注:安装hadoop时,hadoop的安装包需要在jdk下编译,否则安装hadoop时,无法与jdk兼容。这个链接是jdk1.8.版本环境下编译好的hadoop-2.7.3.tar.gz安装包。
链接:https://pan.baidu.com/s/16fSLciWuLExV5p6zaPJcgg
提取码:16ye
本配置为三台机器(hadoop1、hadoop2、hadoop3),所有操作先在一台机器上操作
修改主机名和ip映射
[root@hadoop1 ~]# vi /etc/hosts
<!--虚拟机IP 映射名-->
192.168.233.128 hadoop1
192.168.233.129 hadoop2
192.168.233.130 hadoop3
注:搭建几台机器,此处就写几个"机器ip 映射"
安装jdk与hadoop
[root@hadoop1 usr]# mkdir java
[root@hadoop1 usr]# mkdir hadoop
[root@hadoop1 usr]# cd java
[root@hadoop1 java]# jdk-8u141-linux-x64.tar.gz
[root@hadoop1 java]# tar -zxvf jdk-8u141-linux-x64.tar.gz
[root@hadoop1 usr]# cd hadoop
[root@hadoop1 hadoop]# hadoop-2.7.3.tar.gz
[root@hadoop1 hadoop]# tar -zxvf hadoop-2.7.3.tar.gz
配置jdk与hadoop环境
[root@hadoop1 hadoop]# vim /etc/profile
[root@hadoop1 hadoop]# source /etc/profile
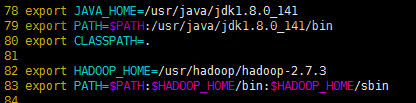
关联集群的映射
[root@hadoop1 hadoop]# vi /usr/hadoop/hadoop-2.7.3/etc/hadoop/slaves
#搭建几台电脑,此处就写几个映射
hadoop1
hadoop2
hadoop3
修改配置文件
[root@hadoop1 hadoop]# /usr/hadoop/hadoop-2.7.3/etc/hadoop
修改jdk的安装路径
[root@hadoop1 hadoop]# vi hadoop-env.sh

[root@hadoop1 hadoop]# vi core-site.xml
<!-- 制定HDFS的老大(NameNode)的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop1:9000</value>
</property>
<!-- “localhost”为主机的映射名 -->
<!-- 指定hadoop运行时产生文件的存储目录[能自动生成目录] -->
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop/tmp</value>
</property>
[root@hadoop1 hadoop]# vi hdfs-site.xml
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--如果namenode节点出不来就使用命令删掉name文件夹 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/hadoop/tmp/dfs/name</value>
</property>
<!-- 数据存储的地址,如果datenode节点出不来就删掉data文件夹 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop/tmp/dfs/data</value>
</property>
[root@hadoop1 hadoop]#cp mapred-site.xml.template mapred-site.xml
[root@hadoop1 hadoop]#vi mapred-site.xml
<!-- 指定mr运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
[root@hadoop1 hadoop]#vi yarn-site.xml
<!-- 指定YARN的老大(ResourceManager)的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop1</value>
</property>
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
配置免密登录(所有机器都需要配置)
https://blog.csdn.net/weixin_38613375/article/details/89180346
将配置好的文件传送到其他机器
[root@hadoop1 hadoop]scp -r /usr/java root@hadoop2:/usr
[root@hadoop1 hadoop]scp -r /usr/java root@hadoop3:/usr
[root@hadoop1 hadoop]scp -r /usr/hadoop root@hadoop2:/usr
[root@hadoop1 hadoop]scp -r /usr/hadoop root@hadoop3:/usr
[root@hadoop1 hadoop]scp /etc/profile root@hadoop2:/etc/profile
[root@hadoop1 hadoop]scp /etc/profile root@hadoop3:/etc/profile
[root@hadoop2 hadoop]source /etc/profile
[root@hadoop3 hadoop]source /etc/profile
格式化namenode
[root@hadoop1 hadoop] hadoop namenode -format
注:对namenode进行初始化(只能格式化一次,多次格式化会出错),在NameNode所在的机器上格式化
启动hadoop
先启动HDFS(在NameNode所在的机器上)
[root@hadoop1 hadoop]# start-dfs.sh
再启动YARN(在ResourceManager所在的机器上)
[root@lhadoop1 hadoop]# start-yarn.sh
验证是否启动成功
[root@hadoop1 hadoop]# jps
3912 DataNode
4378 Jps
4331 NodeManager
4093 SecondaryNameNode
3822 NameNode
4239 ResourceManager
[root@hadoop2 hadoop]# jps
4678 NodeManager
4810 Jps
4571 DataNode
[root@hadoop3 hadoop]# jps
4678 NodeManager
4810 Jps
4571 DataNode
关闭防火墙(所有机器都关闭)
停止firewall
[root@hadoop1 hadoop]# systemctl stop firewalld
#禁止firewall开机启动
[root@hadoop1 hadoop]#systemctl disable firewalld.service
浏览器查看
http://ip地址:50070 (HDFS管理界面)
http://ip地址:8088 yarn管理界面)