最近人工智能领域最火爆的话题非chatGPT以及最新发布的GPT-4模型莫属了。这两个生成式AI模型在问答、搜索、文本生成领域展现出的强大能力,每每让使用过它们的每个用户瞠目结舌、感叹不已。说到以上这两个GPT模型,相信大家也听说过、它们的 “超能力”来自于它们自身的超大模型尺寸,每运行一次AI推理都需要巨大的算力在背后来做支持,显然在本地设备上要运行这样的超大模型是不太可能的。
然而你知道吗,跟它们同属GPT模型家族的GPT-2模型在OpenVINO™开源工具套件的优化和加速下,在装有11代英特尔处理器N5105 2.0-2.9GHz (Jasper Lake)的这样不足千元的AI开发板上就能运行文本生成任务的推理。

AI艾克斯开发板
AIxBoard(爱克斯板)开发板是专为支持入门级边缘AI应用程序和设备而设计。能够满足人工智能学习、开发、实训等应用场景。
该开发板是类树莓派的x86主机,可支持Linux Ubuntu及 完整版Windows操作系统。板载一颗英特尔4核处理器,最高运行频率可达2.9 GHz,且内置核显(iGPU),板载 64GB eMMC存储及LPDDR4x 2933MHz(4GB/6GB/8GB),内置蓝牙和Wi-Fi模组,支持USB 3.0、HDMI视频输出、3.5mm音频接口,1000Mbps以太网口。完全可把它作为一台mini小电脑来看待,且其可集成一块Arduino Leonardo单片机,可外拓各种传感器模块。
此外, 其接口与Jetson Nano载板兼容,GPIO与树莓派兼容,能够最大限度地复用树莓派、Jetson Nano等生态资源,无论是摄像头物体识别,3D打印,还是CNC实时插补控制都能稳定运行。可作为边缘计算引擎用于人工智能产品验证、开发;也可以作为域控核心用于机器人产品开发。
x86架构使支持完整的Windows系统,不需要特殊优化就能直接获得Visual Studio、OpenVINO、OpenCV等最强大的软件支持,最成熟的开发生态,数百万的开源项目,给你的创意提供更多助力。无论您是一个DIY的狂热爱好者、交互设计师还是机器人专家,AI艾克斯开发板都是你理想的伙伴!
下面,就让我们通过以下手把手的教程,来看看这样的推理是怎么样在边缘AI 开发板上运行起来的吧。
如何安装
首先,需要在AI 开发板上安装OpenVINO Notebooks运行环境。由于AI 开发板上自带Windows操作系统,因此可以参考以下具体步骤在Windows上进行OpenVINO Notebooks运行环境的安装。
https://github.com/openvinotoolkit/openvino_notebooks/wiki/Windows
当然AI 开发板也非常方便的支持将系统刷成Linux系统,如果您是 Linux 用户,可点击此链接:https://github.com/openvinotoolkit/openvino_notebooks/wiki/Ubuntu

总体而言,通过以下三个安装步骤即可完成所有安装步骤,接着就可以加载所有的notebooks代码示例了。
-
安装 Python 3.10.x(或Python3.7,3.8或3.9版本),并创建一个虚拟环境
python3 -m venv openvino_env
openvino_env\Scripts\activate
-
对目录实施 Git 克隆 (如果你还没有安装Git,请先去这里安装)
git clone --depth=1 https://github.com/openvinotoolkit/openvino_notebooks.git
cd openvino_notebooks
-
安装所有的库和依赖项
pip install -r requirements.txt
-
运行 Jupyter Notebook
jupyter lab notebooks
在AI 艾克斯开发板上利用OpenVINO优化和部署GPT2
接下来,就让我们看看在AI 开发板上运行GPT2进行文本生成都有哪些主要步骤吧。
注意:以下步骤中的所有代码来自OpenVINO Notebooks开源仓库中的223-gpt2-text-prediction notebook 代码示例,您可以点击以下链接直达源代码。https://github.com/openvinotoolkit/openvino_notebooks/blob/main/notebooks/223-gpt2-text-prediction/223-gpt2-text-prediction.ipynb
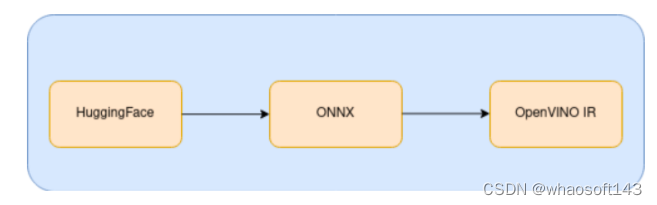
整个代码示例的运行流程如下图所示:

-
预处理首先定义分词。 本次文本生成任务的输入为一个自然语言的序列,在此基础上,GPT-2模型会生成相关内容的长文本。由于自然语言处理模型通常将一个分词的列表作为标准输入,一个分词通常是将一个单词映射成的一个整数值。因此,为了提供正确的输入,我们使用词汇表文件来处理映射。首先让我们加载词汇表文件,代码如下:
1.# this function converts text to tokens
2.def tokenize(text):
3. """
4. tokenize input text using GPT2 tokenizer
5.
6. Parameters:
7. text, str - input text
8. Returns:
9. input_ids - np.array with input token ids
10. attention_mask - np.array with 0 in place, where should be padding and 1 for places where original tokens are located, represents attention mask for model
11. """
12.
13. inputs = tokenizer(text, return_tensors="np")
14. return inputs["input_ids"], inputs["attention_mask"]
其中,eos_token是一个特殊的token,这意味着生成已经完成。我们存储此token的索引,以便在稍后阶段使用这个索引作为填充。
1.eos_token_id = tokenizer.eos_token_id
定义Softmax层。由于GPT-2模型推理的结果是以logits的形式呈现的,因此我们需要定义一个softmax函数,用于将前k个logits转换为概率分布,从而在选择最终的文本预测的结果时挑选概率最大的推理结果。
1.import numpy as np
2.
3.
4.def softmax(x):
5. e_x = np.exp(x - np.max(x, axis=-1, keepdims=True))
6. summation = e_x.sum(axis=-1, keepdims=True)
7. return e_x / summation
确定最小序列长度。如果没有达到最小序列长度,下面的代码将降低eos token出现的概率。这将继续生成下一个单词的过程。
1.def process_logits(cur_length, scores, eos_token_id, min_length=0):
2. """
3. reduce probability for padded indicies
4.
5. Parameters:
6. cur_length - current length of input sequence
7. scores - model output logits
8. eos_token_id - index of end of string token in model vocab
9. min_length - minimum length for appling postprocessing
10. """
11. if cur_length < min_length:
12. scores[:, eos_token_id] = -float("inf")
13. return scores
Top-K采样。在Top-K采样中,我们过滤了K个最有可能的下一个单词,并仅在这K个下一个词中重新分配概率质量。 1.def get_top_k_logits(scores, top_k):
2. """
3. perform top-k sampling
4.
5. Parameters:
6. scores - model output logits
7. top_k - number of elements with highest probability to select
8. """
9. filter_value = -float("inf")
10. top_k = min(max(top_k, 1), scores.shape[-1])
11. top_k_scores = -np.sort(-scores)[:, :top_k]
12. indices_to_remove = scores < np.min(top_k_scores)
13. filtred_scores = np.ma.array(scores, mask=indices_to_remove,
14. fill_value=filter_value).filled()
15. return filtred_scores
-
加载模型并转换为OpenVINO IR格式
下载模型。
1.from transformers import GPT2Tokenizer, GPT2LMHeadModel
2.
3.tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
4.pt_model = GPT2LMHeadModel.from_pretrained('gpt2')
运行结果如下图所示
这里我们要使用开源在HuggingFace的GPT-2模型,需先将原始为PyTorch格式的模型,通过转换到ONNX,从而在OpenVINO中得到优化及推理加速。我们将使用HuggingFace Transformer库功能将模型导出到ONNX。有关Transformer导出到ONNX的更多信息,请参阅HuggingFace文档。转换为ONNX格式后的模型文件,再通过OpenVINO的模型优化器MO转换为OpenVINO IR格式的模型文件。
1.from pathlib import Path
2.from openvino.runtime import serialize
3.from openvino.tools import mo
4.from transformers.onnx import export, FeaturesManager
5.
6.
7.# define path for saving onnx model
8.onnx_path = Path("model/gpt2.onnx")
9.onnx_path.parent.mkdir(exist_ok=True)
10.
11.# define path for saving openvino model
12.model_path = onnx_path.with_suffix(".xml")
13.
14.# get model onnx config function for output feature format casual-lm
15.model_kind, model_onnx_config = FeaturesManager.check_supported_model_or_raise(pt_model, feature='causal-lm')
16.
17.# fill onnx config based on pytorch model config
18.onnx_config = model_onnx_config(pt_model.config)
19.
20.# convert model to onnx
21.onnx_inputs, onnx_outputs = export(tokenizer, pt_model, onnx_config, onnx_config.default_onnx_opset, onnx_path)
22.
23.# convert model to openvino
24.ov_model = mo.convert_model(onnx_path, compress_to_fp16=True, input="input_ids[1,1..128],attention_mask[1,1..128]")
25.
26.# serialize openvino model
27.serialize(ov_model, str(model_path))
接着加载OpenVINO IR格式的模型到CPU上进行推理
1.from openvino.runtime import Core
2.
3.# initialize openvino core
4.core = Core()
5.
6.# read the model and corresponding weights from file
7.model = core.read_model(model_path)
8.
9.# compile the model for CPU devices
10.compiled_model = core.compile_model(model=model, device_name="CPU")
11.
12.# get output tensors
13.output_key = compiled_model.output(0)
在GPT-2的情况下,我们将批大小(batch size)和序列长度(sequence length)作为输入,将批大小、序列长度和vocab大小作为输出。
-
定义文本生成主函数
接下来,我们定义文本生成的主函数
1.def generate_sequence(input_ids, attention_mask, max_sequence_length=128,
2. eos_token_id=eos_token_id, dynamic_shapes=True):
3. """
4. text prediction cycle.
5.
6. Parameters:
7. input_ids: tokenized input ids for model
8. attention_mask: attention mask for model
9. max_sequence_length: maximum sequence length for stop iteration
10. eos_token_ids: end of sequence index from vocab
11. dynamic_shapes: use dynamic shapes for inference or pad model input to max_sequece_length
12. Returns:
13. predicted token ids sequence
14. """
15. while True:
16. cur_input_len = len(input_ids[0])
17. if not dynamic_shapes:
18. pad_len = max_sequence_length - cur_input_len
19. model_input_ids = np.concatenate((input_ids, [[eos_token_id] * pad_len]), axis=-1)
20. model_input_attention_mask = np.concatenate((attention_mask, [[0] * pad_len]), axis=-1)
21. else:
22. model_input_ids = input_ids
23. model_input_attention_mask = attention_mask
24. outputs = compiled_model({"input_ids": model_input_ids, "attention_mask": model_input_attention_mask})[output_key]
25. next_token_logits = outputs[:, cur_input_len - 1, :]
26. # pre-process distribution
27. next_token_scores = process_logits(cur_input_len,
28. next_token_logits, eos_token_id)
29. top_k = 20
30. next_token_scores = get_top_k_logits(next_token_scores, top_k)
31. # get next token id
32. probs = softmax(next_token_scores)
33. next_tokens = np.random.choice(probs.shape[-1], 1,
34. p=probs[0], replace=True)
35. # break the loop if max length or end of text token is reached
36. if cur_input_len == max_sequence_length or next_tokens == eos_token_id:
37. break
38. else:
39. input_ids = np.concatenate((input_ids, [next_tokens]), axis=-1)
40. attention_mask = np.concatenate((attention_mask, [[1] * len(next_tokens)]), axis=-1)
41. return input_ids
-
运行主函数,生成文本
最后,让我们来输入一句话,再由此让GPT-2模型在此基础上生成一段文本:
1.import time
2.text = "Deep learning is a type of machine learning that uses neural networks"
3.input_ids, attention_mask = tokenize(text)
4.
5.start = time.perf_counter()
6.output_ids = generate_sequence(input_ids, attention_mask)
7.end = time.perf_counter()
8.output_text = " "
9.# Convert IDs to words and make the sentence from it
10.for i in output_ids[0]:
11. output_text += tokenizer.convert_tokens_to_string(tokenizer._convert_id_to_token(i))
12.print(f"Generation took {end - start:.3f} s")
13.print("Input Text: ", text)
14.print()
15.print(f"Predicted Sequence:{output_text}")
运行结果如下图所示:

可以看到,即使是在我们这款千元不到的AI 开发板上,运行GPT-2模型进行文本生成也是完全可以支持的。也由此可见,在边缘运行生成性的工作负载(比如我们这里介绍的文本生成)是一项完全可以实现的任务,而尽可能靠近数据产生地,也是人工智能可扩展性和可落地性的关键。
小结:
整个的步骤就是这样!现在就开始跟着我们提供的代码和步骤,动手在你的边缘设备上尝试用Open VINO优化和加速GPT-2吧。 whaosoft aiot http://143ai.com
关于英特尔OpenVINOTM开源工具套件的详细资料,包括其中我们提供的三百多个经验证并优化的预训练模型的详细资料,请您点击 https://www.intel.com/content/www/us/en/developer/tools/openvino-toolkit/overview.html
除此之外,为了方便大家了解并快速掌握OpenVINOTM的使用,我们还提供了一系列开源的Jupyter notebook demo。运行这些notebook,就能快速了解在不同场景下如何利用OpenVINOTM实现一系列、包括计算机视觉、语音及自然语言处理任务。OpenVINOTM notebooks的资源可以在Github这里下载安装:https://github.com/openvinotoolkit/openvino_notebooks 。