
目录
一.引言
机器翻译的人工评价广泛而昂贵,且人工评估可能需要持续数月才能完成且涉及到无法重复使用的人工劳动。BLEU - bilingual evaluation understudy 字面直译意思为'双语评估替身',它的诞生意在提供一种双语互译的质量评估辅助。该方法快速、廉价且独立于语言,且与人类评估高度相关。该评估方法最早应用于机器翻译与人工翻译的快速效果评估,当下 LLM 火热但很多生成的答案由于需要人工评估效果好坏从而导致没有量化指标衡量其好坏,这里简单介绍下 BLEU 的计算与使用。
二.BLEU 简介
Bleu 实现的主要编程任务是将候选者的 n-gram 与参考翻译的 n-gram 进行比较并计算匹配的数量。这些匹配与位置无关。匹配越多,候选翻译越好。为简单起见,我们首先专注于计算 unigram 匹配。
1.Simple BLEU

以一元组即单个单词为例:
◆ Reference 1、2 为参考输出,MT output 为机器翻译输出
◆ MT output 输出三个词均为 the,分母为 7
◆ the 在参考译文中均出现,所以分子为 7
此时 P = 7 / 7 = 1,显然与我们的直观感受不匹配。
2.Modified BLEU
前面这种简单的判断候选翻译词是否在参考语句中出现的 contains 方法显然不够理想,所以提出了 Modified BLEU,Modified 主要修改了上述分子不合理的计算方式,这里有如下定义:
修剪即修改后的单词 Wi 在 Reference J 中的 Count 计算为上式,其中:
◆ 代表单词 wi 的个数,上文中 wi = the,其在 MT output 中个数为 7
◆代表 wi 在 参考 j 中出现的次数,the 在 R1 中出现了 2 次,在 R2 中出现了 1 次
◆ 该指标定义了对于第 j 个参考,wi 的截断计数,对于 R1 该值为 min(7, 2) = 2,R2 为 1
◆ wi 在所有参考翻译里的综合截断计数,以 the 为例,这里 max(1, 2) = 2
修改后的方法分母不变仍未 7,分子为 2,所以 BELU Score = 2 / 7,修改后的分数相对合理。
3.Modified n-gram precision
上面只考虑了单个单词的情况,虽然我们调整了分子的计算方法,分数虽然相对合理,但是由于翻译是重复的单个单词,所以实际观感依然很差。基于这种情况,算法考虑引入 N-Gram,针对不同的词组进行 BLEU 分数的评估,一般 N = 4,以下面语句为例:

我们分别基于 MT output 计算 1-gram 到 4-gram:
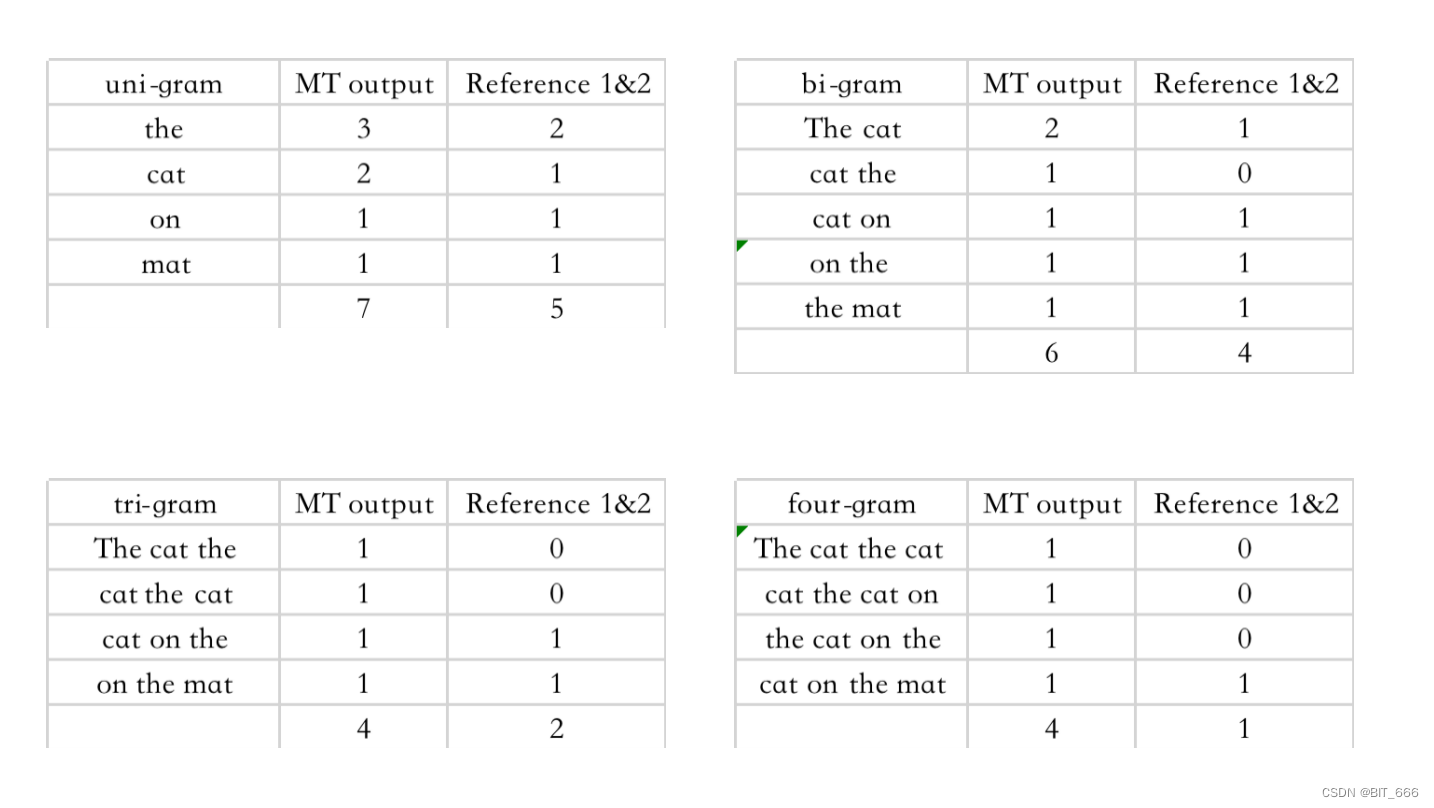
对于更长的段落,我们可以将其理解为更大的句子:

这里使用句子级修改精度的单词加权平均值,而不是句子加权平均值。
4.Sentence brevity penalty

译句较短时,计算得到的 BLEU 分数会有一定失真,为此引入了 Sentence brevity penalty 翻译短句惩罚,对于译句相对参考翻译较短的情况通过引入 BP 对短句进行惩罚:
修改前的 BLEU 计算公式:
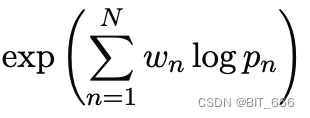
这里采用加权求和的方式,针对不同 n-gram 的概率进行计算,修改后的 BELU 公式为:

c 代表 candidate 候选翻译,r 代表 reference 参考翻译,对于 c ≤ r 的情况,会针对分数进行一些惩罚,其中 BP 的计算基于 r、c 和 exp 指数函数。论文中 baseline 的 n-gram 选择为 N=4,Wn 选择为 1/N。
三.BLEU 计算
python 通过 nltk 库可以计算 output 与 reference 之间的 BLEU 分数,多个 reference 可以通过 reference 的列表传递。BLEU 分数的范围通常在 0-1 之间,其中 1 表示完美匹配,分数越高匹配程度越高。
1.计算句子与单个 reference
from nltk.translate.bleu_score import sentence_bleu
# 参考句子列表
reference = [['The', 'cat', 'is', 'on', 'the' ,'mat']]
# 候选句子
candidate = ['the', 'the', 'the', 'the', 'the', 'the', 'the']
# 计算BLEU分数
bleu_score = sentence_bleu(reference, candidate)
print("BLEU分数:", bleu_score)以上面 7 个 'the' 为例 BLEU分数: 1.1200407237786664e-231。

2.计算句子与多个 reference
from nltk.translate.bleu_score import sentence_bleu
# 参考句子列表
reference = [['The', 'cat', 'is', 'on', 'the' ,'mat'],['There', 'is', 'a', 'cat', 'on', 'the', 'mat']]
# 候选句子
candidate = ['The', 'cat', 'the', 'cat', 'on', 'the', 'mat']
# 计算BLEU分数
bleu_score = sentence_bleu(reference, candidate)
print("BLEU分数:", bleu_score)以 'the cat the cat on the mat' 为例 BLEU分数: 0.4671379777282001。
四.总结
BLEU 最早用于评估机器翻译结果,其主要考虑 n-gram 词组的匹配程度,并引入了 BP 惩罚系数。BLEU 的优点是计算快速,定义简单,结果具有一定参考价值;缺点是只考虑单词的简单组合,未考虑更复杂的语法或近似表达。
提起 n-gram 不得不想起 embedding 的鼻祖 word2vec,本质上 BLEU 其实也是在计算共现的频率,并针对长短句的情况进行了一定的加权优化。所以在 LLM 领域,我们一方面可以基于 NLTK API 快速计算生成效果的硬性指标,另一方面也可以基于 n-gram 进行指标的修改适配自己的业务特点。