代码:
https://github.com/PaddlePaddle/PaddleDetection/tree/develop
这里没讲怎么配环境,只讲自己怎么在docker里跑起来这个工程
1.整理自己的数据集
需要的格式是这样的

train里是训练的图片
val里是测试的图片
比例是训练:验证=8:2
暂时没留测试,自己想留也行
json文件长这样:
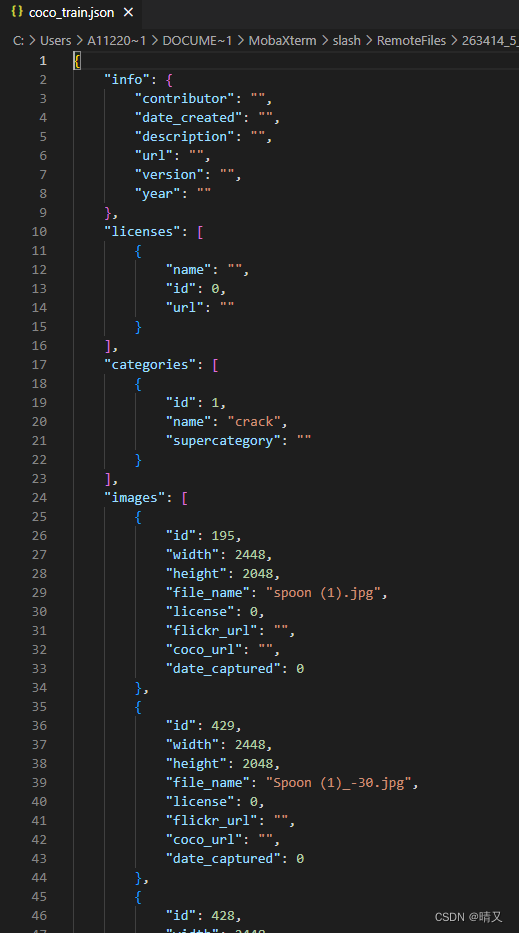
{
"info": {
"contributor": "",
"date_created": "",
"description": "",
"url": "",
"version": "",
"year": ""
},
"licenses": [
{
"name": "",
"id": 0,
"url": ""
}
],
"categories": [
{
"id": 1,
"name": "crack",
"supercategory": ""
}
],
"images": [
{
"id": 195,
"width": 2448,
"height": 2048,
"file_name": "spoon (1).jpg",
"license": 0,
"flickr_url": "",
"coco_url": "",
"date_captured": 0
},
{
"id": 429,
"width": 2448,
"height": 2048,
"file_name": "Spoon (1)_-30.jpg",
"license": 0,
"flickr_url": "",
"coco_url": "",
"date_captured": 0
},
(没复制完,和faster 框架的json文件格式一样其实)
2.把自己的数据集放到PP-YOLOE里训练
找到根目录
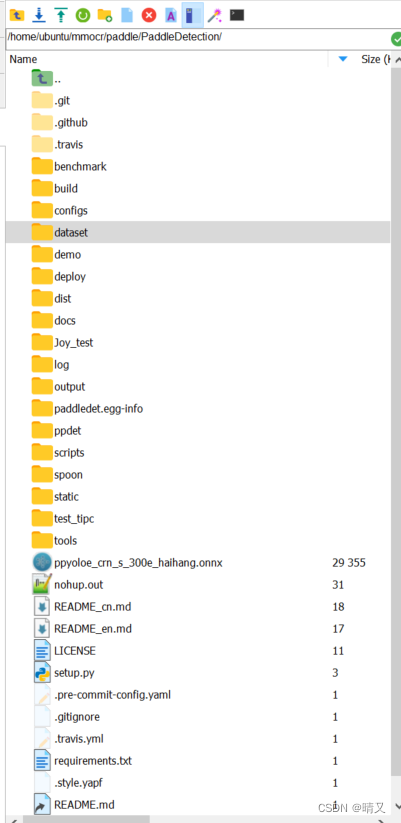
进到datasets文件夹里(自己放哪里都行,后面会用到这个路径,为了方便,可以和我写的一样)
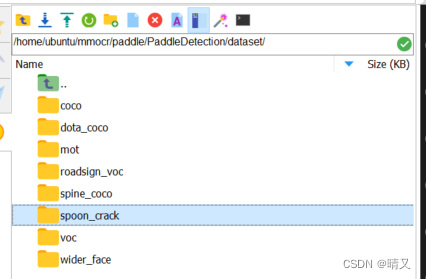
spoon_crack文件夹是我自己建立的
进入这个文件夹

就是刚刚准备好的数据集
2.准备开始训练
第一个文件在:PaddleDetection/configs/ppyoloe/下
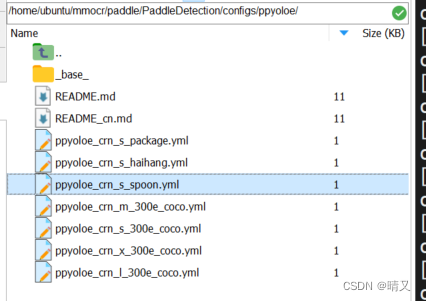
这是我自己新建的yml文件
看前缀可以看出来,用的是ppyoloe-s
打开后是这样的:
_BASE_: [
#下面挨个解析,这几个都得改动
'../datasets/coco_detection_spoon.yml',
'../runtime_spoon.yml',
'./_base_/optimizer_300e.yml',
'./_base_/ppyoloe_crn.yml',
'./_base_/ppyoloe_reader_haihang.yml',
]
log_iter: 100
snapshot_epoch: 10
# 可以自己事先建立好文件夹
weights: /spoon/ppyoloe_crn_s_spoon/model_final
pretrain_weights: https://paddledet.bj.bcebos.com/models/pretrained/CSPResNetb_s_pretrained.pdparams
depth_mult: 0.33
width_mult: 0.50
TrainReader:
batch_size: 32
LearningRate:
base_lr: 0.005
挨个解析:
① ‘…/datasets/coco_detection_spoon.yml’,
它是在PaddleDetection/configs/datasets/下
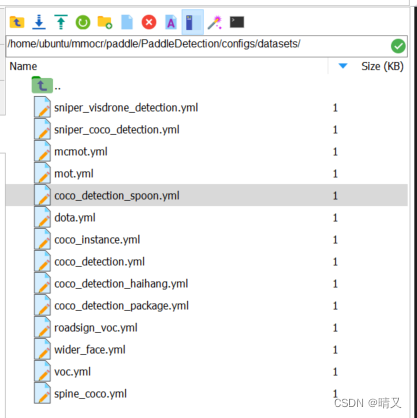
也是我自己重新写的
metric: COCO
#我只有一类:裂缝(crack)
num_classes: 1
TrainDataset:
!COCODataSet
# 写绝对路径比较靠谱。。就是刚刚的train的路径
image_dir: /paddle/paddle/PaddleDetection/dataset/spoon_crack/train
# 这里写json就行,因为这个路径=dataset_dir/anno_path,所以下面anno_path写全就行
anno_path: coco_train.json
# 这里写全路径
dataset_dir: /paddle/paddle/PaddleDetection/dataset/spoon_crack
# 这里不知道啥意思 没改动
data_fields: ['image', 'gt_bbox', 'gt_class', 'is_crowd']
EvalDataset:
!COCODataSet
# 和上面一样
image_dir: /paddle/paddle/PaddleDetection/dataset/spoon_crack/val
anno_path: coco_val.json
dataset_dir: /paddle/paddle/PaddleDetection/dataset/spoon_crack
TestDataset:
!ImageFolder
# 和上面一样
anno_path: coco_val.json # also support txt (like VOC's label_list.txt)
dataset_dir: /paddle/paddle/PaddleDetection/dataset/spoon_crack # if set, anno_path will be 'dataset_dir/anno_path'
②’…/runtime_spoon.yml’,
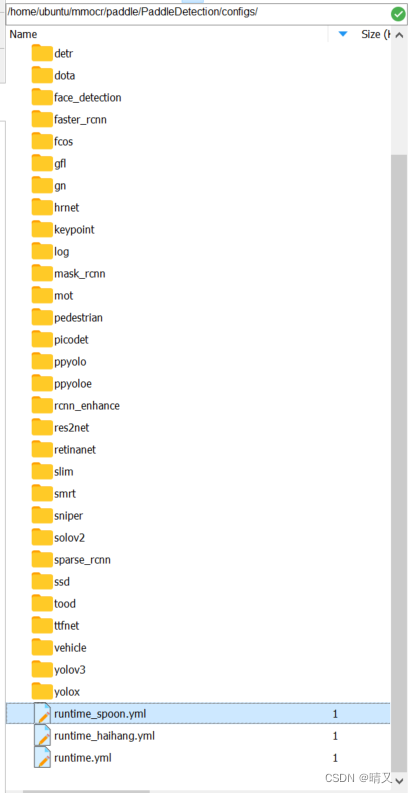
第二个文件在这里,也是自己建立的
use_gpu: true
use_xpu: false
log_iter: 20
# 暂时能看懂的就是这里,可以自己提前把文件夹建立好
save_dir: /paddle/paddle/PaddleDetection/spoon/ppyoloe/output
snapshot_epoch: 1
print_flops: false
# Exporting the model
export:
post_process: True # Whether post-processing is included in the network when export model.
nms: True # Whether NMS is included in the network when export model.
benchmark: False # It is used to testing model performance, if set `True`, post-process and NMS will not be exported.
③’./base/optimizer_300e.yml’,
# 改epoch
epoch: 300
LearningRate:
base_lr: 0.025
schedulers:
- !CosineDecay
max_epochs: 360
- !LinearWarmup
start_factor: 0.
epochs: 5
OptimizerBuilder:
optimizer:
momentum: 0.9
type: Momentum
regularizer:
factor: 0.0005
type: L2
暂时只改了epoch参数
④’./base/ppyoloe_crn.yml’,
architecture: YOLOv3
norm_type: sync_bn
use_ema: true
ema_decay: 0.9998
YOLOv3:
backbone: CSPResNet
neck: CustomCSPPAN
yolo_head: PPYOLOEHead
post_process: ~
CSPResNet:
layers: [3, 6, 6, 3]
channels: [64, 128, 256, 512, 1024]
return_idx: [1, 2, 3]
use_large_stem: True
CustomCSPPAN:
out_channels: [768, 384, 192]
stage_num: 1
block_num: 3
act: 'swish'
spp: true
PPYOLOEHead:
fpn_strides: [32, 16, 8]
grid_cell_scale: 5.0
grid_cell_offset: 0.5
static_assigner_epoch: 100
use_varifocal_loss: True
loss_weight: {
class: 1.0, iou: 2.5, dfl: 0.5}
static_assigner:
name: ATSSAssigner
topk: 9
assigner:
name: TaskAlignedAssigner
topk: 13
alpha: 1.0
beta: 6.0
nms:
name: MultiClassNMS
nms_top_k: 1000
keep_top_k: 100
score_threshold: 0.01
nms_threshold: 0.6
这个我没改动
⑤’./base/ppyoloe_reader_haihang.yml’,
worker_num: 4
eval_height: &eval_height 640
eval_width: &eval_width 640
eval_size: &eval_size [*eval_height, *eval_width]
TrainReader:
sample_transforms:
- Decode: {
}
- RandomDistort: {
}
# 如果你的图片刚开始大小不一样,就加个resize,如果不一样,好像把这个注掉就行,我的图片不一样大,我就加上了resize
- Resize: {
target_size: [608, 608], keep_ratio: False, interp: 2}
- RandomExpand: {
fill_value: [123.675, 116.28, 103.53]}
#- RandomCrop: {}
#- RandomFlip: {}
batch_transforms:
- BatchRandomResize: {
target_size: [320, 352, 384, 416, 448, 480, 512, 544, 576, 608, 640, 672, 704, 736, 768], random_size: True, random_interp: True, keep_ratio: False}
- NormalizeImage: {
mean: [0.485, 0.456, 0.406], std: [0.229, 0.224, 0.225], is_scale: True}
- Permute: {
}
- PadGT: {
}
batch_size: 20
shuffle: true
drop_last: true
use_shared_memory: true
collate_batch: true
EvalReader:
sample_transforms:
- Decode: {
}
- Resize: {
target_size: *eval_size, keep_ratio: False, interp: 2}
- NormalizeImage: {
mean: [0.485, 0.456, 0.406], std: [0.229, 0.224, 0.225], is_scale: True}
- Permute: {
}
batch_size: 2
TestReader:
inputs_def:
image_shape: [3, *eval_height, *eval_width]
sample_transforms:
- Decode: {
}
- Resize: {
target_size: *eval_size, keep_ratio: False, interp: 2}
- NormalizeImage: {
mean: [0.485, 0.456, 0.406], std: [0.229, 0.224, 0.225], is_scale: True}
- Permute: {
}
batch_size: 1
改动了resize那里
3.开始训练,在这一层目录下:
python -m paddle.distributed.launch --gpus 0 tools/train.py -c configs/ppyoloe/ppyoloe_crn_s_spoon.yml --amp

或者后台跑:
nohup python -u -m paddle.distributed.launch --gpus 0 tools/train.py -c configs/ppyoloe/ppyoloe_crn_s_spoon.yml --amp &
结果:
