引言
本文设计的内容主要包含以下几个方面:
- 比较 LLaMA、ChatGLM、Falcon 等大语言模型的细节:tokenizer、位置编码、Layer Normalization、激活函数等。
- 大语言模型的分布式训练技术:数据并行、张量模型并行、流水线并行、3D 并行、零冗余优化器 ZeRO、CPU 卸载技术 ZeRo-offload、混合精度训练、激活重计算技术、Flash Attention、Paged Attention。
- 大语言模型的参数高效微调技术:prompt tuning、prefix tuning、adapter、LLaMA-adapter、 LoRA。
1 大语言模型的细节
1.0 transformer 与 LLM
教会计算机人类的语言(用人类的语言进行思考)是一项艰巨的任务,或许从计算机发明之初这一征程就已经开始了,然而直到现在我们还有很长的路要走。最近,大语言模型大放异彩让我们看到了更大的希望。
大语言模型(Large Language Model,LLM),即规模巨大(参数量巨大)的语言模型,LLM不是一个具体的模型,而是泛指参数量巨大的语言模型。如下图所示,不同的LLM具不同的架构,例如Encoder-only、Encoder-Decoder和Decoder-only等。 这种分类方式又和语言模型中一极其重要的模型有关——Transformer。
Transformer是2017年提出的一个语言模型,最初被用于解决机器翻译的问题,但随着研究的深入,Trf(指代Transformer)在不同问题,甚至不同领域上大放异彩,在自然语言领域的文本表征、分类、生成、问答等问题上都成为了强劲的解决方案,在视觉领域也很出色。
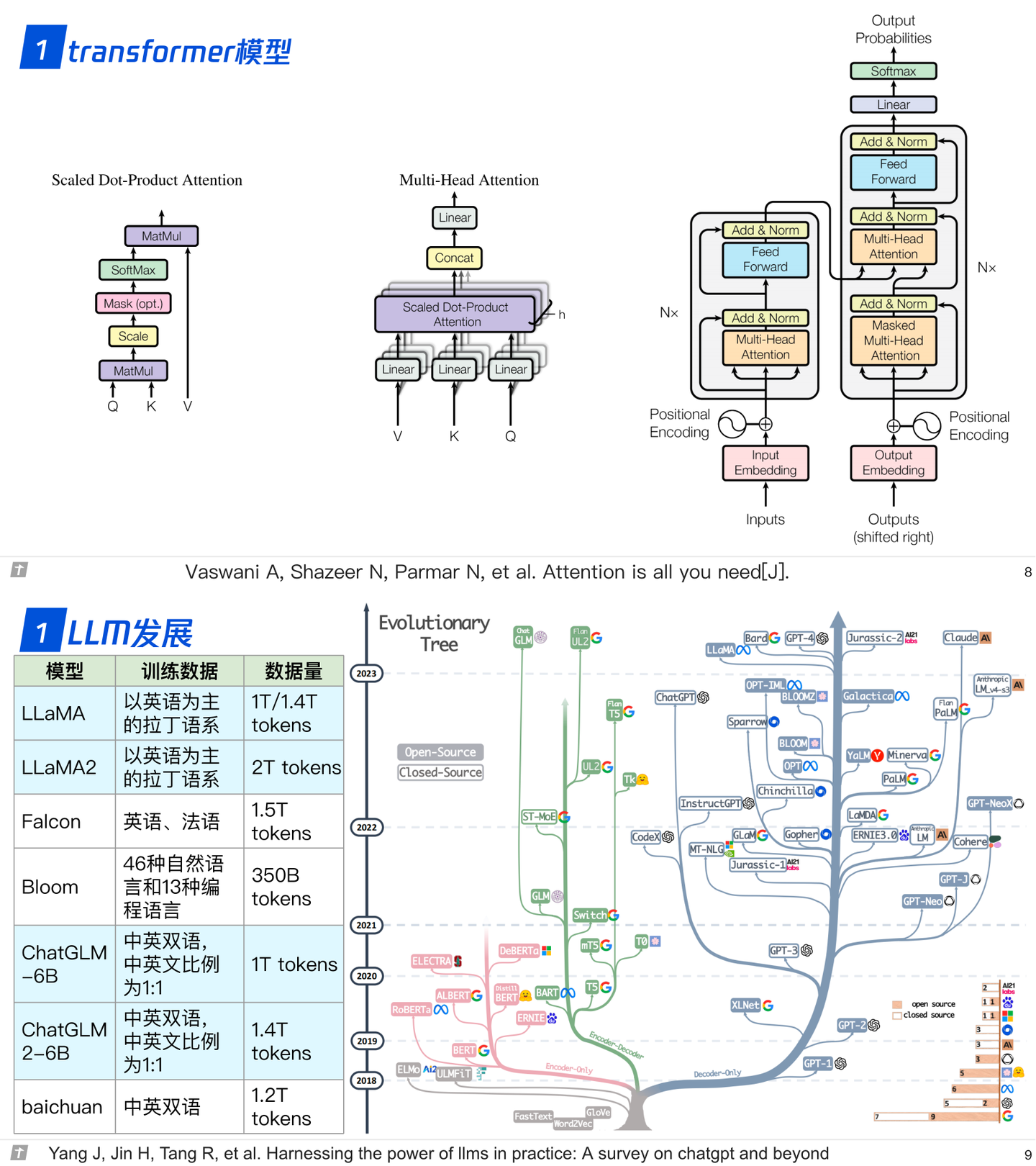
1.1 模型结构
transformer的组成:编码器和解码器。编码器由相同的层堆叠,每层的结构有两部分,多头注意力和前馈。解码器亦由相同的层堆叠,每层的结构为多头注意力、编码器-解码器注意力和前馈。
编码器中的每个元素对整个序列来说都是可见的。解码器的每一层中有两个多头注意力,一个是解码器的输入部分作为qkv的自注意力,一个是上一个解码器层的输出作为q,最后一个编码器层的输出作为kv的编码-解码注意力。编码器层和解码器层的每一个部分都是残差块的形式而且包括了一个layer norm。
在计算注意力时一般都会涉及到掩码,主要有两种掩码:一种是关于padding的掩码,即将不同长度的序列padding到统一长度,计算注意力时需要掩盖那些padding的位置,另一种是解码器中元素可见性的掩码,即位置i的元素只能看见自身和前面的元素。
就解码器而言,输入和输出的元素个数是一样的,但输入包含了SOS,输出是不包含SOS的,因此把最后一个的预测作为下一个位置的预测。
在训练的时候,解码器是可以并行的,以teacher forcing的方式训练,推断的时候则是串行的方式,预测了一个后并入输入。
在编码器和解码器的输入处都有位置编码,位置编码和token嵌入相加。transformer采用的是三角式位置编码,除此之外还有很多类型的位置编码,如相对位置编码、旋转位置编码(RoPE)和可学习的位置编码等。
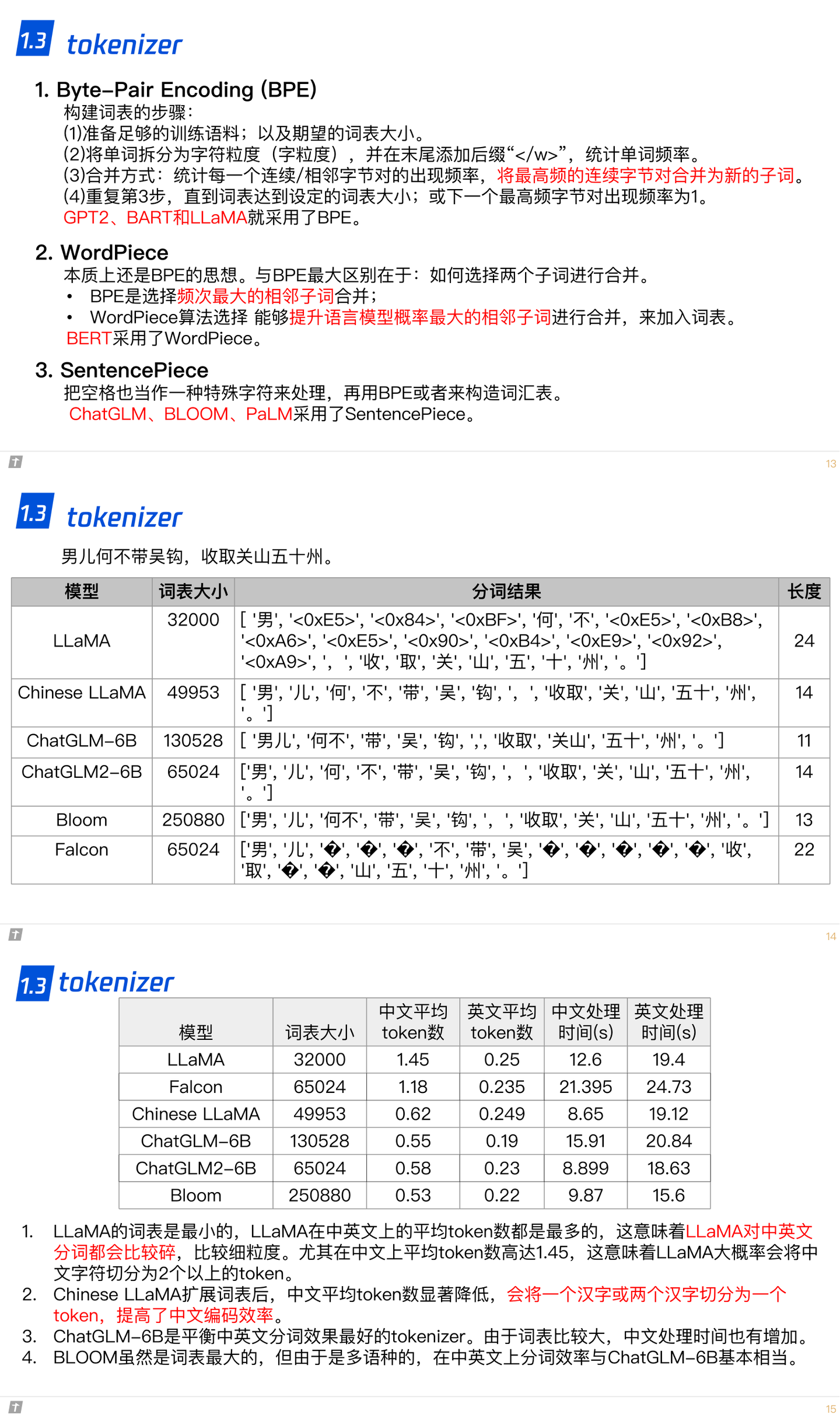
关于原始文本到token的一个转换。英语系的语言是天然的分割的,中文的字之间则没有天然的界限。在输入前,首先要做对的是对原始文本进行清洗,清洗其中无意义的符号、多余的标点、纠错、归一化(如统一大小写,繁简体等)等,这样原始文本就是干净的文本了。对文本进行分词后并不直接输入文本,就英语而言,一般会将word转化成sub word,sub word即模型中的token;中文则一般把单字作为token。sub word作为token能够降低OOV出现的概率。如何把word转化为sub word又有很多相关的方法,如Word Piece、ULM和BPE等。

1.2 训练目标

1.3 tokenizer
1.4 位置编码

1.5 层归一化

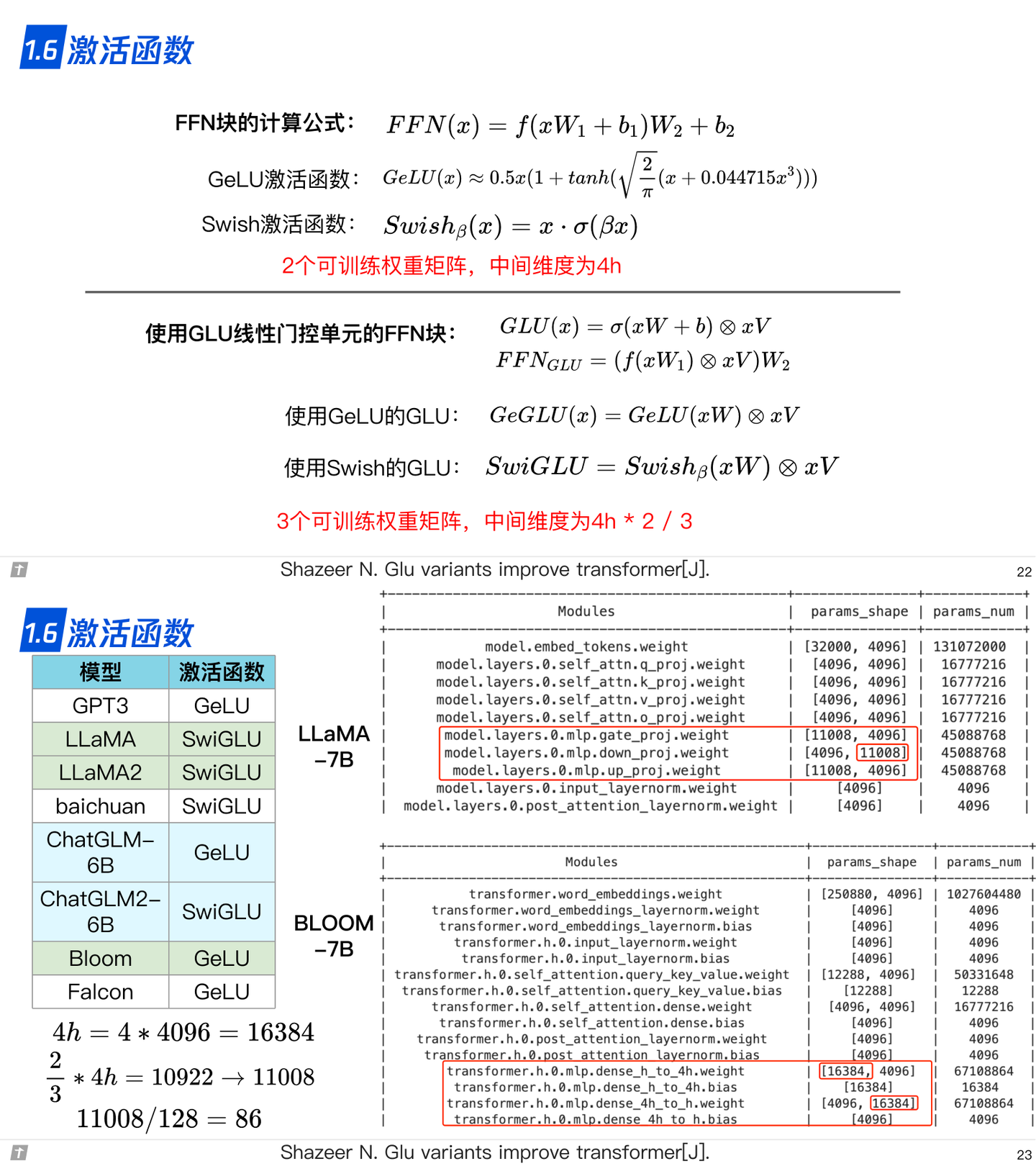
1.6 激活函数
1.7 Multi-query Attention 与 Grouped-query Attention

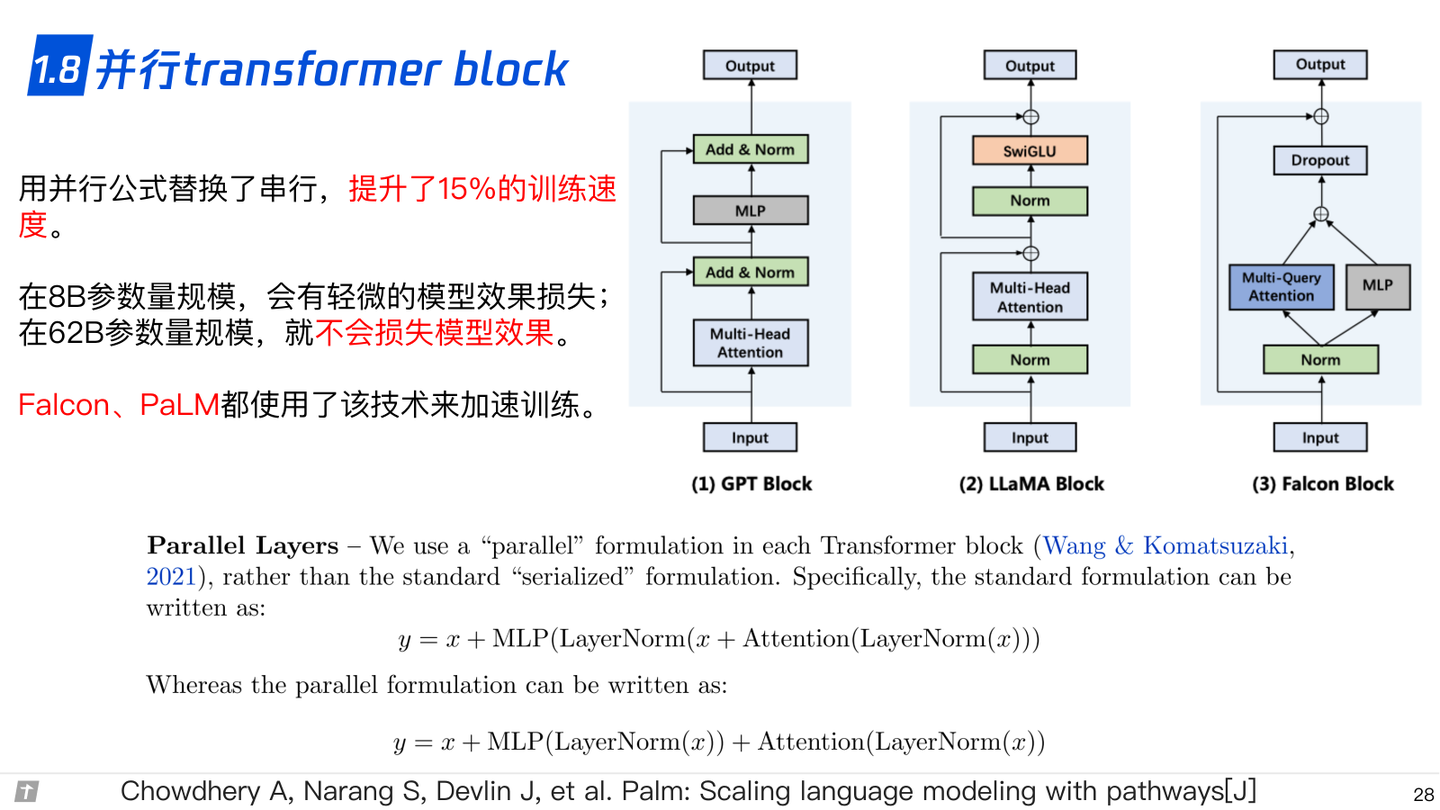
1.8 并行 transformer block
1.9 总结-训练稳定性

2. LLM 的分布式预训练
分布式训练的动机很简答:单节点算力和内存不足,因此不得不做分布式训练。
训练机器学习模型需要大量内存。假设一个大型神经网络模型具有 1000 亿的参数(LLM 时代有不少比这个参数量更大的模型),每个参数都由一个 32 位浮点数(4 个字节)表达,存储模型参数就需要 400GB 的内存。在实际中,我们需要更多内存来存储激活值和梯度。假设激活值和梯度也用 32 位浮点数表达,那么其各自至少需要 400GB 内存,总的内存需求就会超过 1200GB(即 1.2TB)。而如今的硬件加速卡(如 NVIDIA A100)仅能提供最高80GB的内存。单卡内存空间的增长受到硬件规格、散热和成本等诸多因素的影响,难以进一步快速增长。因此,我们需要分布式训练系统来同时使用数百个训练加速卡,从而为千亿级别的模型提供所需的TB级别的内存。
为了方便获得大量用于分布式训练的服务器,我们往往依靠云计算数据中心。一个数据中心管理着数百个集群,每个集群可能有几百到数千个服务器。通过申请其中的数十台服务器,这些服务器进一步通过分布式训练系统进行管理,并行完成机器学习模型的训练任务。

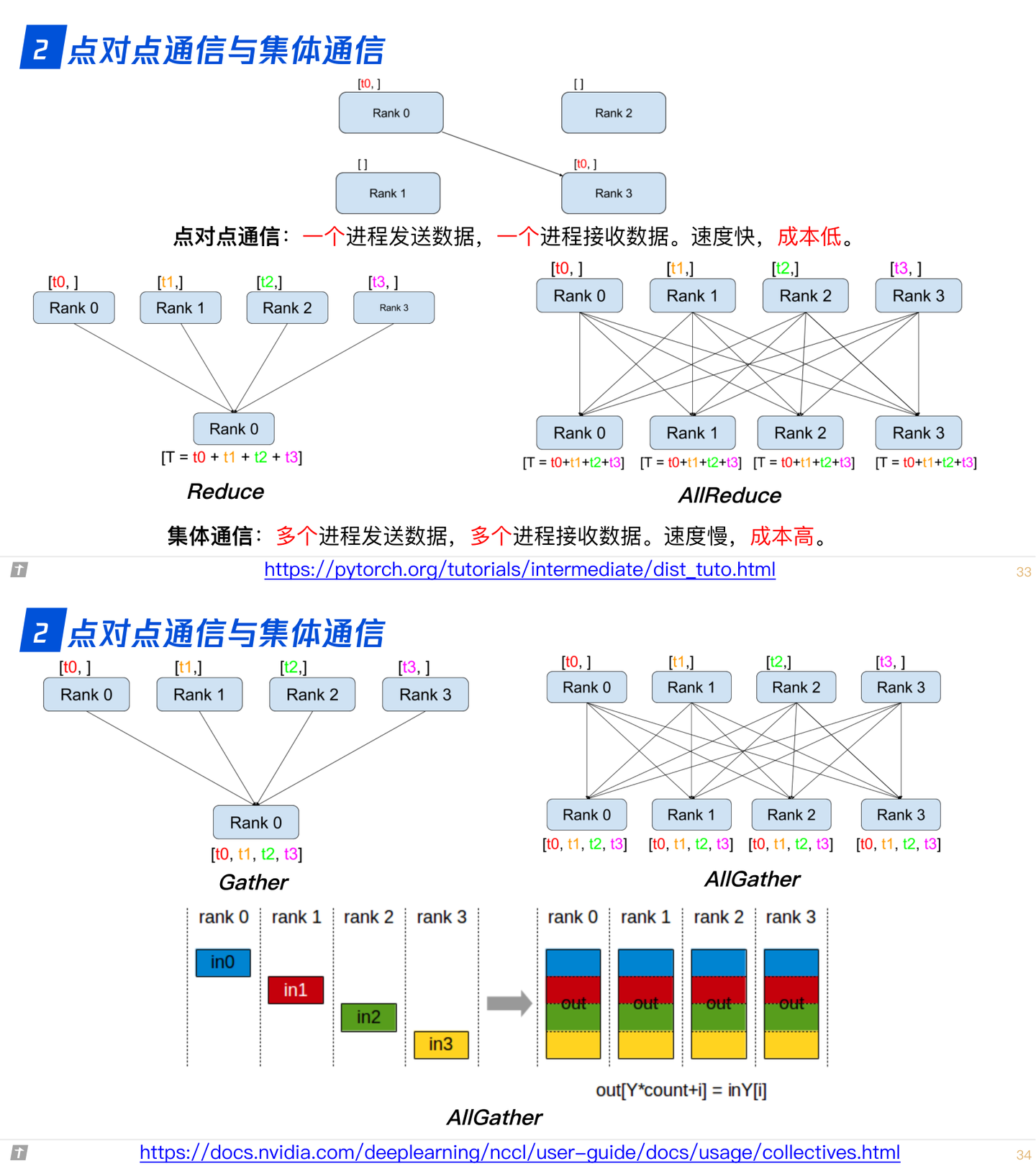
2.0 点对点通信与集体通信
2.1 数据并行
数据并行常见的应用有:PyTorch 和 MegEngine 的 Distributed,也就是起多机进行训练,主要是解决单机算力不足的问题。
在一个数据并行系统中,假设用户给定一个训练批大小为 N,并且希望使用 M 个并行设备来加速训练。那么,该训练批大小会被分为 M 个分区,每个设备会分配到 N / M 个训练样本。这些设备共享一个训练程序的副本,在不同数据分区上独立执行、计算梯度。不同的设备(假设设备编号为 i)会根据本地的训练样本计算出梯度 Gi. 为了确保训练程序参数的一致性,本地梯度 Gi 需要聚合(reduce,各个进程需要和主进程通信),计算出平均梯度。最终,训练程序利用平均梯度修正模型参数,完成小批次的训练。
下图展示了两个设备构成的数据并行训练系统(Data Parallel Training System)的例子。假设用户给定的数据批大小是 64,那么每个设备会分配到 32 个训练样本,并且具有相同的神经网络参数(程序副本)。本地的训练样本会依次通过这个程序副本中的算子,完成前向计算和反向计算。在反向计算的过程中,程序副本会生成局部梯度。不同设备上对应的局部梯度(如设备 1 和设备 2 上各自的梯度1)会进行聚合,从而计算平均梯度。这个聚合的过程往往由集合通信的 AllReduce 操作完成(用 cuda 的话一般是通过 NCCL 来完成)。

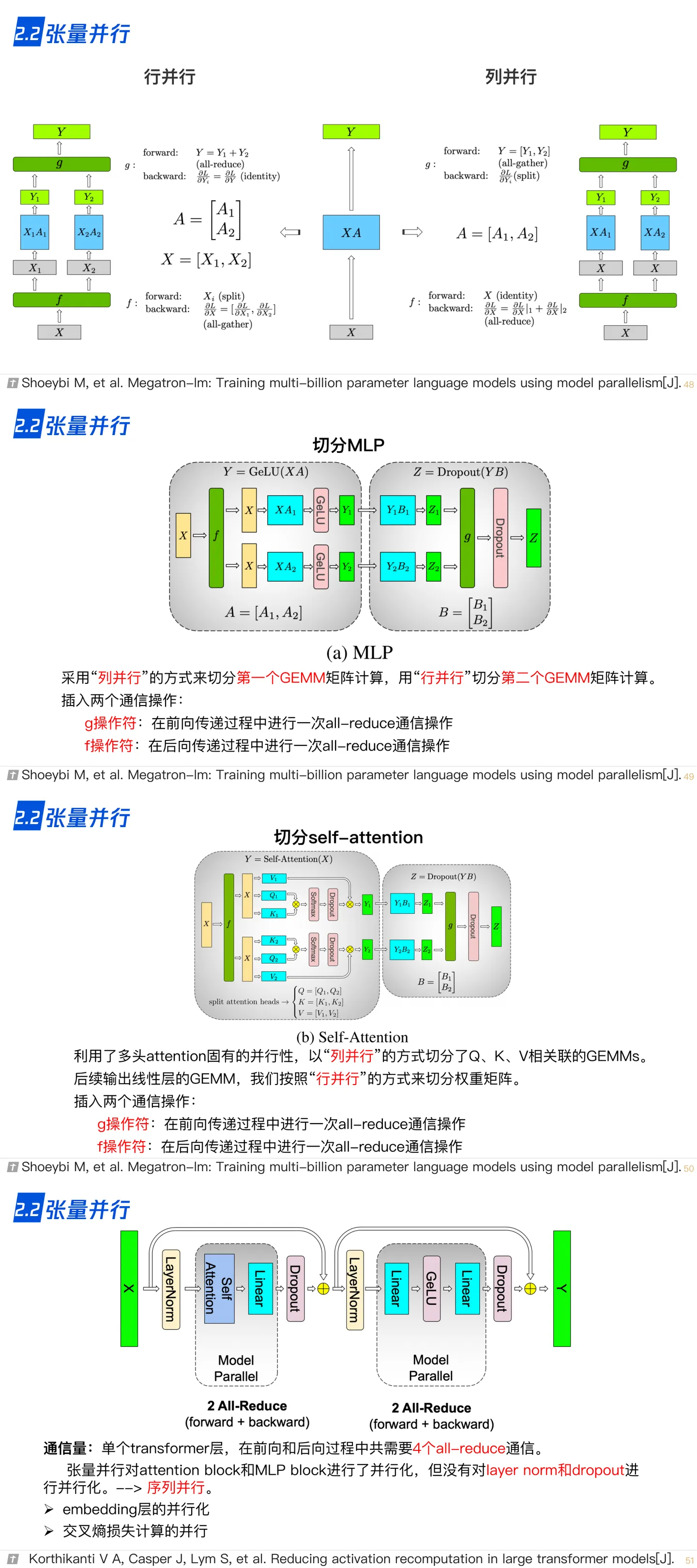
2.2 模型/张量并行
模型并行往往用于解决单节点内存不足的问题。一个常见的内存不足场景是模型中含有大型算子,例如深度神经网络中需要计算大量分类的全连接层。完成这种大型算子计算所需的内存可能超过单设备的内存容量。那么需要对这个大型算子进行切分。假设这个算子具有 P 个参数,而系统拥有 N 个设备,那么可以将 P 个参数平均分配给 N 个设备,从而让每个设备负责更少的计算量,能够在内存容量的限制下完成前向计算和反向计算。这种切分方式是模型并行训练系统(Model Parallelism Training System)的一种应用,也被称为 算子内并行 (Intra-operator Parallelism)。
下图是一个模型并行的流程图,同样的一份数据被广播成两份给两个设备分别计算,两个设备的计算并不相同,分别计算出结果之后再 Gather 汇总结果(到主进程)。
在这个例子中,假设一个神经网络具有两个算子,算子 1 的计算(包含正向和反向计算)需要预留 16 GB的内存,算子 2 的计算需要预留 1GB 的内存。而本例中的设备最多可以提供 10GB 的内存。为了完成这个神经网络的训练,需要对算子 1 实现并行。具体做法是,将算子 1 的参数平均分区,设备 1 和设备 2 各负责其中部分算子1的参数。由于设备 1 和设备 2 的参数不同,因此它们各自负责程序分区 1 和程序分区 2。在训练这个神经网络的过程中,训练数据(按照一个小批次的数量)会首先传给算子 1。由于算子 1 的参数分别由两个设备负责,因此数据会被广播(Broadcast)给这两个设备。不同设备根据本地的参数分区完成前向计算,生成的本地计算结果需要进一步合并,发送给下游的算子 2。在反向计算中,算子 2 的数据会被广播给设备 1 和设备 2,这些设备根据本地的算子 1 分区各自完成局部的反向计算。计算结果进一步合并计算回数据,最终完成反向计算。


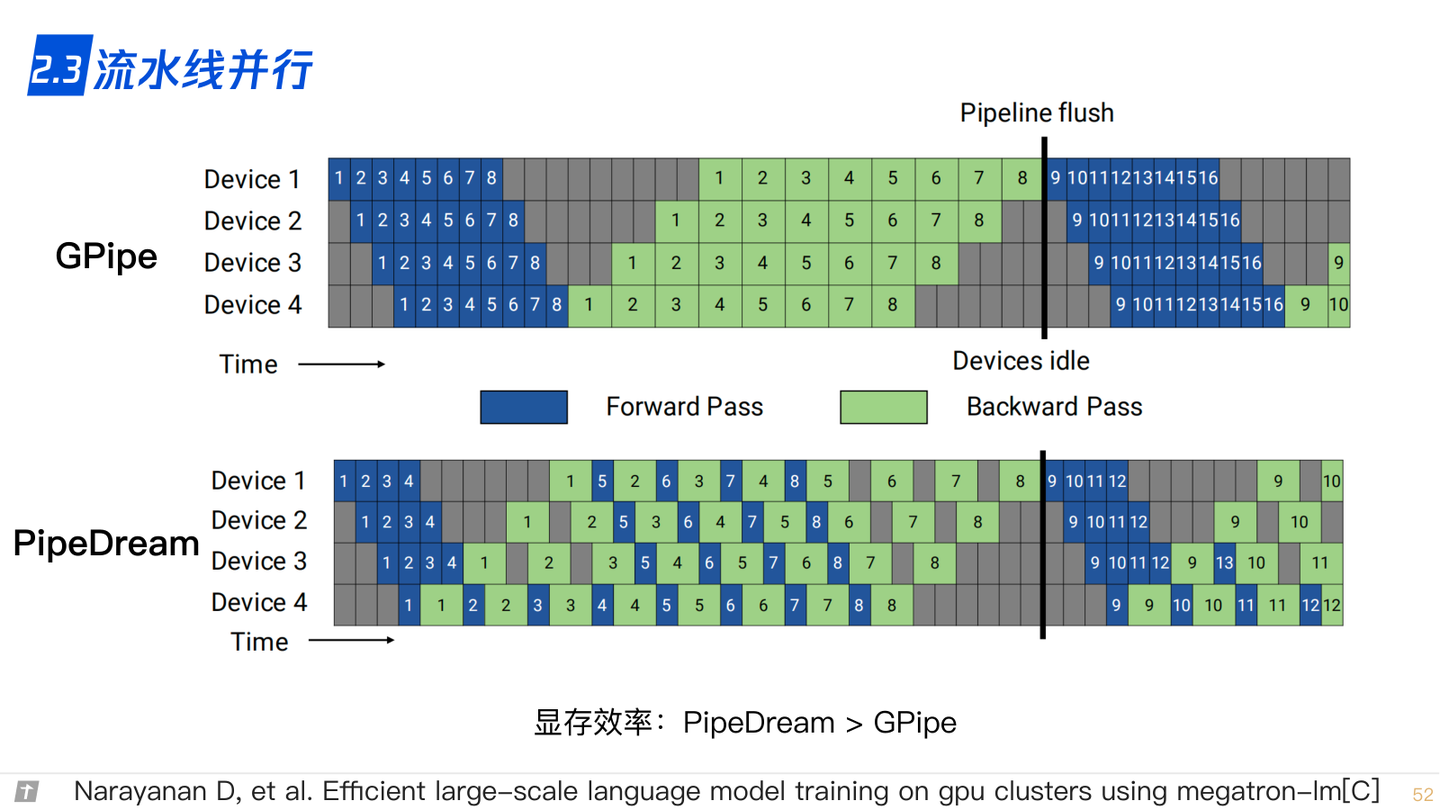
2.3 流水线并行
还有一种常用的实现分布式训练的方法谁流水线并行,这种系统通过算子内并行和算子间并行解决单设备内存不足的问题。
然而,这类系统的运行中,计算图中的下游设备(Downstream Device)需要长期持续处于空闲状态,等待上游设备(Upstream Device)的计算完成,才可以开始计算,这极大降低了设备的平均使用率。这种现象称为模型并行气泡(Model Parallelism Bubble)。
为了减少气泡,通常可以在训练系统中构建流水线。这种做法是将训练数据中的每一个小批次划分为多个微批次(Micro-Batch)。假设一个小批次有 D 个训练样本,将其划分为 M 个微批次,那么一个微批次就有 D / M 个数据样本。每个微批次依次进入训练系统,完成前向计算和反向计算,计算出梯度。每个微批次对应的梯度将会缓存,等到全部微批次完成,缓存的梯度会被加和,算出平均梯度(等同于整个小批次的梯度),完成模型参数的更新。

本例中,模型参数需要切分给 4 个设备存储。为了充分利用这 4 个设备,将小批次切分为两个微批次。假设 Fi,j 表示第 j 个微批次的第 i 个前向计算任务,Bi, j 表示第 j 个微批次的第 i 个反向计算任务。当设备 1 完成第一个微批次的前向计算后(表示为 F0,0),会将中间结果发送给设备 2,触发相应的前向计算任务(表示为F1,0)。与此同时,设备1也可以开始第二个微批次的前向计算任务(表示为 F0,1)。前向计算会在流水线的最后一个设备,即设备3,完成。
系统于是开始反向计算。设备 4 开始第 1 个微批次的反向计算任务(表示为 B3,0)。该任务完成后的中间结果会被发送给设备 3,触发相应的反向计算任务(表示为 B2,0)。与此同时,设备 4 会缓存对应第 1 个微批次的梯度,接下来开始第 2 个微批次计算(表示为 B3,1)。当设备 4 完成了全部的反向计算后,会将本地缓存的梯度进行相加(这里设备 4 相当于主进程,reduce 的操作由它汇总),并且除以微批次数量,计算出平均梯度,该梯度用于更新模型参数。
需要注意的是,计算梯度往往需要前向计算中产生的激活值。经典模型并行系统中会将激活值缓存在内存中,反向计算时就可以直接使用,避免重复计算。而在流水线训练系统中,由于内存资源紧张,前向计算中的激活值往往不会缓存,而是在反向计算中重新计算(Recomputation),也就是用计算换内存。
在使用流水线训练系统中,时常需要调试微批次的大小,从而达到最优的系统性能。当设备完成前向计算后,必须等到全部反向计算开始,在此期间设备会处于空闲状态。
可以看到上图中设备 1 在完成两个前向计算任务后,要等很长时间才能开始两个反向计算任务(等到其他设备前向和反向都计算完了才轮到它计算反向)。这其中的等待时间即被称为流水线气泡(Pipeline Bubble)。
为了减少设备的等待时间,一种常见的做法是尽可能地增加微批次的数量,从而让反向计算尽可能早开始。然而,使用非常小的微批次,可能会造成微批次中的训练样本不足,从而无法充分的利用起来硬件加速器中的海量计算核心。因此最优的微批次数量由多种因素(如流水线深度、微批次大小和加速器计算核心数量等)共同决定。
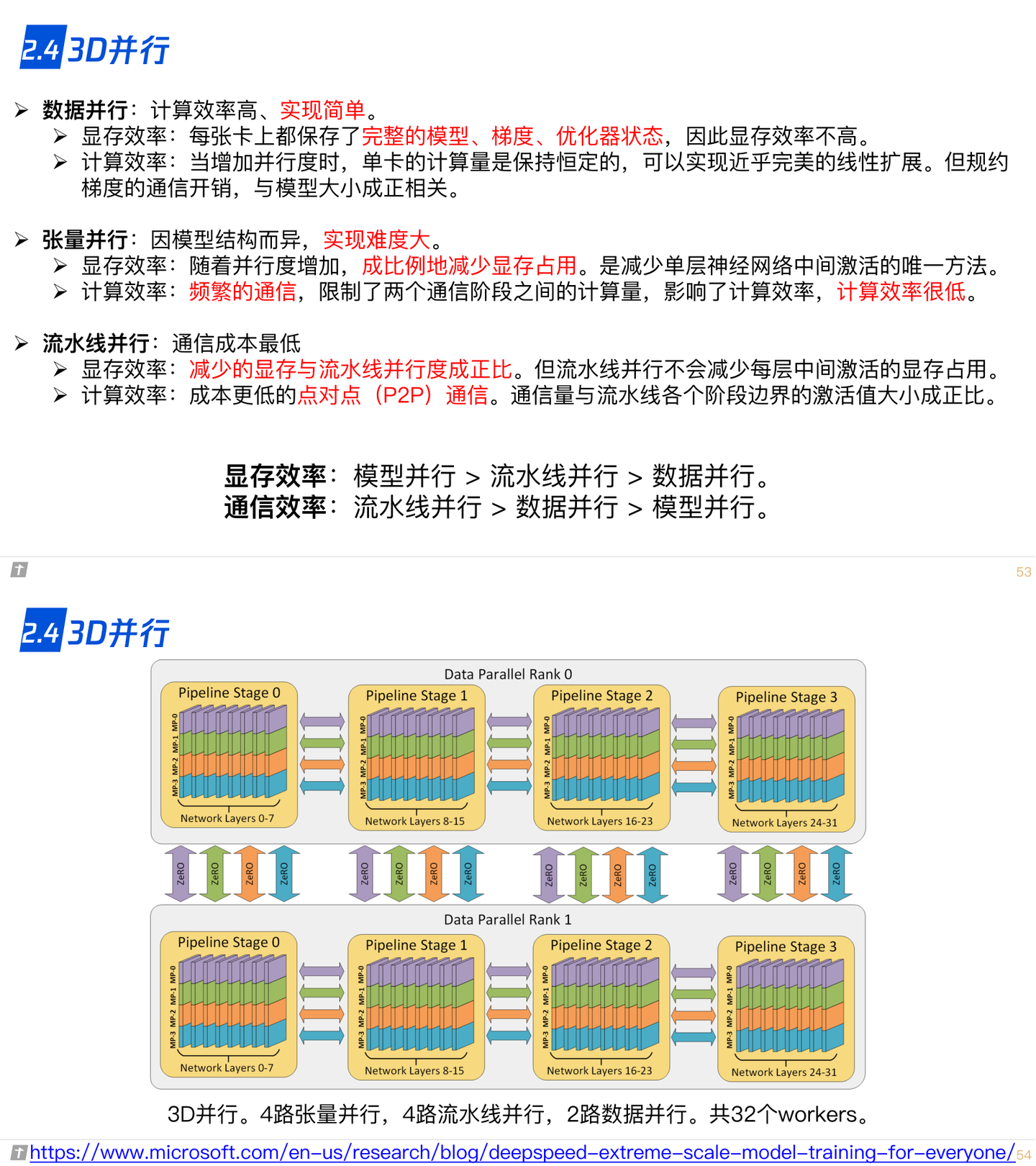
2.4 3D 并行
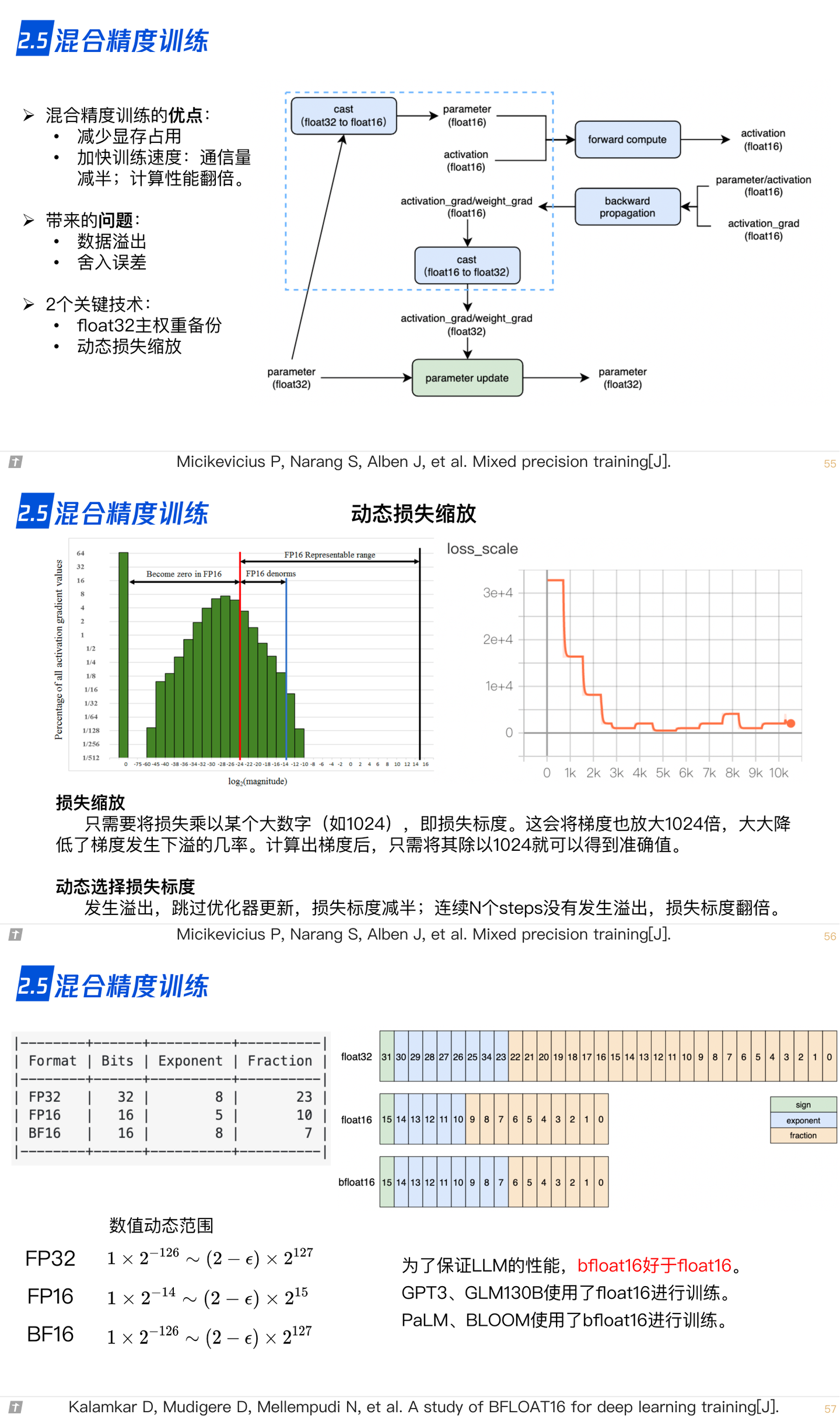
2.5 混合精度训练
在训练大型人工智能模型中,往往会同时面对算力不足和内存不足的问题。因此,需要混合使用数据并行和模型并行,这种方法被称为混合并行。
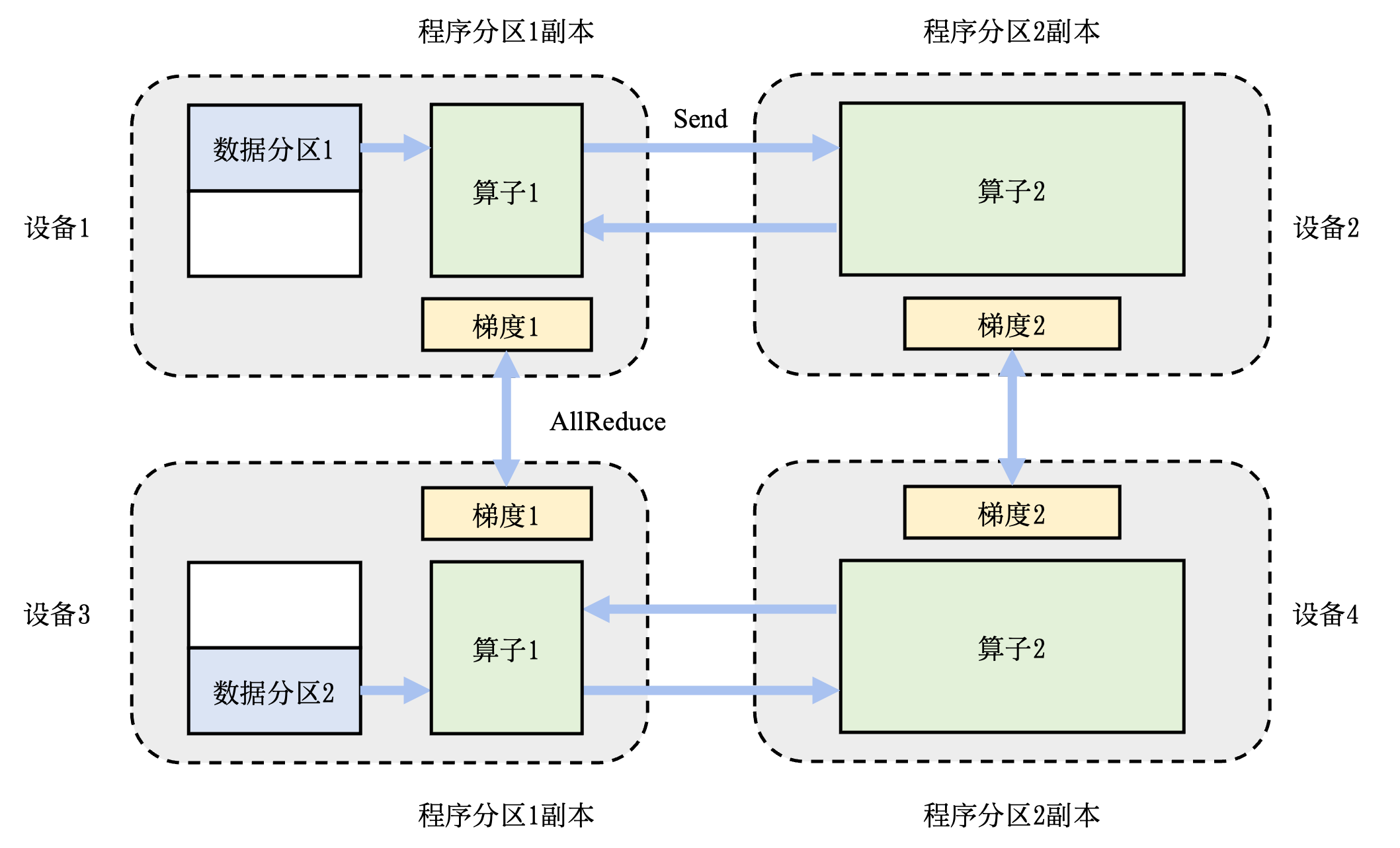
上图就是一个混合并行的例子,数据集被切分到不同的机器上执行,同样的数据集又会被切分到不同的设备上执行不同的计算。这里提供了一个由 4 个设备实现的混合并行的例子。在这个例子中,首先实现算子间并行解决训练程序内存开销过大的问题:该训练程序的算子 1 和算子 2 被分摊到了设备 1 和设备 2 上。进一步,通过数据并行添加设备 3 和设备 4,提升系统算力。为了达到这一点,对训练数据进行分区(数据分区 1 和数据分区 2),并将模型(算子 1 和算子 2,这里不一定是单个算子,可以是对计算图做拆分)分别复制到设备 3 和设备 4。在前向计算的过程中,设备 1 和设备 3 上的算子 1 副本同时开始,计算结果分别发送给设备 2 和设备 4 完成算子 2 副本的计算。在反向计算中,设备 2 和设备 4 同时开始计算梯度,本地梯度通过 AllReduce 操作进行平均。反向计算传递到设备 1 和设备 3 上的算子 1 副本结束。
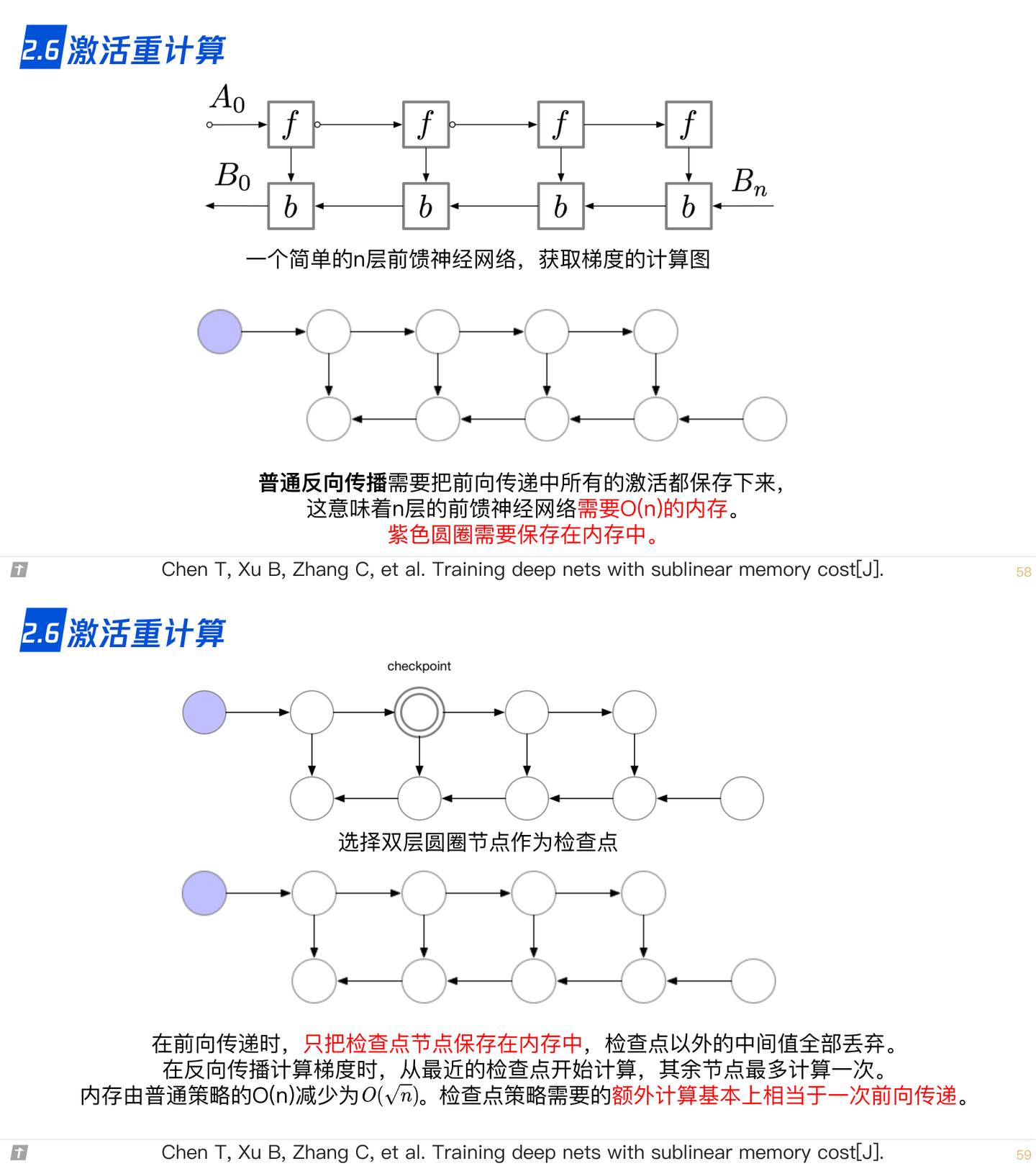
2.6 激活重计算
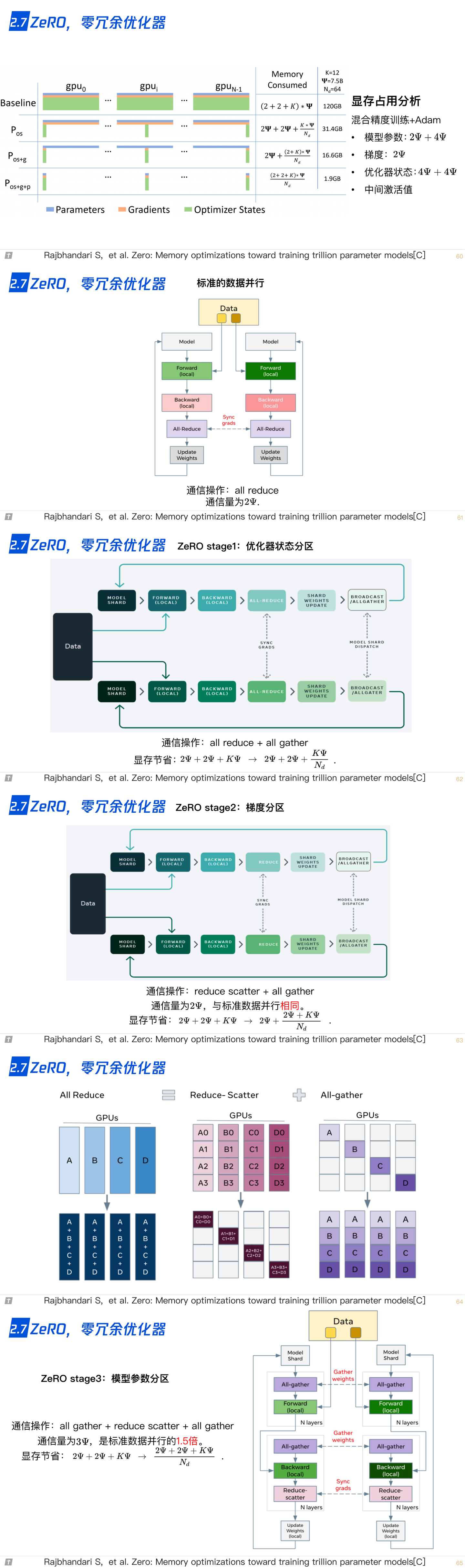
2.7 ZeRO,零冗余优化器
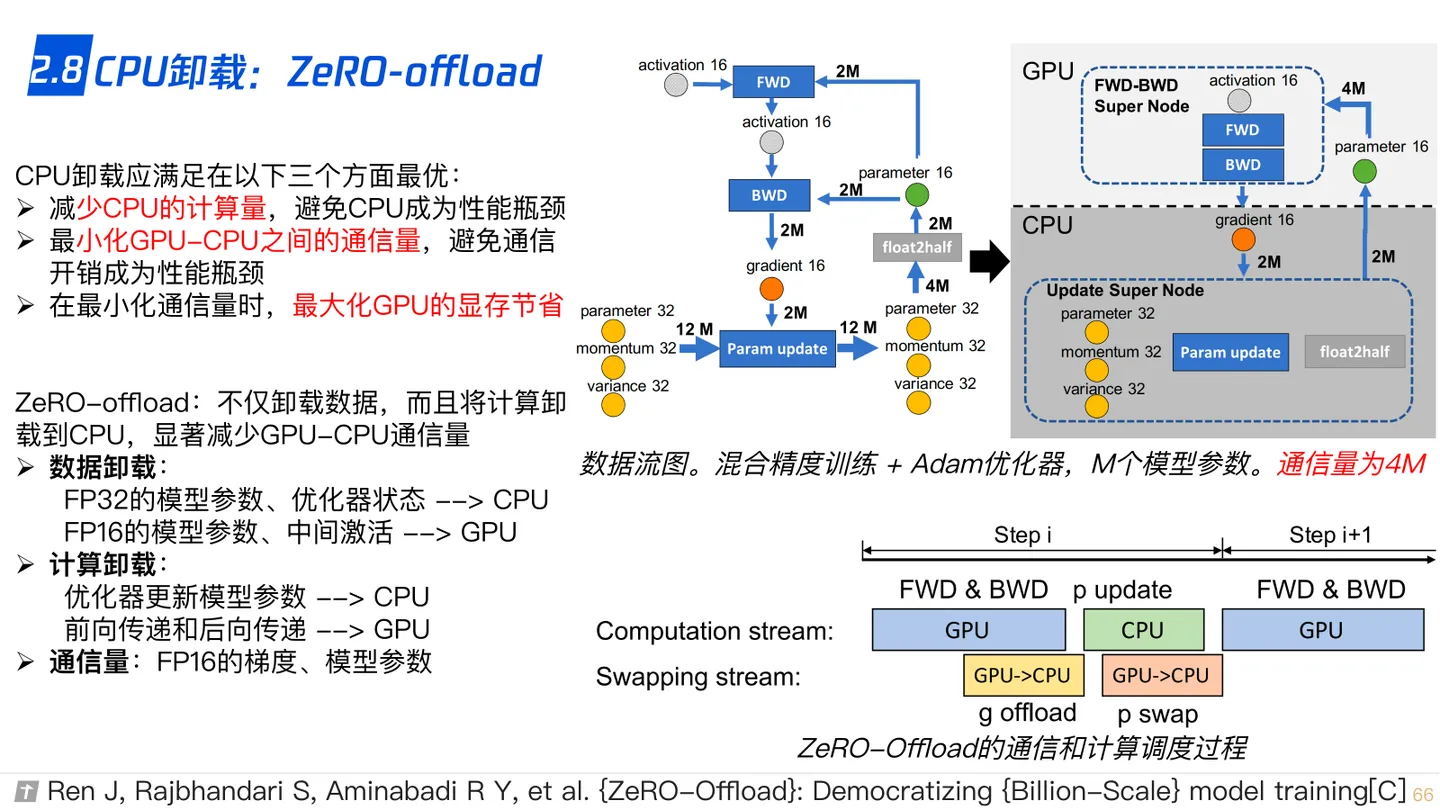
2.8 CPU-offload,ZeRO-offload
2.9 Flash Attention

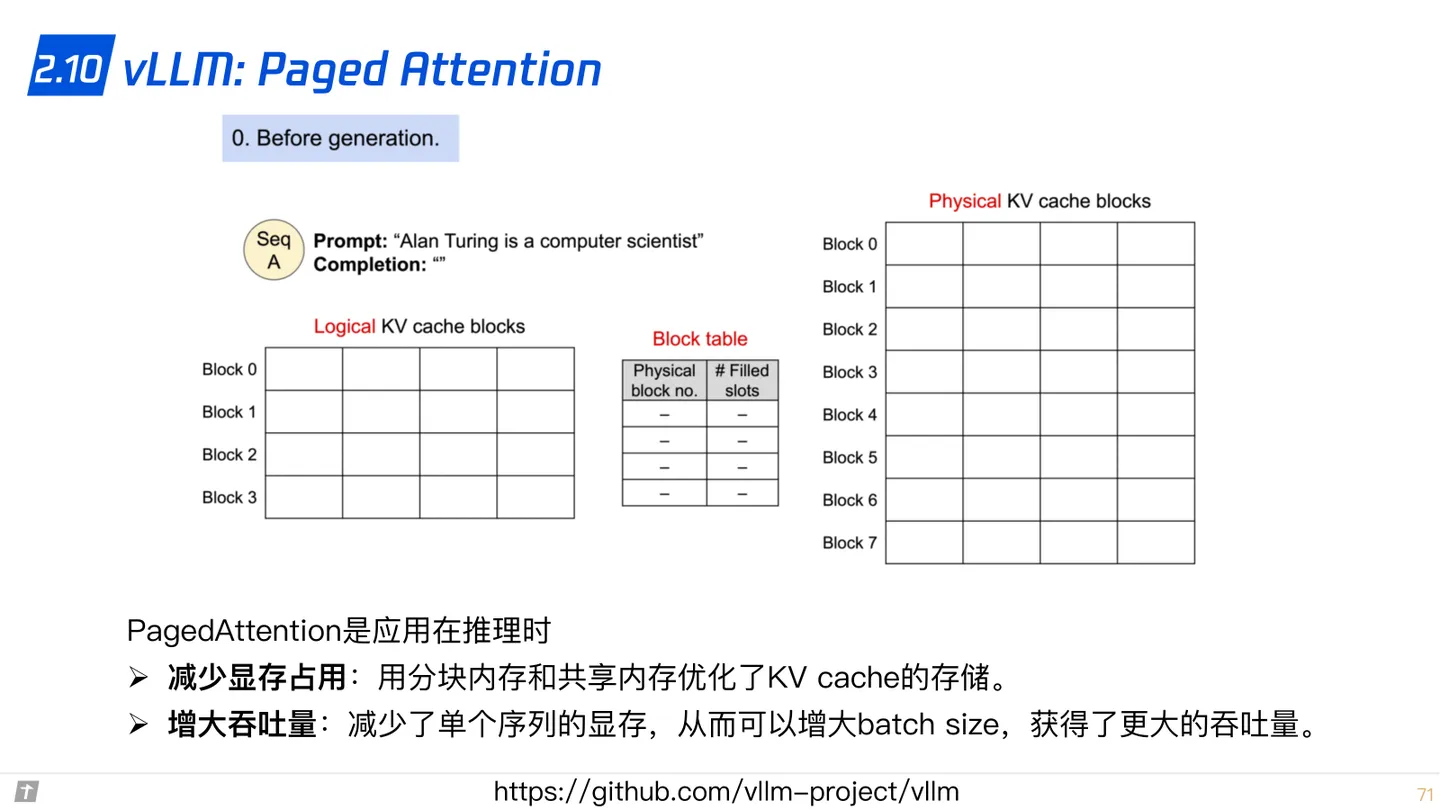
2.10 vLLM: Paged Attention
3. LLM 的参数高效微调
3.0 为什么进行参数高效微调?

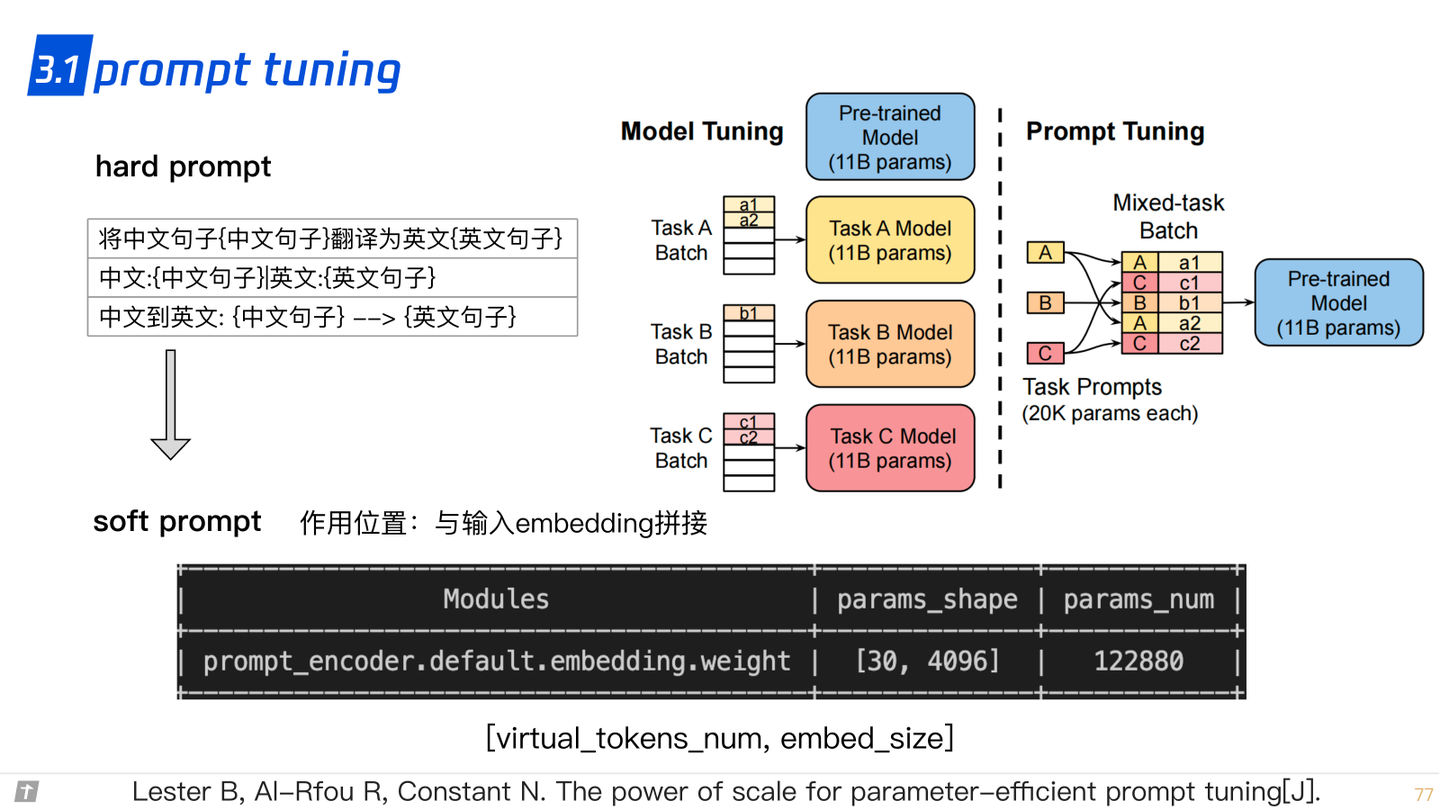
3.1 prompt tuning
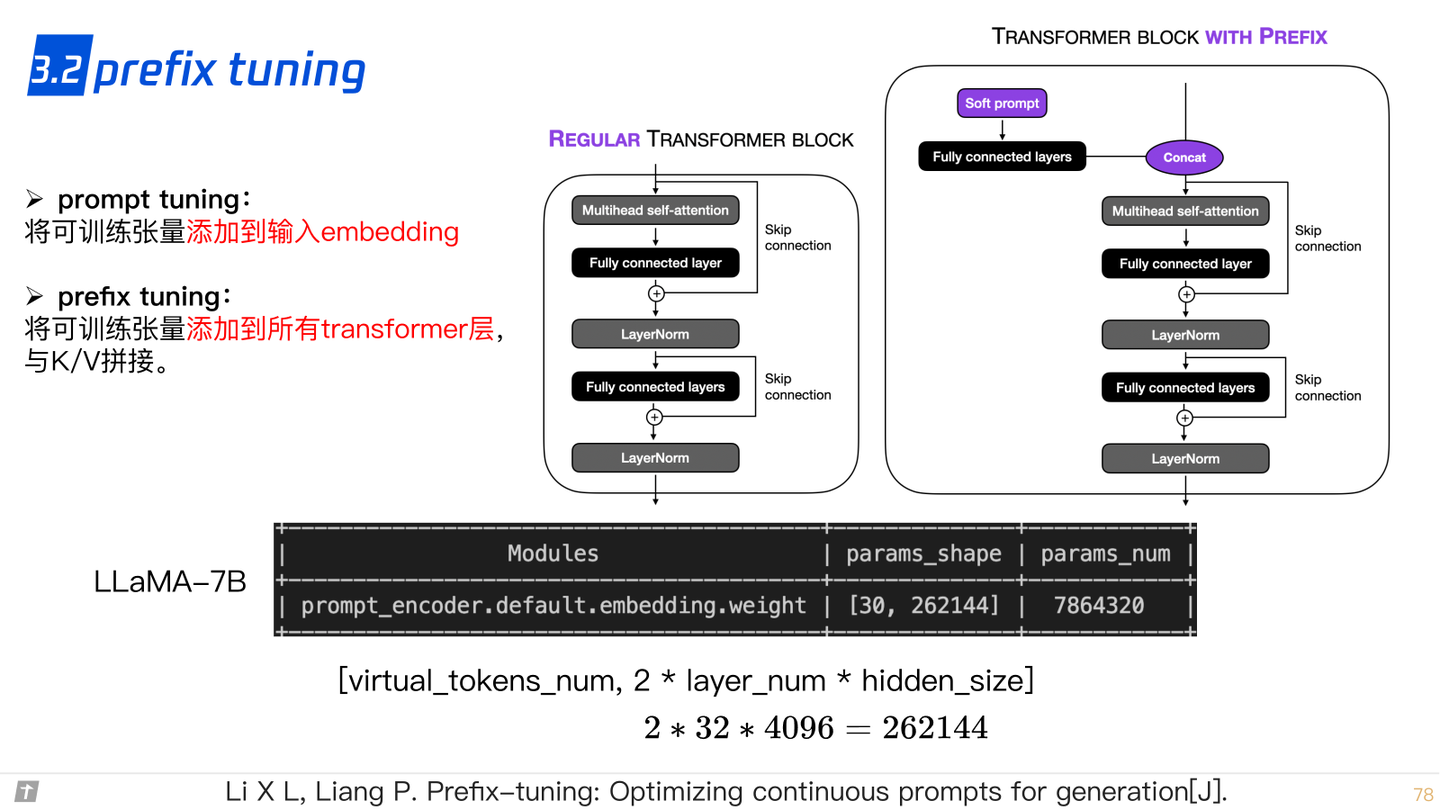
3.2 prefix tuning
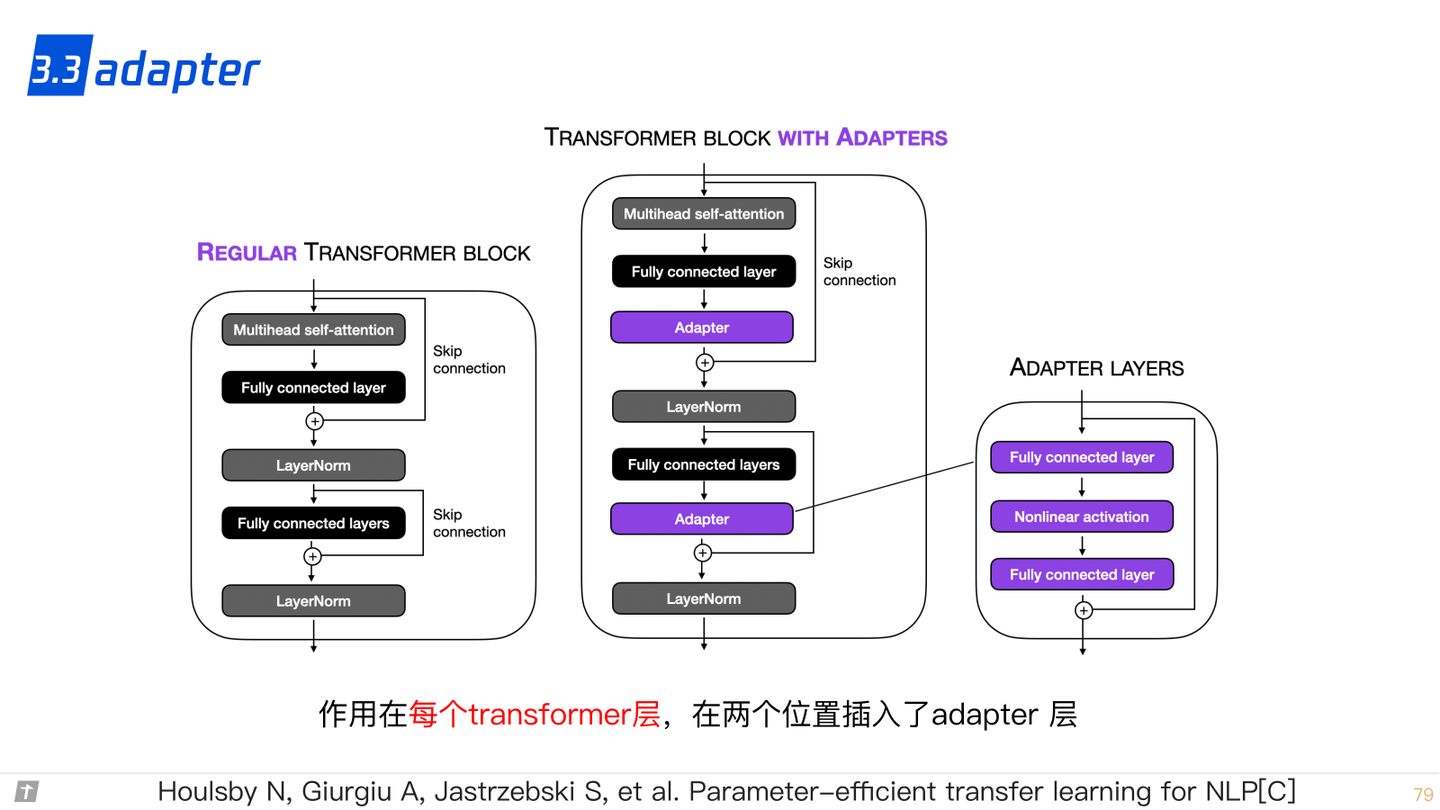
3.3 adapter
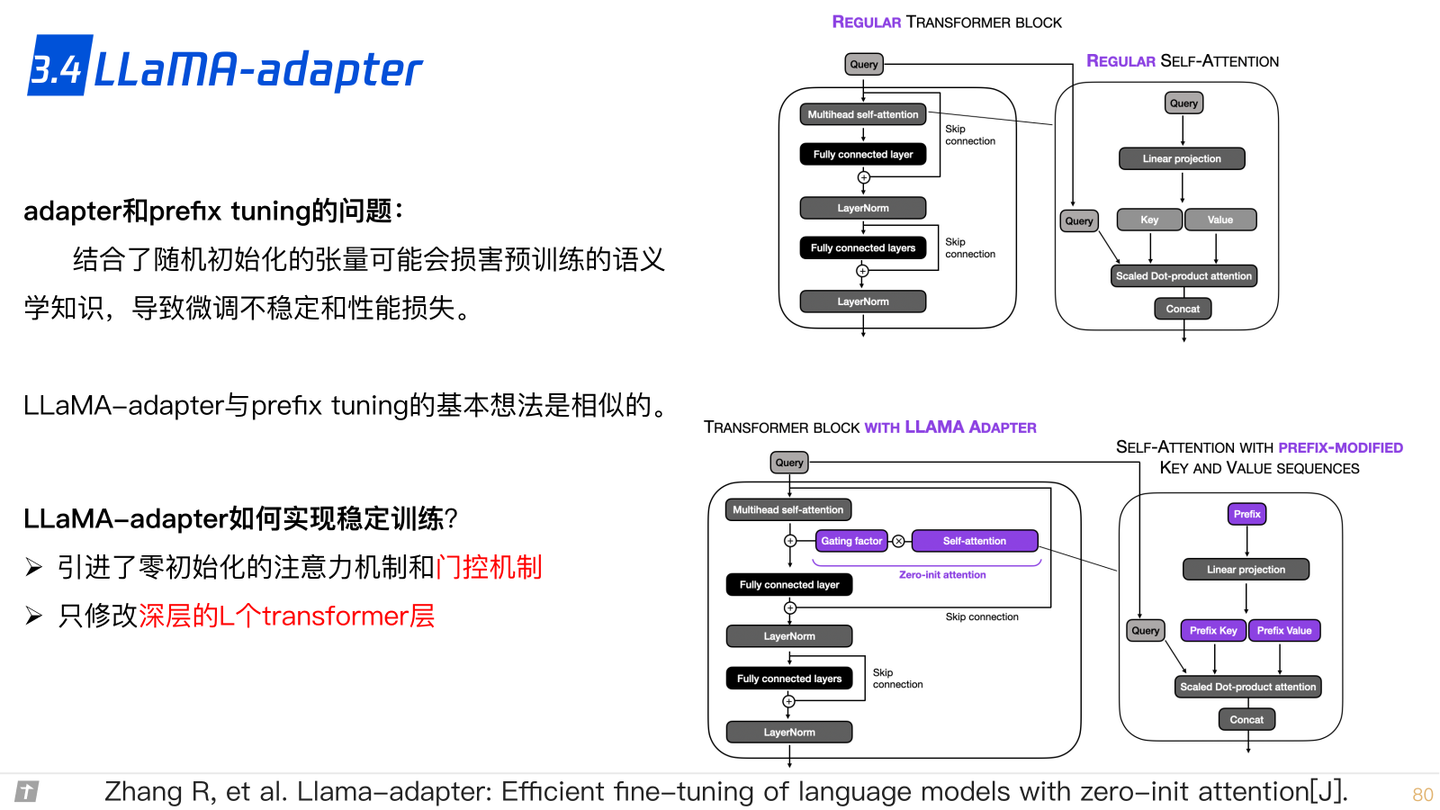
3.4 LLaMA adapter
3.5 LoRA
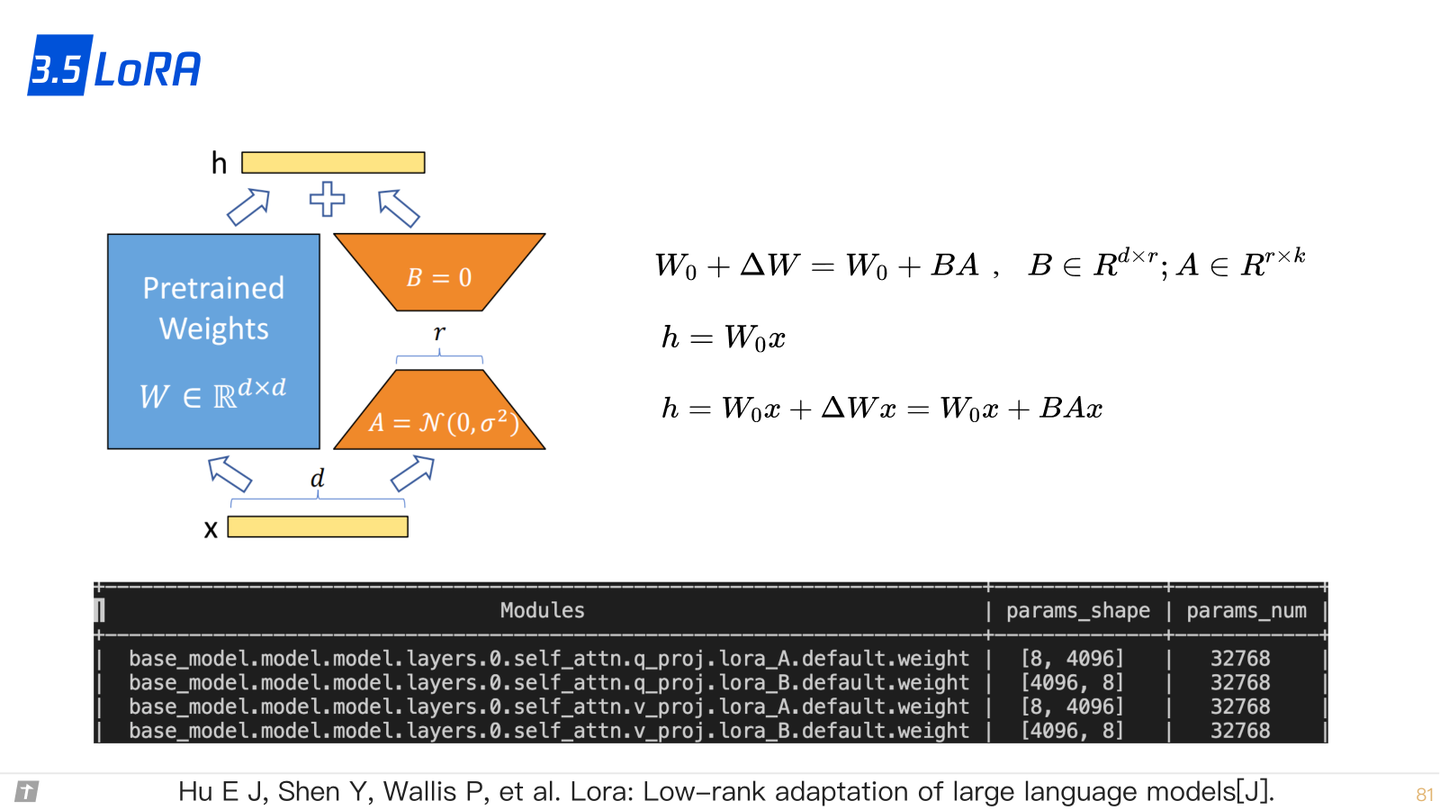
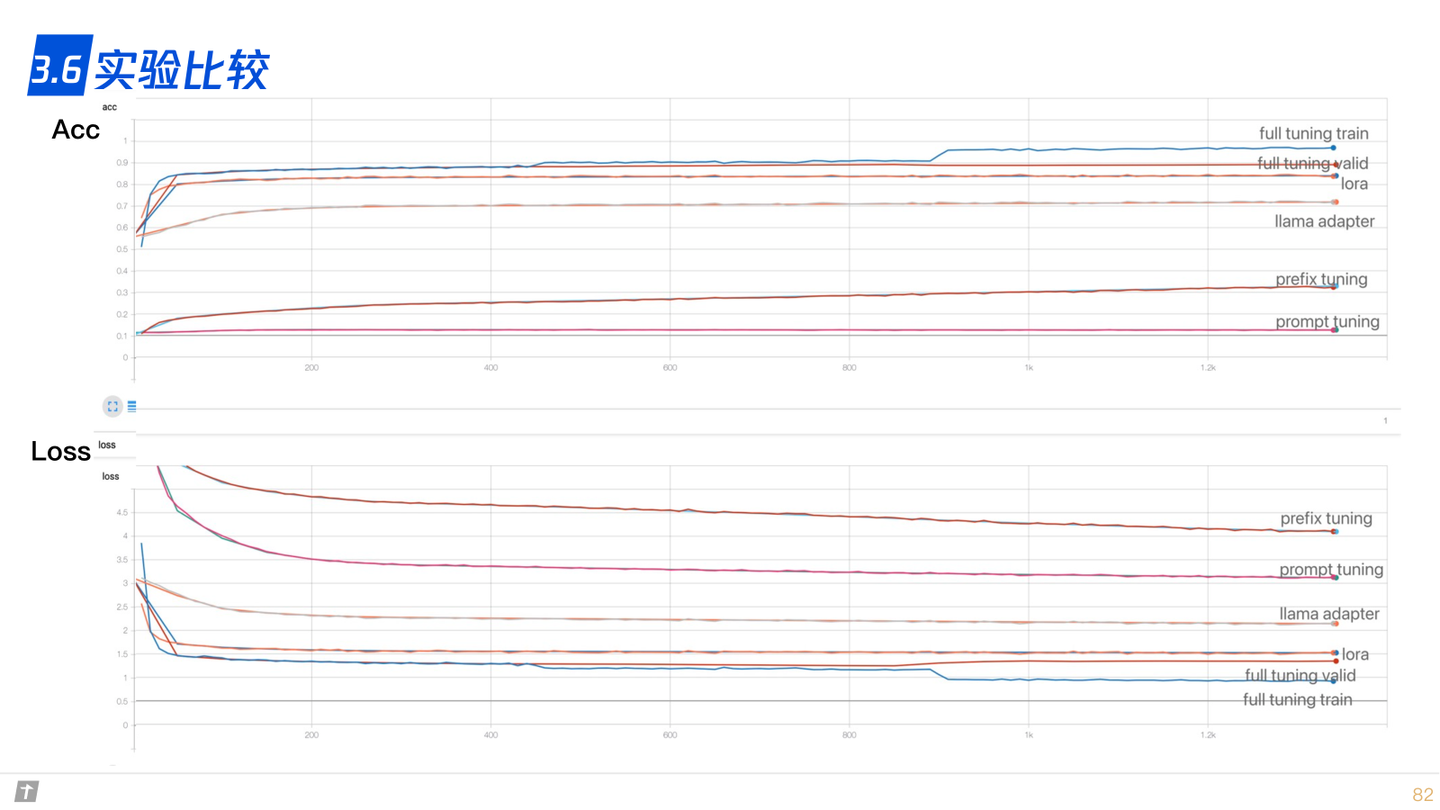
3.6 实验比较