王孬孬young的Hadoop集群2.0版本╭(●`∀´●)╯
注:所需镜像版本:CentOS-7-x86_64-DVD-1511
所需Hadoop版本:hadoop-2.7.3
所需jdk:jdk1.8.0_161
重要提示:在进行操作时,注意自己的安装包版本,如果和我的不同,记得更换版本
附:上次是在RedHat里面的root用户下搭建的集群,之后我自己感觉不太好,这次在CentOS里面的Hadoop用户下重新搭建一下,在此感谢—盛夏光年@1314,在他的帮助下我才成功搭建了这个集群,希望大家可以多多关注他,thank you very much ヽ(。◕‿◕。)ノ
集群搭建正式开始啦:
1 安装CentOs镜像:
注意选择带GUI 的服务器-----安装时有图形化界面

直接在图形化界面上创建hadoop 用户

安装时如果出现这个界面 先输入1 再输入2 再输入q 最后输入yes

2 安装jdk hadoop
以Hadoop用户进入CentOS 在home目录里新建文件夹—software,把Hadoop安装包和jdk安装包放入software目录里面


退出Hadoop用户,以root用户登录CentOs 输入visudo
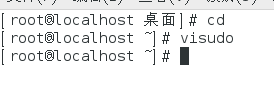
在root ALL=(ALL ) ALL下面添加hadoop ALL=(ALL) ALL----给Hadoop用户赋予Root权限

以Hadoop用户进入CentOS 后安装Hadoop 和jdk
解压缩hadoop jdk安装包
tar -zcvf hadoop-2.7.3.tar.gz
tar -zxvf jdk-8u161-linux-x64.tar.gz


3 配置环境变量
在Hadoop用户中:
打开 配置文件 vi ~/.bashrc
在文件最后面添加以下内容:注意其中Hadoop和 jdk的版本和路径
export JAVA_HOME=/home/hadoop/software/jdk1.8.0
export PATH=$PATH:$JAVA_HOME/bin
##HADOOP_HOME
export HADOOP_HOME=/home/hadoop/software/hadoop-2.7.3
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
# Hadoop Environment Variables
export HADOOP_HOME=/home/hadoop/software/hadoop-2.7.3
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
让环境变量生效: source ~/.bashrc
查看是否生效:hadoop

查看java版本,如果显示以下信息,说明成功

4 对hadoop-2.7.3进行配置:
进入 hadoop-2.7.3/etc/hadoop目录中----所有相关的配置文件都在这个目录中
hadoop-env.sh ------添加jdk(由于Hadoop是java进程,所以需要添加jdk)
slaves -------- 添加节点名称
core-site.xml ------指定namenode的位置
注(hadoop.tmp.dir 是hadoop文件系统依赖的基础配置,很多路径都依赖它。如果hdfs-site.xml中不配置namenode和datanode的存放位置,默认就放在这个路径中.)
hdfs-site.xml ------配置namenode和datanode存放文件的具体路径 配置副本的数量,注:最小值为3,否则会影响到数据的可靠性
mapred-site.xml -----此文件本身是没有的,需要将mapred-site.xml.template重命名为mapred-site.xml
注:(Mapreduce.framework.name:决定mapreduce作业是提交到 YARN集群还是使用本地作业执行器本地执行。)
yarn-site.xml------Yarn.resourcemanager.hostname:资源管理器所在节点的主机名 Yarn.nodemanager.aux-services:一个逗号分隔的辅助服务列表,这些服务由节点管理器执行。该属性默认为空。
打开 hadoop-env.sh
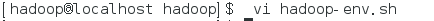
在#The java implementation to use 下面添加你的jdk路径

打开slaves文件 vi slaves

在里面写入节点名
注:我设定的主节点是 hadoop1 其他两个节点是hadoop2 hadoop3这个节点名可以自己取

在hadoop用户下
注意:注意配置文件中的节点名,如果不一样的话改为你自己定的名字,还有hadoop的相关路径注意修改
打开 core-site.xml vi core-site.xml
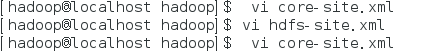
打开后在 <configuration> </configuration>中间添加
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop1:9000/</value> <----这里注意主节点名字
<description> 设定 namenode的主机名及端口</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/software/hadoop-2.7.3/tmp</value> <----这里注意路径,下同!!
<description>存储临时文件的目录</description>
</property>

打开 hdfs-site.xml vi hdfs-site.xml
打开后在 <configuration> </configuration>中间添加
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop1:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/software/hadoop2.7.3/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/software/hadoop-2.7.3/tmp/dfs/data</value>
</property>
vi mapred-site.xml vi mapred-site.xml
**注:**有些人打开mapred-site.xml后是新文件,是因为mapred-site.xml文件名称不全,用 vi mapred-site.xml.template这个命令打开
打开后在 <configuration> </configuration>中间添加
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop1:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop1:19888</value>
</property>
vi yarn-site.xml
打开后在 <configuration> </configuration>中间添加
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</nam
<value>mapreduce_shuffle</value>
</property>
切换到root用户下
vi /ect/hosts
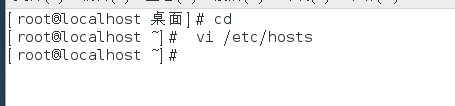
进入文件后在里面添加三行 IP地址和对应的节点名
前面的ip地址查看方法:点击镜像右上角有线----有线设置 出现下图 ipv4地址,后两个节点的接着第一个节点往后就行


5 关闭防火墙
在hadoop1的 root用户下输入:
systemctl stop firewalld.service #停止firewall
systemctl disable firewalld.service #禁止firewall开机启动
firewall-cmd --state #查看默认防火墙状态(关闭后显示notrunning,开启后显示running)
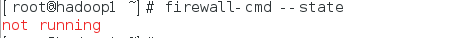
6 克隆
关闭hadoop1 ,克隆hadoop2 hadoop3
三个节点打开,进入root用户 修改主机名和静态IP
修改主机名:
虚拟机都进入root用户,改名为hadoop1


修改静态IP
先连接网络查看IPV4地址和DNS

点击箭头所指的地方


把IPV4和网络掩码 网关填写一下,注意和虚拟机的相对应


设置完毕后点击应用,打开终端
ping www.baidu.com
出现以下信息后按Ctrl+C退出,说明IP修改成功

其他两个节点照例也修改名称和IP,**注意:**我主节点IPV4的地址是:192.168.205.148,那么其他两个子节点的IPV4地址为:192.168.205.149 和 192.168.205.150,IP这点要注意!
7 设置免密登陆
进入hadoop用户下,三台节点都要进行下列操作
例 在hadoop1节点上:
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cd ~/.ssh
ls
cat id_rsa.pub >> authorized_keys
chmod 600 authorized_keys
ssh hadoop1------在不同节点上注意更换节点名
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop2------注意后面的节点名
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop3------注意节点名
在hadoop2 节点上:
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cd ~/.ssh
ls
cat id_rsa.pub >> authorized_keys
chmod 600 authorized_keys
ssh hadoop2------在不同节点上注意更换节点名
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop1------注意后面的节点名
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop3------注意节点名
在hadoop3节点上:
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cd ~/.ssh
ls
cat id_rsa.pub >> authorized_keys
chmod 600 authorized_keys
ssh hadoop3------在不同节点上注意更换节点名
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop1------注意后面的节点名
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop2------注意节点名
在配置完成后,可以在每个节点上都测试一下:(如在hadoop2节点上)
ssh hadoop2
显示下图信息后: exit-----退出登录

8 格式化HDFS文件
进入/home/hadoop/software/hadoop-2.7.3/etc/hadoop目录中
在三个节点内都输入 hdfs namenode -format
出现框内所示,则成功
如果显示 Exiting with status 1则失败

在hadoop1 内输入start-all.sh
后输入 jps 如图显示则成功
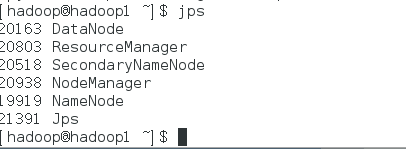
在hadoop2和 hadoop3 内输入jps

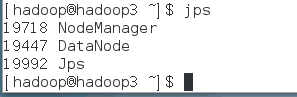
显示三个表示成功
现在Hadoop基于虚拟机的完全分布式集群配置完毕啦~~