TensorFlow提供了一种TFRecords的格式来统一存储数据。理论上,TFRecords可以存储任何形式的数据 , TFRecords文件的是以tf.train.Example Protocol Buffer的格式存储的。以下的代码给出了tf.train.Example的数据结构:
message Example {
Features features = 1;
};
message Features {
map<string, Feature> feature = 1;
};
message Feature {
oneof kind {
BytesList bytes_list = 1;
FloatList float_list = 2;
Int64List int64_list = 3;
}
};首先介绍一下我接下来要展示给大家的工程结构(使用的IDE是 pycharm 2017 community):
接下来代码分三个文件, 分别是 加载数据 prepare_data.py ,制作tfrecords文件 make_data.py, 读取tfrecords文件read_data.py。
1.prepare_data.py
下面代码中数据增强部分我就略过了,可以参考tensorflow数据增强
# -*- coding: utf-8 -*-
import os
import cv2
import numpy as np
dir = "imgs/" # 加载jpg, testShape = (333, 500, 3)
def data_augmentation(data):
"""
数据增强处理
:param data:
:return:
"""
return data
def get_img_data(file_dir):
"""
获取图片数据, 返回类型是 list
:param file_dir: 图片所在目录
:return: 返回类型是 list
"""
files = [os.path.join('imgs', x) for x in os.listdir(file_dir)]
raw_data = [cv2.imread(img) for img in files]
raw_data = data_augmentation(raw_data)
return raw_data
if __name__ == "__main__":
get_img_data(dir)
- make_data.py
# _*_ coding: utf-8 _*_
import tensorflow as tf
import numpy as np
from prepare_data import get_img_data
# tfrecords 支持的数据类型
# tf.train.Feature(int64_list = tf.train.Int64List(value=[int_scalar]))
# tf.train.Feature(bytes_list = tf.train.BytesList(value=[array_string_or_byte]))
# tf.train.Feature(bytes_list = tf.train.FloatList(value=[float_scalar]))
# 创建tfrecords文件
file_nums = 2
instance_per_file = 5
dir = "imgs/"
data = get_img_data(dir) # type(data) list
for i in range(file_nums):
tfrecords_filename = './tfrecords/train.tfrecords-%.5d-of-%.5d' % (i, file_nums)
writer = tf.python_io.TFRecordWriter(tfrecords_filename) # 创建.tfrecord文件
for j in range(instance_per_file):
# type(data[i*instance_per_file+j]) numpy.ndarray
img_raw = np.asarray(data[i*instance_per_file+j]).tostring()
example = tf.train.Example(features=tf.train.Features(
feature={
'label': tf.train.Feature(int64_list=tf.train.Int64List(value=[j])),
'img_raw': tf.train.Feature(bytes_list=tf.train.BytesList(value=[img_raw]))
}))
writer.write(example.SerializeToString())
writer.close()
- read_data.py
import tensorflow as tf
import numpy as np
import cv2
import matplotlib.pyplot as plt
# 读取tfrecords文件
# --------------hyperParams--------------------------
batch_size = 2
capacity = 1000 + 3*batch_size
train_rounds = 3
num_epochs = 30
img_h = 333
img_w = 500
# ---------------------------------------------------
tfrecord_files = tf.train.match_filenames_once('./tfrecords/train.tfrecords-*')
queue = tf.train.string_input_producer(tfrecord_files, num_epochs=num_epochs, shuffle=True, capacity=10)
reader = tf.TFRecordReader()
# 从文件中读出一个队列, 也可以使用read_uo_to函数一次性读取多个样例
_, serialized_example = reader.read(queue)
# 读取多个对应tf.parse_example()
# 读取单个对应tf.parse_single_example()
features = tf.parse_single_example(
serialized_example, features={
'label': tf.FixedLenFeature([], tf.int64),
'img_raw': tf.FixedLenFeature([], tf.string),
}
)
image = tf.decode_raw(features['img_raw'], tf.uint8)
# image_shape = tf.stack([img_h, img_w, 3])
image = tf.reshape(image, [img_h, img_w, 3])
label = tf.cast(features['label'], tf.int64)
# tf.train.shuffle_batch()
to_train_batch, to_label_batch = tf.train.shuffle_batch(
[image, label], batch_size=batch_size, capacity=capacity,
allow_smaller_final_batch=True, num_threads=1, min_after_dequeue=1
)
with tf.Session() as sess:
sess.run(
tf.group(tf.local_variables_initializer(), tf.global_variables_initializer())
)
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
for i in range(train_rounds):
train_batch, label_batch = sess.run([to_train_batch, to_label_batch])
plt.subplot(121)
plt.imshow(train_batch[0])
plt.subplot(122)
plt.imshow(train_batch[1])
plt.show()
coord.request_stop()
coord.join(threads)
print('finish all')
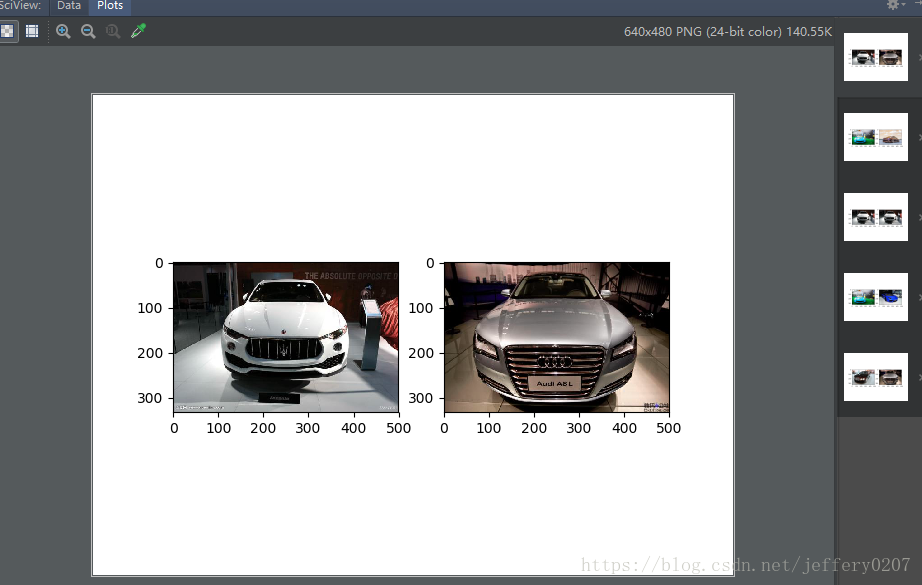
# 下图是read_data.py 读取 tfrecords 的结果: