本文首发至微信公众号:CVHub,不得以任何形式转载或售卖,仅供学习,违者必究!

Title: HuaTuo: Tuning LLaMA Model with Chinese Medical Knowledge
PDF: https://arxiv.org/pdf/2304.06975v1.pdf
Code: https://github.com/scir-hi/huatuo-llama-med-chinese
导读
在生物医学领域,LLM模型(如LLaMa,ChatGLM)因为缺乏一定的医学专业知识语料而表现不佳。该项目通过医学知识图谱和GPT3.5API构建了中文医学指令数据集,并对LLaMa模型进行了指令微调得到了一个针对医学领域的智能问诊模型HuaTuo,相比于未经过医学数据指令微调的原LLaMa而言,HuaTuo模型在智能问诊层面表现出色,可生成一些更为可靠的医学知识回答;与此同时,基于相同医学数据,该项目还训练了医疗版本的ChatGLM模型: ChatGLM-6B-Med,
除了华佗模型,该团队还即将发布扁鹊模型PienChueh(同为基于医学数据训练的大模型),欢迎大家届时使用体验。
引言
ChatGPT模型虽然表现出色,但毕竟不开源,开源社区已提供了许多平替方案,比如LLaMa等(7B,13B,30B,65B),其中7B具有70亿参数,训练成本最低,借助Colossal AI和Deep Speed大模型训练框架,也可以很好的平民化训练并针对性的用于解决特定业务场景下的问题。
不管是原始LLaMa,还是ChatGPT等其它大语言模型,它们在医疗领域的应用仍然存在一些问题。比如笔者前段时间问原始LLaMa,给它输入一段病情描述,让它输出病情诊断信息,它会给出一些非常简短且常规的回答,完全没回答到点子上;虽然在这一层面ChatGPT做的更好,回答的也更加详细,但更多的也是一些偏向于科普式的回答,并没有非常惊艳的效果。而经过专门医疗数据训练的Glass AI(链接:https://glass.health/ai)模型在智能诊断上表现极其出色,感兴趣的读者可自行注册体验(强烈推荐)。但由于Glass AI是一款已商业化的AI智能诊断模型,也并未开源。
由于医疗领域专业知识太多,而LLMs的一般领域知识往往无法满足这种专业化需求,如果直接用于智能诊断,极有可能导致诊断精度、药品推荐和医疗建议等方面的不准确性,甚至危及患者的生命。所以,将专业的医学领域知识,诊断案例数据输入到大模型进行专业化学习非常有必要。
目前,已经有一些方法尝试解决这个问题,但这些方法主要依赖于从人工交流中检索医学信息,容易出现人为错误。此外,LLMs通常只在英语语境下进行训练,这限制了它们在其他语言环境下的理解和响应能力,例如中文,因此它们在中国语境中的应用受到极大限制。
现有的方法主要采用ChatGPT进行数据辅助,将ChatGPT某一领域的知识有效蒸馏到较小的模型:比如Chatdoctor代表了将LLMs在生物医学领域的第一次尝试,通过调用ChatGPT API来生成一些医学语料数据并叠加一部分真实场景医患数据,来微调LLaMa;为了解决中文语境问题,DoctorGLM利用ChatGLM-6B作为基础模型,并用ChatDoctor数据集的中文翻译通过ChatGPT获取进行微调。这些模型出来的效果只能说还行,但距离真实落地还很远。毕竟通过未经过专门医学语料训练的ChatGPT获取的训练数据也是非常general的回答,对模型得不到质的提升。
本项目介绍了一种针对生物医学领域、专注于中文语言的LLM模型—HuaTuo(华驼)。为了保证模型在生物医学领域回答问题的准确性,研究人员通过从中文医学知识图谱CMeKG中提取相关的医学知识,生成多样的指令数据,以确保模型回答问题的事实正确性,并收集了超过8000条指令数据进行监督微调。该模型基于开源的LLaMa-7B基础模型,整合了CMeKG的结构化和非结构化医学知识,并利用基于知识的指令数据进行微调,使得模型具有较为丰富的医学领域专业知识,从而为智能诊断作出较为专业的回答。

HuaTuo Model
Base Model
LLaMA作为一个开源模型,具有7B到65B各个量级的模型;为了更快速高效的训练,作者采用LLaMA-7B作为HuaTuo的基础模型
Medical Knowledge
医学知识的种类包括:结构化医学知识和非结构化医学知识。结构化医学知识指的是医学知识图谱等形式化的知识,而非结构化医学知识则是如医学指南等的非形式化的知识。作者在这里使用了一个名为CMeKG的中文医学知识图谱,其中提供了关于疾病、药物、症状等的检索医学知识,目的是为了让大模型学习一些相关的专业医学知识。下表1展示了CMeKG知识库中的几个医学知识样例。

Knowledge-based Instruction Data
instruct-tuning是一种有助于大模型在zero-shot场景下表现出令人满意性能的tuning微调技术,但这需要有足够丰富的instruct以指导大模型学会理解instruct命令,并作出反馈,当然我们也可以根据上述医学知识可生成一系列instruct-input-output模式的数据如下表2所示。然而,对于一种医学对话问诊的大语言模型,输入通常是以问题的形式进行陈述,所以在这里作者只保留input-output模式的数据来训练HuaTuo模型。

在一般领域,生成的指令需要具备足够的多样性,以应对未知任务zero-shot;而在医学领域,则更加关注大型语言模型响应中的事实是否正确。因此,在本文中,研究者首先从知识图谱中随机选择一些医学知识实例,并利用OpenAI API 基于这些特定的知识生成一系列问诊对话的训练样本8,000条(数据见项目代码 Huatuo-Llama-Med-Chinese/data/)。如下表3所示

实验设置
Baselines
为了对比HuaTuo和其它基础模型的性能,作者进行了与三个基础模型的比较分析:
LLaMA作为HuaTuo的基础模型,作者选择了原生LLaMA-7B作为基础模型比较对象。Alpaca是LLaMA的一种instruct-tuning版本模型,拥有超过80,000个在通用领域中生成的训练样本。ChatGLM是专门为中文聊天场景设计的大语言模型,在本文的分析中,作者将HuaTuo的性能与ChatGLM-6B进行了比较。
Metrics
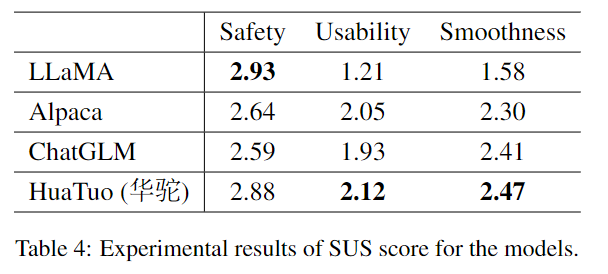
自然语言生成领域中常用的评估指标是Bleu和Rouge,作者在医疗问答任务中引入了新评估指标SUS,分别代表:安全性、可用性和流畅性。其中,安全性维度评估生成的响应是否存在误导用户、对用户健康构成危险的潜在因素,例如错误的药物建议;可用性维度评估生成的响应是否反映了医疗专业知识;流畅性维度则评估生成模型作为语言模型的能力。
实验结果
在这项研究中,作者构建了一个中文对话场景的医疗问诊测试集,并将HuaTuo与其他三个基准模型进行了比较。为了评估模型性能,本项目招募了五名具有医学背景的专业医师,在SUS三个维度上评估模型的安全性、可用性和流畅性。SUS刻度从1(不可接受)到3(好),其中2表示可接受的响应。平均SUS得分如下表4所示。尽管LLaMA获得了最高的安全得分,但其响应常常缺乏信息且重述问题,导致可用性得分低。另一方面,HuaTuo模型显着提高了知识可用性,同时没有太多地牺牲安全性。