全文共9000余字,预计阅读时间约18~30分钟 | 满满干货(附代码),建议收藏!

一、介绍
贝叶斯优化方法已被认定为超参数优化领域的最先进技术,即State of the Art(SOTA)。在效率和性能上表现出卓越的大部分超参数优化方案都是基于贝叶斯优化理念构建的。
对于网格搜索、随机网格搜索与Halving网格搜索三种搜索方式来说,无论构建的思想如何变化,其根本都是在一个大参数空间中、对所有点进行验证后再返回最优损失函数值,尽管随机和Halving等策略可以缩短训练时间和适应大数据及大参数空间,但这些方法仍然无法在效率和精度上做到双赢。为了更快地进行参数搜索并找到具有最佳泛化能力的参数,比较优秀的做法是使用带有先验过程的调参工具,如基于贝叶斯过程的调参工具。
二、 贝叶斯优化基本概念
2.1 工作原理
贝叶斯优化的工作原理是:首先对目标函数的全局行为建立先验知识(通常用高斯过程来表示),然后通过观察目标函数在不同输入点的输出,更新这个先验知识,形成后验分布。基于后验分布,选择下一个采样点,这个选择既要考虑到之前观察到的最优值(即利用),又要考虑到全局尚未探索的区域(即探索)。这个选择的策略通常由所谓的采集函数(Acquisition Function)来定义,比如最常用的期望提升(Expected Improvement),这样,贝叶斯优化不仅可以有效地搜索超参数空间,还能根据已有的知识来引导搜索,避免了大量的无用尝试。
是不是看着有点懵逼,哈哈,没关系,看完本文,你能轻松的理解这个过程!
贝叶斯优化非常强大,但整体的学习难度却非常高。想学好贝叶斯优化,需要充分理解机器学习的主要概念和算法、熟悉典型的超参数优化流程,还需要对部分超出微积分、概率论和线性代数的数学知识有所掌握。特别的是,贝叶斯优化算法本身,与贝叶斯优化用于HPO的过程还有区别。
所以本文的重点是:掌握贝叶斯优化用于HPO的核心过程。
2.2 求解函数最小值的思路
先不考虑HPO的问题,看下这个例子。
假设现在已经知道了一个函数 f ( x ) f(x) f(x)的表达式以及其自变量 x x x的定义域,希望求解出 x x x的取值范围上 f ( x ) f(x) f(x)的最小值,如何能求解出这个最小值?
面对这个问题,通常有以下三种解决思路:
- 对 f ( x ) f(x) f(x)求导、令其一阶导数为0来求解其最小值
限制:函数 f ( x ) f(x) f(x)可微,且微分方程可以直接被求解
- 通过梯度下降等优化方法迭代出 f ( x ) f(x) f(x)的最小值
限制:函数 f ( x ) f(x) f(x)可微,且函数本身为凸函数
- 将全域的 x x x带入 f ( x ) f(x) f(x)计算出所有可能的结果,再找出最小值
限制:函数 f ( x ) f(x) f(x)相对不复杂、自变量维度相对低、计算量可以承受
当知道函数 f ( x ) f(x) f(x)的表达式时,以上方法常常能够有效,但每个方法都有自己的前提条件。假设现在函数 f ( x ) f(x) f(x)是一个平滑均匀的函数,但它异常复杂、且不可微,就无法使用上述三种方法中的任意一种方法求解。
一种有效的解决思路如下:
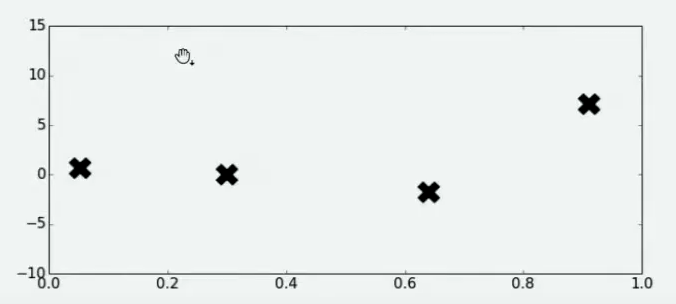
Step 1:在 x x x的定义域上随机选择了4个点,并将4个点带入 f ( x ) f(x) f(x)进行计算
通过随机抽样部分观测点来观察整个函数可能存在的趋势。
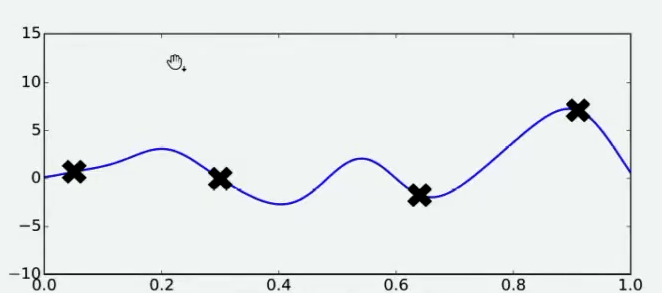
Step 2:当有了4个观测值后,对函数的整体分布可以有如下猜测,从而找到该函数的最小值。
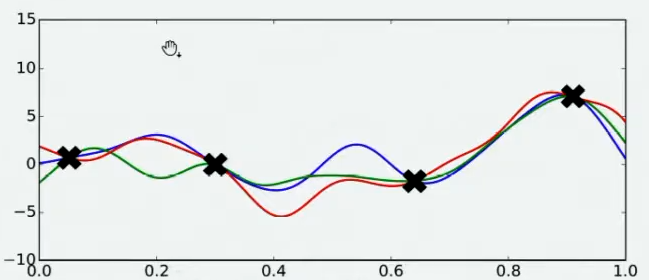
Step 3: 不同的人可能对函数的整体分布有不同的猜测,不同猜测下对应的最小值也是不同的。
Step 4 : 假设有数万个人对该函数的整体分布做出猜测,每个人所猜测的曲线如图所示:
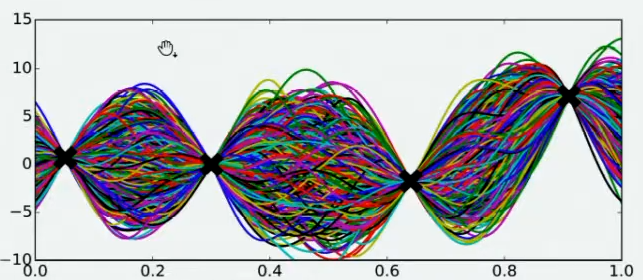
从图像上分析:在观测点的附近(也就是最开始选取的那四个点),每个人猜测的函数值差距不大,但是在远离远侧点的地方,每个人猜测的函数值就高度不一致了。**因为观测点之间函数的分布如何完全是未知的,该分布离观测点越远时,越不确定真正的函数值在哪里,**因此人们猜测的函数值的范围非常巨大。
Step 5:将所有猜测求均值,并将任意均值周围的潜在函数值所在的区域用色块表示,得到一条所有人猜测的平均曲线。
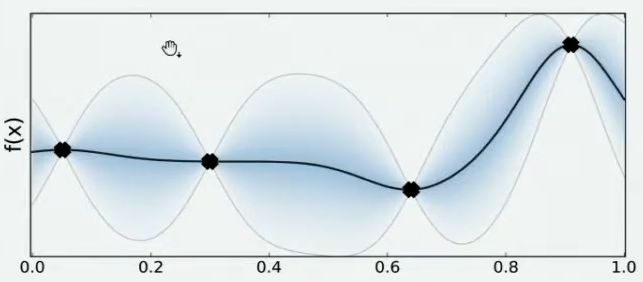
色块所覆盖的范围就是Step 4 中 数万人猜测的函数值的上界和下界,任意 x x x所对应的上下界差异越大,表示人们对函数上该位置的猜测值的越不确定。上下界差异可以衡量人们对该观测点的置信度,色块范围越大,置信度越低。
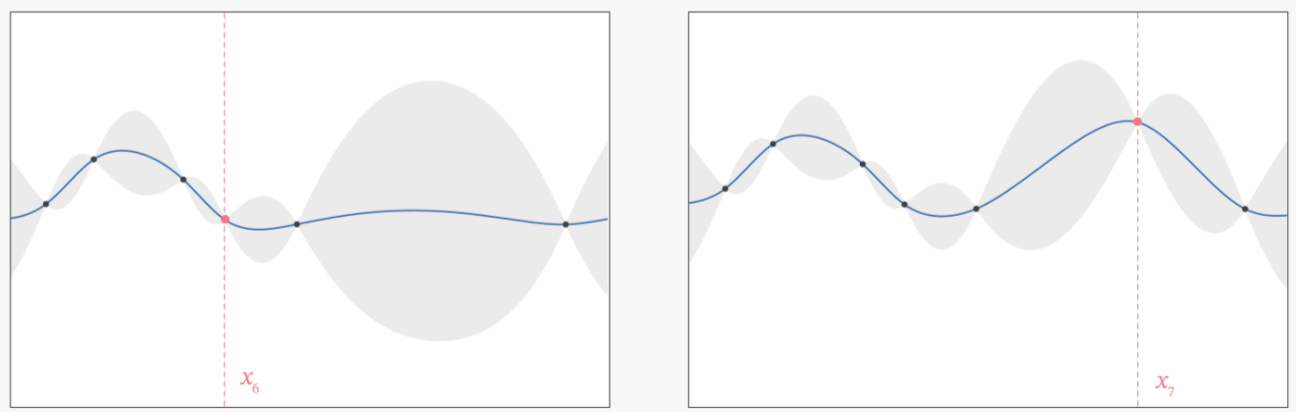
Step 6:在置信度很低的地方补充一个实际的观测点,将数万人的猜测统一起来。**
因为在观测点周围,置信度总是很高的,远离观测点的地方,置信度总是很低,当在置信度很低的区间内取一个实际观测值时,围绕该区间的“猜测”会立刻变得集中,该区间内的置信度会大幅升高。比如 x 6 x_6 x6和 x 7 x_7 x7这两个新增的点。
当整个函数上的置信度都非常高时,就得出了一条与真实的 f ( x ) f(x) f(x)曲线高度相似的曲线 f ∗ f^* f∗,从而将曲线 f ∗ f^* f∗熵的最小值,作为真实的 f ( x ) f(x) f(x)的最小值(因为从始至终都不知道真实 f ( x ) f(x) f(x)的函数分布)
估计越准确, f ∗ f^* f∗越接近 f ( x ) f(x) f(x),则 f ∗ f^* f∗的最小值也会越接近于 f ( x ) f(x) f(x)的真实最小值。
如何才能够让 f ∗ f^* f∗更接近 f ( x ) f(x) f(x)呢?根据刚才提升置信度的过程,很明显——观测点越多,估计出的曲线会越接近真实的 f ( x ) f(x) f(x)。每次进行观测时都要非常谨慎地选择观测点。
Step 7:使用合适的选择观测点方式
方法很多,其中一个最简单的手段是使用最小值出现的频数进行判断。
由于不同的人对函数的整体分布有不同的猜测,不同猜测下对应的最小值也是不同的,根据每个人猜测的函数结果,在 X X X轴上将定义域区间均匀划分为100个小区间,如果有某个猜测的最小值落在其中一个区间中,就对该区间进行计数。当有数万个人进行猜测之后,同时也绘制了基于 X X X轴上不同区间的频数图,频数越高,说明猜测最小值在该区间内的人越多,反之则说明该猜测最小值在该区间内的人越少。该频数一定程度上反馈出最小值出现的概率,频数越高的区间,函数真正的最小值出现的概率越高。
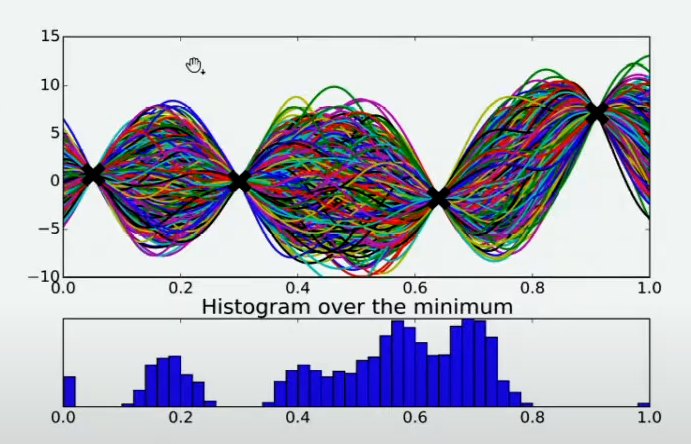
Step 8: 确定下一个观测点
当将 X X X轴上的区间划分得足够细后,绘制出的频数图可以变成概率密度曲线,曲线的最大值所对应的点是 f ( x ) f(x) f(x)的最小值的概率最高,因此将曲线最大值所对应的点确认为下一个观测点。
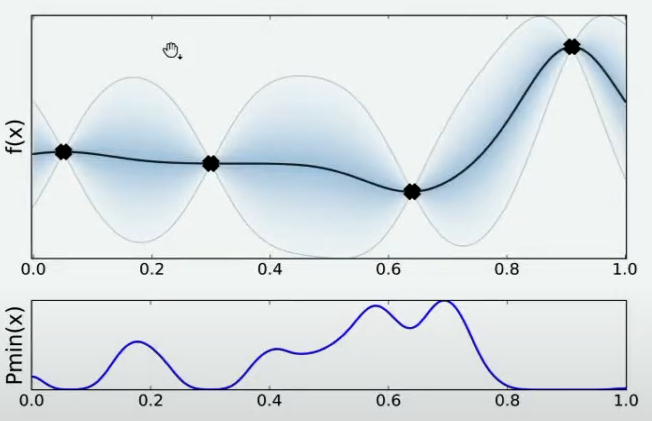
根据图像,最小值最有可能在的区间就在x=0.7左右的位置。
Step 9 : 不断重复此过程
当在x=0.7处取出观测值之后,就有了5个已知的观测点。再让数万人根据5个已知的观测点对整体函数分布进行猜测,猜测完毕之后再计算当前最小值频数最高的区间,然后再取新的观测点对 f ( x ) f(x) f(x)进行计算。当允许的计算次数被用完之后(比如,500次),整个估计也就停止了。
在这个过程当中,其实在不断地优化对目标函数 f ( x ) f(x) f(x)的估计,虽然没有对 f ( x ) f(x) f(x)进行全部定义域上的计算,也没有找到最终确定一定是 f ( x ) f(x) f(x)分布的曲线,但是随着观测的点越来越多,对函数的估计是越来越准确的,因此也有越来越大的可能性可以估计出 f ( x ) f(x) f(x)真正的最小值。这个优化的过程,就是贝叶斯优化。
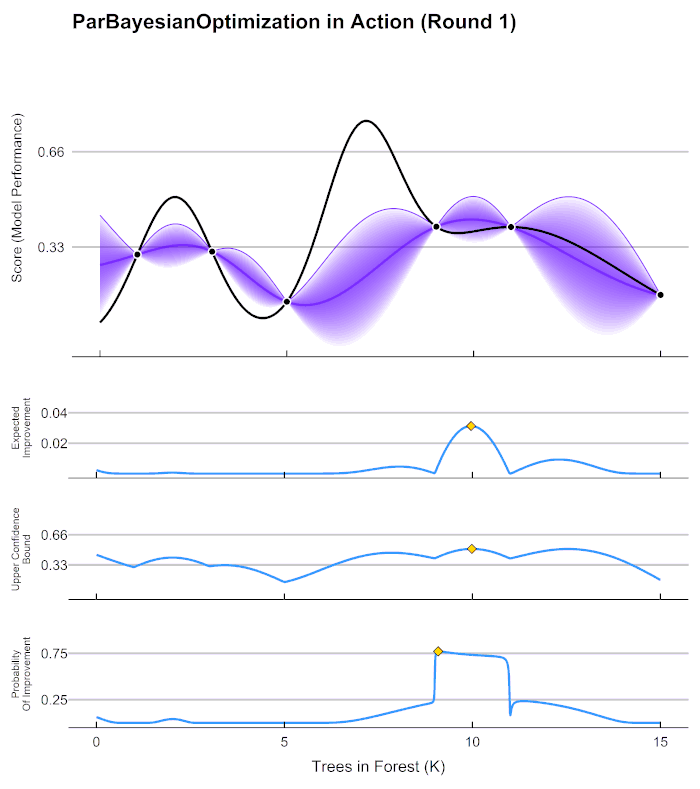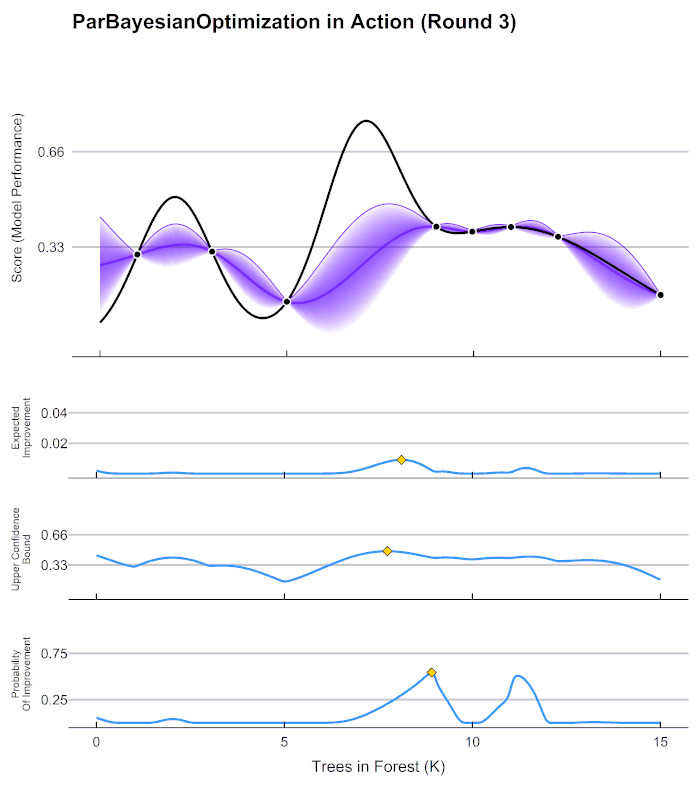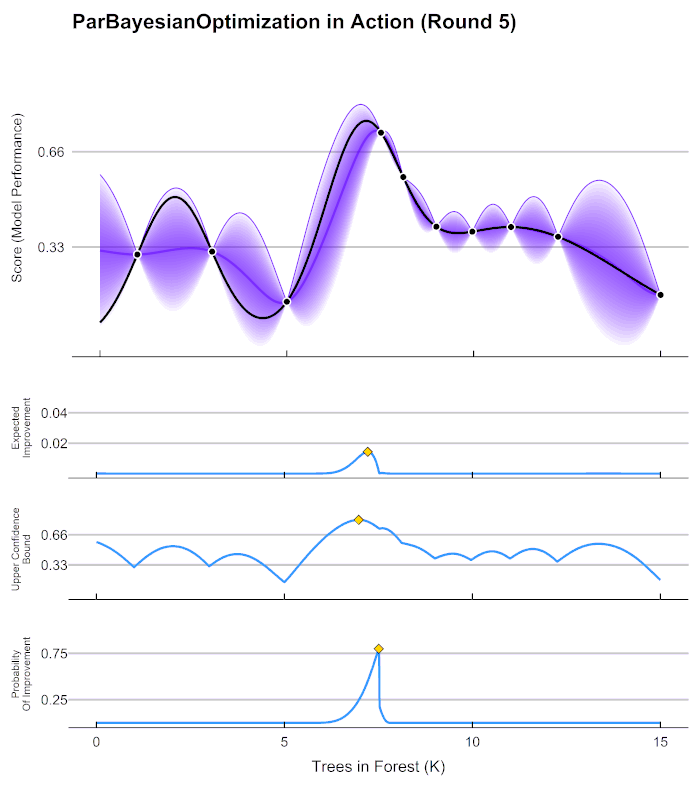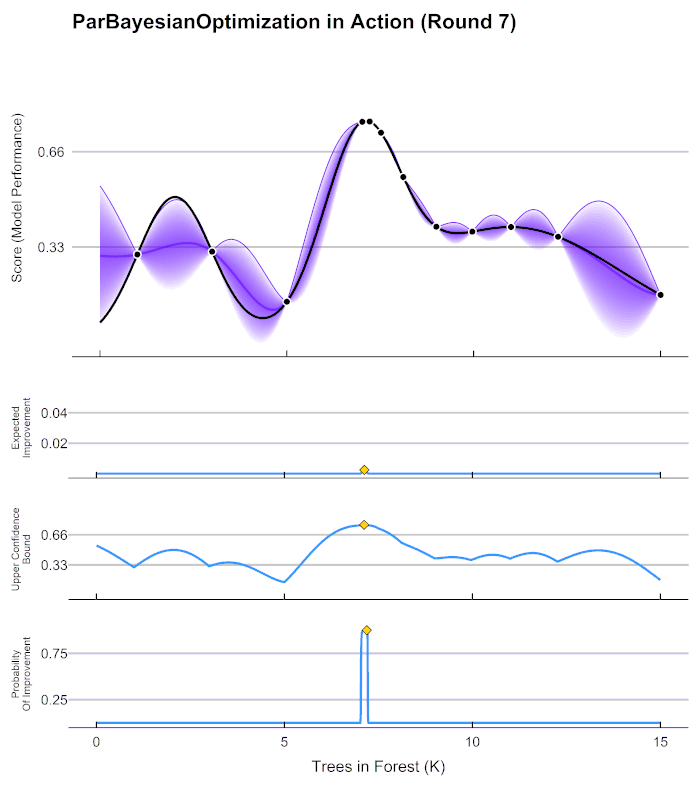
2.3 贝叶斯优化用于HPO的流程
如果充分理解了上面的过程,再看贝叶斯优化流程定义就很好理解了!
在贝叶斯优化的数学过程当中,主要执行以下几个步骤:
-
定义估计函数和定义域:定义需要估计的 f ( x ) f(x) f(x)以及 x x x的定义域
f ( x ) f(x) f(x):
估计的函数 f ( x ) f(x) f(x)是一个黑箱函数,即只知道 x x x与 f ( x ) f(x) f(x)的对应关系,却丝毫不知道函数内部规律、同时也不能写出具体表达式的一类函数,意味着根本无法得到它的显式表达式,只能通过实验或者观测得到某些点上的函数值。
x的定义域:
通常是高维的,并且可以是连续的,离散的或者混合的。
-
取观测值:取出有限的n个 x x x上的值,求解出这些 x x x对应的 f ( x ) f(x) f(x)(求解观测值)
可以使用一些启发式的方法来选择初始点,如随机选取,或者使用某种设计的实验(如拉丁超立方采样)。
-
函数估计:根据有限的观测值,对函数进行估计(该假设被称为贝叶斯优化中的先验知识),得出该估计 f ∗ f^* f∗上的目标值(最大值或最小值)
概率代理模型:
根据有限的观测值、对函数分布进行估计的工具被称为概率代理模型(Probability Surrogate model),毕竟在数学计算中并不能真的邀请数万人对观测点进行连线。
这些概率代理模型自带某些假设,可以根据廖廖数个观测点估计出目标函数的分布 f ∗ f^* f∗(包括 f ∗ f^* f∗上每个点的取值以及该点对应的置信度)。在实际使用时,概率代理模型往往是一些强大的算法,最常见的比如高斯过程、高斯混合模型等等。传统数学推导中往往使用高斯过程,但现在最普及的优化库中基本都默认使用基于高斯混合模型的TPE过程。比如高斯过程是一种常用的方法,因为它能提供预测的均值和方差,从而能够描述预测的不确定性。
-
定义某种规则,以确定下一个需要计算的观测点
采集函数:
在确定下一个观测点时,通常会使用一个取舍策略,也被称为采集函数(acquisition function),采集函数衡量观测点对拟合 f ∗ f^* f∗所产生的影响,并选取影响最大的点执行下一步观测,因此往往关注采集函数值最大的点。
最常见的采集函数主要是概率增量PI(Probability of improvement,比如计算的频数)、期望增量(Expectation Improvement)、置信度上界(Upper Confidence Bound)、信息熵(Entropy)等等。大部分优化库中默认使用期望增量。
-
更新模型和迭代:当得到新的观测值后,需要更新模型,并重新计算采集函数,然后再次确定下一个观测点。这个过程将会一直重复,直到达到停止条件为止。
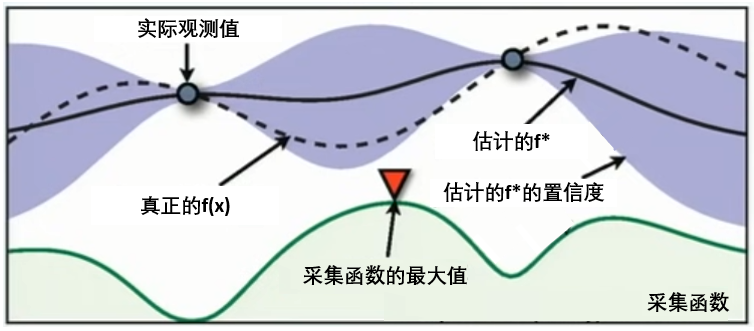
这张图像表现了贝叶斯优化的全部基本元素,目标就是在采集函数指导下,让 f ∗ f^* f∗尽量接近 f ( x ) f(x) f(x)。根据概率代理模型得到估计的f,得到f 上的每个点和对应的置信区间,然后根据f* 得到采集函数的值,采集函数的的最大值就是下一个要使用的点。**
三、实现贝叶斯优化的方式
3.1 常用的优化库
贝叶斯优化在同一套序贯模型下(序贯模型就是2.3节的流程,被称为序贯模型优化(SMBO),是最为经典的贝叶斯优化方法)使用不同的代理模型以及采集函数,可以发展出更多更先进的贝叶斯优化改进版算法,因此,几乎任意一个专业用于超参数优化的工具库都会包含贝叶斯优化的内容。
以下是一些常用库的描述:
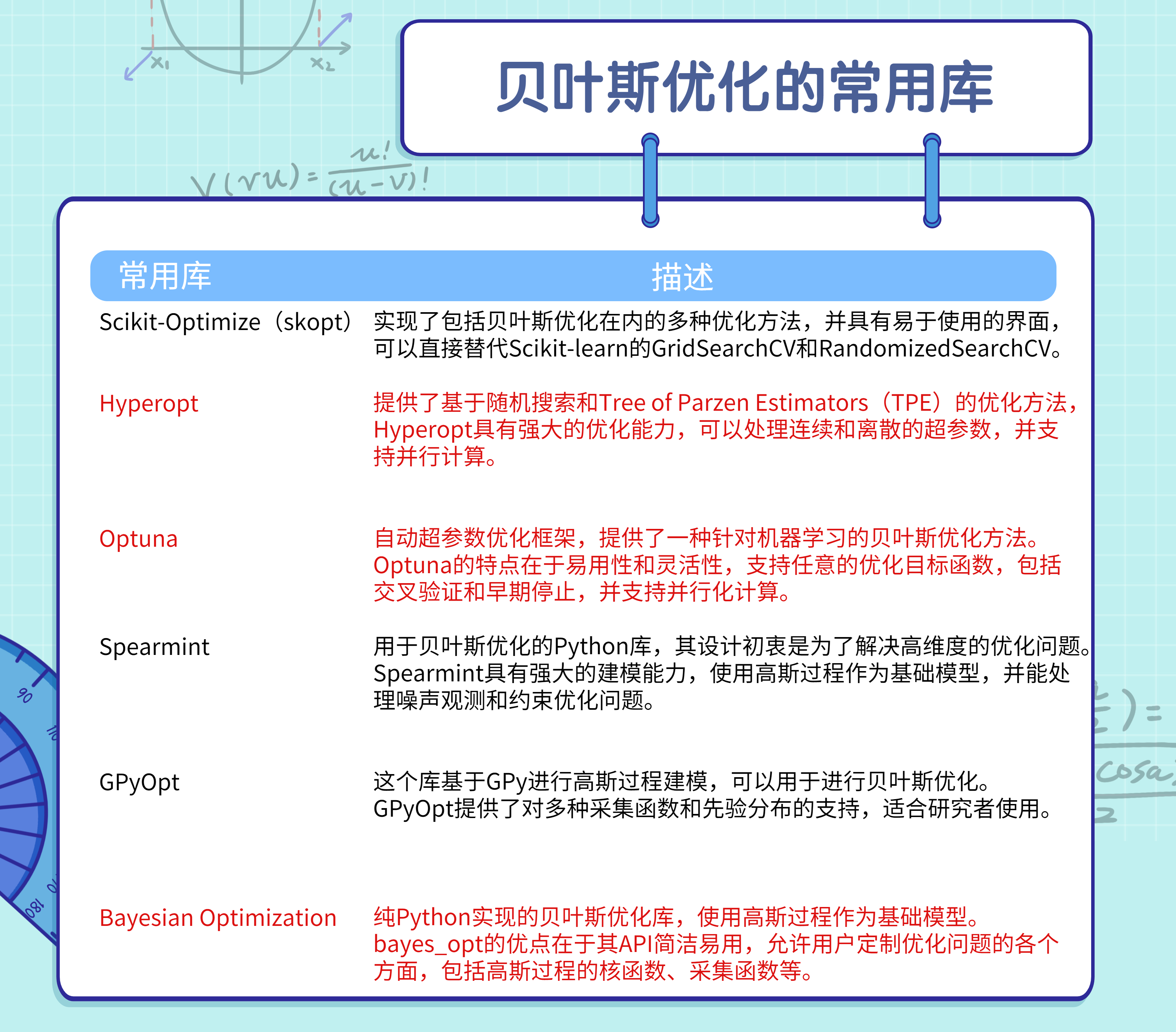
本文主要介绍三个工程上比较常用库:bayesian-optimization,hyperopt,optuna

3.2 基于Bayes_opt实现GP优化
bayes-optimization是最早开源的贝叶斯优化库之一,开源较早、代码简单,但这也导致了bayes-opt对参数空间的处理方式较为原始,同时缺乏相应的提效/监控功能,对算力的要求较高,因此它往往不是进行优化时的第一首选库。
bayes-optmization官方文档,想要进一步了解其基本功能与原理的可以进行阅读。
3.2.1 实操过程
Step 1: 安装Bayes_opt库
!pip install bayesian-optimization
Step 2:导入相关库
import pandas as pd
import numpy as np
import time
import os
import sklearn
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import KFold, cross_validate
#优化器
from bayes_opt import BayesianOptimization
Step 3:读取数据,还是使用Kaggle平台的房价预测数据
data = pd.read_csv("../datasets/House Price/train_encode.csv",index_col=0)
X = data.iloc[:,:-1]
y = data.iloc[:,-1]
数据情况如下:
Step 4: 构建目标函数
目标函数的值即 f ( x ) f(x) f(x)的值。贝叶斯优化会计算 f ( x ) f(x) f(x)在不同 x x x上的观测值。
在HPO过程中,目的是为了筛选出令模型泛化能力最大的参数组合,因此 f ( x ) f(x) f(x)应该是损失函数的交叉验证值或者某种评估指标的交叉验证值。
需要注意的是,bayes_opt库存在三个影响目标函数定义的规则:
1、目标函数的输入必须是具体的超参数,而不能是整个超参数空间,更不能是数据、算法等超参数以外的元素,因此在定义目标函数时,需要让超参数作为目标函数的输入。
2、超参数的输入值只能是浮点数,不支持整数与字符串。当算法的实际参数需要输入字符串时,该参数不能使用bayes_opt进行调整,当算法的实际参数需要输入整数时,则需要在目标函数中规定参数的类型。
3、bayes_opt只支持寻找 f ( x ) f(x) f(x)的最大值,不支持寻找最小值。因此当定义的目标函数是某种损失时,目标函数的输出需要取负(即,如果使用RMSE,则应该让目标函数输出负RMSE,这样最大化负RMSE后,才是最小化真正的RMSE。),当定义的目标函数是准确率,或者auc等指标,则可以让目标函数的输出保持原样。
def bayesopt_objective(n_estimators,max_depth,max_features,min_impurity_decrease):
#定义评估器
#需要调整的超参数等于目标函数的输入,不需要调整的超参数则直接等于固定值
#默认参数输入一定是浮点数,因此需要套上int函数处理成整数
reg = RandomForestRegressor(n_estimators = int(n_estimators)
,max_depth = int(max_depth)
,max_features = int(max_features)
,min_impurity_decrease = min_impurity_decrease
,random_state=24
,verbose=False
,n_jobs=-1)
#定义损失的输出,5折交叉验证下的结果,输出负根均方误差(-RMSE)
#注意,交叉验证需要使用数据,但不能让数据X,y成为目标函数的输入
cv = KFold(n_splits=5,shuffle=True,random_state=24)
validation_loss = cross_validate(reg,X,y
,scoring="neg_root_mean_squared_error"
,cv=cv
,verbose=False
,n_jobs=-1
,error_score='raise'
)
#交叉验证输出的评估指标是负根均方误差,因此本来就是负的损失
#目标函数可直接输出该损失的均值
return np.mean(validation_loss["test_score"])
Step 5:定义参数空间
在bayes_opt中,使用字典方式来定义参数空间,其中参数的名称为键,参数的取值范围为值。
param_grid_opt = {
'n_estimators': (80,100)
, 'max_depth':(10,25)
, "max_features": (10,20)
, "min_impurity_decrease":(0,1)
}
一个操作技巧:bayes_opt只支持填写参数空间的上界与下界,不支持填写步长等参数,且bayes_opt会将所有参数都当作连续型超参进行处理,因此bayes_opt会直接取出闭区间中任意浮点数作为备选参数。例如,取92.28作为n_estimators的值。
Step 6:定义优化目标函数的具体流程
有了目标函数与参数空间之后,就可以按bayes_opt的规则进行优化。
def param_bayes_opt(init_points,n_iter):
#定义优化器,先实例化优化器
opt = BayesianOptimization(bayesopt_objective #需要优化的目标函数
,param_grid_opt #备选参数空间
,random_state=24
)
#使用优化器,bayes_opt只支持最大化
opt.maximize(init_points = init_points #抽取多少个初始观测值
, n_iter=n_iter #一共观测/迭代多少次
)
#优化完成,取出最佳参数与最佳分数
params_best = opt.max["params"]
score_best = opt.max["target"]
#打印最佳参数与最佳分数
print("\n","\n","best params: ", params_best,
"\n","\n","best cvscore: ", score_best)
#返回最佳参数与最佳分数
return params_best, score_best
Step 7: 定义验证函数
验证函数与目标函数高度相似,输入参数或超参数空间、输出最终的损失函数结果。
def bayes_opt_validation(params_best):
reg = RandomForestRegressor(n_estimators = int(params_best["n_estimators"])
,max_depth = int(params_best["max_depth"])
,max_features = int(params_best["max_features"])
,min_impurity_decrease = params_best["min_impurity_decrease"]
,random_state=24
,verbose=False
,n_jobs=-1)
cv = KFold(n_splits=5,shuffle=True,random_state=1412)
validation_loss = cross_validate(reg,X,y
,scoring="neg_root_mean_squared_error"
,cv=cv
,verbose=False
,n_jobs=-1
)
return np.mean(validation_loss["test_score"])
Step 7:执行优化操作
start = time.time()
#初始看10个观测值,后面迭代290次
params_best, score_best = param_bayes_opt(10,290)
print('It takes %s minutes' % ((time.time() - start)/60))
validation_score = bayes_opt_validation(params_best)
print("\n","\n","validation_score: ",validation_score)
看下执行结果:

3.2.2 效果比较及优缺点
和网格搜索效果对比一下:
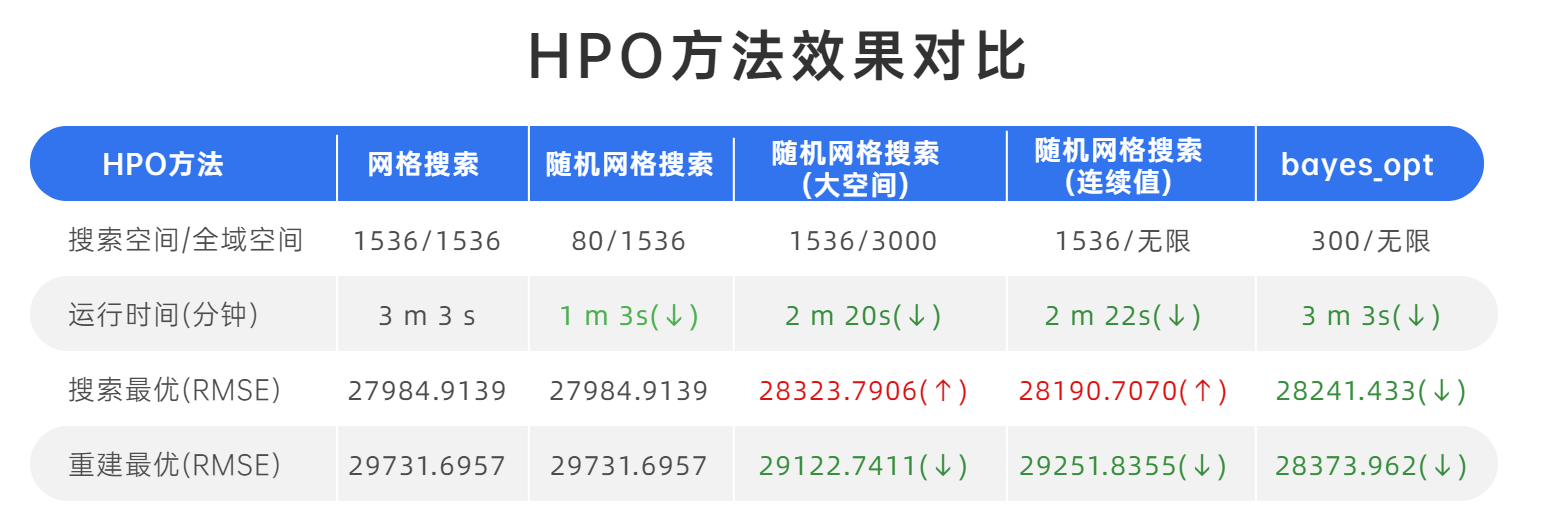
总的来说:其效果在原理上有优越性
基于高斯过程的贝叶斯优化在3m3s内确定最佳分数28373.962,能够以接近的时间获得最好的结果,可见其原理上的优越性。
但是需要注意:贝叶斯优化每次都是随机的,因此并不能在多次运行代码时复现出28373.962这个结果,如果重复运行,也只有很小的概率可以再次找到这个最低值
因此在执行贝叶斯优化时,往往会多运行几次观察模型找出的结果。
3.3 基于HyperOpt实现TPE优化
Hyperopt优化器是目前最通用的贝叶斯优化器之一,它集成了包括随机搜索、模拟退火和TPE(Tree-structured Parzen Estimator Approach)等多种优化算法。相比于Bayes_opt,Hyperopt的是更先进、更现代、维护更好的优化器,也是我们最常用来实现TPE方法的优化器。
在实际使用中,相比基于高斯过程的贝叶斯优化,基于高斯混合模型的TPE在大多数情况下以更高效率获得更优结果,该方法目前也被广泛应用于AutoML领域中。
3.3.1 实操过程
Step 1: 安装hyperopt库
!pip install hyperopt

Step 2:导入相关库
import hyperopt
from hyperopt import hp, fmin, tpe, Trials, partial
from hyperopt.early_stop import no_progress_loss
Step 3:读取数据,还是使用Kaggle平台的房价预测数据
data = pd.read_csv("../datasets/House Price/train_encode.csv",index_col=0)
X = data.iloc[:,:-1]
y = data.iloc[:,-1]
Step 4: 构建目标函数
在定义目标函数 f ( x ) f(x) f(x)时,与Bayes_opt一样,Hyperopt也有一些特定的规则会限制我们的定义方式,主要包括:
1 、目标函数的输入必须是符合hyperopt规定的字典
不能是类似于sklearn的参数空间字典、不能是参数本身,更不能是数据、算法等超参数以外的元素。因此在自定义目标函数时,需要让超参数空间字典作为目标函数的输入。
2、 Hyperopt只支持寻找 f ( x ) f(x) f(x)的最小值,不支持寻找最大值,因此当定义的目标函数是某种正面的评估指标时(如准确率,auc),需要对该评估指标取负。如果定义的目标函数是负损失,也需要对负损失取绝对值。当且仅当定义的目标函数是普通损失时,才不需要改变输出。
def hyperopt_objective(params):
#定义评估器
#需要搜索的参数需要从输入的字典中索引出来
#不需要搜索的参数,可以是设置好的某个值
#在需要整数的参数前调整参数类型
reg = RandomForestRegressor(n_estimators = int(params["n_estimators"])
,max_depth = int(params["max_depth"])
,max_features = int(params["max_features"])
,min_impurity_decrease = params["min_impurity_decrease"]
,random_state=24
,verbose=False
,n_jobs=-1)
#交叉验证结果,输出负根均方误差(-RMSE)
cv = KFold(n_splits=5,shuffle=True,random_state=1412)
validation_loss = cross_validate(reg,X,y
,scoring="neg_root_mean_squared_error"
,cv=cv
,verbose=False
,n_jobs=-1
,error_score='raise'
)
#最终输出结果,由于只能取最小值,所以必须对(-RMSE)求绝对值
#以求解最小RMSE所对应的参数组合
return np.mean(abs(validation_loss["test_score"]))
Step 5:定义参数空间
在hyperopt中,需要使用特殊的字典形式来定义参数空间,其中键值对上的键可以任意设置,只要与目标函数中索引参数的键一致即可,键值对的值则是hyperopt独有的hp函数,包括了:
hp.quniform(“参数名称”, 下界, 上界, 步长) - 适用于均匀分布的浮点数
hp.uniform(“参数名称”,下界, 上界) - 适用于随机分布的浮点数
hp.randint(“参数名称”,上界) - 适用于[0,上界)的整数,区间为前闭后开
hp.choice(“参数名称”,[“字符串1”,“字符串2”,…]) - 适用于字符串类型,最优参数由索引表示
hp.choice(“参数名称”,[*range(下界,上界,步长)]) - 适用于整数型,最优参数由索引表示
hp.choice(“参数名称”,[整数1,整数2,整数3,…]) - 适用于整数型,最优参数由索引表示
hp.choice(“参数名称”,[“字符串1”,整数1,…]) - 适用于字符与整数混合,最优参数由索引表示
hyperopt中的参数空间定义方法应当都为前闭后开区间
param_grid_hp = {
'n_estimators': hp.quniform("n_estimators",80,100,1)
, 'max_depth': hp.quniform("max_depth",10,25,1)
, "max_features": hp.quniform("max_features",10,20,1)
, "min_impurity_decrease":hp.quniform("min_impurity_decrease",0,5,1)
}
Step 6:定义优化目标函数的具体流程
有了目标函数和参数空间,接下来要进行优化,需要了解以下参数:
- fmin:自定义使用的代理模型(参数
algo),有tpe.suggest以及rand.suggest两种选项,前者指代TPE方法,后者指代随机网格搜索方法 - partial:功修改算法涉及到的具体参数,包括模型具体使用了多少个初始观测值(参数
n_start_jobs),以及在计算采集函数值时究竟考虑多少个样本(参数n_EI_candidates) - trials:记录整个迭代过程,从hyperopt库中导入的方法Trials(),优化完成之后,可以从保存好的trials中查看损失、参数等各种中间信息
- early_stop_fn:提前停止参数,从hyperopt库导入的方法no_progress_loss(),可以输入具体的数字n,表示当损失连续n次没有下降时,让算法提前停止
def param_hyperopt(max_evals=100):
#保存迭代过程
trials = Trials()
#设置提前停止
early_stop_fn = no_progress_loss(100)
#定义代理模型
#algo = partial(tpe.suggest, n_startup_jobs=20, n_EI_candidates=50)
params_best = fmin(hyperopt_objective #目标函数
, space = param_grid_hp #参数空间
, algo = tpe.suggest #代理模型
#, algo = algo
, max_evals = max_evals #允许的迭代次数
, verbose=True
, trials = trials
, early_stop_fn = early_stop_fn
)
#打印最优参数,fmin会自动打印最佳分数
print("\n","\n","best params: ", params_best,
"\n")
return params_best, trials
Step 7: 定义验证函数
验证函数与目标函数高度相似,输入参数或超参数空间、输出最终的损失函数结果。
def hyperopt_validation(params):
reg = RandomForestRegressor(n_estimators = int(params["n_estimators"])
,max_depth = int(params["max_depth"])
,max_features = int(params["max_features"])
,min_impurity_decrease = params["min_impurity_decrease"]
,random_state=24
,verbose=False
,n_jobs=-1
)
cv = KFold(n_splits=5,shuffle=True,random_state=24)
validation_loss = cross_validate(reg,X,y
,scoring="neg_root_mean_squared_error"
,cv=cv
,verbose=False
,n_jobs=-1
)
return np.mean(abs(validation_loss["test_score"]))
Step 7:执行优化操作
import time
def optimized_param_search_and_report(num_evals):
start_time = time.time()
# 进行贝叶斯优化
params_best, trials = param_hyperopt(num_evals)
# 打印最佳参数验证结果
hyperopt_validation(params_best)
# 打印所有搜索相关的记录
print("All search records:")
print(trials.trials[0])
end_time = time.time()
elapsed_time = (end_time - start_time) / 60 # 转换为分钟
print(f"Optimization completed in 0.0708 minutes.")
# 执行优化
optimized_param_search_and_report(300)
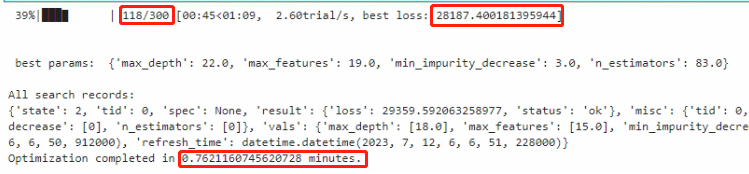
看下执行结果:
3.3.2 效果比较及优缺点
和网格搜索效果对比一下:
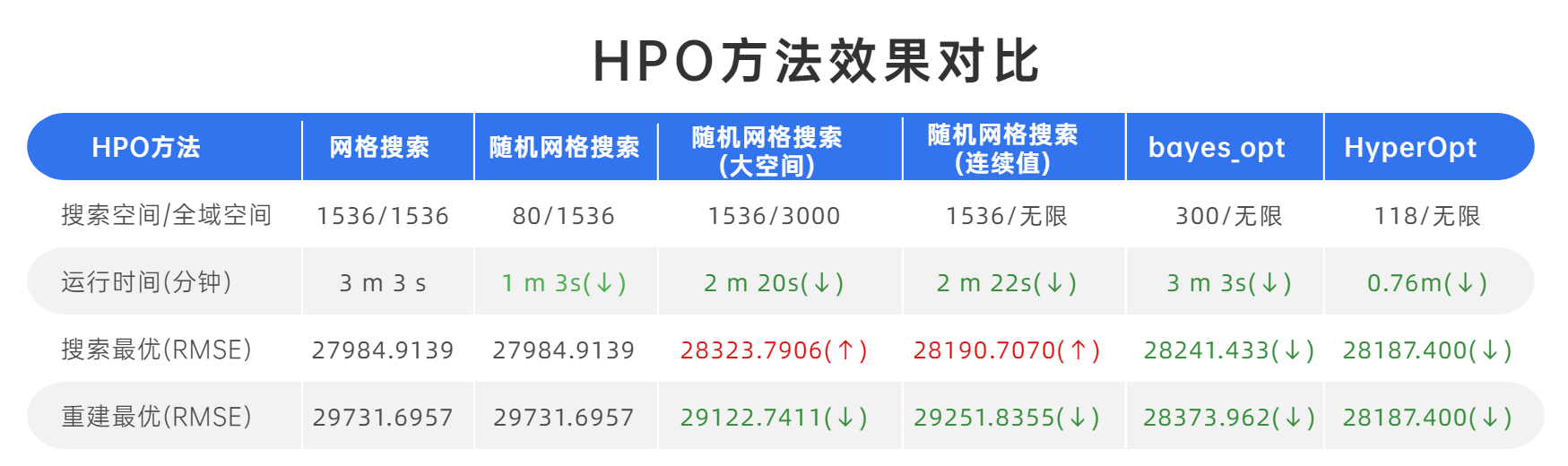
总的来说:TPE方法相比于高斯过程计算会更加迅速,hyperopt在不到1分钟时间,就得到综合最好的效果
不过HyperOpt的缺点就是代码精密度要求较高、灵活性较差,略微的改动就可能让代码疯狂报错难以跑通。
3.4 基于Optuna实现
Optuna是目前为止最成熟、拓展性最强的超参数优化框架,它是专门为机器学习和深度学习所设计。为了满足机器学习开发者的需求,Optuna拥有强大且固定的API,因此Optuna代码简单,编写高度模块化,
Optuna可以无缝衔接到PyTorch、Tensorflow等深度学习框架上,也可以与sklearn的优化库scikit-optimize结合使用,因此Optuna可以被用于各种各样的优化场景。
3.4.1 实操过程
Step 1: 安装hyperopt库
!pip install optuna

Step 2:导入相关库
import optuna
Step 3:读取数据,还是使用Kaggle平台的房价预测数据
data = pd.read_csv("../datasets/House Price/train_encode.csv",index_col=0)
X = data.iloc[:,:-1]
y = data.iloc[:,-1]
Step 4: 构建目标函数及定义参数空间
在Optuna中,不需要将参数或参数空间输入目标函数,而是需要直接在目标函数中定义参数空间。Optuna优化器会生成一个指代备选参数的变量trial,该变量无法被用户获取或打开,但该变量在优化器中生存,并被输入目标函数。在目标函数中,可以通过变量trail所携带的方法来构造参数空间
def optuna_objective(trial):
#定义参数空间
n_estimators = trial.suggest_int("n_estimators",80,100,1) #整数型,(参数名称,下界,上界,步长)
max_depth = trial.suggest_int("max_depth",10,25,1)
max_features = trial.suggest_int("max_features",10,20,1)
min_impurity_decrease = trial.suggest_int("min_impurity_decrease",0,5,1)
#定义评估器
#需要优化的参数由上述参数空间决定
#不需要优化的参数则直接填写具体值
reg = RandomForestRegressor(n_estimators = n_estimators
,max_depth = max_depth
,max_features = max_features
,min_impurity_decrease = min_impurity_decrease
,random_state=24
,verbose=False
,n_jobs=-1
)
#交叉验证过程,输出负均方根误差(-RMSE)
#optuna同时支持最大化和最小化,因此如果输出-RMSE,则选择最大化
#如果选择输出RMSE,则选择最小化
cv = KFold(n_splits=5,shuffle=True,random_state=24)
validation_loss = cross_validate(reg,X,y
,scoring="neg_root_mean_squared_error"
,cv=cv #交叉验证模式
,verbose=False #是否打印进程
,n_jobs=-1 #线程数
,error_score='raise'
)
#最终输出RMSE
return np.mean(abs(validation_loss["test_score"]))
Step 5:定义优化目标函数的具体流程
在Optuna的模块sampler可以定义备选的算法,包括我TPE优化、随机网格搜索以及其他各类更加高级的贝叶斯过程,对于Optuna.sampler中调出的类,可以直接输入参数来设置初始观测值的数量、以及每次计算采集函数时所考虑的观测值量。
def optimizer_optuna(n_trials, algo):
#定义使用TPE或者GP
if algo == "TPE":
algo = optuna.samplers.TPESampler(n_startup_trials = 15, n_ei_candidates = 20)
elif algo == "GP":
from optuna.integration import SkoptSampler
import skopt
algo = SkoptSampler(skopt_kwargs={'base_estimator':'GP', #选择高斯过程
'n_initial_points':30, #初始观测点10个
'acq_func':'EI'} #选择的采集函数为EI,期望增量
)
#实际优化过程,首先实例化优化器
study = optuna.create_study(sampler = algo #要使用的具体算法
, direction="minimize" #优化的方向,可以填写minimize或maximize
)
#开始优化,n_trials为允许的最大迭代次数
#由于参数空间已经在目标函数中定义好,因此不需要输入参数空间
study.optimize(optuna_objective #目标函数
, n_trials=n_trials #最大迭代次数(包括最初的观测值的)
, show_progress_bar=True #要不要展示进度条呀?
)
#可直接从优化好的对象study中调用优化的结果
#打印最佳参数与最佳损失值
print("\n","\n","best params: ", study.best_trial.params,
"\n","\n","best score: ", study.best_trial.values,
"\n")
return study.best_trial.params, study.best_trial.values
Step 6:执行优化操作
import time
def optimized_optuna_search_and_report(n_trials, algo):
start_time = time.time()
# 进行贝叶斯优化
best_params, best_score = optimizer_optuna(n_trials, algo)
# 打印最佳参数和分数
print("\n","\n","best params: ", best_params,
"\n","\n","best score: ", best_score,
"\n")
end_time = time.time()
elapsed_time = (end_time - start_time) / 60 # 转换为分钟
print(f"Optimization completed in 0.0708 minutes.")
return best_params, best_score
# 执行优化
best_params, best_score = optimized_optuna_search_and_report(300, "TPE")
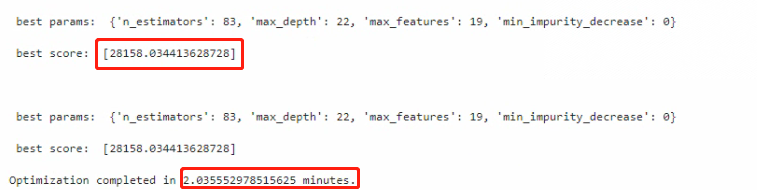
看下执行结果:
3.4.2 效果比较及优缺点
和网格搜索效果对比一下:
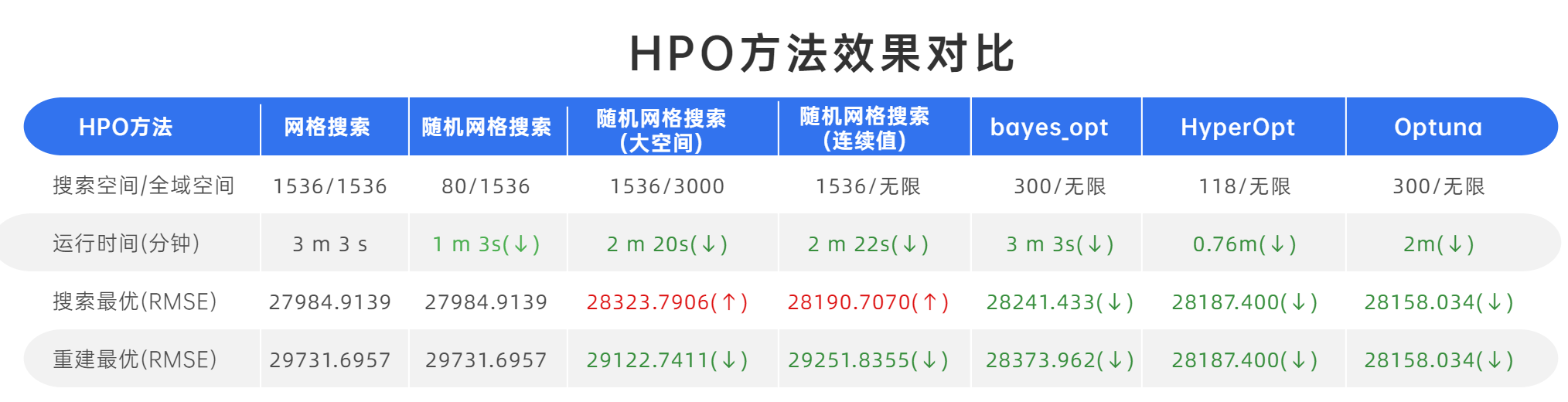
很显然,它在较短的时间内,得到了最好的效果。
大家可以自行调试。
四、结语
这篇文章解释了超参数优化的高阶内容 – 贝叶斯优化的基本原理和流程,并对三种主流的贝叶斯优化库——Bayes_opt、HyperOpt 和 Optuna进行了实操演示,希望通过本文,大家能真正理解到贝叶斯优化的工作原理和如何用它来求解函数的最小值,并且学会在超参数优化任务中如何实际应用贝叶斯优化。
最后,感谢您阅读这篇文章!如果您觉得有所收获,别忘了点赞、收藏并关注我,这是我持续创作的动力。您有任何问题或建议,都可以在评论区留言,我会尽力回答并接受您的反馈。如果您希望了解某个特定主题,也欢迎告诉我,我会乐于创作与之相关的文章。谢谢您的支持,期待与您共同成长!