深入理解GPT-2计算掩码自注意力过程,了解GPT-3工作原理
从GPT-2到GPT-3的发展思路是逐渐提高模型规模、性能和通用性,同时解决先前版本的一些限制。以下是这一发展过程的主要思路和关键点:
- 逐步提高模型规模:
- GPT-2: GPT-2是OpenAI首次推出的基于Transformer的语言模型。它采用了1.5亿个参数,是当时规模较大的模型之一。然而,由于担心滥用,OpenAI最初不公开发布了其最大规模版本。
- GPT-3: 在GPT-2的基础上,OpenAI进一步提高了模型的规模。GPT-3的最大版本(GPT-3.5-turbo)拥有1750亿个参数,比GPT-2大约10倍,成为迄今为止最大规模的语言模型之一。这使得GPT-3具有更高的自然语言处理能力。
- 增加通用性:
- 更广泛的应用: GPT-3的目标是成为通用的自然语言处理模型,可以应用于各种任务,而不仅仅是文本生成。这一目标使GPT-3在问答、对话、文本生成、翻译等多个任务上都能表现出色。
- 零样本学习: GPT-3引入了零样本学习的能力,这意味着它可以在未经过特定任务训练的情况下执行各种任务。这一特性使GPT-3更具通用性,能够快速适应新任务。
- 解决滥用问题:
- 加强安全性: 由于担心滥用,特别是在自动文本生成方面,OpenAI采取了一些安全措施。他们限制了模型的访问,并审查了使用API的应用程序,以减少不适当的内容生成。
- 迭代改进: 随着发布和使用,OpenAI不断改进GPT-3的安全性,以减少可能的滥用风险。
总的来说,从GPT-2到GPT-3的发展思路是不断提高模型规模、性能和通用性,同时关注滥用问题,以确保该技术的道德和社会责任。这一发展过程代表了深度学习自然语言处理领域的快速发展和创新。
之前的文章已经介绍了GPT以及GPT2的总体情况,本文重点介绍GPT-2计算掩码自注意力的详细过程,了解GPT-3的工作原理,并对一些常见的语言模型应用进行介绍。
图解Self-Attention
之前的文章中,我们使用如下图片来展示如何在一个层中使用 Self-Attention,这个层正在处理单词it。

在这一节,我们会详细介绍如何实现这一点。请注意,我们会讲解清楚每个单词都发生了什么。这就是为什么我们会展示大量的单个向量。而实际的代码实现,是通过巨大的矩阵相乘来完成的。但在这里,我们把重点放在词汇层面上。
图解 Self-Attention(without masking)
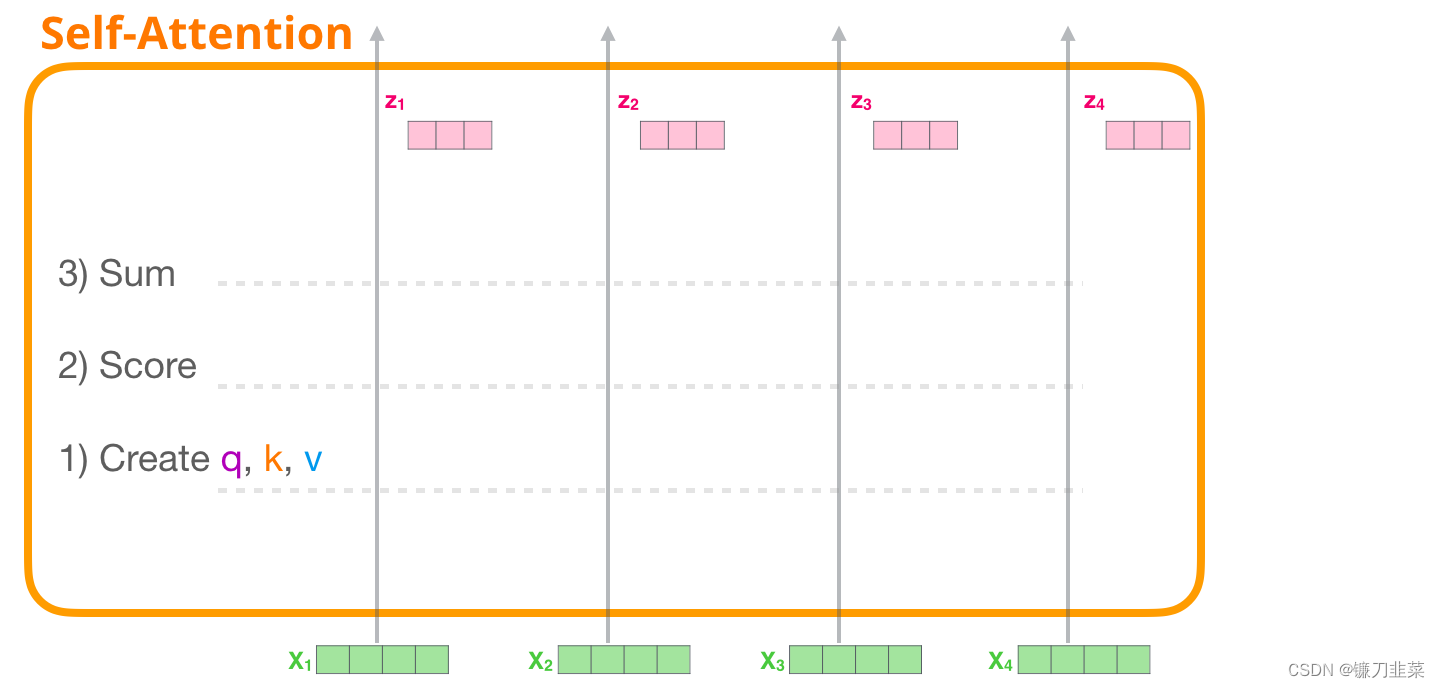
首先,我们介绍原始的Self-Attention,它被用在 Encoder 模块中进行计算。以一个简单的 Transformer为例,它一次只能处理 4个token。
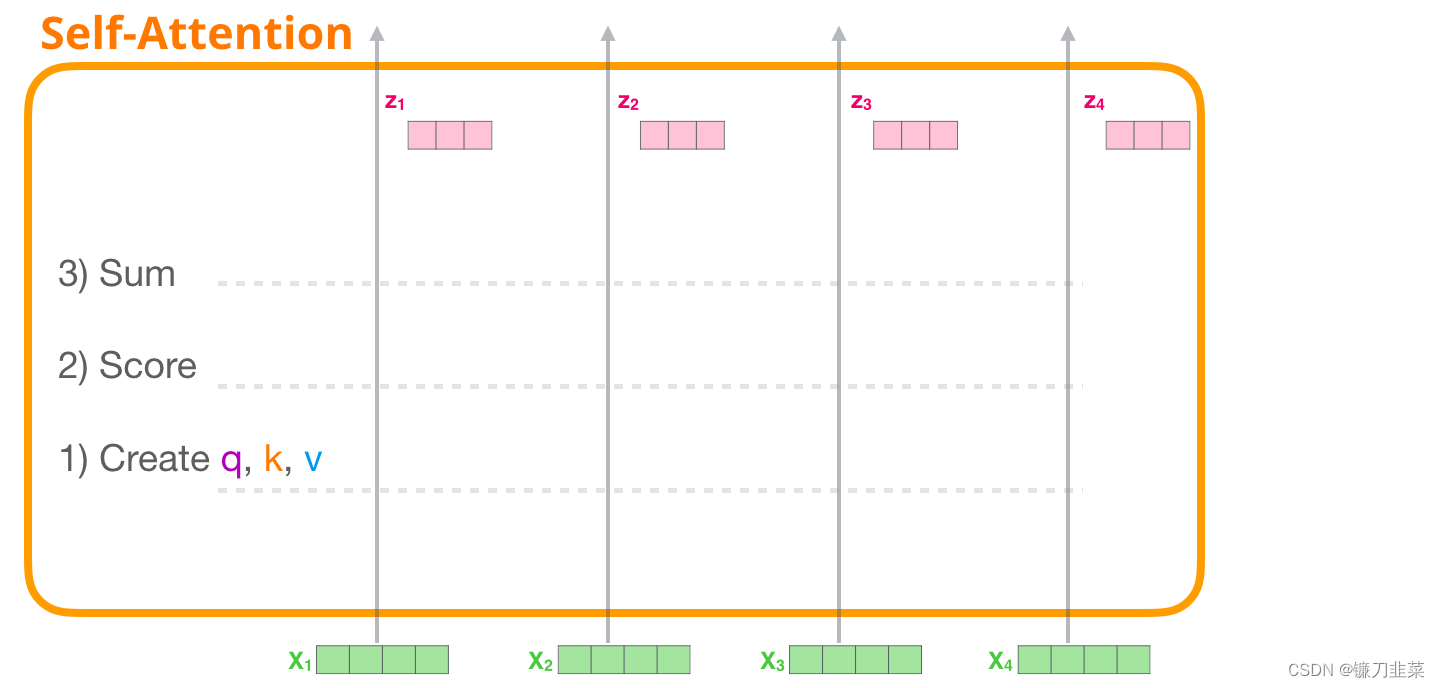
Self-Attention 主要通过 3 个步骤来实现:
- 为每个路径(path)创建 Query、Key、Value 矩阵。
- 对于每个输入的token,使用它的Query 向量为所有其他的Key 向量进行打分。
- 将Value 向量乘以它们对应的分数后求和。
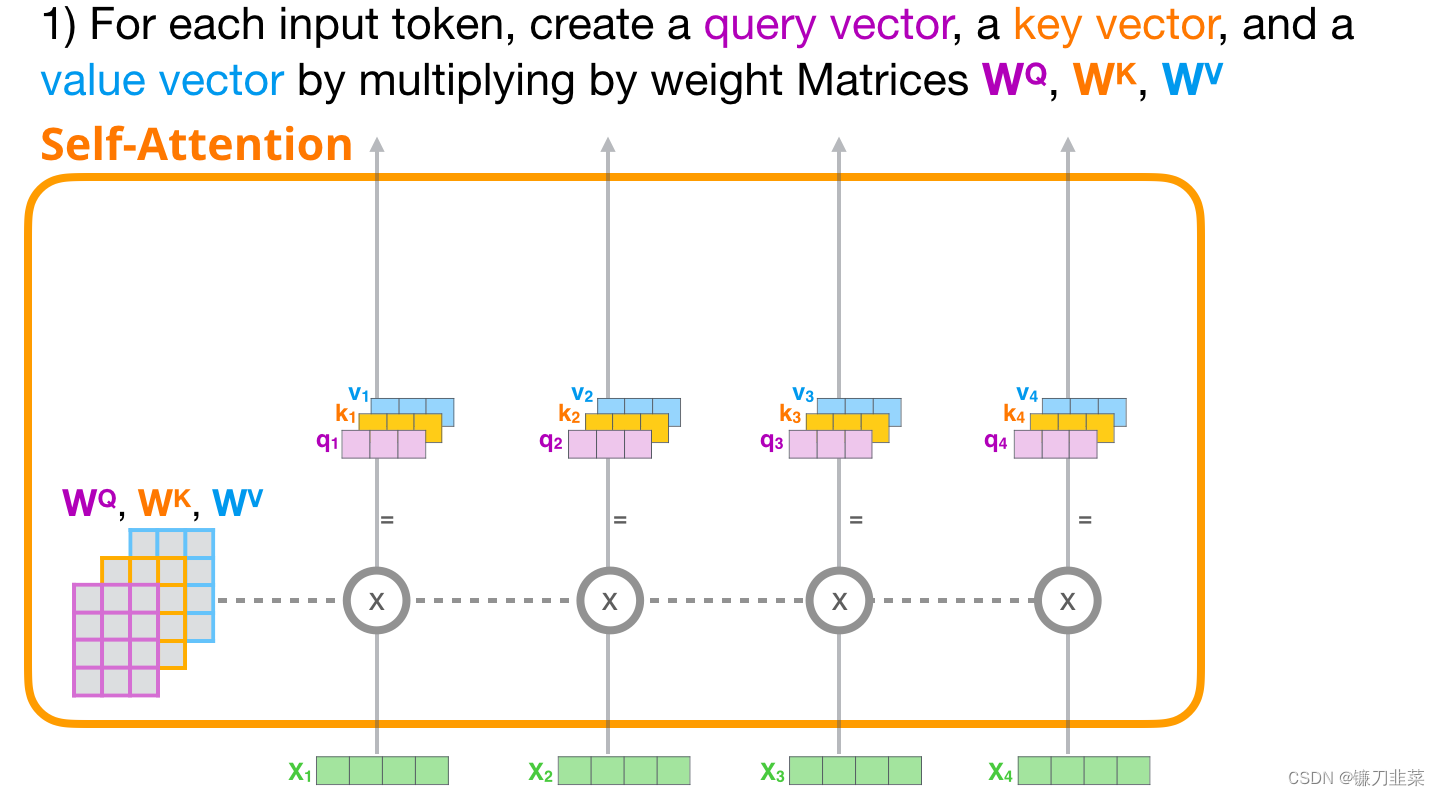
1. 创建Query、Key和Value向量
首先关注第一条路径。我们会使用它的Query 向量,并比较所有的Key 向量。这会为每个Key 向量产生一个分数。Self-Attention 的第一步是为每个 token 的路径计算 3 个向量。也就是说,对于每个输入单词,分别与权重矩阵 W Q W^Q WQ、 W K W^K WK、 W V W^V WV相乘,得到一个查询向量(query vector)、关键字向量(key vector)、数值向量(value vector),如下图所示:
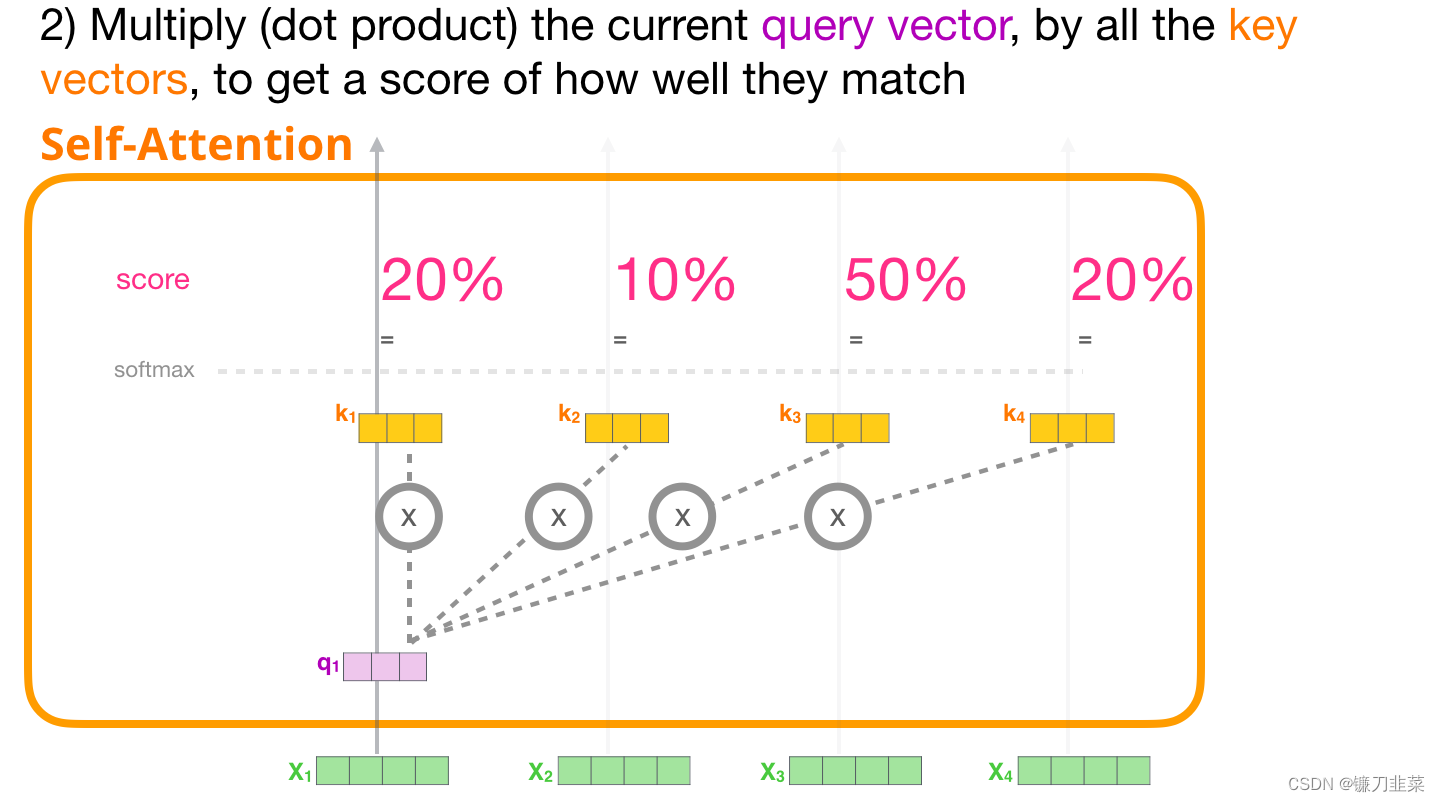
2. 计算分数
现在我们有了这些向量,我们只对步骤 2 使用Query 向量和Value 向量。因为我们关注的是第一个token 的向量,我们将第一个token 的 Query 向量和其他所有的token 的 Key 向量相乘,得到4 个token 的分数。
3. 计算和
现在可以将这些分数和Value 向量相乘。在我们将它们相加后,一个具有高分数的Value 向量会占据结果向量的很大一部分。
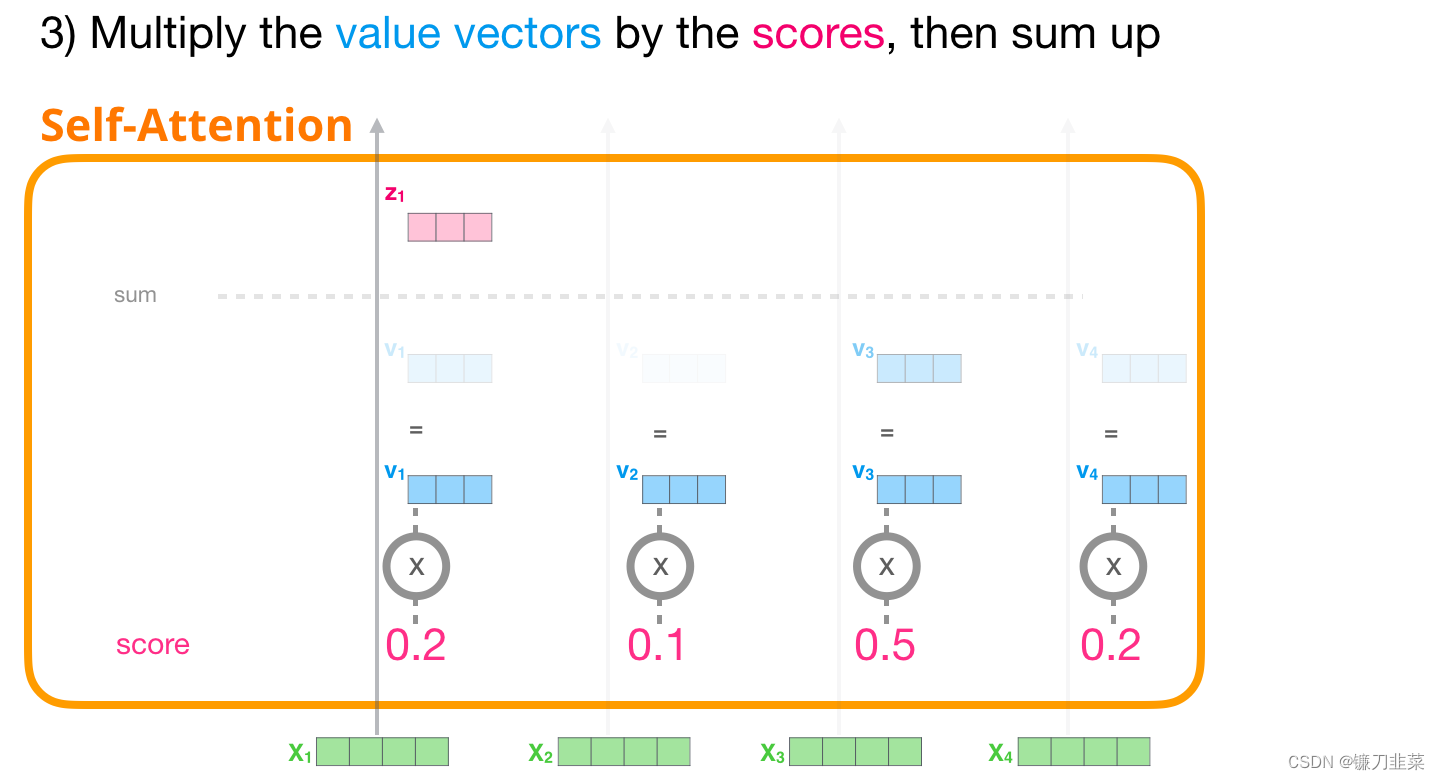
分数越低,Value 向量就越透明。这是为了说明,乘以一个小的数值会稀释 Value 向量。
如果我们对每个路径都执行相同的操作,我们会得到一个向量,可以表示每个 token,其中包含每个 token 合适的上下文信息。这些向量会输入到 Transformer 模块的下一个子层(前馈神经网络)。
图解 Masked Self-Attention
现在,我们已经了解了 Transformer 的 Self-Attention 步骤,现在继续研究 masked self-attention。Masked self-attention 和 self-attention 是相同的,除了第 2 个步骤。假设模型只有 2 个 token 作为输入,我们正在观察(处理)第二个 token。在这种情况下,最后 2 个 token 是被屏蔽(masked)的。所以模型会干扰评分的步骤。它基本上总是把未来的 token 评分为 0,因此模型不能看到未来的词:
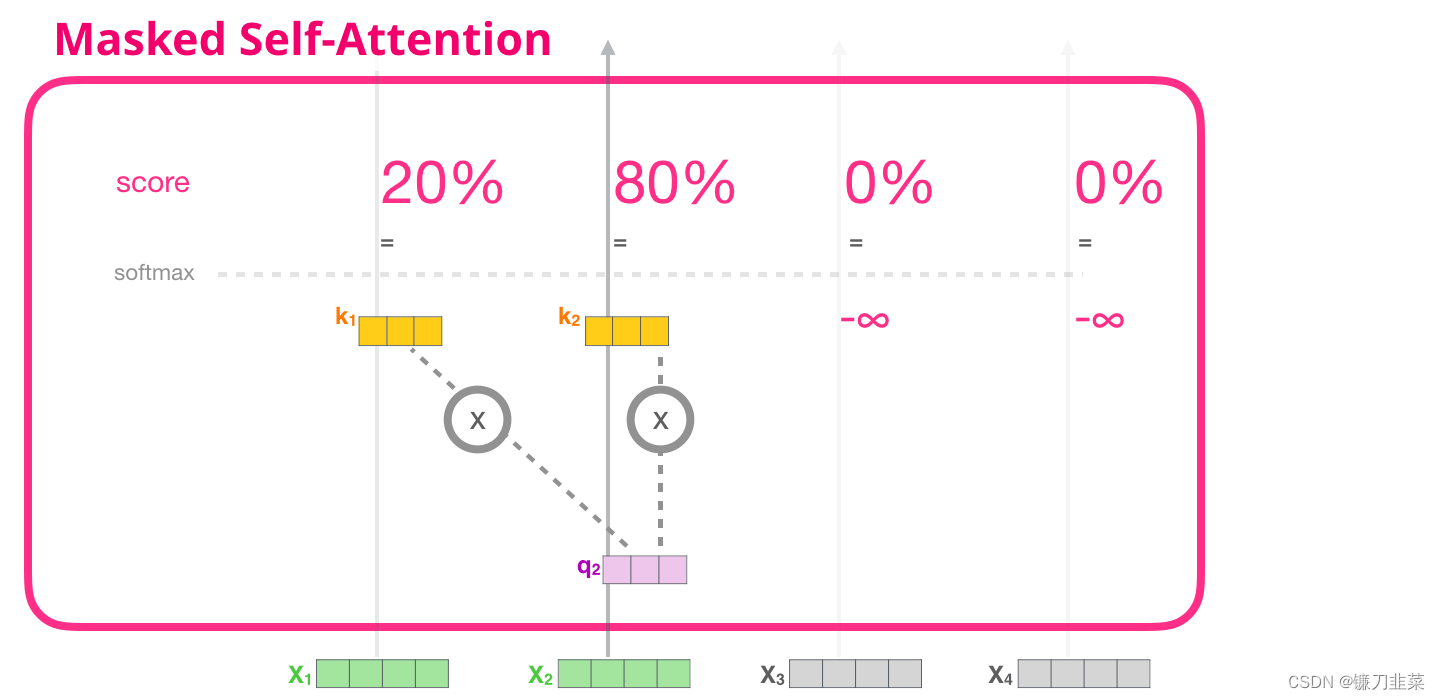
这个屏蔽(masking)经常用一个矩阵来实现,称为 attention mask。想象一下有 4 个单词的序列(例如,机器人必须遵守命令)。在一个语言建模场景中,这个序列会分为 4 个步骤处理——每个步骤处理一个词(假设现在每个词是一个 token)。由于这些模型是以 batch size 的形式工作的,我们可以假设这个简单模型的 batch size 为 4,它会将整个序列作(包括 4 个步骤)为一个 batch 处理。

在矩阵的形式中,我们把 Query 矩阵和 Key 矩阵相乘来计算分数。让我们将其可视化如下,不同的是,我们不使用单词,而是使用与格子中单词对应的 Query 矩阵(或者 Key 矩阵)。
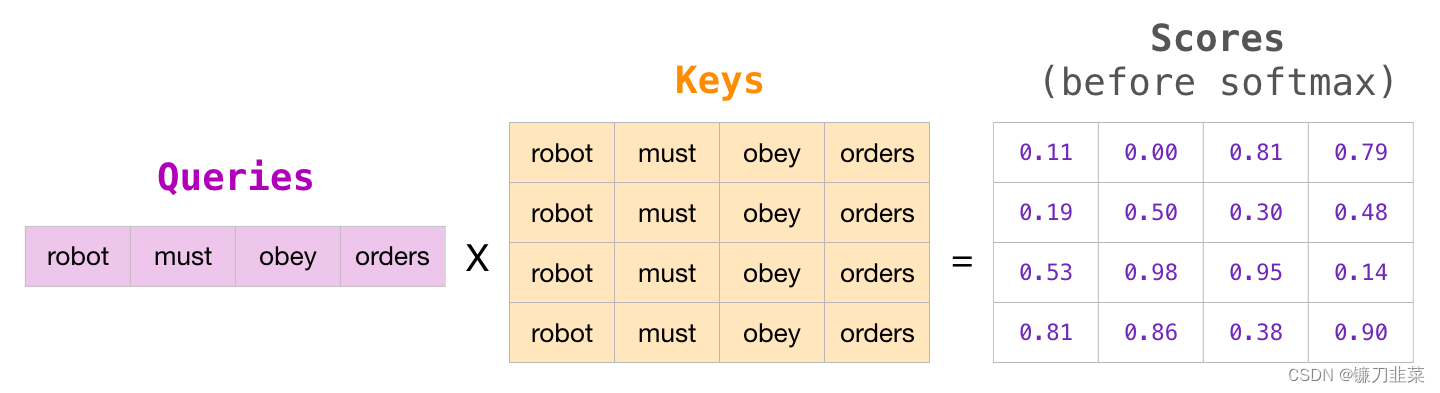
在做完乘法之后,我们加上三角形的 attention mask。它将我们想要屏蔽的单元格设置为负无穷大或者一个非常大的负数(e.g. -1 billion in GPT2):

然后对每一行应用 softmax,会产生实际的分数,我们会将这些分数用于 Self-Attention。

这个分数表的含义如下:
- 当模型处理数据集中的第1个数据(第 1 行),其中只包含着一个单词 (robot),它将 100% 的注意力集中在这个单词上。
- 当模型处理数据集中的第2个数据(第 2 行),其中包含着单词(robot must)。当模型处理单词 must,它将 48% 的注意力集中在 robot,将 52% 的注意力集中在 must。
- 诸如此类,继续处理后面的单词。
GPT-2 Masked Self-Attention
现在,我们可以更详细地了解 GPT-2 的 masked attention机制。
评价模型:每次处理一个 token
我们可以让 GPT-2 像masked self-attention 一样工作。但是在评价模型时,当我们的模型在每次迭代后只添加一个新词,那么对于已经处理过的 token 来说,沿着之前的路径重新计算 self-attention 是低效的。
在这种情况下,我们处理第一个 token(现在暂时忽略 <s>)。
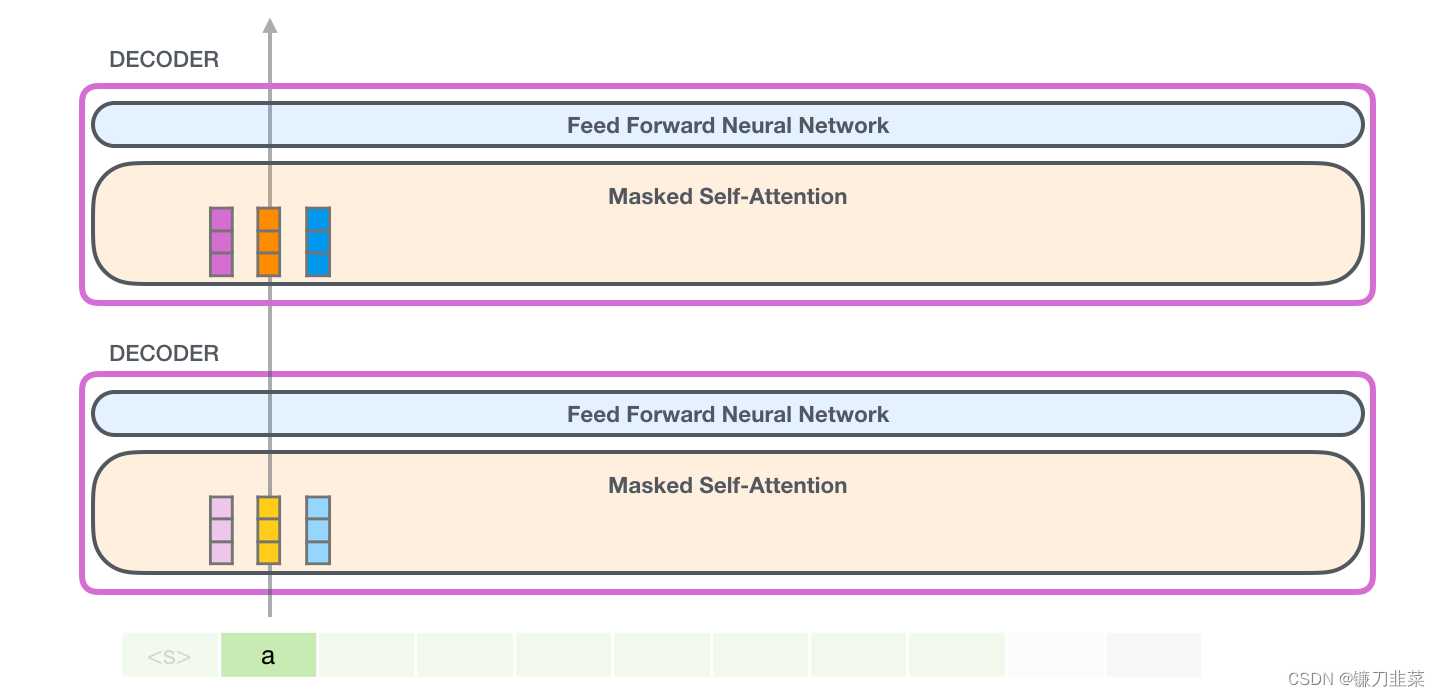
GPT-2 保存 token a 的 Key 向量和 Value 向量。每个 self-attention 层都持有这个 token 对应的 Key 向量和 Value 向量:
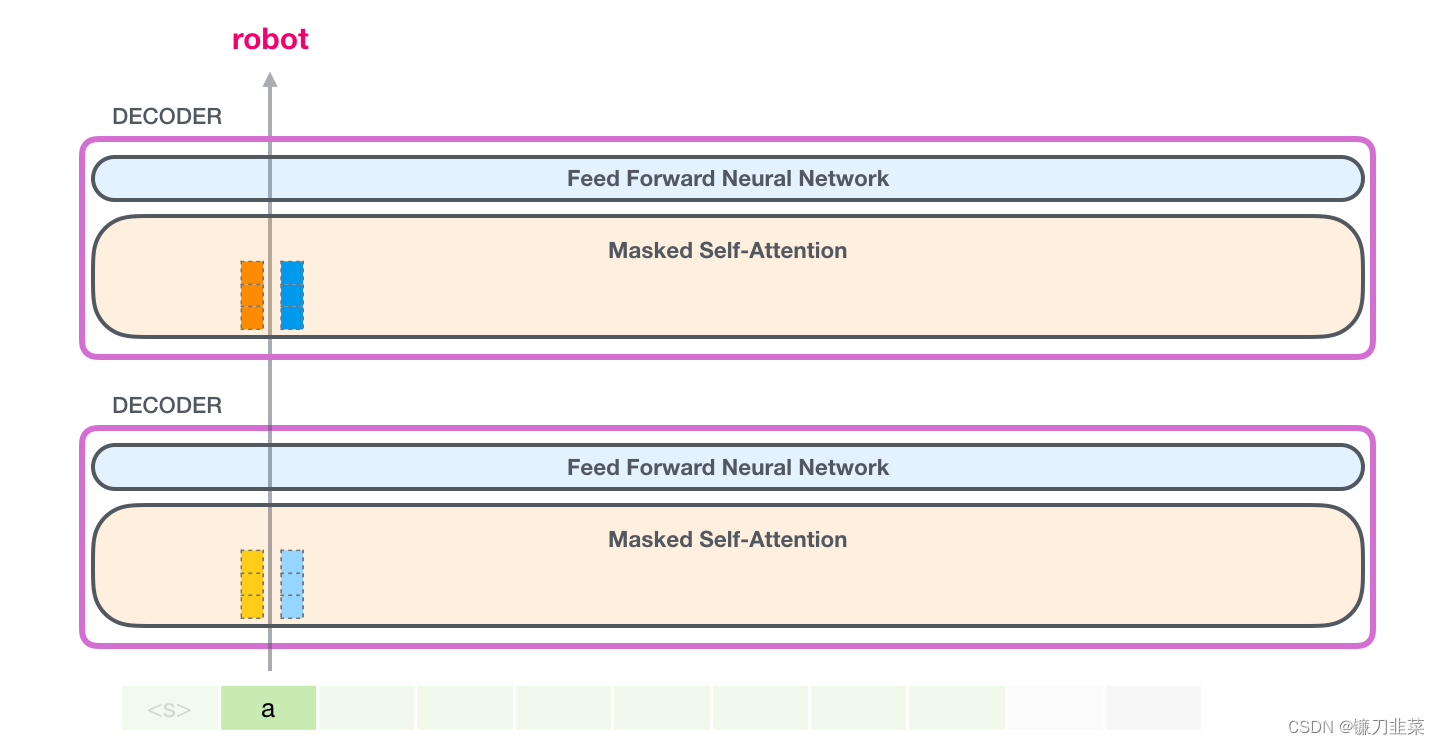
现在在下一个迭代,当模型处理单词 robot,它不需要生成 token a 的 Query、Value 以及 Key 向量。它只需要重新使用第一次迭代中保存的对应向量:
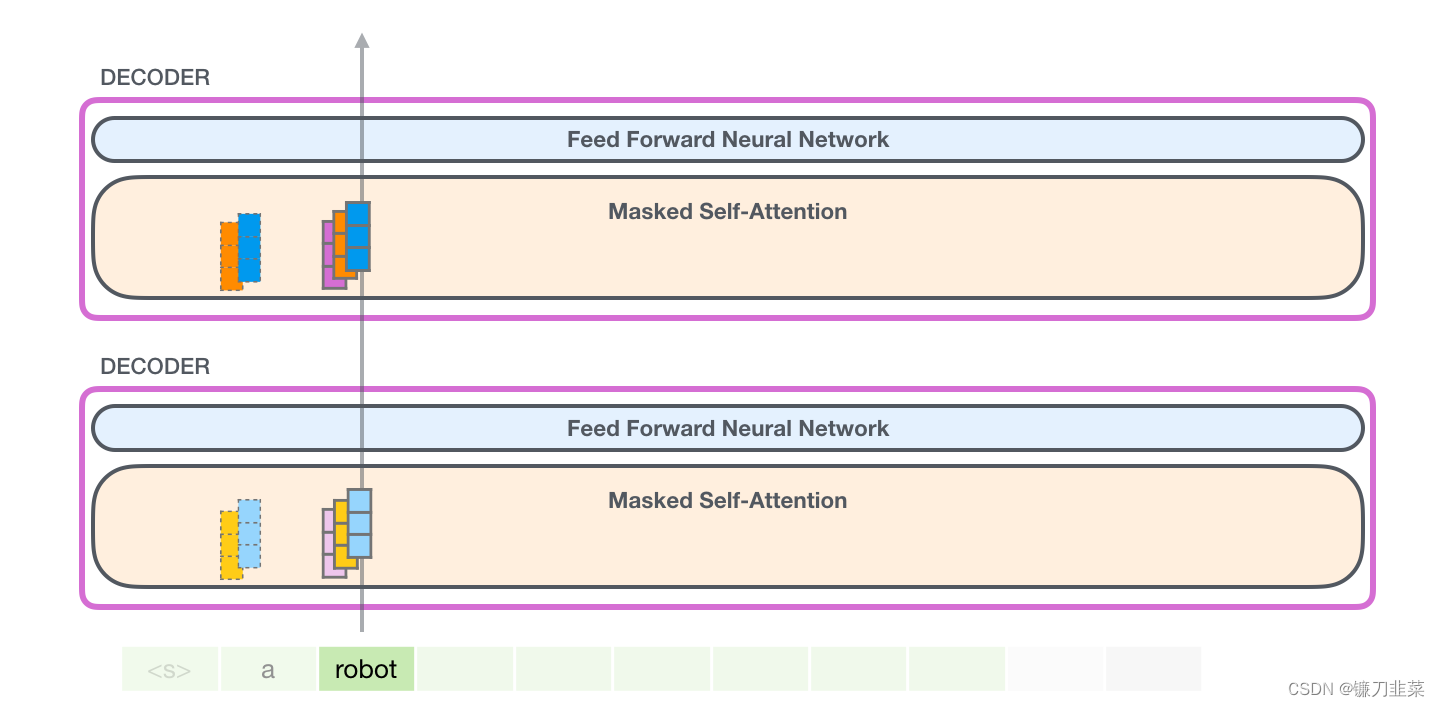
GPT-2 Self-attention
1. 创建 Query、Key 和 Value 矩阵
让我们假设模型正在处理单词 it。如果我们讨论最下面的模块(对于最下面的模块来说),这个 token 对应的输入就是 it 的 embedding 加上第 9 个位置的位置编码:
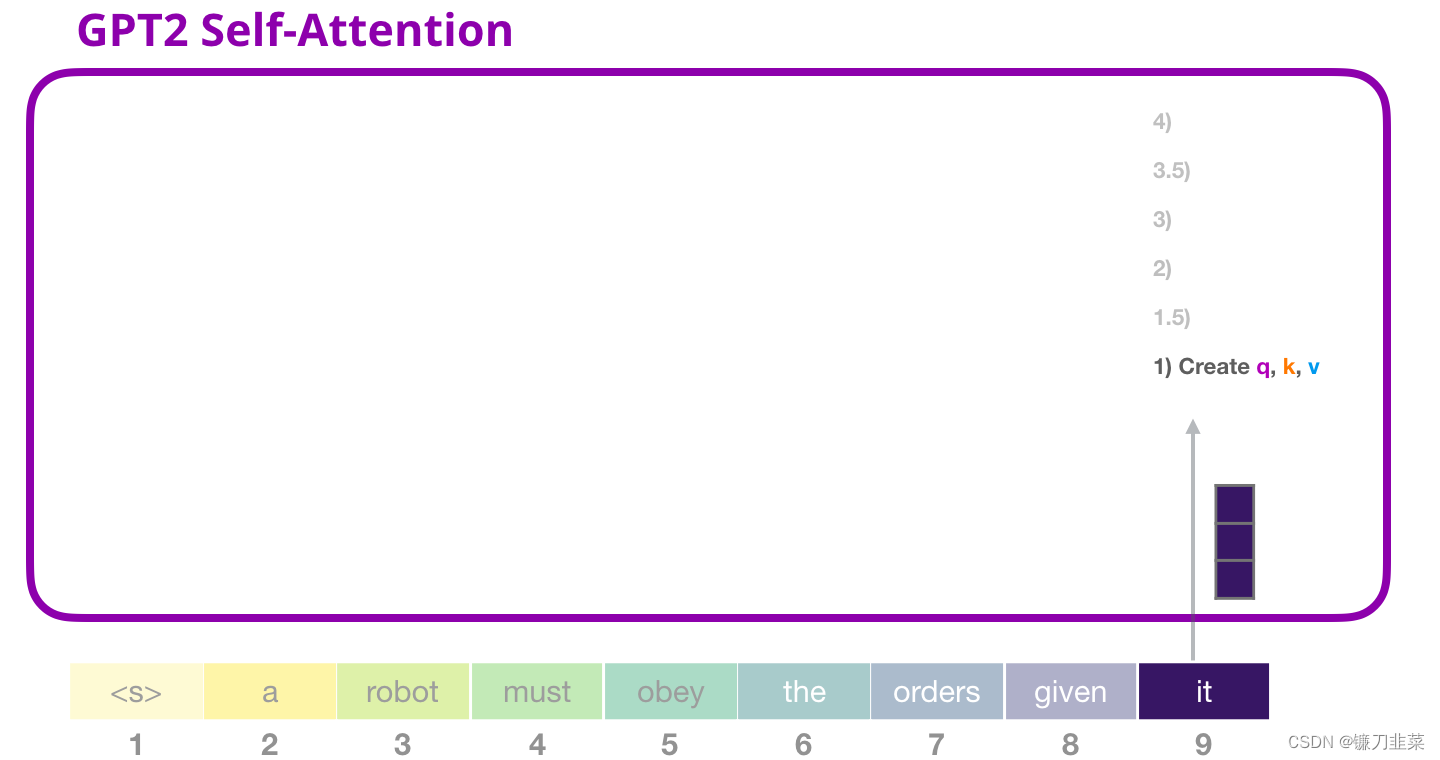
Transformer 中每个模块都有它自己的权重(在后文中会拆解展示)。我们首先遇到的权重矩阵是用于创建 Query、Key、和 Value 向量的。
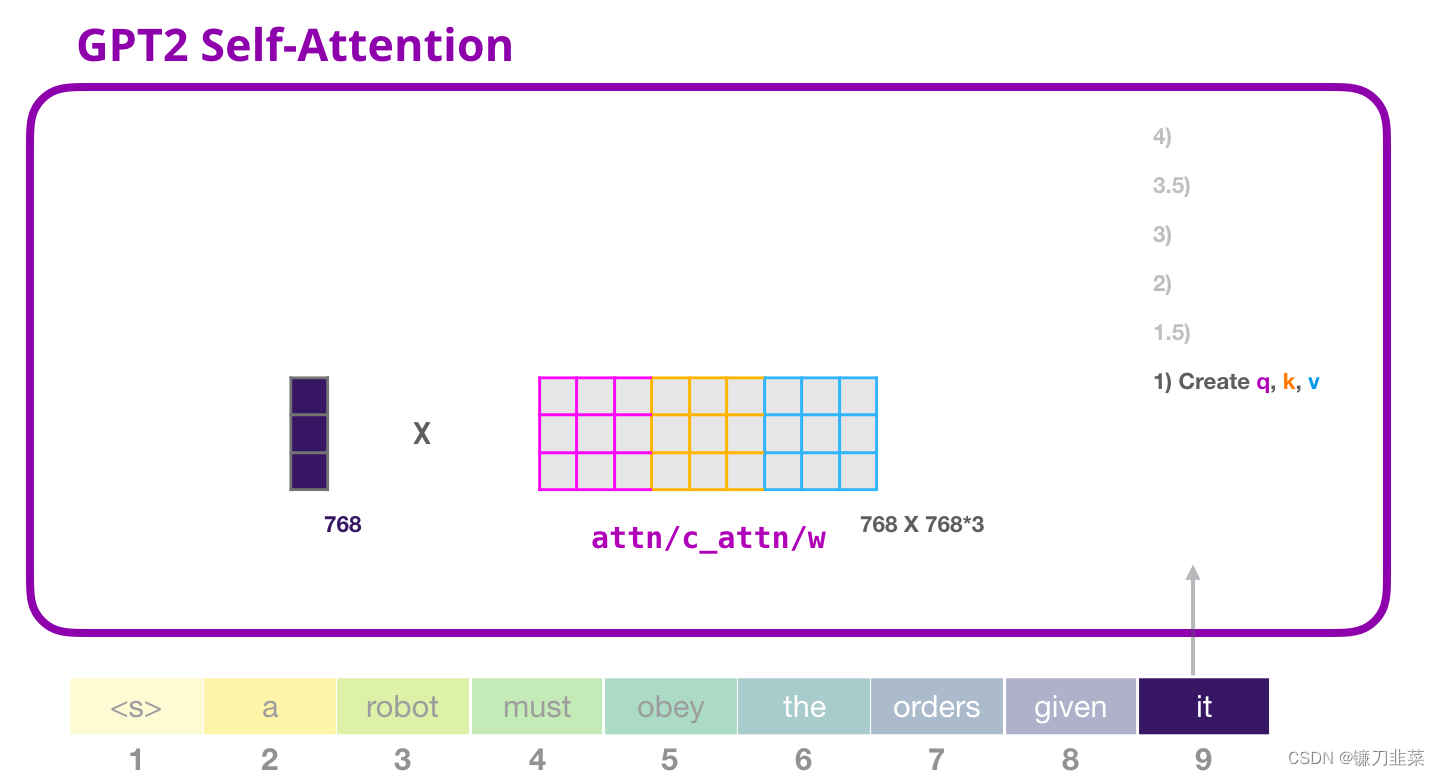
Self-Attention 将它的输入乘以权重矩阵(并添加一个 bias 向量,此处没有画出),这个相乘会得到一个向量,这个向量基本上是 Query、Key 和 Value 向量的拼接。
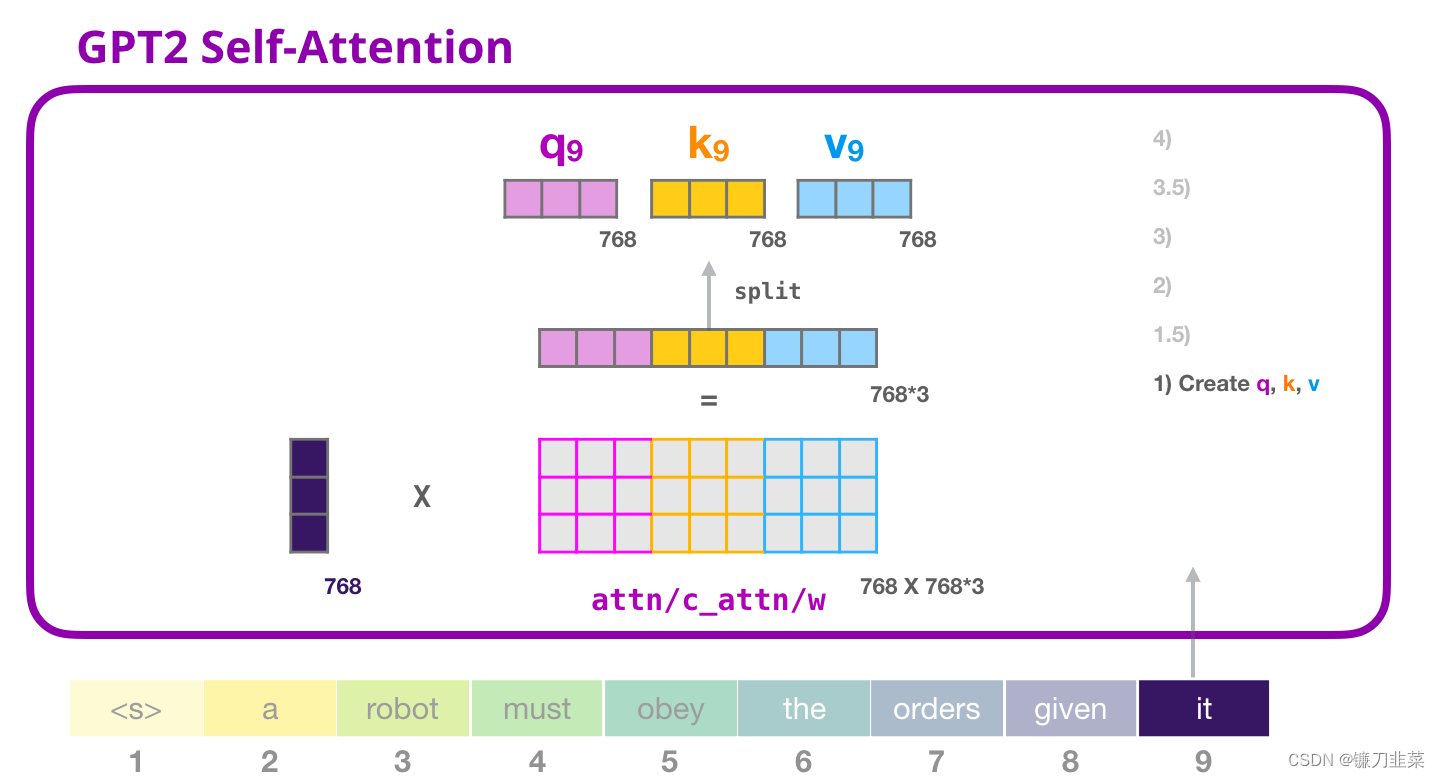
将输入向量与 attention 权重向量相乘(并加上一个 bias 向量)得到这个 token 的 Key、Value 和 Query 向量拆分为 attention heads。
1.5 拆分为attention heads
在之前的例子中,我们只关注了 Self Attention,忽略了 multi-head 的部分。现在对这个概念做一些讲解是非常有帮助的。Self-attention 在 Q、K、V 向量的不同部分进行了多次计算。拆分 attention heads 只是把一个长向量变为矩阵。小的 GPT-2有 12 个 attention heads,因此这将是变换后的矩阵的第一个维度:
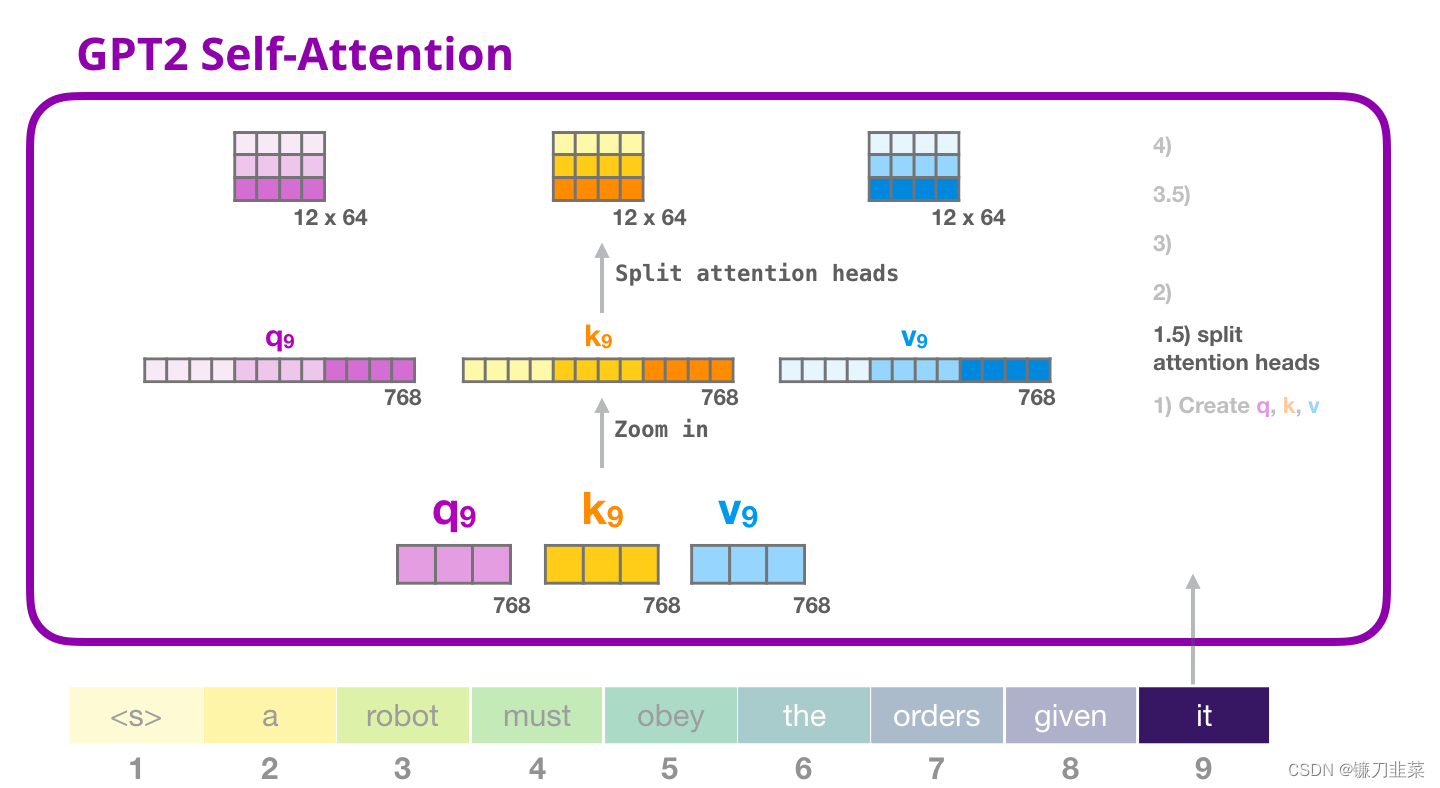
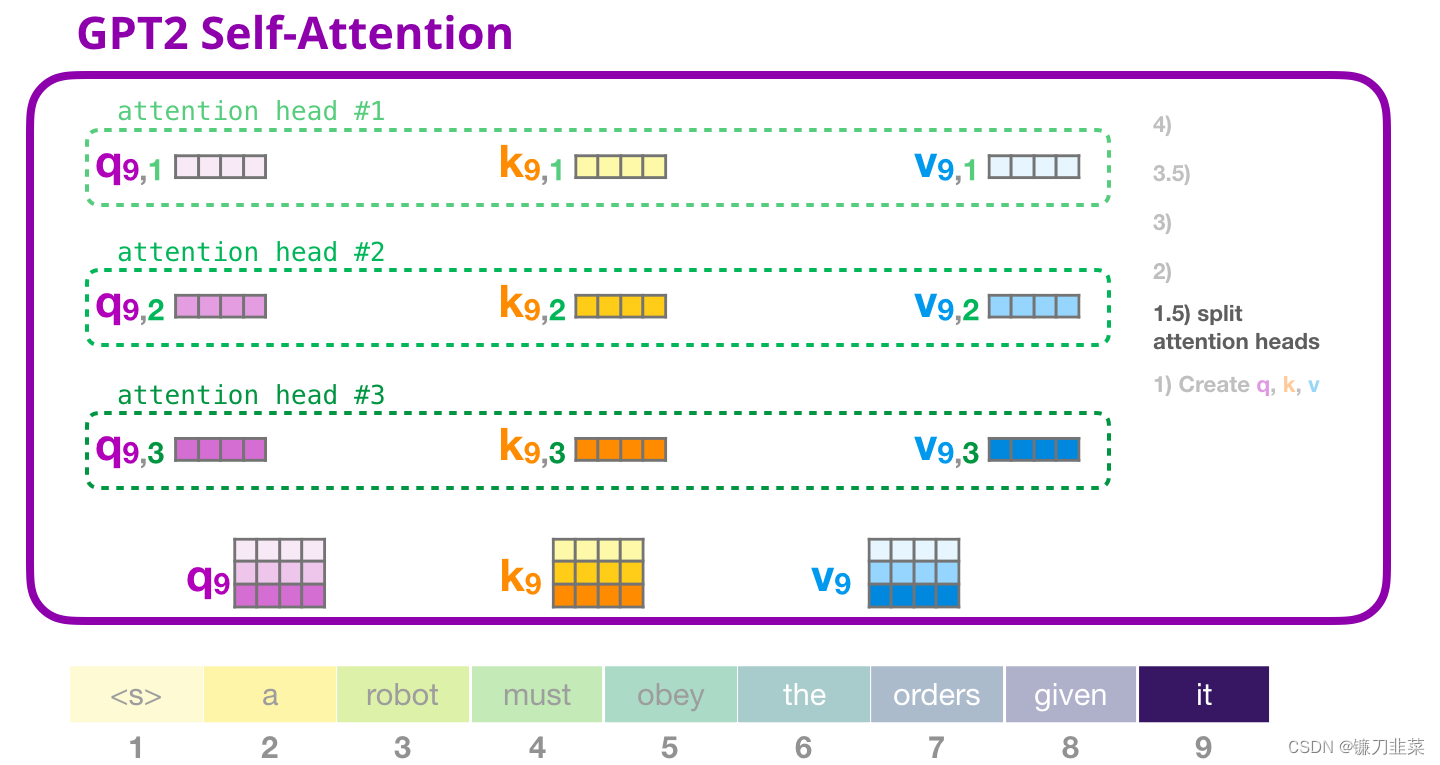
在之前的例子中,我们研究了一个 attention head 的内部发生了什么。理解多个 attention-heads 的一种方法,是像下面这样(如果我们只可视化 12 个 attention heads 中的 3 个):
2. 评分
现在可以继续进行评分,这里我们只关注一个 attention head(其他的 attention head 也是在进行类似的操作)。
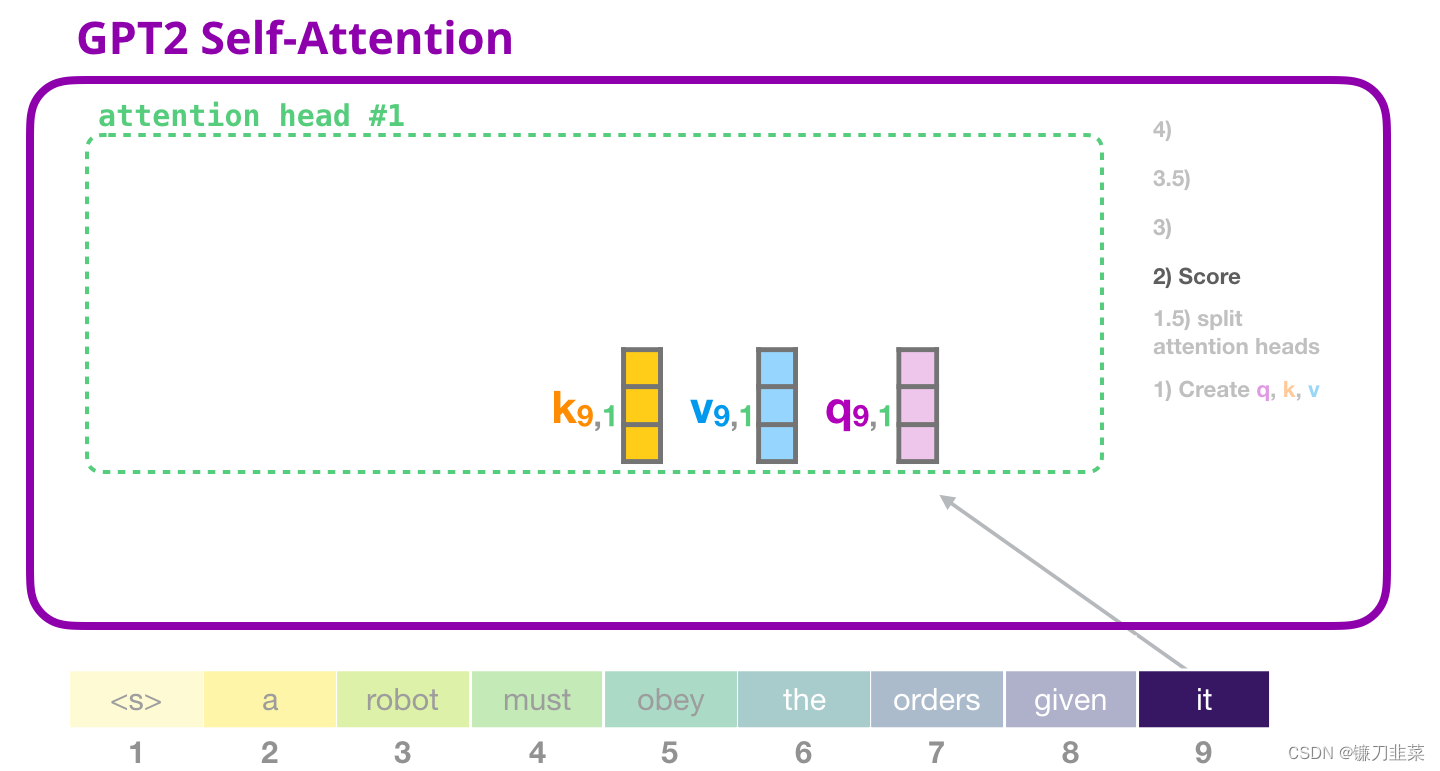
现在,这个token 可以根据其他所有token 的Key 向量进行评分(这些Key 向量是在前面一个迭代中的第一个 attention head 计算得到的):
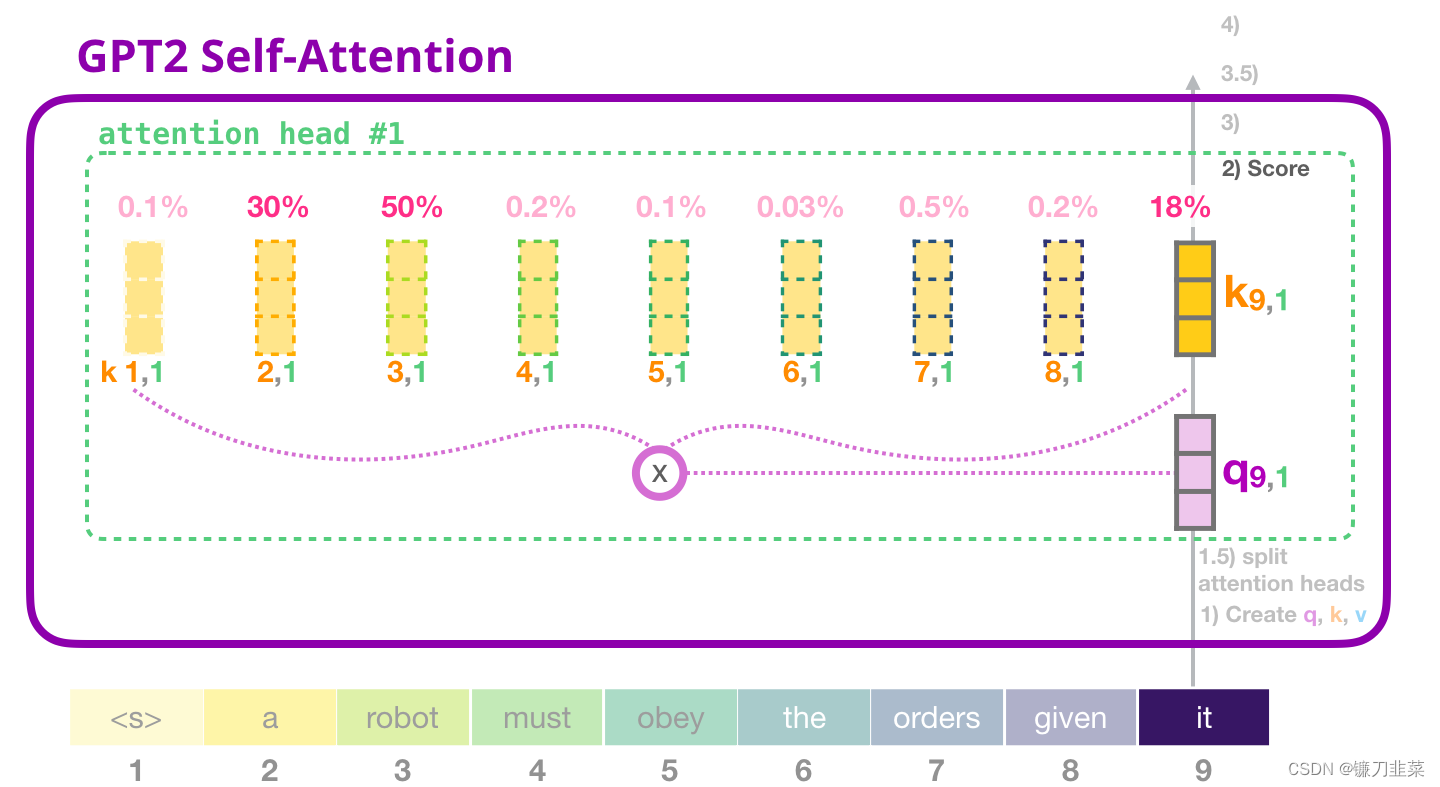
3. 求和
正如之前所看的那样,我们现在将每个Value 向量乘以对应的分数,然后加起来求和,得到第一个 attention head 的 Self-Attention 结果:
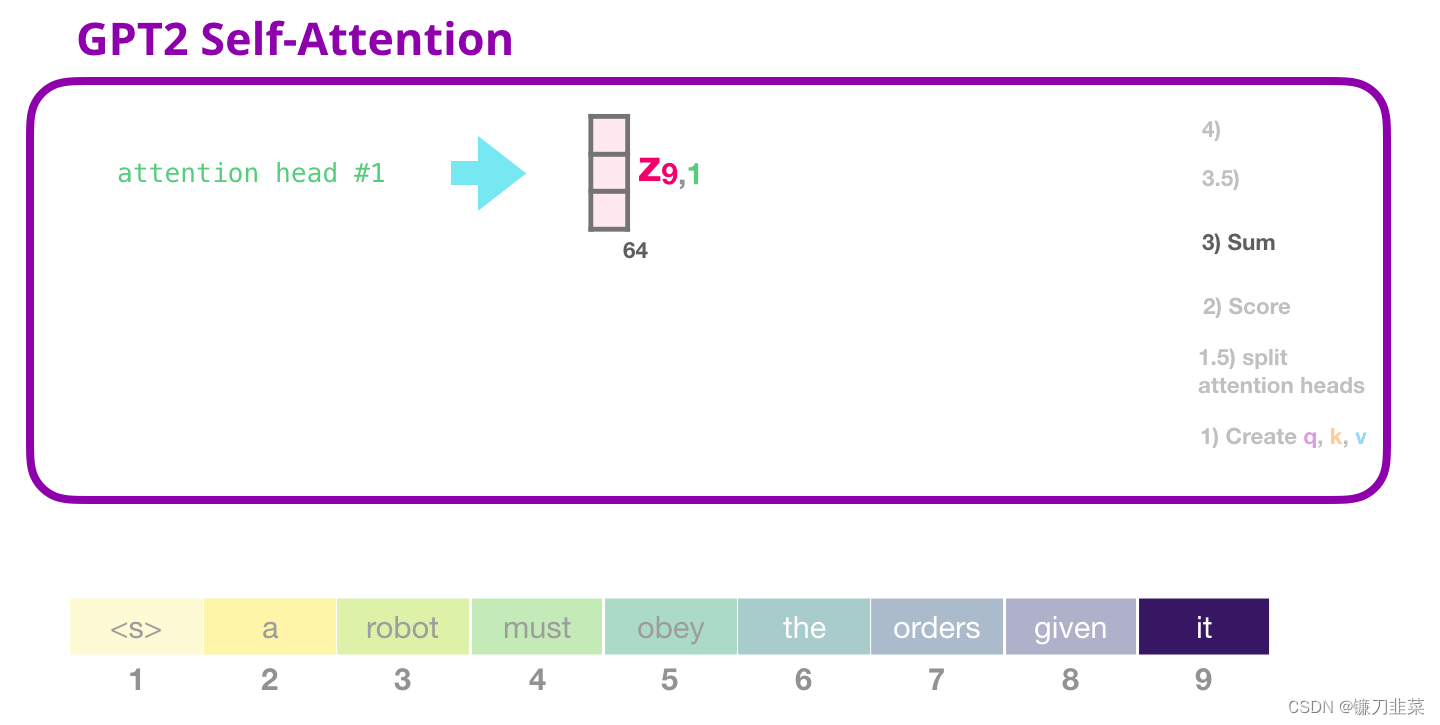
3.5 合并attention heads
我们处理各种注意力的方法是首先把它们连接成一个向量:
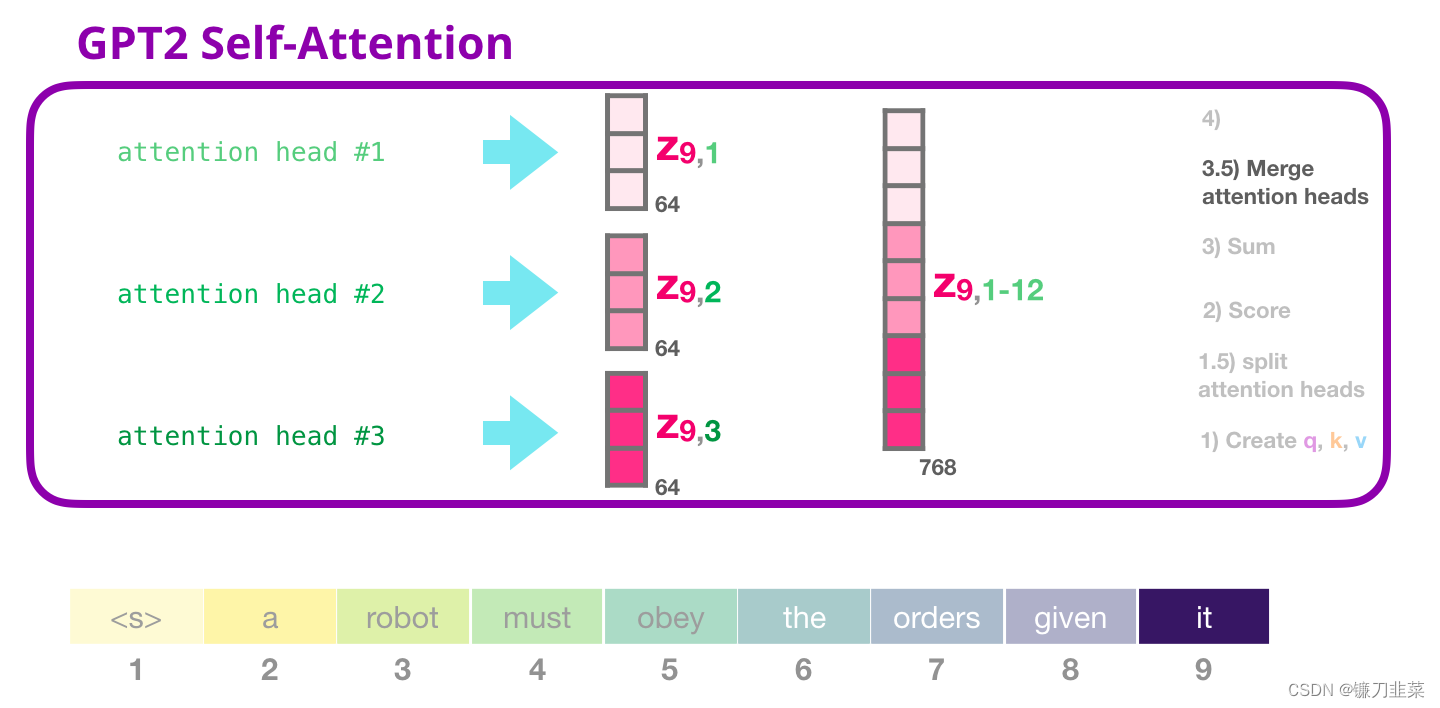
但是,这个向量还没有准备好发送到下一个子层(向量的长度不对)。我们首先需要把这个隐层状态的巨大向量转换为同质的表示(homogenous representation)。
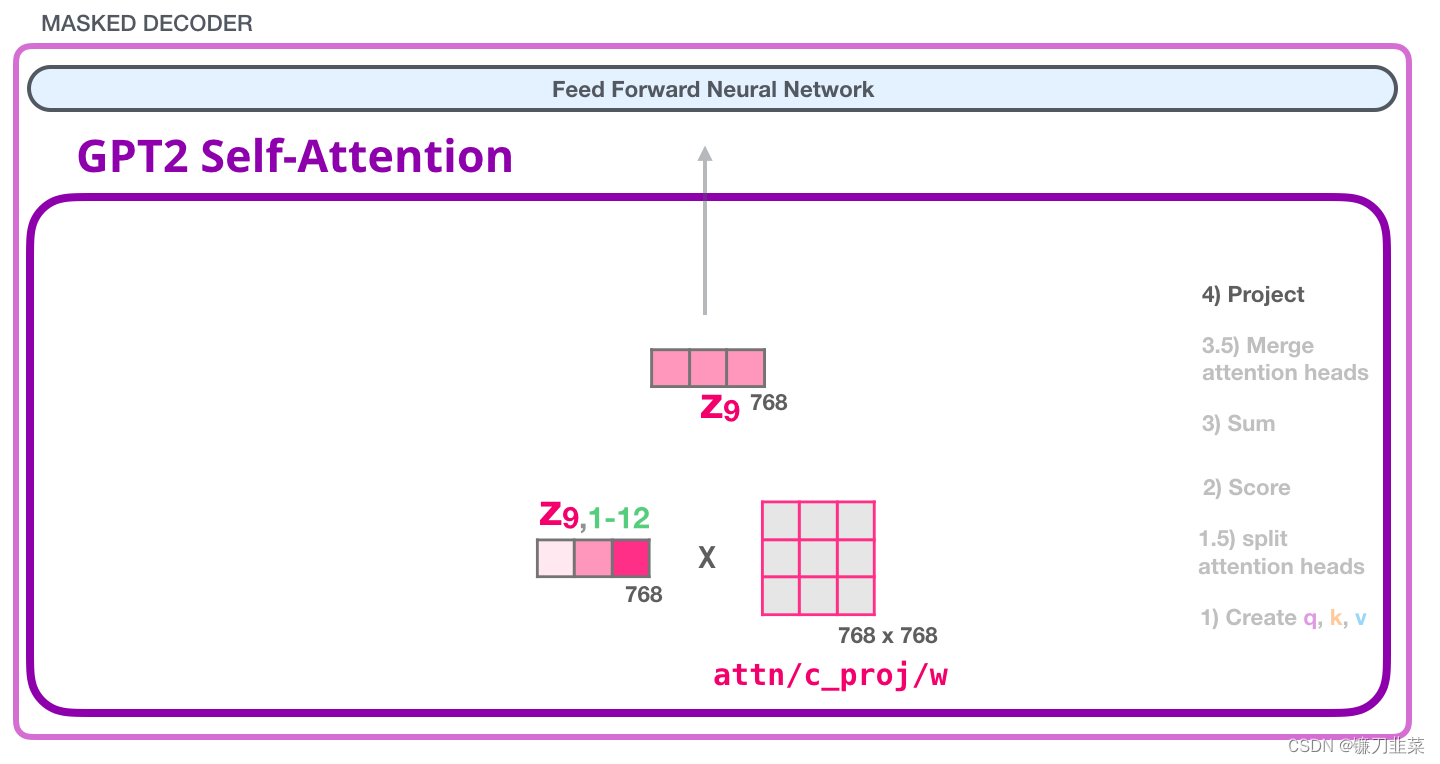
4. 映射(投影)
我们将让模型学习如何将拼接好的 Self Attention 结果转换为前馈神经网络能够处理的形状。在这里,我们使用第二个巨大的权重矩阵,将 attention heads 的结果映射到 self-attention 子层的输出向量:
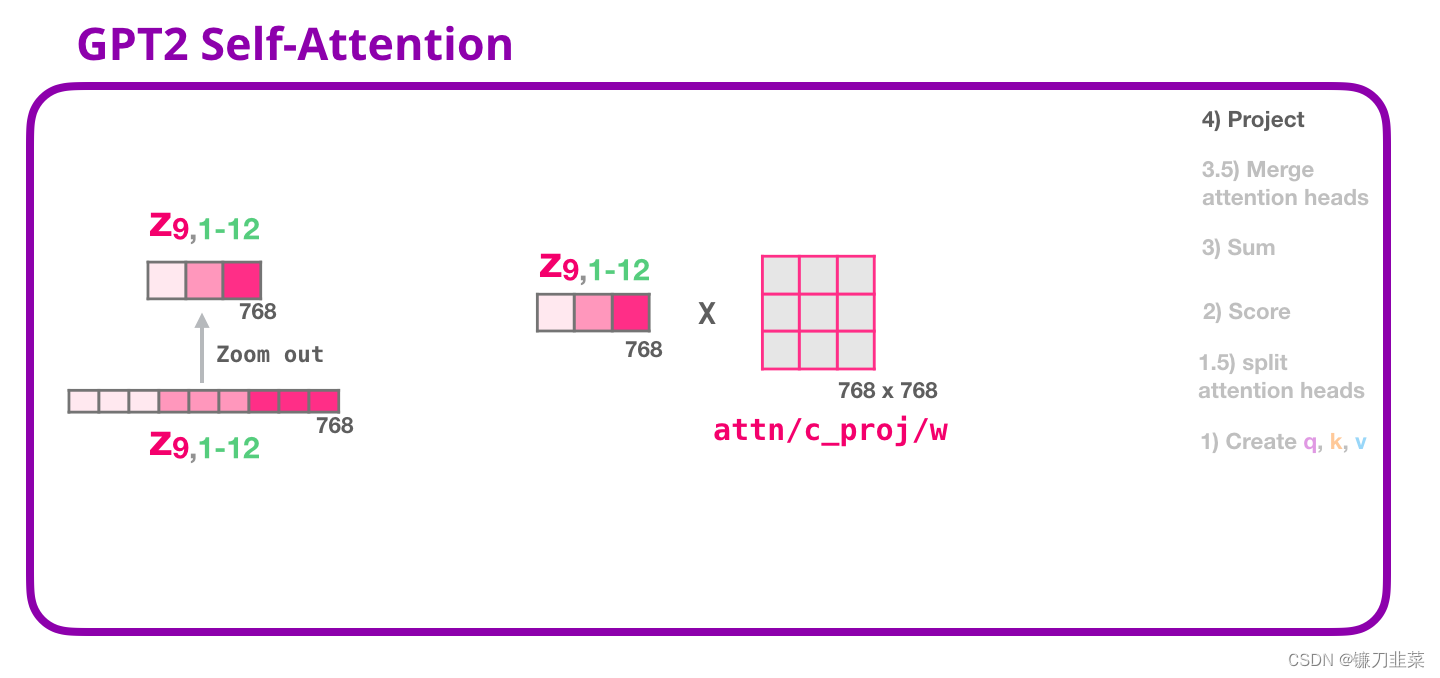
通过映射,得到了一个向量,我们可以把这个向量传给下一层:
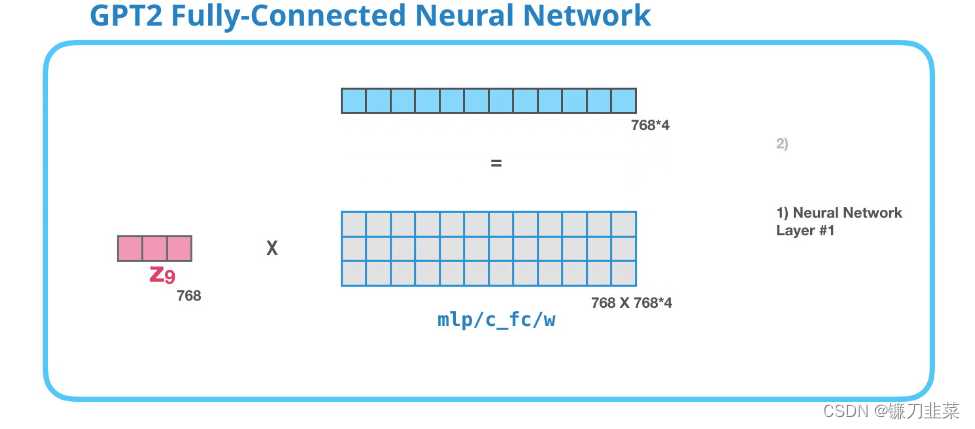
GPT-2 全连接神经网络
第一层
全连接神经网络是用于处理 Self Attention 层的输出,这个输出的表示包含了合适的上下文。全连接神经网络由两层组成。第一层是模型大小的 4 倍(由于 GPT-2 small 是 768,因此这个网络会有 个神经元)。为什么是四倍?这只是因为这是原始 Transformer 的大小(如果模型的维度是 512,那么全连接神经网络中第一个层的维度是 2048)。这似乎给了 Transformer 足够的表达能力,来处理目前的任务。
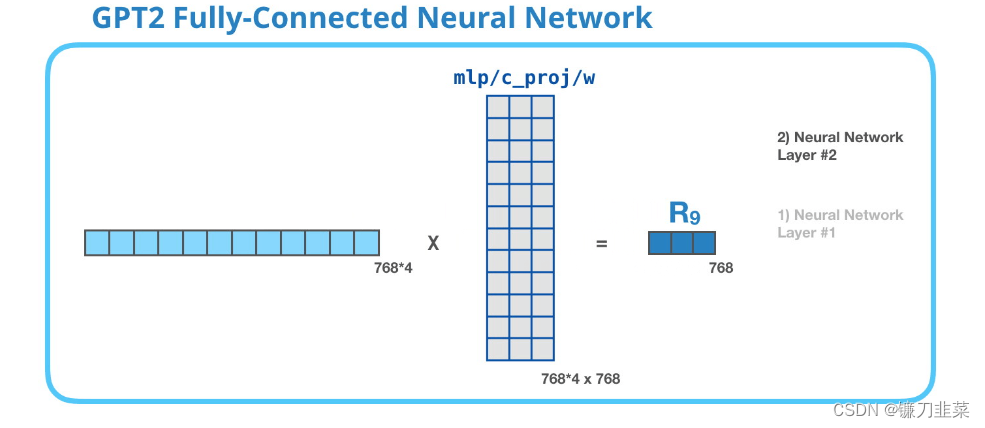
第二层:把向量映射到模型的维度
第 2 层把第 1 层得到的结果映射回模型的维度(在 GPT-2 small 中是 768)。这个相乘的结果是 Transformer 对这个 token 的输出。
以上就是我们讨论的 Transformer 的最详细的版本!现在已经了解了 Transformer 语言模型内部发生了什么。总结一下,我们的输入会遇到下面这些权重矩阵:
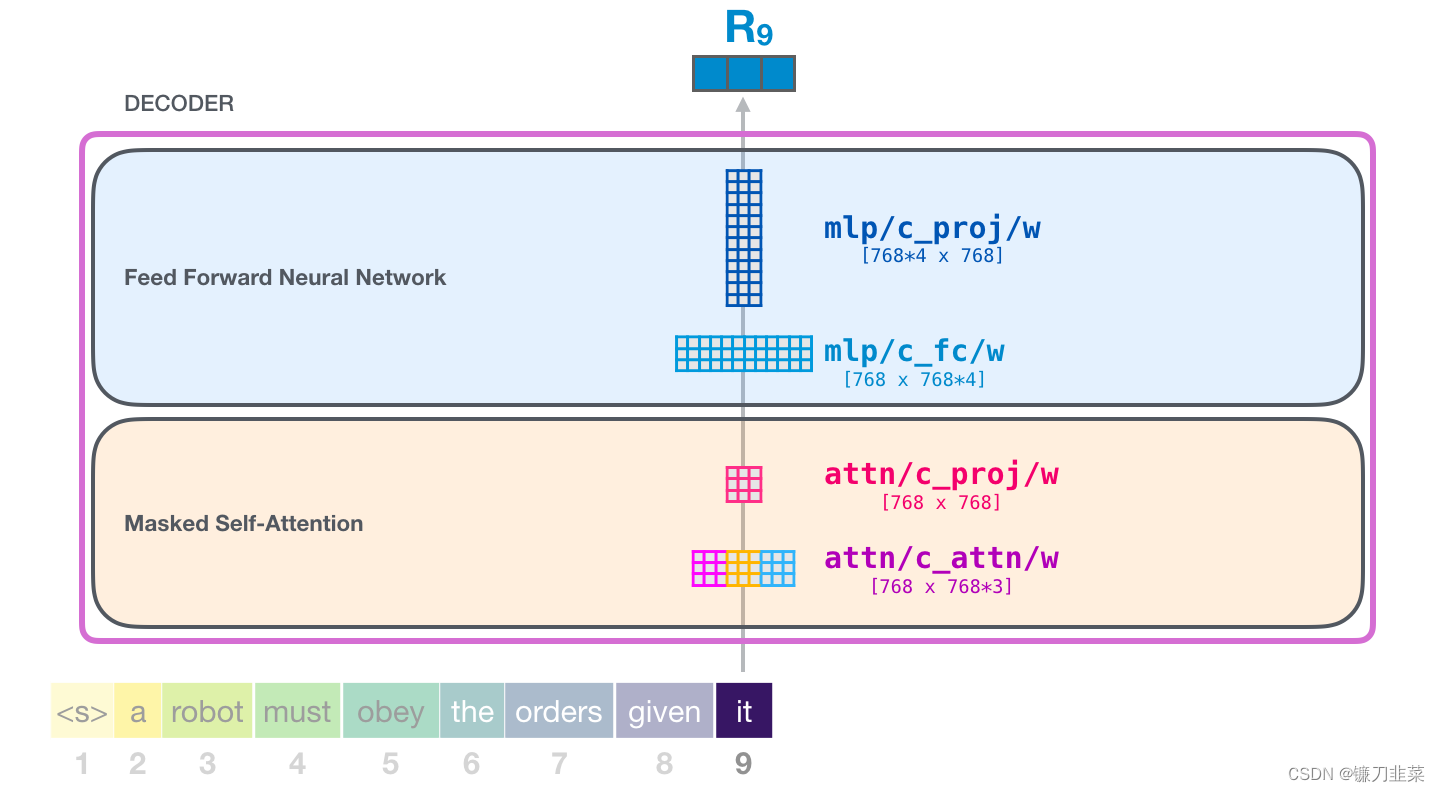 每个模块都有它自己的权重。另一方面,模型只有一个 token embedding 矩阵和一个位置编码矩阵。
每个模块都有它自己的权重。另一方面,模型只有一个 token embedding 矩阵和一个位置编码矩阵。
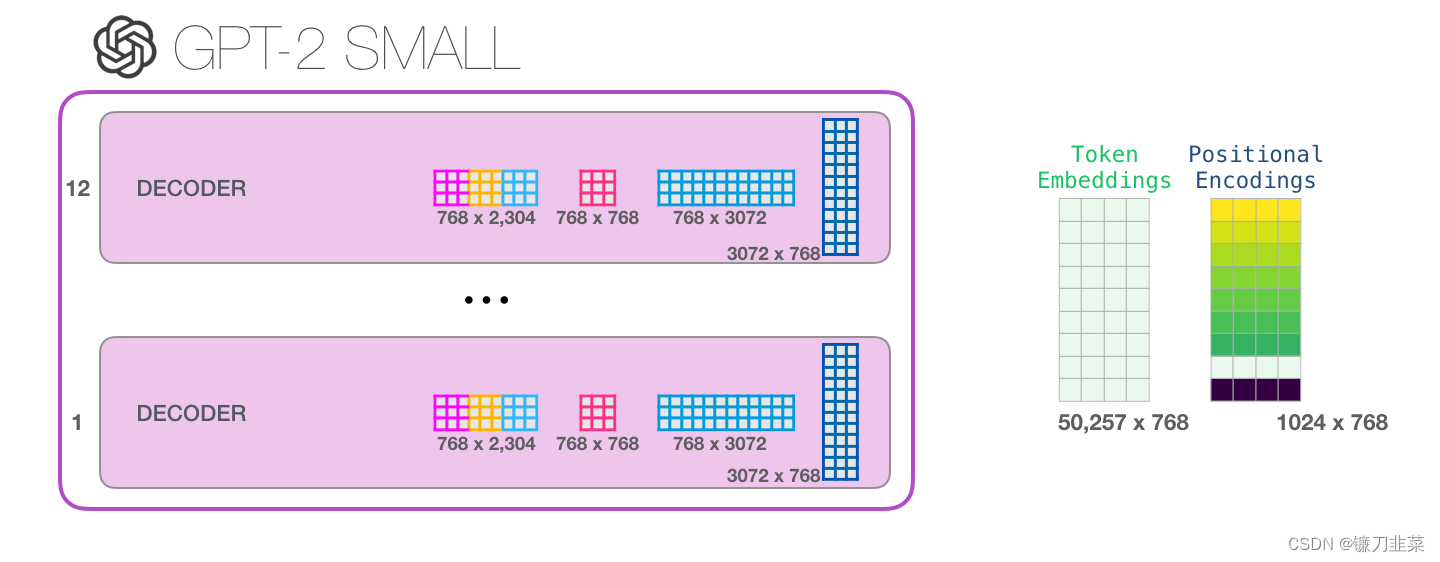
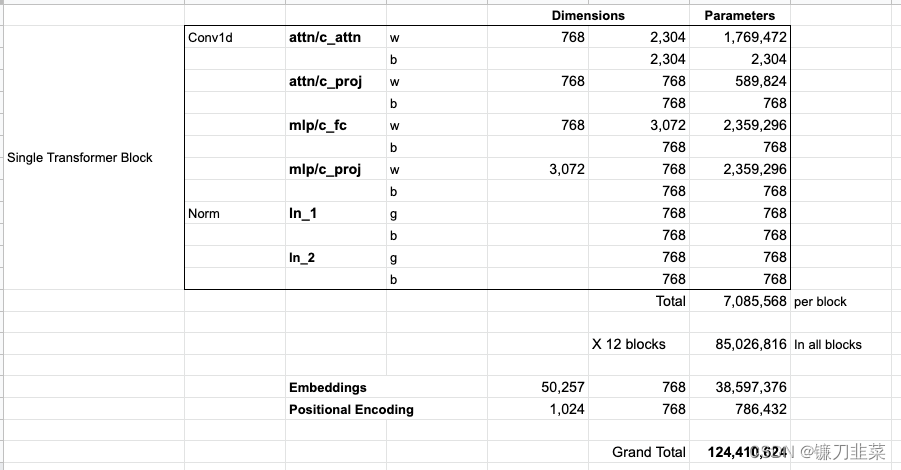
查看模型的所有参数如下:
GPT-3
GPT-3延续GPT的单向语言模型训练方式,但是引入了 Sparse Transformer 中的 sparse attention 模块(稀疏注意力),并且把模型尺寸增大到了1750亿,使用45TB数据进行训练。同时GPT-3主要聚焦于更通用的NLP模型,在一系列基准测试和特定领域的自然语言处理任务中达到最新的SOTA结果。
sparse attention 与传统 self-attention(称为 dense attention) 的区别在于:
dense attention:每个 token 之间两两计算 attention,复杂度 O(n²)sparse attention:每个 token 只与其他 token 的一个子集计算 attention,复杂度 O(n*logn)
与GPT-2相比,GPT-3的图像生成功能更成熟,不需要微调,就可以在不完整的图像样本基础上补全完整的图像。GPT-3实现了两个转变:
1)从语言到图像的转换
2)使用更少的领域数据,甚至不经过微调步骤去解决问题。
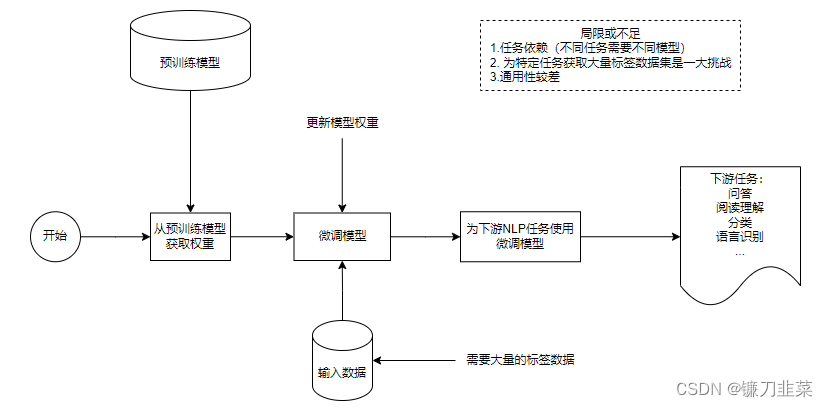
1. 预训练模型一般流程
预训练模型的一般流程如图所示,其中微调是一个重要环节。
2. GPT-3与BERT的区别
GPT-3和BERT是两个不同的自然语言处理(NLP)模型,它们在多个方面有着显著的区别:
- 模型架构:
- GPT-3(Generative Pre-trained Transformer 3)是一个基于Transformer的Decoder模块的自回归语言模型,使用Masked Self-Attention。它的设计目的是生成文本,可以用于生成各种自然语言文本,如文章、故事、对话等。
- BERT(Bidirectional Encoder Representations from Transformers)是一个基于Transformer的Encoder模块的自编码语言模型,使用Self-Attention。BERT的目标是通过双向上下文建模,提取文本中的表示形式,通常用于各种NLP任务的预训练。
- 任务类型:
- GPT-3: GPT-3主要用于生成文本,它是一个生成模型,可以生成与输入文本相关的自然语言输出。
- BERT: BERT主要用于提取文本的表示形式,它是一个表示学习模型,可以用于各种NLP任务,如文本分类、命名实体识别、问答等。
- 训练方式:
- GPT-3: GPT-3采用自回归方式进行预训练,即它通过生成文本来学习语言的概率分布。GPT-3的训练基于4990亿标识符的语料库。
- BERT: BERT采用自编码方式进行预训练,即它通过预测输入文本中的遮蔽词汇来学习文本表示。其中的BERT Large训练数据基于25亿标识符的语料库
- 方向性:
- GPT-3: GPT-3是一个自回归模型,通常用于生成文本。它生成一系列文本标记,其中每个标记都依赖于前面生成的标记。
- BERT: BERT是一个双向模型,它可以同时考虑上下文中的词汇,因此可以更好地理解整个文本的上下文。
- 任务适应性:
- GPT-3: GPT-3通常需要微调才能适应特定的任务。它的输出可以通过添加任务特定的头部(例如分类头部)来用于各种任务。
- BERT: BERT通过在预训练后添加一个简单的任务特定层(例如分类层)来适应不同的NLP任务,因此更容易用于迁移学习。
- 规模:
- GPT-3: GPT-3是目前已知最大规模的语言模型之一,具有数千亿个参数,其中GPT-3 Large模型有1750亿个参数。
- BERT: BERT的规模相对较小,通常有数亿或数千万个参数。其中BERT Large模型由3.4亿个参数。
需要注意的是,GPT-3和BERT都是在NLP领域取得了巨大成功的模型,它们各自具有不同的优势和应用领域。选择使用哪个模型取决于具体的任务和需求。
3. GPT-3与传统微调的区别
GPT-3与传统微调(Fine-Tuning)方法在自然语言处理(NLP)中有一些重要的区别,主要体现在以下几个方面:
- 规模和预训练:
- GPT-3:GPT-3是一个极其庞大的预训练语言模型,具有数十亿个参数,它在大规模的文本语料库上进行了自监督预训练。GPT-3的目标是在预训练阶段捕获尽可能多的自然语言知识,而不是为特定任务进行优化。
- 传统微调:传统微调方法通常使用较小规模的预训练模型(如BERT或GPT-2),然后在特定任务的标记数据上进行有监督微调。微调的目标是根据任务特定的目标函数来优化模型,以便更好地适应特定任务。
- 任务适应性:
- GPT-3:由于其巨大的规模和预训练过程的广泛性,GPT-3在多种NLP任务上表现出色,而无需特定任务的微调。这使得GPT-3可以直接用于多种任务,而不需要重新训练模型。
- 传统微调:传统微调方法需要为每个任务进行单独的微调,通常需要大量的标记数据。每个任务都需要一个特定的目标函数和微调过程。
- 通用性:
- GPT-3:GPT-3被设计为一种通用的自然语言处理工具,可以用于生成文本、回答问题、翻译等多种任务。它可以用于多领域的应用,而不需要特定领域的定制。
- 传统微调:传统微调通常需要为每个领域和任务创建定制的模型和训练流程,这可能需要大量的工程工作。
- 数据需求:
- GPT-3:由于其大规模的预训练和迁移学习能力,GPT-3通常需要更少的任务特定标记数据来在新任务上表现良好。
- 传统微调:传统微调方法通常需要大量的标记数据来获得好的性能,尤其是在需要精确的任务中。
- 灵活性:
- GPT-3:GPT-3的预训练模型可以用于各种自然语言处理任务,而无需更改模型的体系结构。这提供了更大的灵活性。
- 传统微调:传统微调可能需要修改模型体系结构以适应特定任务的需求,这可能需要更多的工程工作。
总的来说,GPT-3是一种通用的、预训练的自然语言处理模型,具有出色的泛化能力,可直接用于多种任务。传统微调方法更侧重于特定任务的优化,通常需要更多的工程和标记数据。选择哪种方法取决于任务的性质、数据可用性和资源等因素。
4. GPT-3的示例
GPT-3(Generative Pre-trained Transformer 3)是一个自然语言处理(NLP)模型,具有出色的自然语言理解和生成能力。以下是一些示例,展示了GPT-3可以执行的各种任务和应用场景:
- 文本生成:
- 文章写作:GPT-3可以生成文章、博客帖子、新闻稿等。
- 创意写作:它可以生成诗歌、小说、故事等创意文本。
- 自动问答:
- 问答系统:GPT-3可以回答关于广泛主题的问题,包括科学、历史、技术等。
- 法律咨询:它可以提供法律领域的问题答案和建议。
- 自然语言理解:
- 情感分析:GPT-3可以分析文本中的情感,如正面、负面或中性。
- 意图识别:它可以识别用户的意图,用于聊天机器人和虚拟助手。
- 语言翻译:
- 翻译服务:GPT-3可以将文本从一种语言翻译成另一种语言。
- 代码生成:
- 代码编写:它可以生成程序代码,包括Python、JavaScript等。
- 虚拟助手:
- 个性化助手:GPT-3可以用于构建个性化虚拟助手,用于回答用户的问题和执行任务。
- 创作和艺术:
- 绘画和插画:它可以生成绘画描述或创作美术作品的说明。
- 音乐创作:GPT-3可以生成音乐和歌词。
- 科学和研究:
- 数据分析:它可以帮助分析数据、生成图表和报告。
- 科学研究:用于生成假设、探索科学领域的问题。
- 教育:
- 在线教育:GPT-3可用于生成教育材料、答案和练习题。
- 社交媒体和聊天:
- 社交媒体帖子:它可以为社交媒体平台生成帖子、评论和回复。
这些示例只是GPT-3的一小部分潜在用途。该模型可以根据提供的输入文本和任务执行多种自然语言处理任务,使其成为一个强大的自然语言处理工具。
更多关于GPT-3的资料请查看How GPT3 Works - Visualizations and Animations
语言模型应用案例
只有 Decoder 的 Transformer 在语言模型之外一直展现出不错的应用。它已经被成功应用在了许多应用中,可以用类似上面的图解方式来描述这些成功应用。
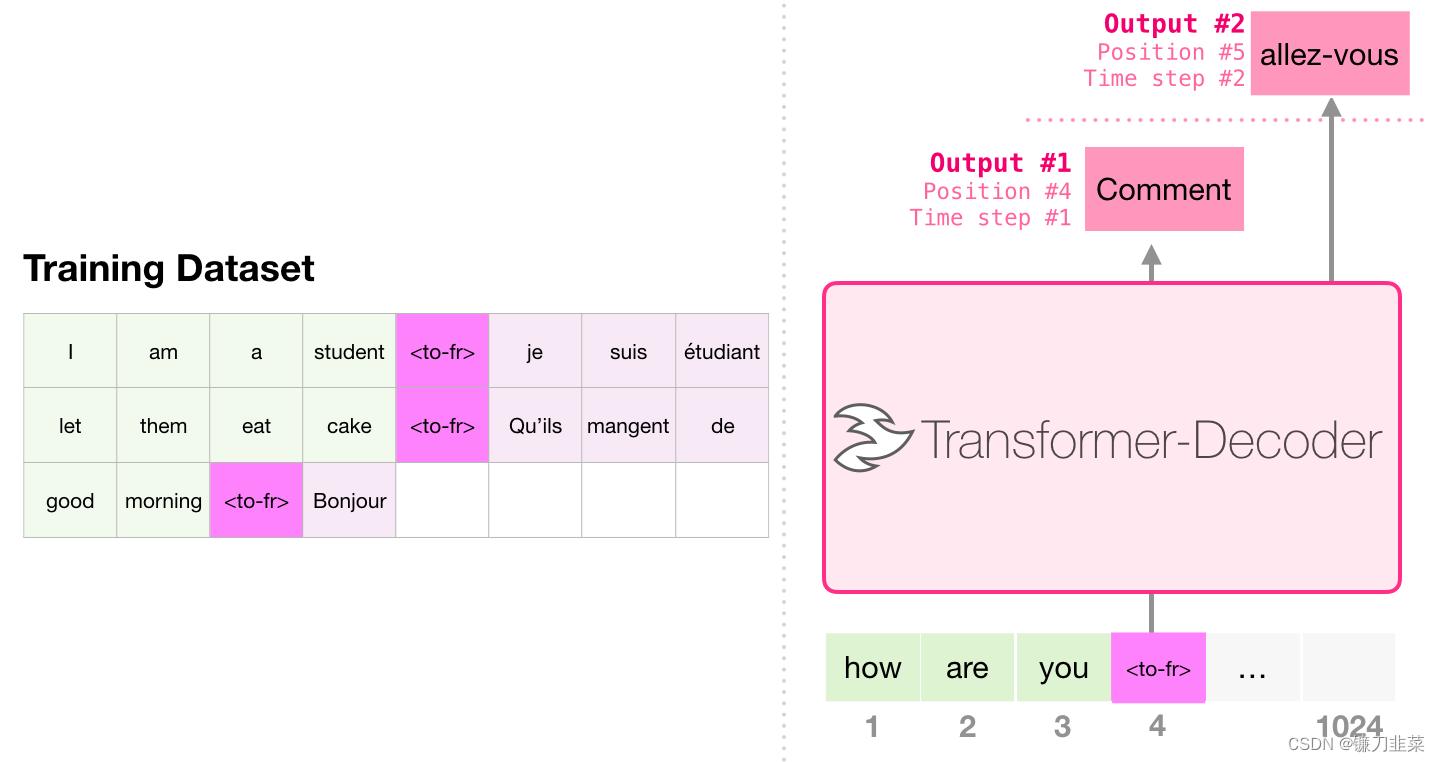
1. 机器翻译
进行机器翻译时,Encoder 不是必须的。我们可以用只有 Decoder 的 Transformer 来解决同样的任务:
2. 生成摘要
这是第一个只使用 Decoder 的 Transformer 来训练的任务。它被训练用于阅读一篇维基百科的文章(目录前面去掉了开头部分),然后生成摘要。文章的实际开头部分用作训练数据的标签:
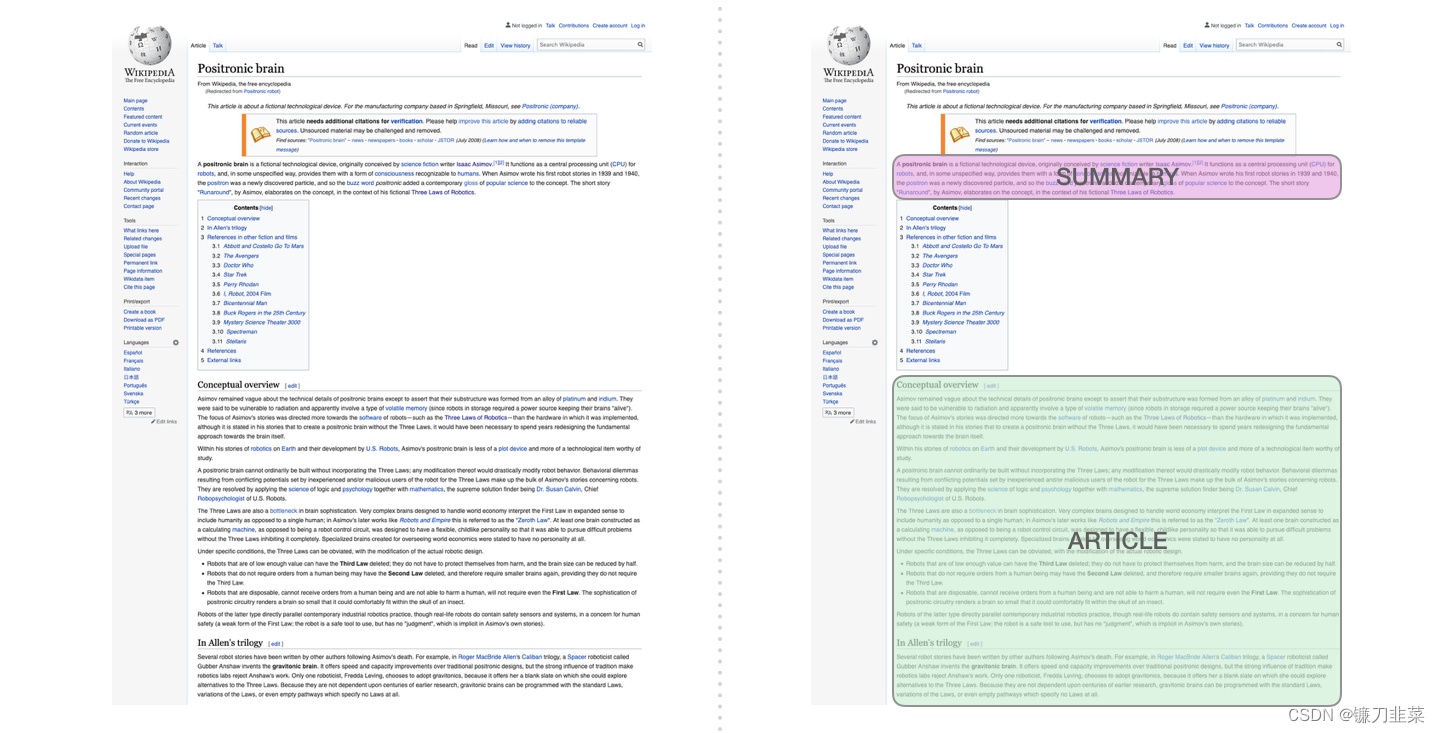
论文里针对维基百科的文章对模型进行了训练,因此这个模型能够总结文章,生成摘要:
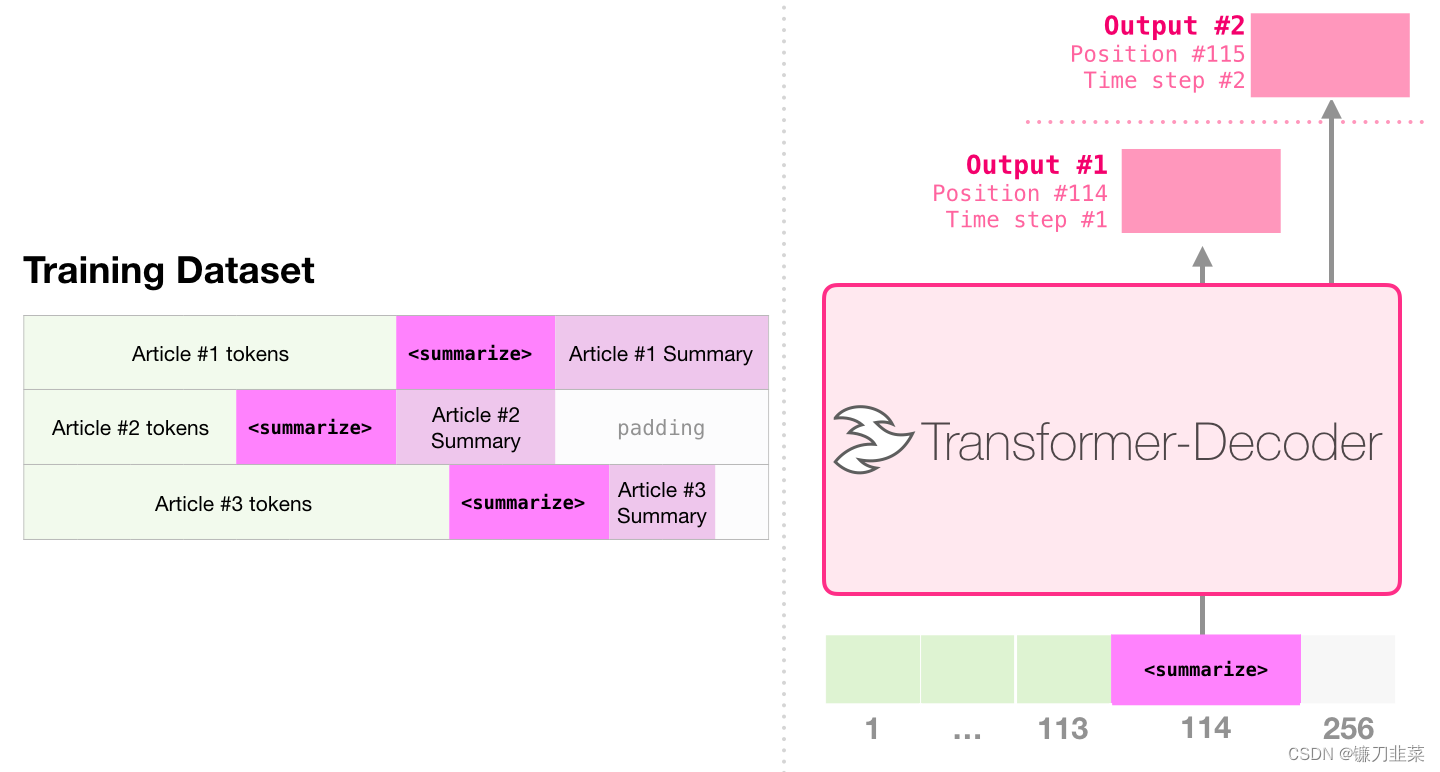
3. 迁移学习
在Sample Efficient Text Summarization Using a Single Pre-Trained Transformer 中,一个只有 Decoder 的 Transformer 首先在语言模型上进行预训练,然后微调进行生成摘要。结果表明,在数据量有限制时,它比预训练的 Encoder-Decoder Transformer 能够获得更好的结果。
GPT-2 的论文也展示了在语言模型进行预训练的生成摘要的结果。
4. 音乐生成
Music Transformer 论文使用了只有 Decoder 的 Transformer 来生成具有表现力的时序和动态性的音乐。音乐建模就像语言建模一样,只需要让模型以无监督的方式学习音乐,然后让它采样输出(前面我们称这个为 漫步)。
你可能会好奇在这个场景中,音乐是如何表现的。请记住,语言建模可以把字符、单词、或者单词的一部分(token),表示为向量。在音乐表演中(让我们考虑一下钢琴),我们不仅要表示音符,还要表示速度–衡量钢琴键被按下的力度。
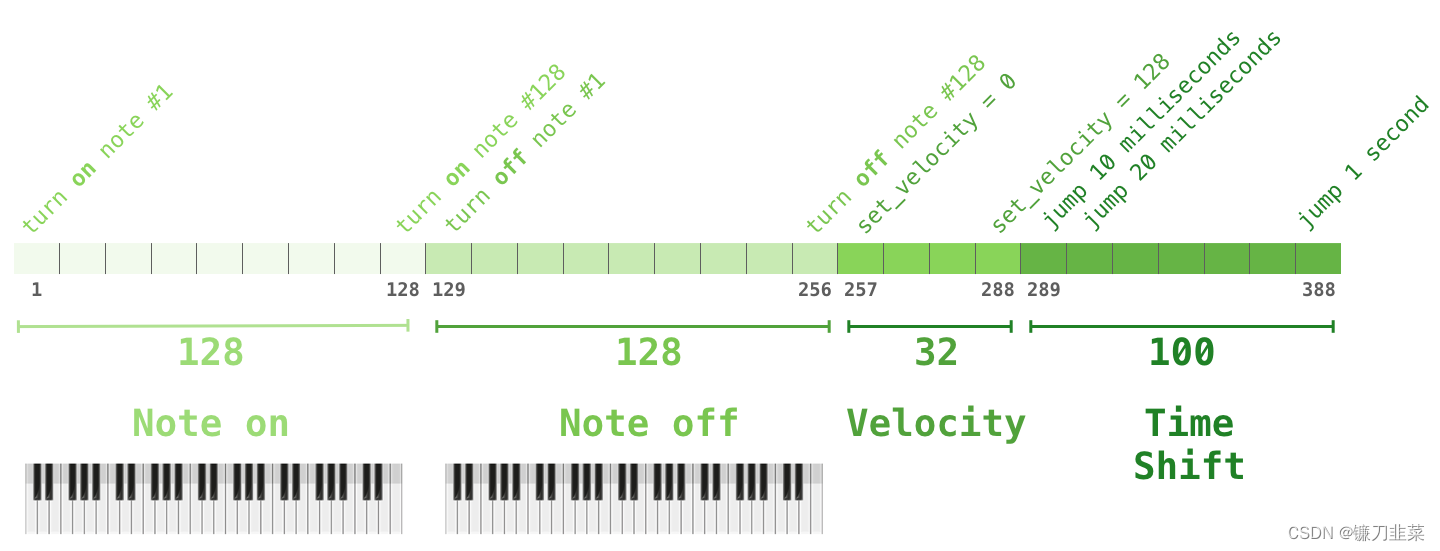
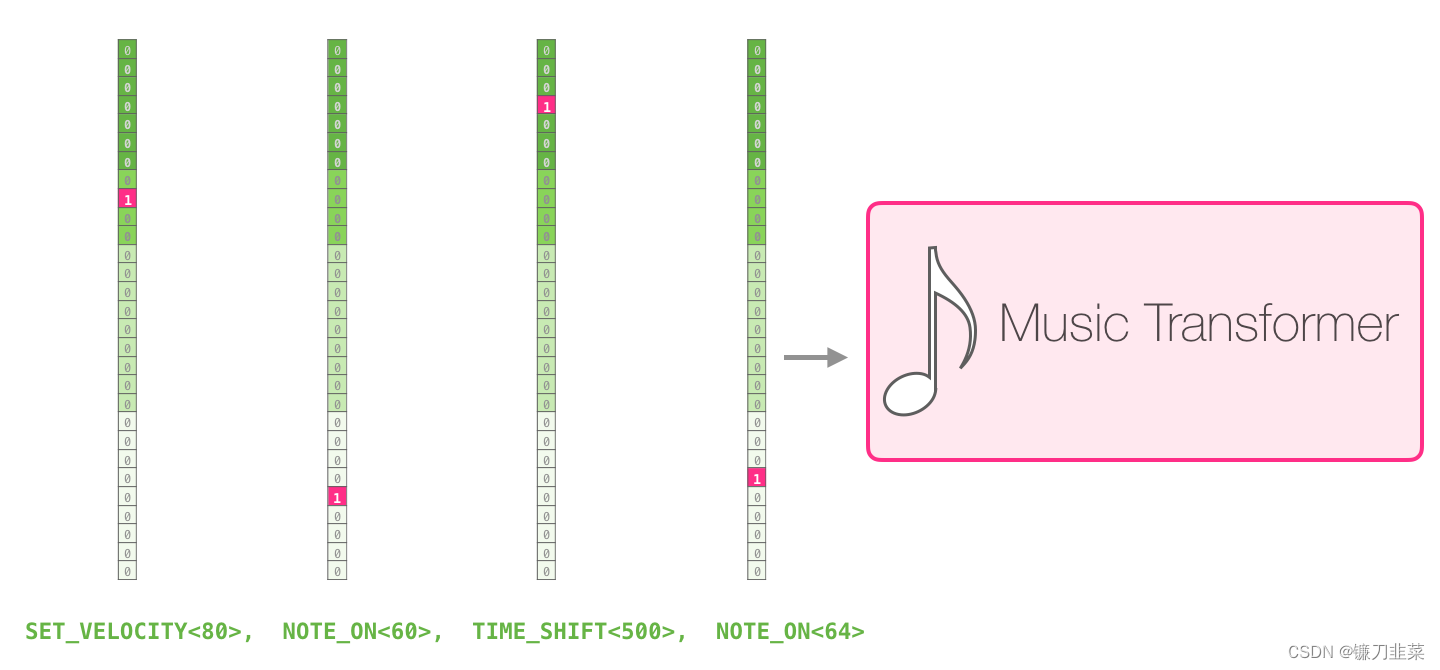
一场表演就是一系列的 one-hot 向量。一个 midi 文件可以转换为下面这种格式。论文里使用了下面这种输入序列作为例子:

这个输入系列的 one-hot 向量表示如下:
在这基础之上添加了一些注释:
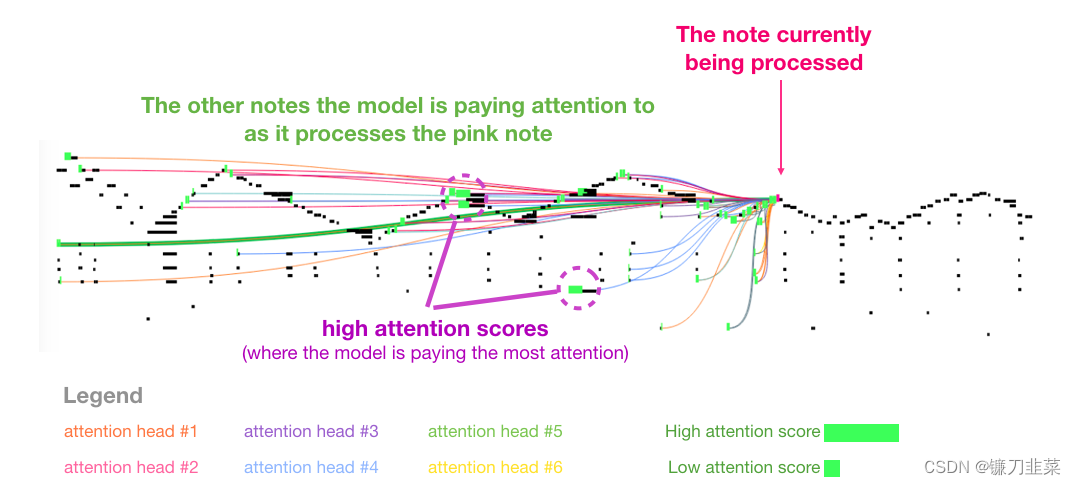
这段音乐有一个反复出现的三角形轮廓。Query 矩阵位于后面的一个峰值,它注意到前面所有峰值的高音符,以知道音乐的开头。这幅图展示了一个 Query 向量(所有 attention 线的来源)和前面被关注的记忆(那些受到更大的softmax 概率的高亮音符)。attention 线的颜色对应不同的 attention heads,宽度对应于 softmax 概率的权重。
GPT-2代码
- Open AI的GPT-2代码仓库:https://github.com/openai/gpt-2
- 查看Hugging Face的pytorch-transformers库。除了GPT2,它还实现了BERT、Transformer XL、XLNet和其他尖端transformers模型。