Gpt-1
论文:《Improving Language Understanding by Generative Pre-Training》
GPT-1网络结构
无监督,使用12层transforer decoder结构,每一层维度是768,12个注意力heads
token embedding矩阵,经过transformer decoder处理后,经过线性层和softmax层,得到下一个token的预测分布
位置编码3072维
Adam优化器,最大学习率为2.5e-4
token序列长度是512,100个epochs
激活函数使用GELU
正则化手段:残差网络、dropout,drop比例是0.1
有监督微调dropout比例0.1
有监督微调学习率6.25e-5,batchsize是32,训练epoch为3
二,无监督训练
给定一个无标注样本库的token序列集合,语言模型的目标就是最大化下面的似然值。也就是通过前面的tokens,预测下一个token。
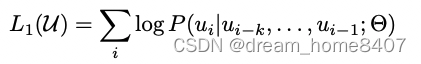
有监督微调
得到无监督的预训练模型后,将得到参数值直接应用于有监督任务中,对于一个有变迁的数据集c,将这些tokens输入到预训练模型中,再经过一个全链接+softmax得到预测结果,

对应文本分类任务而言,可以直接对预测模型进行fine-tune,由于我们的预测模型是在连续的文本序列上训练,对于某些具有结构化输入的task,需要我们对输入进行一些修改,
开始符号,中间符号,结束符号,将句子进行拼接,
GPT2
论文 Language Models are Unsupervised Multitask Learners
设计prompt,提示生成,
Zero-shot:下游任务不需要训练模型,
作者认为,只要语言模型的容量够大,训练数据足够丰富,仅仅依赖模型便可以同时完成其他下游监督任务,
网络结构,
和GPT-1没有太大差别,将输入维度和decoder层按比例放大,比如输入维度由原来的768增加至1024,堆叠的层数变为24层,
GPT-3
论文:《Language Models are Few-Shot Learners》
模型结构:
GPT-3沿用了GPT-2的结构,训练过程也与GPT-2类似。主要区别在于扩展了GPT-2的模型大小、数据集大小及多样性。在初始化、归一化以及tokenization等方面做了一些改进,同时借鉴了Sparse Transformer的优化点。文章也提到了一些模型并行方面的优化工作。为了验证模型容量对效果的影响,文章训练了8个不同容量的模型——参数范围从1.25亿参数到1750亿参数,跨越三个数量级,其中最大的模型被称作GPT-3。各个模型的参数如下图所示。值得注意的是,更大的模型一般会使用更大的batch size,但只需要更小的learning rate。
自回归模型,可学习参数,非稀疏,
堆叠96层decoder,输入维度12288 ,128个头,
层数增加后,输入维度也要增加,每一个批量训练大小是320万样本,批量更大,计算性能好,通信量变小,分布式计算会更好,
对于小的模型,数据更容易拟合,
模型越来越大,模型不容易过拟合,模型神经网络设计,不会像简单的MLP一样容易过拟合,
大力出奇迹,
few-shot ,
in-context learning上下文学习, few-shot ,少样本学习需要根据上下文,
in-context learning可以学习数值加法,文本纠错,和翻译,相同的格式之间具有相关性,通过上下文学习其中的规律,
模型评估,few-shot learning 在任务之前,翻译单词输入开始任务之前,加以三个左右的例子,让模型提取到更多的信息
one-shot learning 在任务描述后,翻译单词输入开始任务之前,加入一个例子,希望模型看到句子后,哪呢个根据有用的信息帮助你做后面的翻译,
zero-shot learning 对于翻译任务构建prompt对下面这句话进行翻译,然后加上翻译的单词
训练数据集:
common crawl 下载后把样本,分类器任务正例保留,负例去掉,去重使用的是lsh的方法,一篇文章是一些词的集合,和另外一篇很大文章集合中进行比较相似度,作者采样时候,一个bathsize中只选择60%
微调:
对每个标注好的样本,我可以计算损失,然后进行权重进行更新,微调学习率初始值要小一点,是从预训练模型开始训练的,
总结:
GPT系列从1到3历经两年多,使用的底层均依托transformer的解码器,在莫新钢结构方面没有让爱大的创新和改进,主要靠不断增加模型容量和超强的算力,GPT2主要讲述zero-shot,GPT3主要讲述类,few-shot-learning
尽管和apt-2相比,gpt-3性能已经非常出色,在质量和参数量方面都有明显的改进,但他们仍然存在一些局限性,
1,gpt-3在文本合成和几个nlp任务上,仍然存在显著的弱点,比如文本合成的任务,尽管总体质量很高,但是gpt-3会在较长的段落中社区连贯性,自相矛盾,偶尔还会生成不合逻辑的句子和段落,gpt系列均基于自回归语言模型结构(单向),这个结构的采样和计算都会简单,gpt-3相关实验均不包含任何双向结构或其他训练目标(如去噪),这种结构限制gpt-3的能力,作者推测,大型双向模型在微调方面比gpt-3更强,文章提出,基于gpt-3的规模,或者尝试使用few-shot/zero-shot learing训练一个双向语言模型,是未来一个非常有前景的方向,
写长文本还是有问题,可以写出每一段的标题
2,gpt-3和其他类似lm的模型一样,它将会落人预训练目标的极限,简而言之,大语言模型缺乏和真实世界的交互,因此缺乏有管世界的上下文信息,自监督训练可能会达到一个极限,因此需要使用不同的方法进行增强,作者提出,从人类哪里学习目标函数,通过强化学习进行微调,增加不同的模态,前两者就是instruct-gpt的工作了
3,语言模型普遍存在一个局限性是,在预训练阶段,样本的利用率低,尽管gpt-3在测试阶段,朝着更加接近人类的测试时间(one-shot或者zero-shot)但是它在预训练阶段看到的文本,仍然比人类一生中看到的文本还要多得多,
4,gpt-3的规模巨大,无论目标函数或算法如何,gpt-3的训练昂贵,且不方便进行推理,gpt3这样的大模型通常包含非常多的技能,但大多数不是特定任务所需要的,作者提出,解决上述问题的一个未来方向可能是对大模型进行蒸馏,业界已有针对蒸馏进行大量探索,但尚未在千亿参数下进行尝试,
5,gpt-3与大多数深度学习系统有一些共同的局限性-不可解释性,很难保证gpt-3生成一些文章不包含敏感词汇-比如宗教偏见,种族起始以及性别偏见
instructGPT
过程:1,收集标注好的数据集,用它来监督学习对gpt3进行微调,2,对模型输出的多个结果进行人工标注,按照由好到坏的顺序排序,再将排序结果的数据集进一步微调这个监督模型
目的:本文的主要目标是探索如何训练语言模型(LMs)来遵循用户的指示,执行各种任务,并提供有用和可靠的输出,对齐用户意图
实现的方法:人工反馈强化学习
一,sft(有监督微调),收集问答数据,然后使用监督学习在该数据集上进行微调预训练的gpt3模型.
二,奖励模型(RM)训练,给定预训练模型一些问题,然后让gpt对生成的答案,gpt生成下一单词的概率采样,采样通常采用,binsearch通常生成4个答案,然后人工判断,对这四个答案进行排序,给定模型输入和输出,使得输出就是答案的分数满足之前的排序关系,
三,sft后的模型在rm模型进行强化学习(RL),使得生成的答案在奖励模型中进行打分,然后根据打分去优化它的参数,使得gpt3最终的输出对齐人类的意图
最后的模型就是instuctGPT
RM模型的损失函数使用的是pairwise的ranking loss 以排序