这个博文的内容:
1.k-Fold和StratifiedKFold的区别;
2.LightGBM的代码流程,不会讲LightGBM的内部原理。
3. 贝叶斯优化超参数:这个在之前的博文已经讲过了,链接:
贝叶斯优化(Bayesian Optimization)只需要看这一篇就够了,算法到python实现
K-Fold vs StratifiedKFold
这里就不说为什么要用K-Fold了,如果有人不清楚可以评论emm(估计是骗不到评论了哈哈)。
StratifiedKFold的Stratified就是社会分层的意思,就是假设按照4:1的比例划分训练集和验证集的时候,划分的训练集和验证集是等比例标签的。看个例子:
from sklearn.model_selection import StratifiedKFold,KFold
x_train = pd.DataFrame({'x':[0,1,2,3,4,5,6,7,8,9],'y':[0,1,0,1,0,1,0,1,0,1]})
kf = StratifiedKFold(n_splits = 5, shuffle = True, random_state = 0)
for i in kf.split(x_train.x,x_train.y):
print(i)
运行结果:
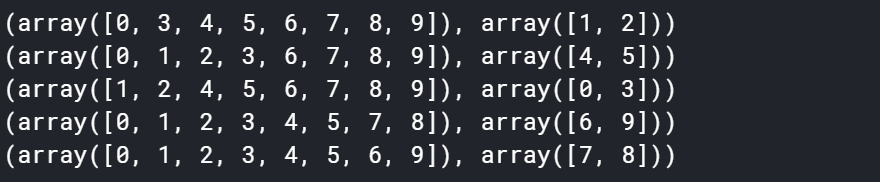
我简单的构建了一个十个数据的数据集,然后标签类别有两类(奇数和偶数,不过这个不重要啦)。然后通过K-Fold把是个数据划分成五组训练集+验证集(也就是说我们会训练五个模型)。因为原始的十个数据中,有五个是奇数,五个是偶数,所以比例是1:1,没错吧。
所以StratifiedKFold就是保证验证机的不同类别的样本和原始数据的比例相同,可以看到五组数据中每一组的验证集和训练集的不同类别的样本数量比例就是1:1。
那么KFold就是随机划分,没有考虑这个保持比例相同的问题,可以看上面的例子,用KFold来实现(完全一样,就是StratifiedKFold变成了KFold):
from sklearn.model_selection import StratifiedKFold,KFold
x_train = pd.DataFrame({'x':[0,1,2,3,4,5,6,7,8,9],'y':[0,1,0,1,0,1,0,1,0,1]})
kf = KFold(n_splits = 5, shuffle = True, random_state = 0)
for i in kf.split(x_train.x,x_train.y):
print(i)
运行结果:

可以看到,第一组验证集是两个偶数,第四组是两个奇数,就是随机分的。
这里需要注意,上面说两个偶数和两个奇数是指验证集的样本的类别,而不是上图的两个数组。图中的数组就是原始数据的索引值,比方说第一个验证集中是【2,8】,是吧第2个样本和第8个样本分到了验证集,而不是样本特征为2和8的分到了验证集.
不过可想而知,假如数据样本是回归任务的数据,不是分类的,那么怎么用StratifiedKFold呢?不能用了,所以到时候就用KFold就行了,不过回归任务也要注意考虑时间关系。
python代码
先导入数据,使用sklearn内嵌的啥乳腺癌数据,500多个样本,每个样本30个特征,然后是一个2分类问题。
import numpy as np
import pandas as pd
from sklearn.model_selection import StratifiedKFold,KFold
import lightgbm as lgb
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris,load_breast_cancer
cancer = load_breast_cancer()
X_train,x_test,Y_train,y_test = train_test_split(cancer.data,cancer.target,test_size=0.2,random_state=3)
先把数据分成测试集和训练集,这里的训练集之后还会再被分成训练集+验证集。
下面随便用一组超参数构建lightGBM模型:
from sklearn import metrics
kf = StratifiedKFold(n_splits = 5, shuffle = True, random_state = 0)
# kf = KFold(n_splits = 5, shuffle = True, random_state = 0)
y_pred = np.zeros(len(x_test))
for fold,(train_index,val_index) in enumerate(kf.split(X_train,Y_train)):
x_train,x_val = X_train[train_index],X_train[val_index]
y_train,y_val = Y_train[train_index],Y_train[val_index]
train_set = lgb.Dataset(x_train,y_train)
val_set = lgb.Dataset(x_val,y_val)
params = {
'boosting_type': 'gbdt',
'metric': {'binary_logloss', 'auc'},
'objective': 'binary',#regression,binary,multiclass
# 'num_class':2,
'seed': 666,
'num_leaves': 20,
'learning_rate': 0.1,
'max_depth': 10,
'n_estimators': 5000,
'lambda_l1': 1,
'lambda_l2': 1,
'bagging_fraction': 0.9,
'bagging_freq': 1,
'colsample_bytree': 0.9,
'verbose':-1,
}
model = lgb.train(params,train_set,num_boost_round=5000,early_stopping_rounds=50,
valid_sets = [val_set],verbose_eval=100)
y_pred += model.predict(x_test,num_iteration=model.best_iteration)/kf.n_splits
y_pred = [1 if y > 0.5 else 0 for y in y_pred]
rmse = metrics.accuracy_score(y_pred,y_test)
print(rmse)
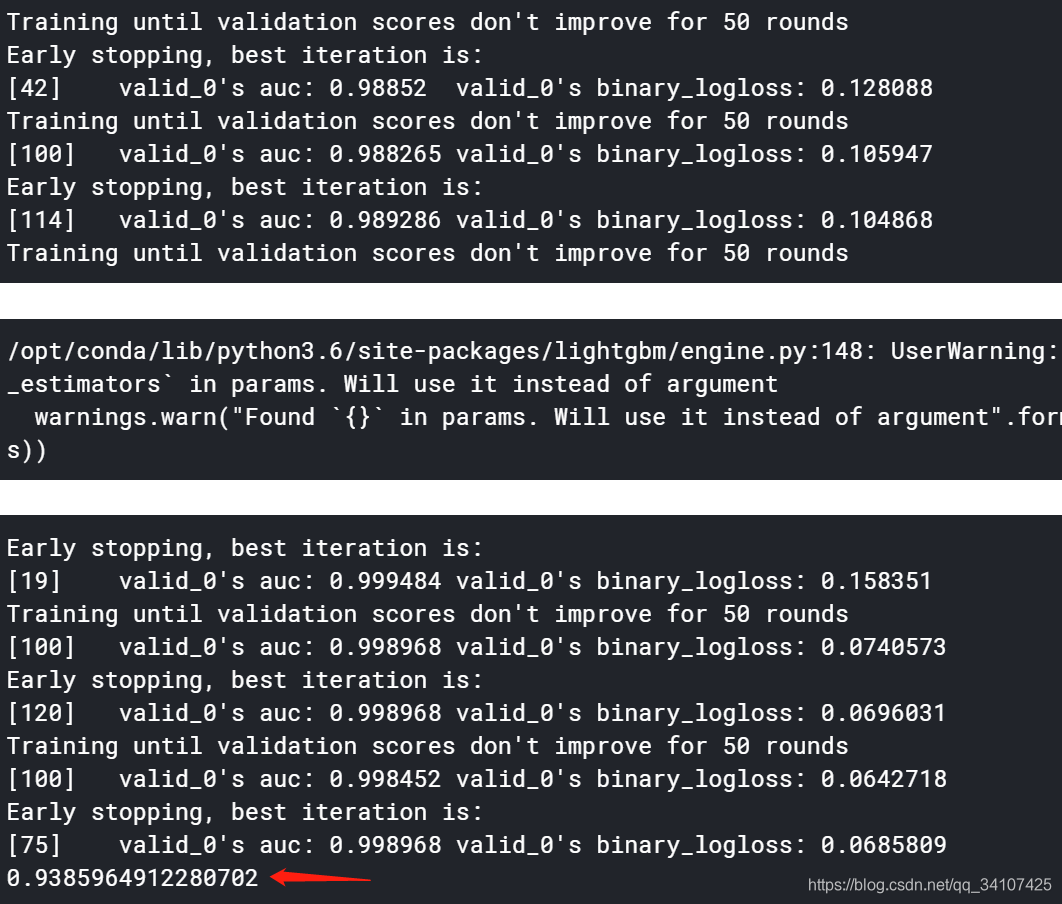
这里0.9385就是测试集的准确率。下面使用贝叶斯调参(下面对于验证集和测试集的概念可能有点混乱,是因为在比赛中,会有一个要提交的分数,那个是真正的测试集而不是从训练集中分出来的,没事看代码就好):
def cv_lgm(num_leaves,max_depth,lambda_l1,lambda_l2,bagging_fraction,bagging_freq,colsample_bytree):
kf = StratifiedKFold(n_splits = 5, shuffle = True, random_state = 0)
# kf = KFold(n_splits = 5, shuffle = True, random_state = 0)
y_pred = np.zeros(len(x_test))
for fold,(train_index,val_index) in enumerate(kf.split(X_train,Y_train)):
x_train,x_val = X_train[train_index],X_train[val_index]
y_train,y_val = Y_train[train_index],Y_train[val_index]
train_set = lgb.Dataset(x_train,y_train)
val_set = lgb.Dataset(x_val,y_val)
params = {
'boosting_type': 'gbdt',
'metric': {'binary_logloss', 'auc'},
'objective': 'binary',#regression,binary,multiclass
# 'num_class':2,
'seed': 666,
'num_leaves': int(num_leaves), #20
'learning_rate': 0.1,
'max_depth': int(max_depth),
'lambda_l1': lambda_l1,
'lambda_l2': lambda_l2,
'bagging_fraction': bagging_fraction,
'bagging_freq': int(bagging_freq),
'colsample_bytree': colsample_bytree,
}
model = lgb.train(params,train_set,num_boost_round=5000,early_stopping_rounds=50,
valid_sets = [val_set],verbose_eval=100)
y_pred += model.predict(x_test,num_iteration=model.best_iteration)/kf.n_splits
y_pred = [1 if y > 0.5 else 0 for y in y_pred]
accuracy = metrics.accuracy_score(y_pred,y_test)
return accuracy
from bayes_opt import BayesianOptimization
rf_bo = BayesianOptimization(
cv_lgm,
{'num_leaves': (10, 50),
'max_depth': (5,40),
'lambda_l1': (0.1,3),
'lambda_l2': (0.1,3),
'bagging_fraction':(0.6,1),
'bagging_freq':(1,5),
'colsample_bytree': (0.6,1),
}
)
rf_bo.maximize()
找到的最优化超参数是:{‘target’: 0.9473684210526315,
‘params’: {‘bagging_fraction’: 0.9726062500743026,
‘bagging_freq’: 3.3964048376327938,
‘colsample_bytree’: 0.9350215025768822,
‘lambda_l1’: 0.5219868645323071,
‘lambda_l2’: 0.1006192480920821,
‘max_depth’: 32.69376913856991,
‘num_leaves’: 36.29712182920533}}
然后再把参数带入LGB,重新训练就OK了。可以使用
rf_bo.max()
找到最优参数。
不过了我在贝叶斯优化的那个博文中最后一句说的,贝叶斯超参数某种意义上,也是一种瞎猜,但是多数做比赛的都会用用这个2333.
