前提:需要3台配置好jdk和hadoop环境变量的虚拟机
可以配置好一台服务器然后用xsync脚本进行同步,具体见另外一篇博客https://blog.csdn.net/qq_41813208/article/details/102575933
其中三台服务器的名称分别是
hadoop112、hadoop113、hadoop114
修改了hosts文件将三个名称绑定了服务器
例如
hadoop112 192.168.1.112
hadoop113 192.168.1.113
hadoop114 192.168.1.114
注意
hadoop和jdk目录在/opt文件夹下,
其中环境变量如下
如果后面配置文件出现了hadoop路径问题,根据自己的实际环境修改一下

配置地图:
| hadoop112 | hadoop113 | hadoop114 | |
| HDFS | NameNode DataNode |
DataNode |
SecondaryNameNode DataNode |
| YARN | NodeManager |
ResourceManager NodeManager |
NodeManager |
开始配置:登录到hadoop112进行配置
1)核心配置文件
配置core-site.xml 注意路径问题!
sudo vim /opt/module/hadoop-2.7.7/etc/hadoop/core-site.xml
在该文件中编写如下配置
<!-- 指定HDFS中NameNode的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop112:9000</value> </property> <!-- 指定Hadoop运行时产生文件的存储目录 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/module/hadoop-2.7.7/data/tmp</value> </property>
(2)HDFS配置文件
2.1、配置hadoop-env.sh
sudo vim /opt/module/hadoop-2.7.7/etc/hadoop/hadoop-env.sh
将下面代码写入文件
export JAVA_HOME=/opt/module/jdk1.8.0_211/
如图:
2.2、配置hdfs-site.xml
sudo vim /opt/module/hadoop-2.7.7/etc/hadoop/hdfs-site.xml
写入文件 注意复制到<configuration>标签内
<property> <name>dfs.replication</name> <value>3</value> </property> <!-- 指定Hadoop辅助名称节点主机配置 --> <property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop114:50090</value> </property>

(3)YARN配置文件
3.1、配置yarn-env.sh
sudo vim /opt/module/hadoop-2.7.7/etc/hadoop/yarn-env.sh
写入
export JAVA_HOME=/opt/module/jdk1.8.0_211/
如图
3.2、配置yarn-site.xml
sudo vim /opt/module/hadoop-2.7.7/etc/hadoop/yarn-site.xml
写入 注意复制到<configuration>标签内
<!-- Reducer获取数据的方式 --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 指定YARN的ResourceManager的地址 --> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop113</value> </property>

(4)MapReduce配置文件
4.1、配置mapred-env.sh
sudo vim /opt/module/hadoop-2.7.7/etc/hadoop/mapred-env.sh
写入
export JAVA_HOME=/opt/module/jdk1.8.0_211/
4.2、配置mapred-site.xml
mepred-site.xml文件不存在需要想利用模板,
cp命令拷贝mapred-site.xml.template 命名为mapred-site.xml
sudo cp /opt/module/hadoop-2.7.7/etc/hadoop/mapred-site.xml.template /opt/module/hadoop-2.7.7/etc/hadoop/mapred-site.xml
然后
sudo vim /opt/module/hadoop-2.7.7/etc/hadoop/mapred-site.xml
写入
<!-- 指定MR运行在Yarn上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>

(5) 修改slaves文件,hadoop-3.2.1版本的hadoop是workers文件
不能有空格和空行
vim /opt/module/hadoop-2.7.7/etc/hadoop/slaves

分发配置文件
通过xsync脚本分发
关于xsync看另外一篇博客:https://blog.csdn.net/qq_41813208/article/details/102575933
执行下面命令,将修改后的hadoop配置文件同步到hadoop113、hadoop114服务器
xsync /opt/moudel/hadoop-2.7.7
最后可以检验一下hadoop113、hadoop114服务器的配置文件有没有和hadoop112一样同步了
比如查看一下core-site.xml文件
cat /opt/module/hadoop-2.7.7/etc/hadoop/core-site.xml
是否和hadoop112一样
最后群起集群
首先需要退出所有服务器的DataNode、NameNode、SecondaryNameNode进程
关闭输入jps显示除jps的所有进程
注意!!!
启动hdfs前需要格式化namenode
如果是第一次使用则需要执行 hdfs namenode -format 后面不可以使用这条命令,原因如下链接
(注意*如果前面以及格式化了就不用再格式化了原因,见博客namenode不能一直格式化的原因)
一、启动hdfs
关闭方法
输入:stop-dfs.sh
启动方法
输入start-dfs.sh
即可这个脚本文件在hadoop根目录sbin/下
二、启动YARN
巨大的坑需要注意一下!
必须要在hadoop113上启动,原因在于ResourceManeger在hadoop113上!
执行 start-yarn.sh
得到启动结果,如果中途遇到输入密码,则配置一下无密登录
关于无密登录参考这两篇博客:
https://blog.csdn.net/qq_41813208/article/details/102597273
https://blog.csdn.net/qq_41813208/article/details/102575933
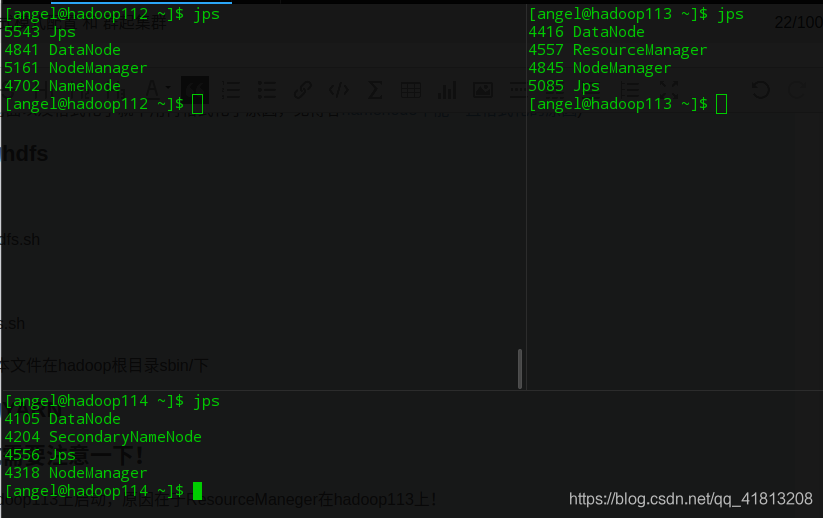
最后验证一下
如果访问不到页面,则关闭服务器的防火墙
在hadoop112上关闭,输入sudo systemctl stop firewalld.service 即可关闭防火墙,就可以访问到下面的页面
永久关闭sudo systemctl disable firewalld.service
浏览器输入hadoop112的ip+50070端口访问页面表示成功!
http://hadoop112:50070

