Hadoop2和Hadoop1是不一样的,所以专门为了Hadoop2 做了一个记录。
我的环境是Ubuntu 16.4
首先确保Java已经安装完毕,并且环境变量已经配置OK,具体的细节我就不在这里讲解了。
然后确保ssh已经安装好,sshd需要启动并且使用Hadoop的脚本管理远程的Hadoop节点。
安装ssh相关:
sudo apt-get install ssh
sudo apt-get install rsync
下载并配置Hadoop 2.6.5:
下载完成后,解压到/bigdata 目录,并做下面的操作。
- 修改etc/hadoop/hadoop-env.sh文件,加入java和Hadoop的根目录位置信息:

-
修改etc/hadoop/core-site.xml:
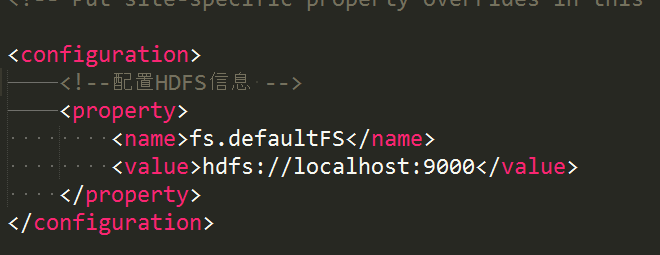
-
修改etc/hadoop/hdfs-site.xml

配置Ubuntu 免密码登录:
-
ssh-keygen -t rsa
我的系统是Ubuntu 16 ,所以直接一直回车到底就可以了
-
cat .ssh/id_rsa.pub >> .ssh/authorized_keys
把公钥里面的内容,放到authorized_keys 这个文件里面,这样的话我们就可以直接在本地直接ssh 面密码登录到本机。尝试着直接执行 ssh localhost ,可以直接不需要输入密码登录到本地机器(如果第一次的时候遇到需要确认的时候,直接输入yes,第二次就不需要了)。
把Hadoop配置到环境变量:
修改.profile 文件,在最后一行加入Hadoop环境信息,见下图

接下来执行 source .profile 命令,把配置生效。
格式化HDFS:
执行如下的命令:
hdfs namenode -format
其实HDFS给我一种其实相当于是一个大的网盘一样的感觉。可以保证我们存进去的文件是具有高安全性的。并且也有一定的效率保证。
启动HDFS的NameNode和DataNode的守护进程:
start-dfs.sh
Hadoop的守护进程日志默认是保存在$HADOOP_LOG_DIR 这个变量所指向的目录中。如果这个变量不存在的话,那么默认存储到 $HADOOP_HOME/logs 这个目录中
通过浏览器访问查看nameNode 的信息的话,默认的URL为: http://localhost:50070/
这是我在手机上访问的结果:
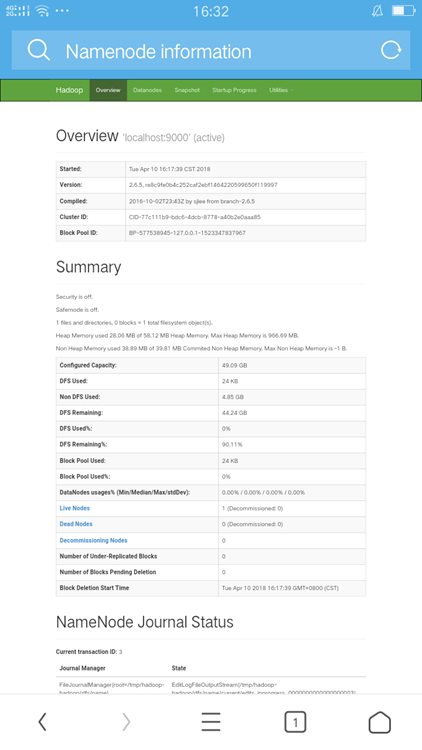
在HDFS上面创建目录:
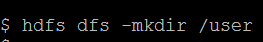
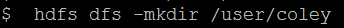
然后查看自己创建的目录已经成功:

OK到这里,HDFS基本上已经没什么问题了。
往HDFS里面放文件并测试:
-
在HDFS 中建立一个input 目录
-
往这个目录中放置一些文件,这里我就直接使用etc/hadoop 下的所有配置文件放进去
-
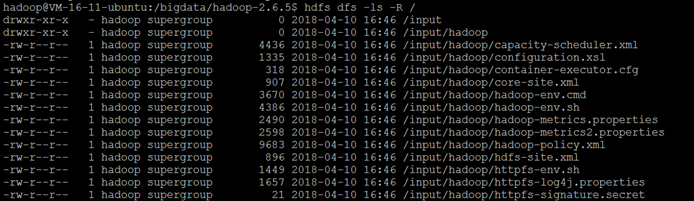
a 查看文件是否已经放置成功
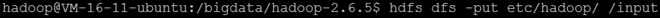
4. 接下来执行一个example的 Hadoop 包来测试下环境是否可以运行
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.5.jar grep /input/hadoop/core-site.xml /user/coley/test1 'dfs[a-z.]+'
红色字体的为HDFS中的源文件的路径,蓝色字体为HDFS中的target 路径的位置,用于存放处理完成后的文件。
通过HDFS命令查看目标路径,可以看到有如下两个文件:

从HDFS把文件下载到本地,然后查看具体的内容:

如果想关闭HDFS的话,可以通过下面的方式:
配置YARN:
之前的例子是我们直接手动执行了mapreduce。在Hadoop 2 之后引入了一种新的方式 --YARN。
YARN是一个资源分配框架,我们把执行mapReduce的执行分配给YARN,让YARN来去分配执行这些JOB。
-
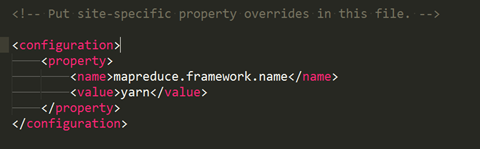
配置 etc/hadoop/mapred-site.xml
到etc/hadoop 目录下,修改mapred-site.xml.template 文件的名字为 mapred-site.xml
接下来打开文件,做如下修改:
-
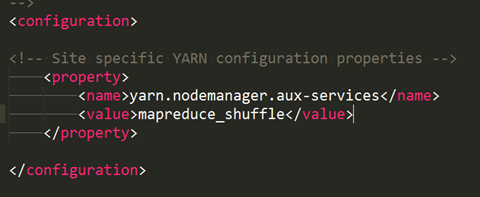
配置etc/hadoop/yarn-site.xml
同上,然后把内容修做如下修改:
接下来,启动ResourceManager和NodeManager的守护进程:
start-yarn.sh
可以在localhost的8088 端口来查看这个资源管理的状态。http://localhost:8088/
接下来启动一个mapreduce的job(和刚刚一样,但是本次的执行是通过向YARN注册来执行。所以可以通过YARN的管理页面看到)
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.5.jar grep /input/hadoop/* /user/coley/test4 'dfs[a-z.]+'
关闭yarn可以通过下面命令:
stop-yarn.sh
参考的官方文档:http://hadoop.apache.org/docs/r2.6.5/hadoop-project-dist/hadoop-common/SingleCluster.html