Faster-Rcnn代码下载地址:https://github.com/ShaoqingRen/faster_rcnn
一 前言
Faster rcnn是用来解决计算机视觉(CV)领域中Object Detection的问题的。最初的检测分类的解决方案是:Hog+SVM来实现的;深度学习中经典的解决方案是使用: SS(selective search)产生proposal,之后使用像SVM之类的classifier进行分类,得到所有可能的目标。也就是为检测开辟新天地的RCNN方法。
那么几种深度学习的目标检测算法有什么区别呢?首先看下图的结构所示:
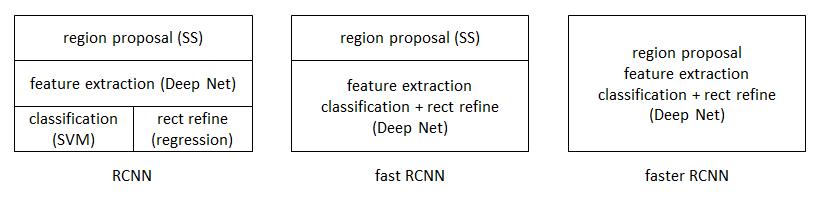
(1)RCNN 解决的是,“为什么不用CNN做classification呢?” 用SS去选框,CNN提特征,SVM分类。BB盒回归。
(2)Fast-RCNN 解决的是,“为什么不一起输出bounding box和label呢?”
(3)Faster-RCNN 解决的是,“为什么还要用selective search呢?为什么不用CNN做特征提取呢?” 鉴于神经网络的强大的feature extraction能力,可以将目标检测的任务放到NN上面来做,于是出现了RPN(region proposal network)
二 为什么做Faster-Rcnn
(1)SPPnet 和 Fast R-CNN 已经减少了detection步骤的执行时间,只剩下region proposal成为瓶颈;
(2)因此提出了 Region Proposal Network(RPN) 用来提取检测区域,并且和整个检测网络共享卷积部分的特征。RPN同时训练区域的边界和objectness score(理解为是否可信存在oject);
(3)最终把RPN和Fast-RCNN合并在一起,用了“attention” mechanisms(其实就是说共享这事)。在VOC数据集上可以做到每张图只提300个proposals(Fast-RCNN用selective search是2000个)。
三 Region Proposal Network(RPN)的结构
基本设想是:在提取好的特征图上,对所有可能的候选框进行判别。
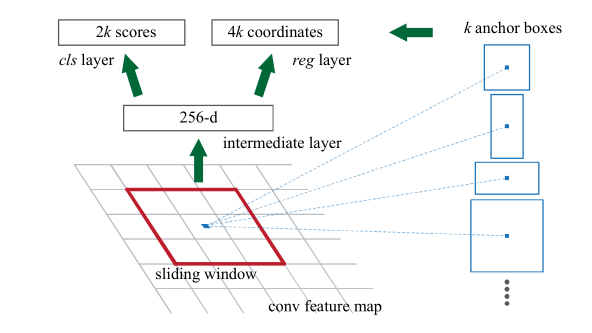
RPN的网络流程图,即也是利用了SPP的映射机制,从conv5上进行滑窗来替代从原图滑窗。在这个特征图上使用3*3的卷积核(滑动窗口)与特征图进行卷积,那么这个3*3的区域卷积后可以获得一个256维的特征向量。因为这个3*3的区域上,每一个特征图上得到一个1维向量,256个特性图即可得到256维特征向量。
3*3滑窗中心点位置,对应预测输入图像3种尺度(128,256,512),3种长宽比(1:1,1:2,2:1)的regionproposal,这种映射的机制称为anchor,产生了k=9个anchor。即每个3*3区域可以产生9个region proposal。所以对于这个40*60的feature map,总共有约20000(40*60*9)个anchor,也就是预测20000个region proposal。
后面接入到两个全连接层,即clslayer和reglayer分别用于分类和边框回归。clslayer包含2个元素,用于判别目标和非目标的估计概率。reglayer包含4个坐标元素(x,y,w,h),用于确定目标位置。cls:正样本,与真实区域重叠大于0.7,负样本,与真实区域重叠小于0.3。reg:返回区域位置。
最后根据region proposal得分高低,选取前300个region proposal,作为Fast R-CNN的输入进行目标检测。
四 Region Proposal Network(RPN)的作用
(1) 输出proposal的位置(坐标)和score ;
(2) 将不同scale和ratio的proposal映射为低维的feature vector ;
(3) 输出是否是前景的classification和进行位置的regression;
(4) RPN输出对于某个proposal,判断属于前景或者背景,其中主要是和ground-truth的IoU做比较,小于0.3视为negative(背景),大于0.7视为positive(前景),其它的直接抛弃不进行训练使用。
五 Region Proposal Network(RPN)的训练方式
两种训练方式: joint training(联合训练)和alternating training (交替训练):
(1) 交替训练:首先训练RPN, 之后使用RPN产生的proposal来训练Fast-RCNN, 使用被Fast-RCNN tuned的网络初始化RPN,如此交替进行。
(2) 联合训练:首先产生region proposal,之后直接使用产生的proposal训练Faster-RCNN,在backward计算梯度时,把提取的ROI区域当做固定值看待;在backward更新参数时,来自RPN和来自Fast RCNN的增量合并输入原始特征提取层。
六 Faster-Rcnn的几种输入scale
(1)原图尺度:原始输入的大小。不受任何限制,不影响性能。
(2)归一化尺度:输入特征提取网络的大小,在测试时设置,源码中opts.test_scale=600。anchor在这个尺度上设定。这个参数和anchor的相对大小决定了想要检测的目标范围。
(3)网络输入尺度:输入特征检测网络的大小,在训练时设置,源码中为224*224。
七 Faster-Rcnn实验结果
(1)与Selective Search方法(黑)相比,当每张图生成的候选区域减少时,本文RPN方法(红蓝)的召回率下降不大,说明RPN方法的目的性更明确。
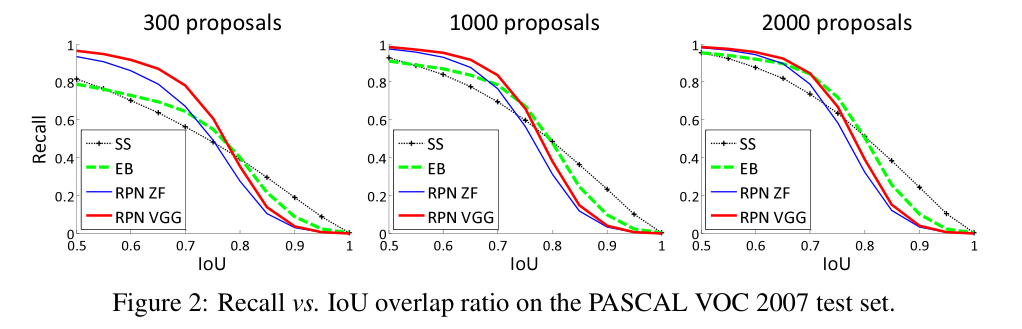
(2) 在不同的数据集上,平均物体检测率(mean Averaged Precision, mAP)的对比