在tensorflow程序中,推荐使用tensorflow内定标准格式——TFRecords,这是一种通用的有利于高效读取文件。TFRecords其实是一种二进制文件,虽然它不如其他格式好理解,但是它能更好的利用内存,更方便复制和移动,并且不需要单独的标签文件。
TFRecords文件包含了tf.train.Example 协议内存块(protocol buffer)(协议内存块包含了字段 Features)。我们可以写一段代码获取你的数据, 将数据填入到Example协议内存块(protocol buffer),将协议内存块序列化为一个字符串, 并且通过tf.python_io.TFRecordWriter 写入到TFRecords文件。
从TFRecords文件中读取数据, 可以使用tf.TFRecordReader的tf.parse_single_example解析器。这个操作可以将Example协议内存块(protocol buffer)解析为张量。
下面我们直接通过代码片段体会TFRecords的生成和读取显示
# -*- coding: utf-8 -*-
import argparse
import sys
import pandas as pd
import tensorflow as tf
import os
os.environ['TF_CPP_MIN_LOG_LEVEL']='3'
FLAGS = None
"""
创建并生成tfrecords文件
"""
def saveTfRecords(data_set, name):
user_id = data_set.user_id
age = data_set.age
sex = data_set.sex
user_lv_cd = data_set.user_lv_cd
user_reg_dt = data_set.user_reg_dt
filename = os.path.join(FLAGS.dir_path, name + '.tfrecords')
writer = tf.python_io.TFRecordWriter(filename)
for index in range(user_id.size):
# print(age[index])
example = tf.train.Example(features=tf.train.Features(feature={
'user_id': tf.train.Feature(int64_list = tf.train.Int64List(value=[user_id[index]])),
'age': tf.train.Feature(bytes_list = tf.train.BytesList(value=[str.encode(str(age[index]))])),
'sex': tf.train.Feature(float_list = tf.train.FloatList(value=[sex[index]])),
'user_lv_cd': tf.train.Feature(int64_list = tf.train.Int64List(value=[user_lv_cd[index]])),
'user_reg_dt': tf.train.Feature(bytes_list = tf.train.BytesList(value=[str.encode(str(user_reg_dt[index]))]))
}))
writer.write(example.SerializeToString())
writer.close()
"""
读取tfrecords文件
"""
def readTfRecords(name):
filename = os.path.join(FLAGS.dir_path, name + '.tfrecords')
filename_queue = tf.train.string_input_producer([filename])
reader = tf.TFRecordReader()
_,serialized_example = reader.read(filename_queue)
features = tf.parse_single_example(
serialized_example,
features={
'user_id': tf.FixedLenFeature([],tf.int64),
'age': tf.FixedLenFeature([],tf.string),
'sex': tf.FixedLenFeature([],tf.float32),
'user_lv_cd': tf.FixedLenFeature([],tf.int64),
'user_reg_dt': tf.FixedLenFeature([],tf.string),
})
user_id = features['user_id']
age = features['age']
sex = features['sex']
user_lv_cd = features['user_lv_cd']
user_reg_dt = features['user_reg_dt']
return user_id,age,sex,user_lv_cd,user_reg_dt
"""
读取csv文件
"""
def getDataSet(file_path):
csv = pd.read_csv(file_path)
return csv
"""
print读取的tfrecords文件,这个是逐行读取,其中由于tensorflow不支持转换为string,采用了bytes.decode转换
"""
def printRecords(user_id, age, sex, user_lv_cd, user_reg_dt):
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
threads = tf.train.start_queue_runners(sess=sess)
for i in range(10):
val_user_id, val_age, val_sex, val_user_lv_cd, val_user_reg_dt = sess.run(
[user_id, age, sex, user_lv_cd, user_reg_dt])
print(val_user_id, bytes.decode(val_age), val_sex, val_user_lv_cd, bytes.decode(val_user_reg_dt))
"""
print读取的tfrecords文件,这个批量读取(分为批量打乱读取和批量读取),一般实际训练模型采用这种读取方式。
"""
def calcRecords(m_user_id, m_age, m_sex, m_user_lv_cd, m_user_reg_dt):
user_id = tf.cast(m_user_id,tf.int64)
age = tf.cast(m_age,tf.string)
sex = tf.cast(m_sex,tf.int64)
user_lv_cd = tf.cast(m_user_lv_cd,tf.int64)
user_reg_dt = tf.cast(m_user_reg_dt,tf.string)
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
# tf.train.shuffle_batch批量打乱并数据
val_user_id, val_age, val_sex, val_user_lv_cd, val_user_reg_dt = tf.train.shuffle_batch([user_id, age, sex, user_lv_cd, user_reg_dt],
batch_size=10,
capacity=2000,
min_after_dequeue=1000,
num_threads=12)
# tf.train.batch批量取数据
# val_user_id, val_age, val_sex, val_user_lv_cd, val_user_reg_dt = tf.train.batch([user_id, age, sex, user_lv_cd, user_reg_dt],
# batch_size=10,
# capacity=2000,
# num_threads=12)
threads = tf.train.start_queue_runners(sess=sess)
for i in range(10):
p_user_id, p_age, p_sex, p_user_lv_cd, p_user_reg_dt = sess.run([val_user_id, val_age, val_sex, val_user_lv_cd, val_user_reg_dt])
print(p_user_id, p_sex, p_user_lv_cd)
def main(unused_argv):
"""
csv文件,格式:
user_id,age,sex,user_lv_cd,user_reg_dt
1,46-55岁,0,5,2004-10-12
2,19-25岁,2,3,2013-04-10
3,26-35岁,2,4,2016-01-26
4,-1,2,1,2016-01-26
5,-1,2,3,2016-01-26
6,-1,2,1,2016-01-26
7,19-25岁,2,3,2016-01-26
8,26-35岁,2,3,2016-01-26
9,26-35岁,0,4,2013-04-10
10,26-35岁,0,3,2016-01-26
"""
# save train TfRecords文件
train_data_set = getDataSet(FLAGS.train_path)
saveTfRecords(train_data_set, 'train')
# save train TfRecords文件
test_data_set = getDataSet(FLAGS.test_path)
saveTfRecords(test_data_set, 'test')
# read train TfRecords文件
user_id, age, sex, user_lv_cd, user_reg_dt = readTfRecords("train")
calcRecords(user_id, age, sex, user_lv_cd, user_reg_dt)
# read test TfRecords文件
user_id, age, sex, user_lv_cd, user_reg_dt = readTfRecords("test")
printRecords(user_id, age, sex, user_lv_cd, user_reg_dt)
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument(
'--train_path',
type=str,
default=r"E:\jdata_user\JData_User.csv",
help='read train file'
)
parser.add_argument(
'--test_path',
type=str,
default=r"E:\jdata_user\JData_User_Test.csv",
help='read test file'
)
parser.add_argument(
'--dir_path',
type=str,
default=r"E:\jdata_user",
help='Directory to save data files and write the converted result'
)
FLAGS, unparsed = parser.parse_known_args()
tf.app.run(main=main, argv=[sys.argv[0]] + unparsed)
注:
(1)上述代码片段是对演示TFRecords文件的生成和读取显示过程,其中包含了对字符串的特殊处理过程,由于tf.train.Feature不支持string类型,所以save时候把字符串转换为byte后在读取时候再转换为string显示。
(2)在实际tensorflow使用场景中,一般字符串不参加运算,所以在生成TFRecords文件不建议包含字符串变量(如果必须包含字符串建议转化为词向量参与运算)
(3)本代码片段所涉及文件结果如下图

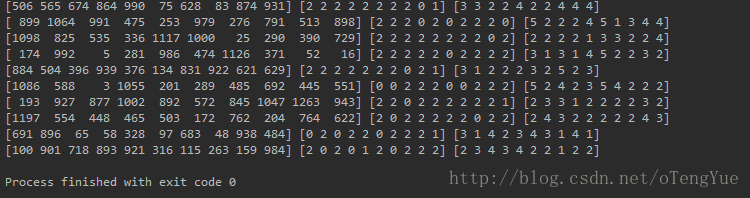
(4)一般读取数据并训练模型采用上述代码片段中的calcRecords函数的方式(打乱数据顺序并批量读取),读取显示后的效果如下:
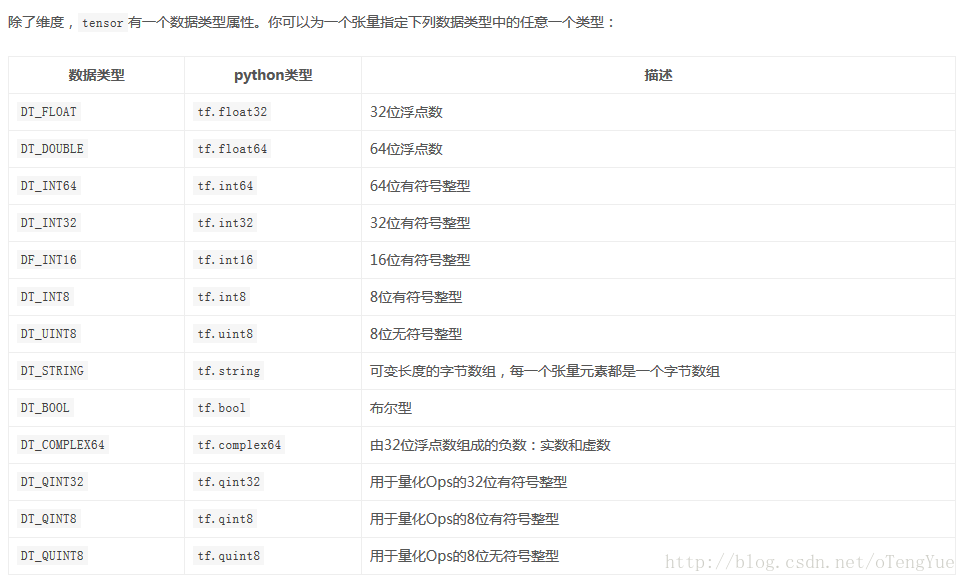
扩展:tensorflow中的数据类型