自己在本机准备安装四台linux环境,我本机安装的是最小化安装(内存分配512M),
首先配置vi /etc/hosts
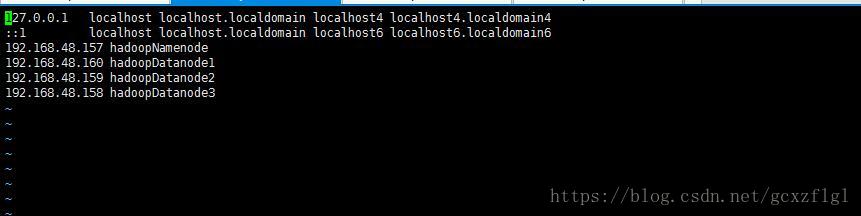
host名字千万别有* / _等特殊字符,否则当你后面配置好后启动datenode报错:Does not contain a valid host:port authority
然后关闭防火墙:service iptables stop ---- chkconfig iptables off
安装好一台后,其余三台克隆,克隆后的机器需要修改两处
第一处:vi /etc/udev/rules.d/70-persistent-net.rules
发现最下面有两处网络配置,其中eth1是本机的网络配置,我们删除eth0之后,然后将eth1修改为0,
第二处:vi /etc/sysconfig/network-scripts/ifcfg-eth0
删除网关和UUID即可

然后重启机器就可以了
安装集群之前首先安装jdk环境,本次以jdk1.7为例点击打开链接
安装后,我们先安装gcc 命令:yum -y install gcc-c++
为了同时对机器进行操作,我们需要配置免密登陆点击打开链接,
mini版(最小化安装时没有openssh-clients),我们安装下 命令:yum -y install openssh-clients
以上工作做完后开始解压hadoop安装包,大家自己官网下载即可
第一步解压文件:
解压后目录下多个类似 hadoop-2.6.4的文件夹,大家自己下载的解压后对应自己下载后的版本
首先进入指定目录 命令:cd hadoop-2.6.4/etc/hadoop
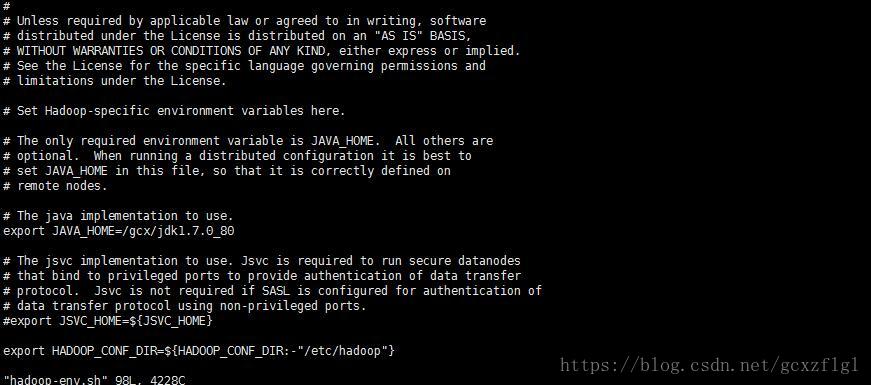
首先修改vi hadoop-env.sh下的JAVA_HOME,第一次进来时是默认的${JAVA_HOME},
因为我们在操作过程中不是在同一个bash里,所以写${JAVA_HOME}不会生效,换成自己的jdk就可以了
第二步修改vi core-site.xml
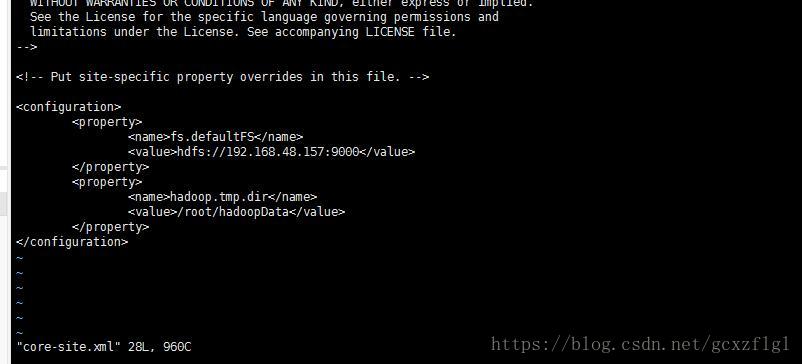
第一个property配置指定HADOOP所使用的文件系统schema(URI),HDFS的老大(NameNode)的地址
第二个property配置指定hadoop运行时产生文件的存储目录
第三步修改vi hdfs-site.xml
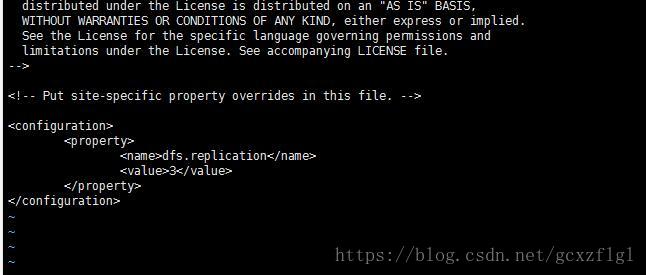
这个是配置副本的数量,假设其中一台机器挂掉,其余两台还有这个数据的备份
第四步复制一个 mapred-site.xml ,然后编辑文件
cp mapred-site.xml.template mapred.site.xml
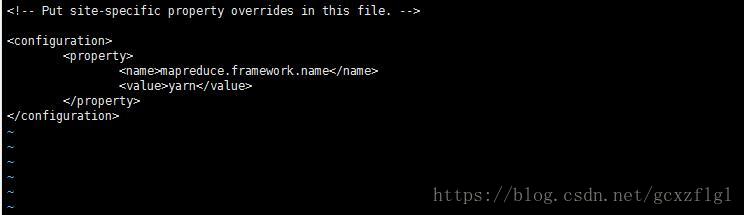
指定mr运行在yarn上
第五步修改vi yarn-site.xml
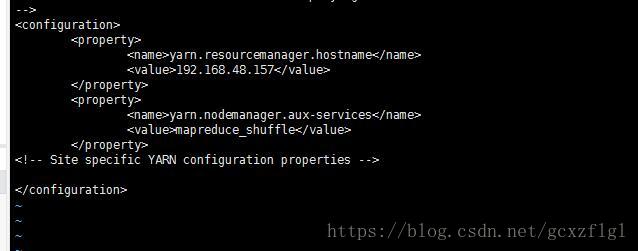
第一个property配置指定YARN的老大(ResourceManager)的地址
第二个property配置指定reducer获取数据的方式
第六步修改环境变量
vi /etc/profile
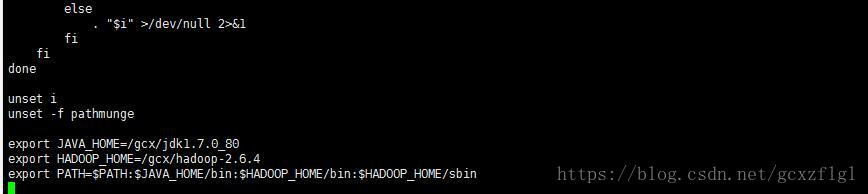
第七步复制hadoop-2.6.4和/etc/hosts/、/etc/profile到其他机器上
scp -r /gcx/hadoop-2.6.4 hadoopDatanode1:/gcx/
scp /etc/hosts hadoopDatanode1:/etc/
scp /etc/profile hadoopDatanode1:/etc/
其余地址同理
第八步:namenode格式化信息并且创建保存hadoop运行时产生文件的存储目录
推荐大家用xshell6全会话操作,就不用来回写重复命令
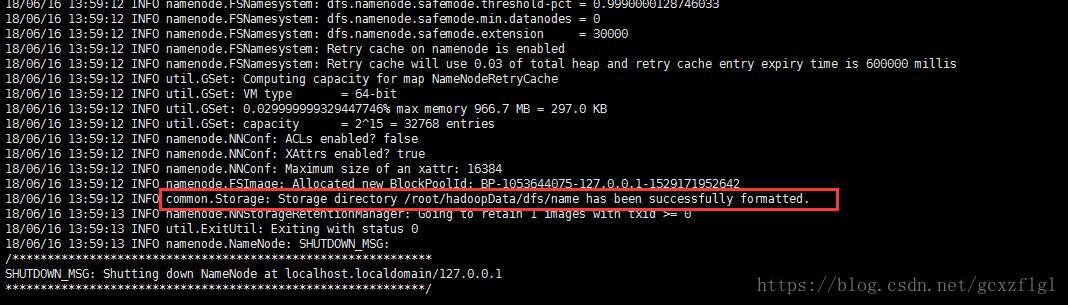
namenode机器格式化:hadoop namenode -format
会打印出这样的信息代表成功
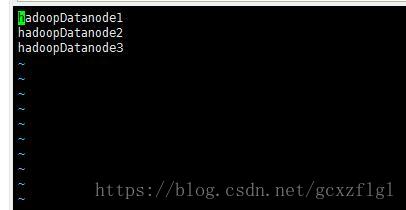
第九步配置slaves
hadoop提供了一个命令启动全部需要启动的文件
vi hadoop-2.6.4/etc/hadoop/slaves
里面有默认的localhost直接干掉,换成datanode的host名
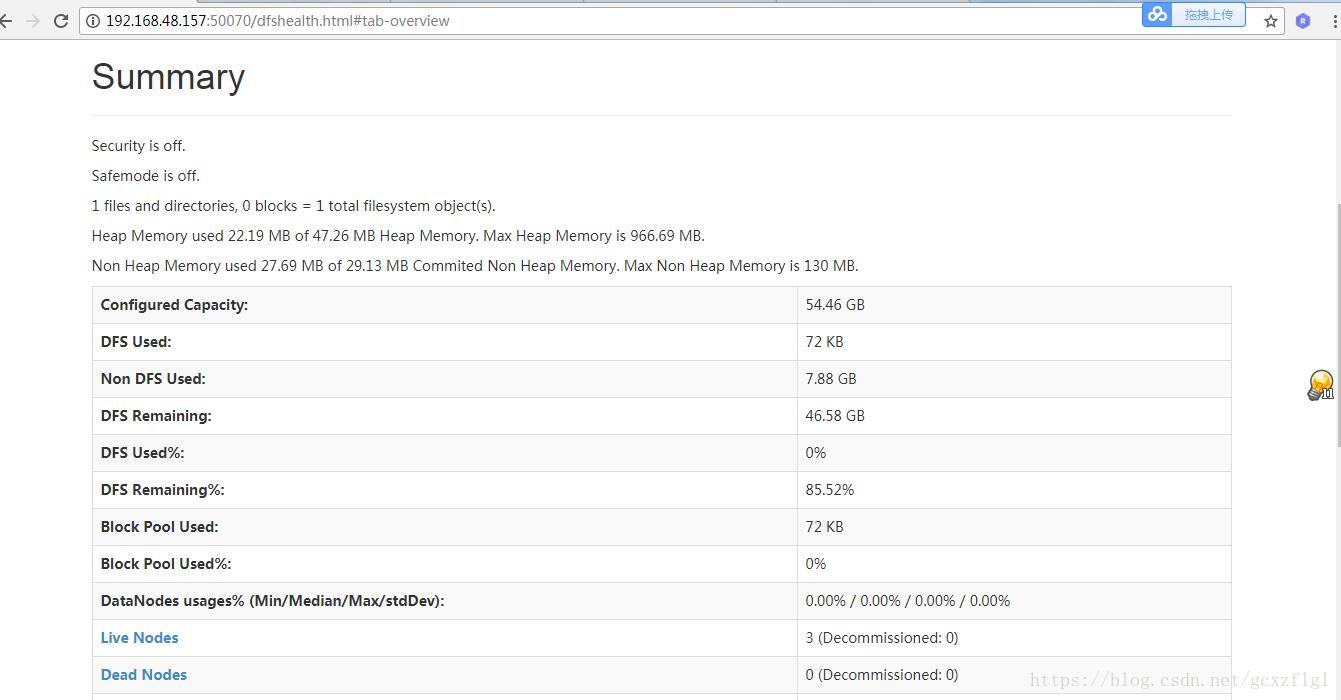
第十步启动命令后访问页面:
hadoop-2.6.4/sbin/start-all.sh
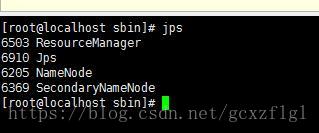
当前namenode jps后会有这几个
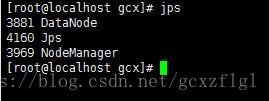
datenode会有这几个
浏览器访问地址后显示看到三台datanode全部启动起来了,这就完成了初步的搭建