目录
一、概要
与T5模型(
Text-to-Text Transfer Transformer,详见文末链接
)相似,OpenAI提出的GPT-3模型(第三代GPT)也是通过将不同形式的自然语言处理任务重定义为文本生成实现模型的通用化。两者的区别在于,GPT-3主要展示的是超大规模语言模型的小样本学习(Few-shot learning)能力。GPT-3模型的输入不仅以自然语言描述或者指令作为前缀表征目标任务,还使用少量的目标任务标注样本作为条件上下文。例如,对于机器翻译任务,在小样本的情况下,为了获得“ cheese ”的法语翻译,可以构建以下输入:
Translate English to French:
sea otter => outre de mer
plush girafe => girafe peluche
cheese =>
实验表明,GPT-3模型不需要任何额外的精调,就能够在只有少量目标任务标注样本的情况下进行很好的泛化。
二、深入扩展
GPT-3延续了GPT-2(第二代GPT)
的单向Transformer自回归语言模型结构,但是将规模扩大到了1750亿个参数。自回归语言模型为什么会具有小样本学习的能力呢?其关键在于数据本身的有序性,使得连续出现的序列数据往往会蕴含着同一任务的输入输出模式。因此,语言模型的学习过程实际上可以看作从很多不同任务中进行元学习的过程。 下图演示了这一过程。
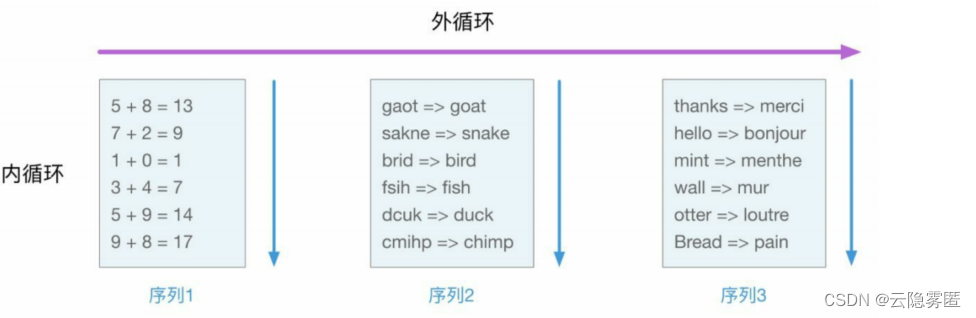
图中的每个序列都包含一个具体任务的多个连续样本,语言模型在该序列上的训练则为一次“内循环”(Inner loop),也称为“In-Context Learning ”。模型在不同序列上的训练则对应元学习的“外循环”(Outer loop),起到了在不同任务之间泛化的作用,以避免模型过拟合至某一个特定的任务。由此可见,数据的规模与质量对于GPT-3的小样本学习能力起到了关键的作用。
由于需要以少量标注样本作为条件,因此,GPT-3模型的输入序列可能较长。GPT-3使用了大小为2048的输入,相较于其他模型,其对于内存、计算量的要求都要更高。由于GPT-3庞大的参数量,目前在将 GPT-3用于下游任务时,主要是在小样本学习的设定下直接进行推理, 而不对模型本身作进一步的精调。