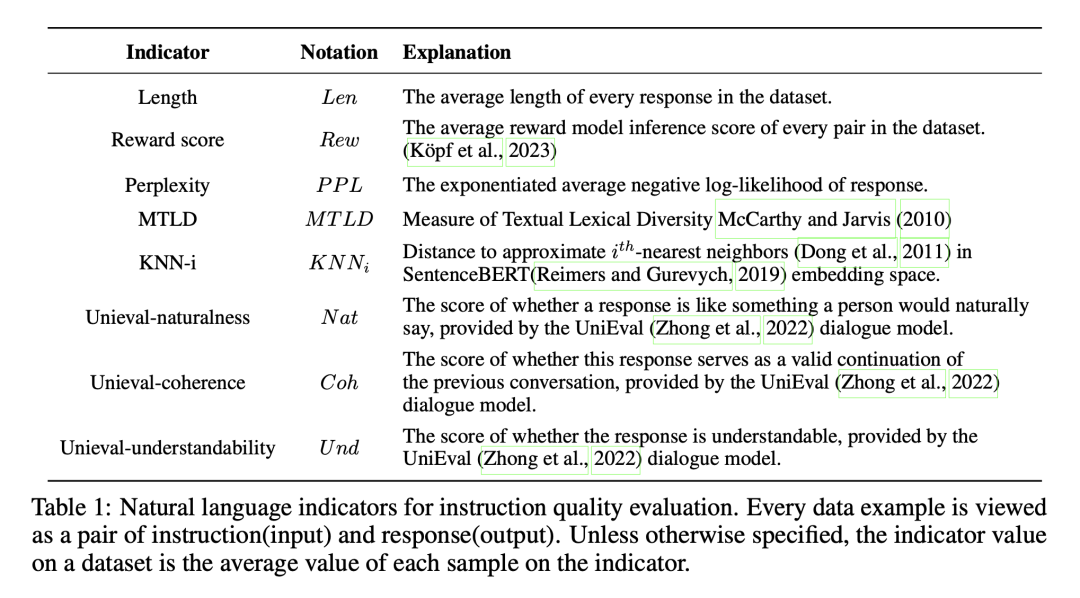
Table1
为了调查数据质量与这些指标间的关系,作者还在LLaMA-7B上做了大量实验。实验结果被应用于估算指令挖掘中的参数。为了进一步研究该方法的性能,作者用其从未见过的数据集中选择高质量数据。结果显示指令挖掘能帮助从各种指令遵从数据中挑出相对高质量的样本。相比于用未过滤过的数据集上微调的模型,用指令挖掘筛选后的数据集微调的模型在42.5%的样本上效果更好(见figure4)。
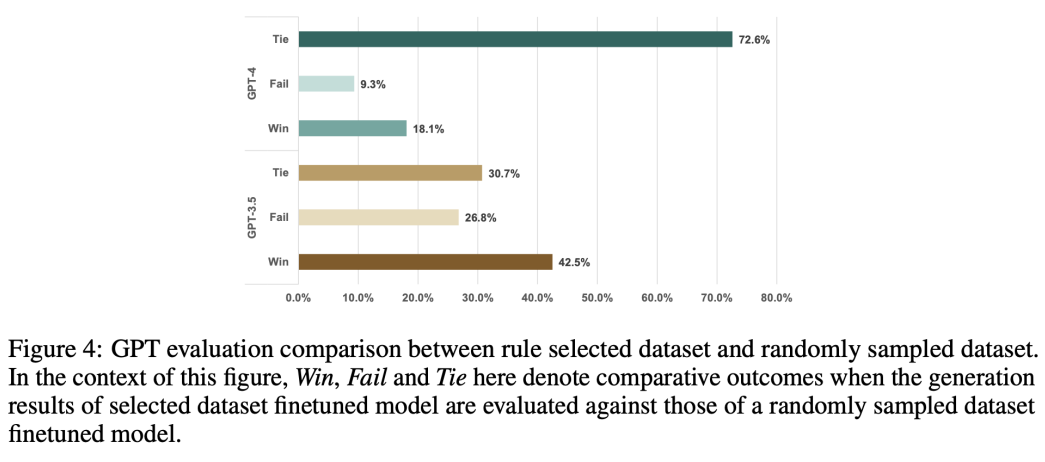
Figure4
指令微调对模型听从指令很重要,而获取大量多样性且人造的指令数据开销大,所以有人开始用类似self-instruct的方式大量构造但仍消耗很多资源,因此人们寻求获取小数量且高质量指令数据的方法,如LIMA,但其仍需专家帮助制定规则来挑选数据。而作者提出的指令挖掘完全不需要人类或机器标注,他们先提出一个质量评估假设,即可以用公平评估集上的微调模型产生的损失来估计教学数据的质量(见Instruction1),该评估集中包含了无偏见的人类写的指令与高质量回复。

Instruction1
在该假设下,他们能用推理损失来量化指令数据集质量(可见图5中的公式1,数据集D的质量正比于用D微调后的模型在D_eval上的负损失)。但估计推理损失需要实际微调语言模型,这可能非常耗时,为了克服这个问题作者引入一组选定的自然语言指标,可以利用它们来预测推理损失,而无需实际微调LLM。用各种语言指标来预测推理损失的公式可见图6中的公式2,是一个关于最小损失常数和通过函数F变换后的各种语言指标的值的函数。

Figure5(包含公式1)

Figure6(包含公式2)
为了研究语言指标与数据集质量间的关系,他们首先从一个多样的数据池中采样了78个不同的子数据集。然后他们记录下微调模型在这个评估集上的推理损失。接着计算各个子数据集的指标值。最后基于的大量获得的实验数据,应用统计回归模型来确定推理损失和指标值之间的关系。作者通过比较使用指令挖掘与随机采样数据集微调的模型间的推理性能,进一步证明指令挖掘有效且可拓展。
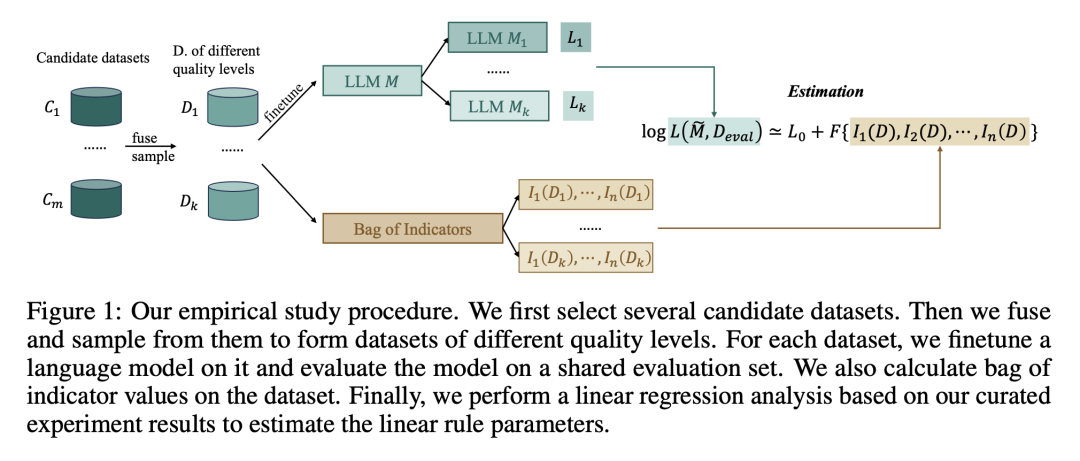
Figure1
最后,整个流程如Figure1所示。关于语言指标与损失的单变量分析图在Figure2,table4是用规则估计的值与实际微调后的loss的关系,说明了作者用语言指标取代loss的可行性。
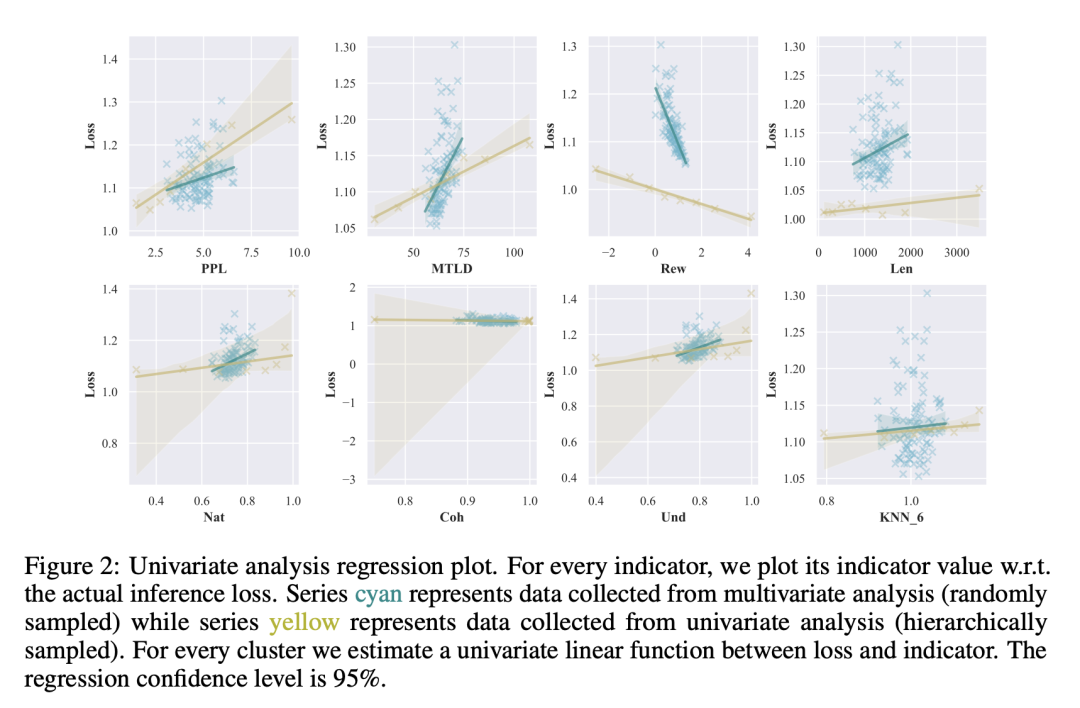
Figure2
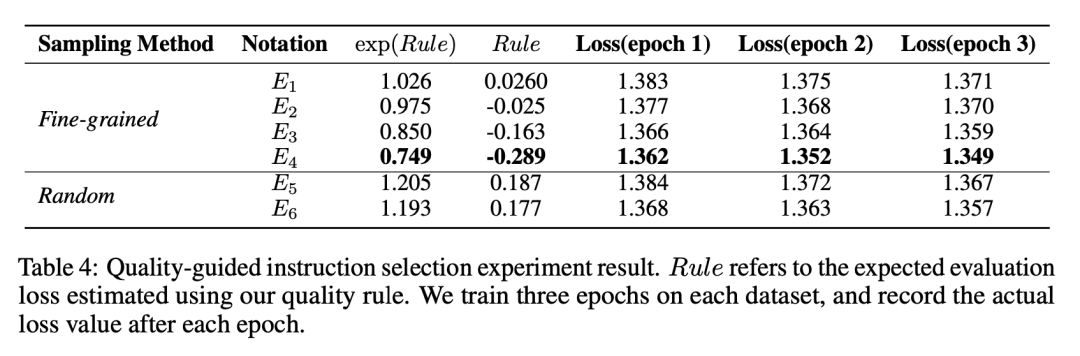
Table4