参考文献:
自动机器学习超参数调整(贝叶斯优化)—介绍了例子
贝叶斯优化(Bayesian Optimization)深入理解
贝叶斯优化(BayesianOptimization)
贝叶斯网络,看完这篇我终于理解了(附代码)!
贝叶斯优化: 一种更好的超参数调优方式
简介
所谓优化,实际上就是一个求极值的过程,数据科学的很多时候就是求极值的问题。那么怎么求极值呢?很显然,很容易想到求导数,这是一个好方法,但是求导即基于梯度的优化的条件是函数形式已知才能求出导数,并且函数要是凸函数才可以。然而实际上很多时候是不满足这两个条件的,所以不能用梯度优化,贝叶斯优化应运而生了。
贝叶斯优化常原来解决反演问题,
(反演问题是指由结果及某些一般原理(或模型)出发去确定表征问题特征的参数(或模型参数))
贝叶斯优化的好处在于只需要不断取样,来推测函数的最大值。并且采样的点也不多。
贝叶斯优化方法为什么好
贝叶斯优化通过基于目标函数的过去评估结果建立替代函数(概率模型),来找到最小化目标函数的值。贝叶斯方法与随机或网格搜索的不同之处在于,它在尝试下一组超参数时,会参考之前的评估结果,因此可以省去很多无用功。
超参数的评估代价很大,因为它要求使用待评估的超参数训练一遍模型,而许多深度学习模型动则几个小时几天才能完成训练,并评估模型,因此耗费巨大。贝叶斯调参发使用不断更新的概率模型,通过推断过去的结果来“集中”有希望的超参数。
贝叶斯优化的适用条件
黑盒优化
不知道函数的具体形态即表达式,但是如果给定一个x,可以计算y。如果(x,y)够多了,那么就基本知道函数图像的走势了。
适用于小于20维的空间上优化
贝叶斯优化的历史与在神经网络中的应用
Bayesian Optimization(BO)是超参数优化最受欢迎的算法之一,但是因为典型的BO toolboxes都是基于高斯过程,并且主要关注于低维连续优化问题,所以在NAS上没有应用。直到2013年,开始有了一些动作,Swersky et al.使用GP-based的BO算法来推导出用于搜索网络结构的核函数,但是迄今为止都没能找到state-of-the-art的模型。相反一些使用tree-based模型的方法,例如使用treed Parzen estimators的Bergstra et al. 2011,以及使用随机森林的Hutter et al. 2011等都成功地在一系列问题上找到了高维条件空间并且取得了最优的表现
BO自从2013年开始在NAS领域取得早期的成功,如(Bergstra et al. 2013)得到了最先进的视觉模型,(Domhan et al. 2015)所构建的模型在CIFAR10(没有data augmentation)上取得了最好成绩,(Mendoza et al. 2016)是第一个自动化调参的神经网络模型,并且在与人类专家比赛中获得胜利。
贝叶斯优化基本原理与流程
贝叶斯优化是一种近似逼近的方法,用各种代理函数来拟合超参数与模型评价之间的关系,然后选择有希望的超参数组合进行迭代,最后得出效果最好的超参数组合。
贝叶斯优化问题有四个部分:
- 目标函数:我们想要最小化/最大化的内容,在这里,目标函数是机器学习模型使用该组超参数在验证集上的损失。
- 域空间:要搜索的超参数的取值范围
- 优化算法:构造代理函数,以及选择下一个超参数值的方法(采集函数)。
- 结果历史记录:来自目标函数评估的存储结果,包括超参数和验证集上的损失。
算法流程:
- 1、初始化,随机选择若干组参数x,训练模型,得到相应的模型评价指标y
- 2、用代理函数来拟合x,y(例如,高斯过程就是一种代理函数)
- 3、用采集函数来选择最佳的x*
- 4、将x*带入模型,得到 新的y,然后进入第2步
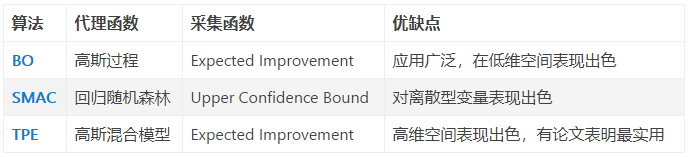
贝叶斯优化的经典变种及其文章
参考:https://www.jianshu.com/p/3587b24f1a6d
-
Bayesian Optimization(高斯过程回归)
贝叶斯优化 (Bayesian Optimization),这个工作最初是由 J Snoek et.在 NIPS 2012 中提出的,并随后多次进行改进 [3, 4]。它要求已经存在几个样本点,并且通过高斯过程回归(假设超参数间符合联合高斯分布)计算前面 n 个点的后验概率分布,得到每一个超参数在每一个取值点的期望均值和方差,其中均值代表这个点最终的期望效果,均值越大表示模型最终指标越大,方差表示这个点的效果不确定性,方差越大表示这个点不确定是否可能取得最大值非常值得去探索,具体的细节分析可以参见这篇博客
但是这个算法仅仅在低纬空间表现优于 Random Search,而在高维空间和 Random Search 表现相当。
优点:在低维空间显著优于 Random Search
缺点:在高维空间仅和 Random Search 相当
注:这个算法的另一个名称为 Spearmint[2]
原文:Snoek J, Larochelle H, Adams R P. Practical bayesian optimization of machine learning algorithms[C]//Advances in neural information processing systems. 2012: 2951-2959. -
TPE
TPE 算法来源于 Y Bengio 在顶会 NIPS2011 的工作 [7]。 TPE 依旧属于贝叶斯优化,其和 SMAC 也有着很深的渊源。其为一种基于树状结构 Parzen 密度估计的非标准贝叶斯优化算法。相较于其他贝叶斯优化算法,TPE 在高维空间表现最佳。
优点 1:相比其他贝叶斯优化算法,高维空间的情况下效果更好
优点 2:相比 BO 速度有显著提升
缺点:在高维空间的情况下,与 Random Search 效果相当
注:所有贝叶斯优化算法在高维空间下表现均和 Random Search 相当 [6]
原文:Bergstra J S, Bardenet R, Bengio Y, et al. Algorithms for hyper-parameter optimization -
SMAC
SMAC 算法出自于期刊 LION 2011[5],其论文中表明,由于先前的 SMBO 算法,不支持离散型变量。SMAC 提出使用 Random Forest 将条件概率 p(y|λ) 建模为高斯分布,其中 λ 为超参的选择。这使得它能够很好的支持离散型变量,并在离散型变量和连续型变量的混合的时候有着不错的表现 [6]。
优点 1:能很好的支持离散型变量,并针对高维空间有一定改善
优点 2:相比 BO 速度有显著提升
缺点:效果不稳定,高维空间表现和 Random Search 相当
原文:Hutter F, Hoos H H, Leyton-Brown K. Sequential model-based optimization for general algorithm configuration
Python中的贝叶斯优化库
Python中有几个贝叶斯优化库,它们目标函数的替代函数不一样。
1、Hyperopt,它使用Tree Parzen Estimator(TPE)。参考:自动化机器学习(AutoML)之自动贝叶斯调参
2、Spearmint(高斯过程代理)
3、SMAC(随机森林回归)。
贝叶斯优化的缺点和解决办法
-
陷入局部点。对于贝叶斯优化,一个主要需要注意的地方,是一旦它找到了一个局部最大值或最小值,它会在这个区域不断采样,所以它很容易陷入局部最值。
解决办法:
为了减轻这个问题,贝叶斯优化算法会在勘探和利用(exploration and exploitation)中找到一个平衡点:
勘探(exploration),就是在还未取样的区域获取采样点。除了在曲线上扬的方向,在其它的区域也不忘寻找。
利用(exploitation),就是根据后验分布,在最可能出现全局最值的区域进行采样。在明确的曲线上扬方向继续走,大概率获得更好的结果,但是容易陷入局部最优。 -
需要消耗大量资源及时间。由于需要至少几十次迭代,即需要训练几十次的模型,因而会造成大量资源、时间消耗。基于这个特点,可以说贝叶斯优化算法适合传统AutoML ,对深度AutoML不是特别好。
解决办法:将贝叶斯优化与多保真度(如bandit-based方法)相结合。 -
对于那些具有未知平滑度和有噪声的高维、非凸函数,BO算法往往很难对其进行拟合和优化,而且通常BO算法都有很强的假设条件,而这些条件一般又很难满足。
解决办法:将贝叶斯优化与多保真度(如bandit-based方法)相结合。 -
效果不稳定。由于初始化存在随机性,其效果不稳定。也有论文表明,贝叶斯优化算法并不显著优于随机搜索(random search)
贝叶斯优化算法(高斯回归过程)
贝叶斯优化在不知道目标函数(黑箱函数)长什么样子的情况下,通过猜测黑箱函数长什么样,来求一个可接受的最大值。
- 由于目标函数未知,故不能使用梯度优化算法。
- 和网格搜索相比,优点是迭代次数少(节省时间),粒度可以到很小,缺点是不容易找到全局最优解。
优化目标
贝叶斯优化的主要目的是与大部分机器学习算法类似,学习模型的表达形式 ,在一定范围内求一个函数的最大(小)值:
这类
往往很特殊:
1. 没有解析表达或者形式未知,故而没办法用跟梯度有关的优化方法;
2. 值的确定会受到一些外界干预(如人的干预)。
优化流程与核心步骤、核心函数
输入:
target:黑箱函数
x:自变量取值范围
Y:可以接受的黑箱函数因变量取值
输出:
x:贝叶斯优化器猜测的最大值的x值
target(xnew):贝叶斯优化器猜测的最大值的函数值
贝叶斯优化流程图:
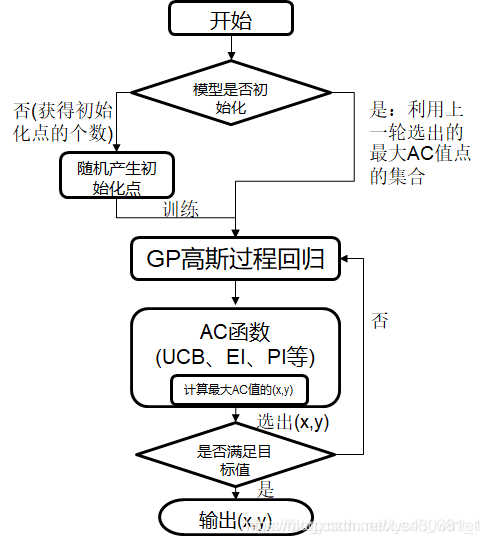
贝叶斯优化算法核心步骤如下:
(1).通过样本点
对高斯过程 进行估计和更新。(简称高斯过程回归)
(2).通过提取函数 (acquisition function)来指导新的采样。(简称提取/采集)
贝叶斯优化有两个核心函数,先验函数(Prior Function,PF)与采集函数(Acquisition Function,AC),
(1)先验函数PF主要利用高斯过程回归(也可以是其它PF函数,但高斯过程回归用的多);
(2)采集函数AC主要包括EI,PI,UCB这几种方法,同时exploration与exploitation的平衡,也是通过AC来完成的。(采集函数也可以叫效能函数(Utility Funtcion),但一般还是称呼为采集函数)
高斯过程
为什么采用高斯过程?
可表达、平滑、良好校正的方差估计、封闭形式的计算性
高斯过程(Gaussian process)
高斯过程常在论文里面简写为GP。定义:如果随机过程的有限维分布均为正态分布,则称此随机过程为高斯过程或正态过程。
1、第一个问题:什么是随机过程?
随机过程就是一族随机变量{ X(t), t},其中,t是参数,它属于某个指标集T,T称为参数集。
注:注意区分随机变量与随机过程。
- 随机变量的概念,我们都很熟悉,例如:随机变量X,之所以称其为随机变量,是因为它的取值是随机的,即X可能取0,0.4,0.7(只是举例)等有限值。
- 一般的,随机过程的参数t代表时间,当T={0,1,2,,,}时,随机过程也称为随机序列。
所谓随机序列,就是当我们在N个间距相等的不同时刻分别观测X这个量,我们会得到一族随机变量,即N个随机变量,姑且记为X(0),X(1),X(2),X(3),X(N-1), 这N个元素每一个都是随机变量。 - 当在时间T范围内取无数个时刻,即使相邻的时刻间隔趋近于0,则我们就得到随机过程{ X(t), t}了!所以,随机过程就是一个以时间为线索的随机变量的集合。
-在随机过程{ X(t), t}中,如果固定时刻t,即观察随机过程中的一个随机变量。例如,固定时间为t0, 则X(t0)就是一个随机变量,其取值随着随机试验的结果而变化,变化有一定规律,叫做概率分布.
随机过程在时刻取的值叫做过程所处的状态,状态的全体集合称为状态空间;
随机变量是定义在状态空间A中的,当固定一次随机实验,即取定
, 则X(t,a0 )$就是一条一个样本的样本路径,它是时间t的函数,可能是连续的,也可能有间断点和跳跃。
样本空间就是图中蓝紫色的部分,在蓝紫色空间中随便画一条函数(随着X轴变化的函数),都是一个样本路径。(高斯过程取值是随机变量,并没有明显的边界。在此图中,蓝紫色空间的边界是高斯函数的均值+或者-1x方差作为边界,当然也可以取2x方差等作为边界)

2、第二个问题:什么是“随机过程的有限维分布均为正态分布”?
我们先来看一个随机序列:
, 这是一个有限维n的序列,我们可以理解为一个无穷维序列
进行的n次采样。在这里
可以理解为时间,但是更准确的应该理解为一个连续的指标集。因为其一般性,就可以看成是有限维分布。
所以“随机过程的有限维分布均为正态分布”就好理解了,即
服从一个n元正太分布。
在贝叶斯优化算法中,我们通常假设 假设我们需要估计的模型
服从高斯过程,即:
采集函数(acquisition function)
从上述高斯过程可以看出,通过高斯过程给出了 的概率描述,即 在各个x值上的取值概率。那么很自然地,我们希望通过采样来精确这种描述,即选取合适的x点,使得 更加接近目标。
我们看论文的时候经常会在论述acquisition function 的地方看到两种采样思路,一种是explore和exploit:
acquisition function的目的就旨在平衡这两种采样过程。
探索(exploration)与利用(exploitation)
探索(exploration):简单来说就是尽量选择远离已知点的点为下一次用于迭代的参考点,即尽量探索未知的区域,点的分布会尽可能的平均。(也有的文章说,探索就是选择方差大的地方。本质上是一样的,因为根据高斯回归过程,远离已知点的地方方差更大)(在automl中,exploration指的是发现新的架构)
利用(exploitation):简单来说就是尽量选择靠近已知点的点为下一次用于迭代的参考点,即尽量挖掘已知点周围的点,点的分布会出现一个密集区域,容易进入局部最大。(也有的文章说,利用就是选择方差小的)(在automl中,exploitation指的是利用或共享已经发现的架构中的有用信息,如参数)
如下,上面的图表示贝叶斯优化器以利用为主,下面图表示贝叶斯优化器以探索为主。

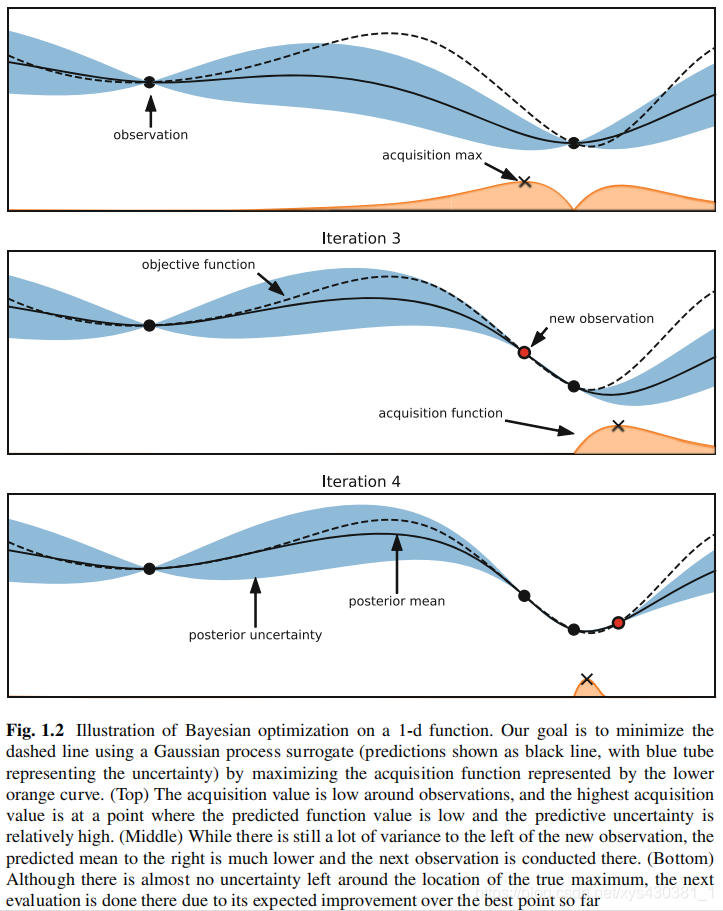
实例阐述
- 目的:本例的目的是求取最小值
- 虚线是目标函数(真正的曲线)
- 实线是通过高斯过程回归得出的均值线
- 蓝色边界是高斯过程回归得出的不确定性边界(方差)
- 黄色线由采集函数生成,黄色线上的点是经评估得出的下一个采样点
受约束的贝叶斯优化
在贝叶斯优化问题中,存在很多约束,如存储空间、时间消耗。
一个简单的办法是设置惩罚函数。
高级办法:使用信息理论采集函数的贝叶斯优化框架允许解耦目标函数和约束的评估,从而动态地选择下一个评估。
参见:book《Automated Machine Learning》—2019 springer出版
文章 《Bayesian optimization with unknown constraints》—2014
贝叶斯优化的一个完整例子
假设我们想知道下面这个黑箱函数在(-2,10)之间的最大值,最大值大概是14,我们假定找到一个点其函数值大于13,就已经可以接受了,返回该函数值。
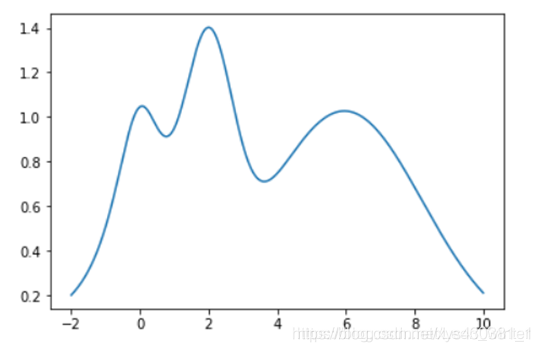
贝叶斯优化过程中,每一个step产生一个自变量x的采样点。
(第一个图产生的两个点(红点)其实是初始化过程产生的,和贝叶斯优化没有什么关系,为了方便分析,这里默认初始化的两个点也是贝叶斯优化前两次迭代过程产生的)
怎么看图?
- 在经过几次迭代,即标题中的"After xxx Steps",就有几个点的值 显示在每次迭代的上面的图中(红点标注)。
- 每次迭代的上面的图是高斯过程,根据当前的已知点,给出了f(x)的随机过程,即各个x对应的可能 ,
- 每次迭代的下面的图是采集过程(效用函数),根据UBC推测下一个合适的x点。
看第9步迭代结果(有九个采样点),可见第9步迭代结果就已经很接近真实的最大值,如果我们认为大于13的结果我们就可以接受,所以第9个确定的点就是可以接受的点,这时贝叶斯优化器就会退出迭代,把该点的值和函数值返回。
与网格搜索相比较,贝叶斯优化器可以很快地确定一个可以接受的的值,这在求黑箱函数任意函数值的时间复杂度很高时,显得尤其的有优势,同时贝叶斯优化器没有搜索细度的限制。缺点是返回的结果不一定是真实的最大值(网格搜索也不一定能找到)。

 )
)
下面以第5次迭代到第6次迭代为例,讲解一下具体的步骤
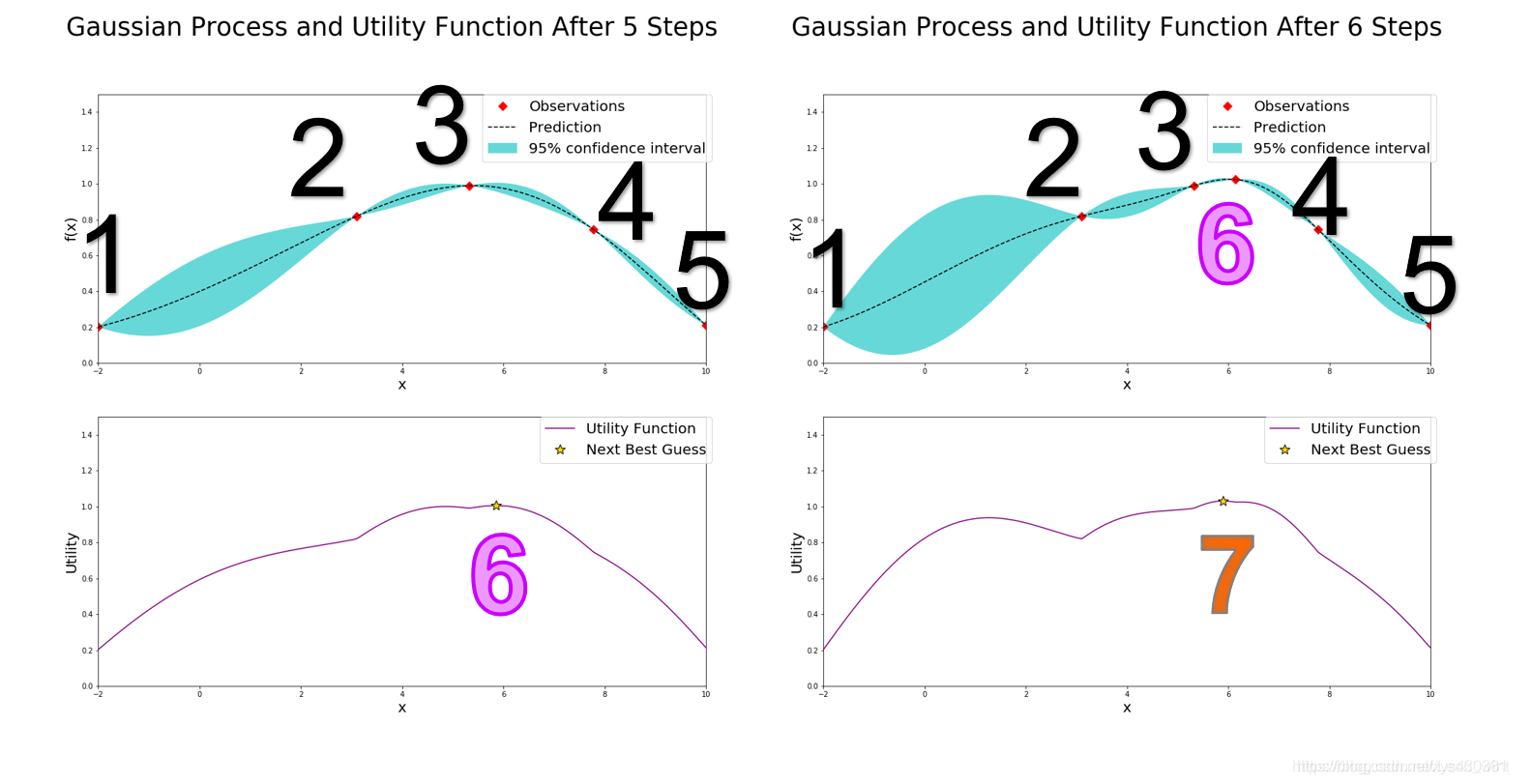
如左上图,在经过了五次迭代后,左上图已经有五个确定的点(红点标出),但是此时的最大的已确定点3达不到预期的要求(假设我们要求找到的点的函数值一定要大于13,不大于13就继续猜),因此贝叶斯优化器需要根据已知的情况(五个确定的点)进一步猜测最大点在哪里,按照UCB策略,贝叶斯优化器就计算出左下的AC函数,AC函数图像我不说也能猜到,就是左上图中的蓝色边界上界,而AC函数最大值就是贝叶斯优化器猜的第六个点的位置,计算该点的函数值,看右上图,发现点6确实比点3好一点,但是还达不到要求,继续猜第7个点的位置,就是右下图新的AC函数取得最大值的位置。
现在说一下左上图和右上图中的虚线和蓝色区间,虚线表示高斯回归过程求得的未知点的均值μ,同时高斯过程也会给出未知点的标准差σ(和已知点相比,未知点太多了),而蓝色区间就是μ±1.96σ,所以可见越是靠近已知点,标准差越小,越是远离已知点,标准差越大,此时说明高斯过程回归对这个未知点越不确定。
完整的步骤见图下:
)







TPE算法(Tree-Structured Parzen Estimator)
原文:Bergstra J S, Bardenet R, Bengio Y, et al. Algorithms for hyper-parameter optimization—nips2011
TPE 依旧属于贝叶斯优化,其和 SMAC 也有着很深的渊源。其为一种基于树状结构 Parzen 密度估计的非标准贝叶斯优化算法。相较于其他贝叶斯优化算法,TPE 在高维空间表现最佳。
优点 1:相比其他贝叶斯优化算法,高维空间的情况下效果更好
优点 2:相比 BO 速度有显著提升
注:所有贝叶斯优化算法在高维空间下表现均和 Random Search 相当 .
TPE能处理的数据类型
原文中关于数据类型的描述:
the configuation space is described using uniform, log-uniform, quantized log-uniform, and categorical variables. In these cases, the TPE algorithm makes the following replacements:
uniform → truncated Gaussian mixture,
log-uniform → exponentiated truncated Gaussian mixture,
categorical → re-weighted categorical
Python 环境下有一些贝叶斯优化程序库,它们目标函数的代理算法有所区别。本部分主要介绍「Hyperopt」库,它使用树形 Parzen 评估器(TPE)作为搜索算法。该库中可以优化四种参数类型:
choice(categorial):类别变量
quniform:离散均匀分布(在整数空间上均匀分布)
uniform:连续均匀分布(在浮点数空间上均匀分布)
loguniform:连续对数均匀分布(在浮点数空间中的对数尺度上均匀分布)
为什么说TPE是树形结构
参数配置空间是树形的。前面的参数决定了后续要选择使用哪些参数,以及参数的取值范围
参考:What makes a Tree-Structured Parzen Estimator “tree-structured?”
It means that your hyperparameter space is tree-like: the value chosen for one hyperparameter determines what hyperparameter will be chosen next and what values are available for it.
From a HyperOpt example, in which the model type is chosen first, and depending on that different hyperparameters are available:
space = hp.choice('classifier_type', [
{
'type': 'naive_bayes',
},
{
'type': 'svm',
'C': hp.lognormal('svm_C', 0, 1),
'kernel': hp.choice('svm_kernel', [
{'ktype': 'linear'},
{'ktype': 'RBF', 'width': hp.lognormal('svm_rbf_width', 0, 1)},
]),
},
{
'type': 'dtree',
'criterion': hp.choice('dtree_criterion', ['gini', 'entropy']),
'max_depth': hp.choice('dtree_max_depth',
[None, hp.qlognormal('dtree_max_depth_int', 3, 1, 1)]),
'min_samples_split': hp.qlognormal('dtree_min_samples_split', 2, 1, 1),
},
])
原文:
In this work we restrict ourselves to tree-structured configuration spaces. Configuration spaces are tree-structured in the sense that some leaf variables (e.g. the number of hidden units in the 2nd layer of a DBN) are only well-defined when node variables (e.g. a discrete choice of how many layers to use) take particular values.
PBT优化(deepmind 2017年)
《Population Based Training of Neural Networks》论文解读
问题分析
神经网络的训练受模型结构、数据表征、优化方法等的影响。而每个环节都涉及到很多参数(parameters)和超参数(hyperparameters),对这些参数的调节决定了模型的最终效果。通常的做法是人工调节,但这种方式费时费力且很难得到最优解。
两种常用的自动调参的方式是并行搜索(parallel search)和序列优化(sequential optimisation)。
- 并行搜索就是同时设置多组参数训练,比如网格搜索(grid search)和随机搜索(random search)。
- 序列优化很少用到并行,而是一次次尝试并优化,比如人工调参(hand tuning)和贝叶斯优化(Bayesian optimisation)。
并行搜索的缺点在于没有利用相互之间的参数优化信息。而序列优化这种序列化过程显然会耗费大量时间。
还有另一个问题是,对于有些超参数,在训练过程中并不是一直不变的。比如监督训练里的学习率,强化学习中的探索度等等。通常的做法是给一个固定的衰减值,而在强化学习这类问题里还会随不同场景做不同调整。这无疑很难找到一个最优的自动调节方式。
具体方法
作者提出了一种很朴素的思想,将并行优化和序列优化相结合。既能并行探索,同时也利用其他更好的参数模型,淘汰掉不好的模型。
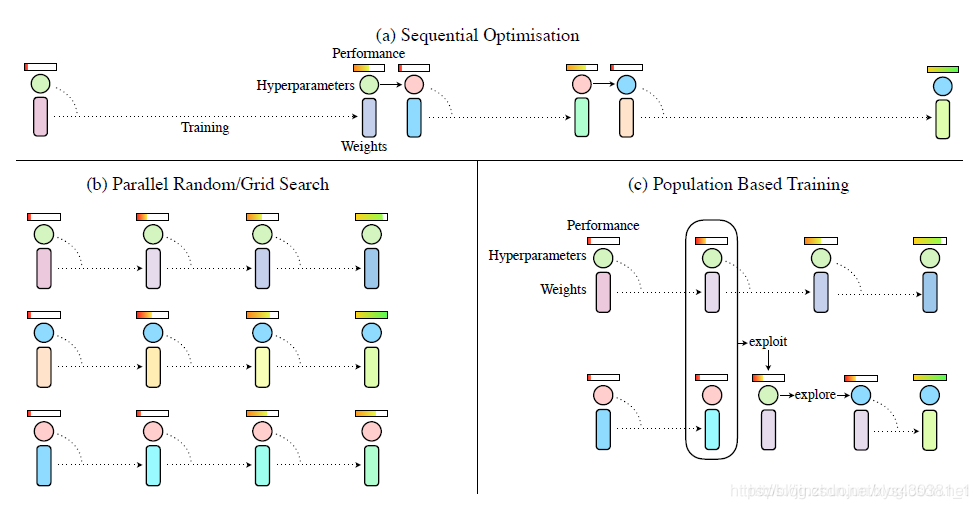
如图所示,(a)中的序列优化过程只有一个模型在不断优化,消耗大量时间。(b)中的并行搜索可以节省时间,但是相互之间没有任何交互,不利于信息利用。©中的PBT算法结合了二者的优点。
首先PBT算法随机初始化多个模型,每训练一段时间设置一个检查点(checkpoint),然后根据其他模型的好坏调整自己的模型。若自己的模型较好,则继续训练。若不好,则替换(exploit)成更好的模型参数,并添加随机扰动(explore)再进行训练。其中checkpoint的设置是人为设置每过多少step之后进行检查。扰动要么在原超参数或者参数上加噪声,要么重新采样获得。作者还写了几个公式来规范说明这个问题,看起来逼格更高一点,我个人觉得没有必要再写在这里了。
PBT是一种很通用的方法,可以用于很多场景,其一般套路如下:
- Step:对模型训练一步。至于一步是一次iteration还是一个epoch还是其它可以根据需要指定。
- Eval:在验证集上做评估。
- Ready: 选取群体中的一个模型来进行下面的exploit和explore操作(即perturbation)。这个模型一般是上次做过该操作后经过指定的时间(或迭代次数等)。
- Exploit: 将那些经过评估比较烂的模型用那些比较牛叉的模型替代。
- Explore: 对上一步产生的复制体模型加随机扰动,如加上随机值或重采样。
现有项目
Google Vizier
前面已经介绍了Grid search、Random search和Bayesian Optimization等算法,但并不没有完,因为我们要使用这些自动调参算法不可能都重新实现一遍,我们应该关注于自身的机器学习模型实现而直接使用开源或者易用的调参服务。
近期Google就开放了内部调参系统Google Vizier的论文介绍,感兴趣可以在这里阅读
paper https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/46180.pdf
与开源的hyperopt、optunity不同,Vizier是一个service而不是一个library,也就是算法开发者不需要自己部署调参服务或者管理参数存储,只需要选择合适的调参算法,如贝叶斯优化,然后Vizier就会根据模型的一些历史指标推荐最优的超参数组合给开发者,直接使用这些超参数会比自己瞎猜或者遍历参数组合得到的效果更好。当然开发者可以使用Vizier提供的Algorithm Playground功能实现自己的自动调参算法,还有内置一些EarlyStopAlgorithm也可以提前发现一些“没有前途”的调优任务提前结束剩下计算资源。
目前Google Vizier已经支持Grid search、Random search已经改良过的Bayesian optimization,为什么是改良过的呢?前面提到贝叶斯优化也需要几个初始样本点,这些样本点一般通过随机搜索要产生,这就有冷启动的代价了,Google将不同模型的参数都归一化进行统一编码,每个任务计算的GaussianProcessRegressor与上一个任务的GaussianProcessRegressor计算的残差作为目标来训练,对应的acquisition function也不是简单的均值乘以n倍方差了,这相当于用了迁移学习模型的概念,从paper的效果看基本解决了冷启动的问题,这个模型被称为(Stacked)Batch Gaussian Process Bandit。
Google Vizier除了实现很好的参数推荐算法,还定义了Study、Trial、Algorithm等非常好的领域抽象,这套系统也直接应用到Google CloudML的HyperTune subsystem中,开发者只需要写一个JSON配置文件就可以在Google Cloud上自动并行多任务调参了。
Advisor开源项目
Google Vizier是目前我看过最赞的超参数自动调优服务,可惜的是它并没有开源,外部也只有通过Google CloudML提交的任务可以使用其接口,不过其合理的基础架构让我们也可以重现一个类似的自动调参服务。
Advisor就是一个Google Vizier的开源实现,不仅实现了和Vizier完全一致的Study、Trial、Algorithm领域抽象,还提供Grid search、Random search和Bayesian optimization等算法实现。使用Advisor很简单,我们提供了API、SDK、Web以及命令行等多种访问方式,并且已经集成Scikit-learn、XGBoost和TensorFlow等开源机器学习框架,基本只要写一个Python函数定义好模型输入和指标就可以实现任意的超参数调优(黑盒优化)功能。
Advisor使用Python实现,基于Scikit-learn的GPR实现了贝叶斯优化等算法,也欢迎更多开发者参与,开源地址 tobegit3hub/advisor 。
Advisor在线服务
hypertune.cn 是我们提供的在线超参数推荐服务,也是体验Advisor调参服务的最好入口,在网页上我们就可以使用所有的Grid search、Random search、Bayesian optimization等算法功能了。
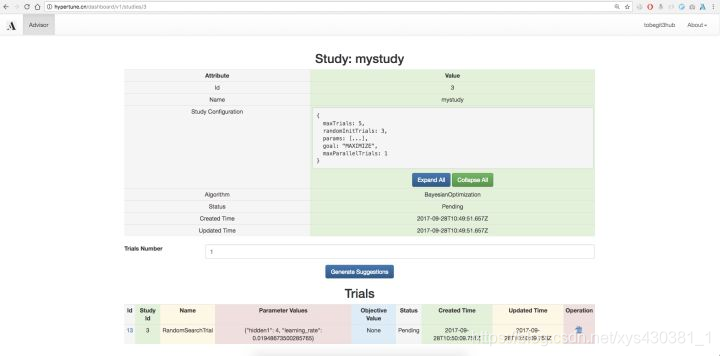
首先打开 http://hypertune.cn , 目前我们已经支持使用Github账号登录,由于还没有多租户权限隔离因此不需要登录也可以访问全局信息。在首页我们可以查看所有的Study,也就是每一个模型训练任务的信息,也可以在浏览器上直接创建Study。
这里需要用户定义Study configuration,也就是模型超参数的search space,和Google Vizier一样我们支持Double、Integer、Discrete和Categorical四种类型的超参数定义,基本涵盖了数值型、字符串、连续型以及离散型的任意超参数类别,更详细的例子如下图。
定义好Study好,我们可以进入Study详情页,直接点击“Generate Suggestions”按钮生成推荐的超参数组合,这会根据用户创建Study选择的调参算法(如BayesianOptimization)来推荐,底层就是基于Scikit-learn实现的联合高斯分布、高斯过程回归、核技巧、贝叶斯优化等算法实现。
当然我们也可以使用Grid search、Random search等朴素的搜索算法,生成的Trial就是使用的该超参数组合的一次运行,默认是没有objective value的,我们可以在外部使用该超参数进行模型训练,然后把auc、accuracy、mean square error等指标在网页上回填到参数推荐服务,下一次超参数推荐就会基于已经训练得到模型数据,进行更优化、权衡exploritation和exploration后的算法推荐。对于Eearly stop算法,我们还需要每一步的性能指标,因此用户可以提供Training step以及对应的Objective value,进行更细化的优化。
除了提供在网页上集成推荐算法,我们也集成了Scikit-learn、XGBoost和TensorFlow等框架,在命令行只要定义一个函数就可以自动实现创建Study、获取Trial以及更新Trial metrics等功能,参考 https://github.com/tobegit3hub/advisor/tree/master/examples 。对于贝叶斯优化算法,我们还提供了一维特征的可视化工具,像上面的图一样直观地感受均值、方差、acquisition function的变化,参考 https://github.com/tobegit3hub/advisor/tree/master/visualization 。
